
移动测试开发 智能化自动生成文本总结的方法
背景
对长文本进行总结和概括一直以来都是一项繁琐的任务,需要工作人员耗费大量的时间和精力去理解文本内容再对重要信息进行提炼和整合。尤其是针对一些晦涩难懂且专业性较强的文本,更是只有经验丰富的工作人员才能对文本进行正确的理解和总结。因此,我们渴望用一种自动化的方式来实现对文本进行准确的总结和概括。
随着神经网络和自然语言处理技术的发展,为自动化生成摘要、总结提供了有效的方法,并在一定程度提高了人们的工作效率。本文将从当下比较热门、效果较好的技术来为大家进行介绍。
热点技术
一、从原文中抽取句子组成文本总结
从原文中抽取关键句子组合成文本总结,通过一些算法来计算各个句子在原文中的权重,将权重靠前的句子提取出来,作为摘要句,常见的方法有:
TextRank
使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值,最后选取 N 个得分最高的节点,作为摘要。其基本思想来源于谷歌的 PageRank 算法,不需要事先对多篇文档进行学习训练, 因其简洁有效而得到广泛应用。编码 + 聚类/分类
通过 Bert,transformer 或 wor2vec 方式进行编码,得到句子级别的向量表示。再用聚类的方式或分类模型来提取出关键句子。对于聚类可用 K-Means 聚类和 Mean-Shift 聚类等进行句子聚类,得到 N 个类别。最后从每个类别中,选择距离质心最近的句子,得到 N 个句子,组合成最终摘要。对于分类,可以选择合适的分类模型进行分类,其标签获取往往是选取原文中与标准摘要计算 ROUGE 得分最高的一句话加入候选集合,接着继续从原文中进行选择,保证选出的摘要集合 ROUGE 得分增加,直至无法满足该条件。得到的候选摘要集合对应的句子设为 1 标签,其余为 0 标签。
抽取式的方法发展较早,技术相对成熟,效果稳定。摘要中所有的语句均来自于源文,逻辑合理,语句通顺。其缺点在于可能会引入冗余信息或缺失关键信息,组成的文本连贯性较差。在实际应用中可将此方法用于辅助人工分析。尤其是在较长的文本中,可提取出关键句子,让人抓住重点。
二、用文本生成模型来生成文本总结
生成式方法是让模型去理解源文本,再生成新的文本,与人工写总结的方式相似。对于机器而言,生成式是一个序列生成的问题,通过源文档序列 x=[x1, x2, ... , xn] 生成摘要序列 y=[y1, y2, ..., ym]。这里为大家介绍两个基础的网络模型。
- Seq2Seq+Attention 模型
Seq2Seq 模型简单概括就是拼接两个 RNN 系(RNN,LSTM 等)的模型,分别称为模型的 Encoder 部分和 Decoder 部分。Encoder 部分负责输入文本语义的编码,生成一个 “浓缩输入语义” 的语义空间 meaning space。Decoder 部分负责根据这个语义空间及每个 time-step 的 Decoder 输出,进行 Attention 机制并生成句子,从而实现在语义背景下从句子到句子的直接转换(Sequence to Sequence)。
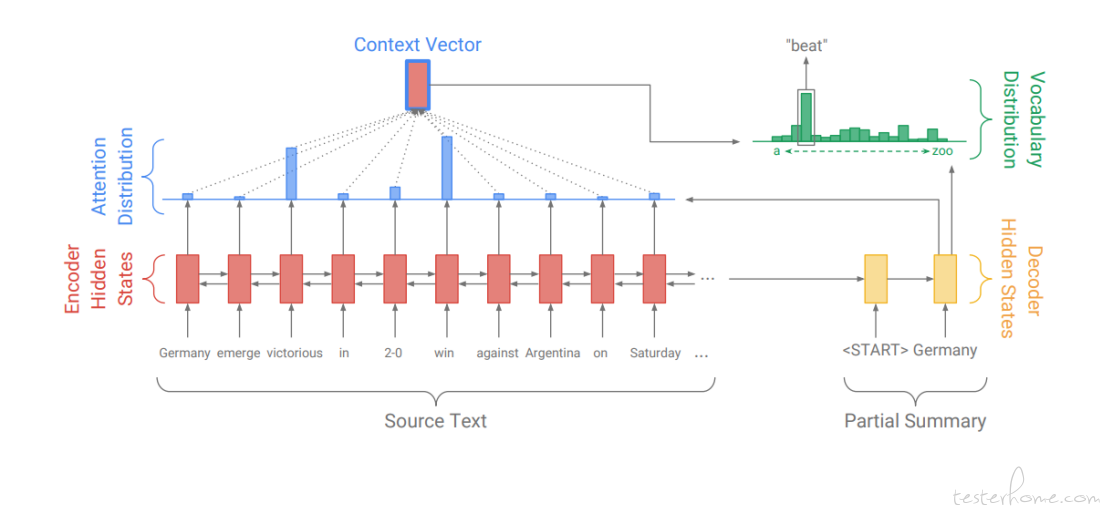
该模型的不足之处在于:无法生成训练时未出现(OOV)的词,只能生成词汇表中的词;会产生错误的事实,句子的可读性较差;文本自我重复,即聚焦于某些公共 Attention 很大的单词;长文本摘要生成难度较大。
- Pointer-Generator(指针生成器网络)
该方法在基于注意力机制的 Seq2Seq 基础上增加了 Copy 和 Coverage 机制,缓解未登录词问题(OOV)和生成重复的问题。
PGN 架构的核心思想: 对于每一个解码器的时间步, 计算一个生成概率 p_gen = [0, 1] 之间的实数值, 相当于一个权值参数. 用这个概率调节两种选择的取舍, 要么从词汇表生成一个单词, 要么从原文本复制一个单词。
①. 使用指针生成器网络 (pointer-generator network),通过指针从原文中拷贝词,这种方式可以在正确复述原文信息的同时,也能使用生成器生成一些新的词。
②. 使用覆盖率 (coverage) 机制,追踪哪些信息已经在摘要中了,通过这种方式以期避免生成具有重复片段的摘要。
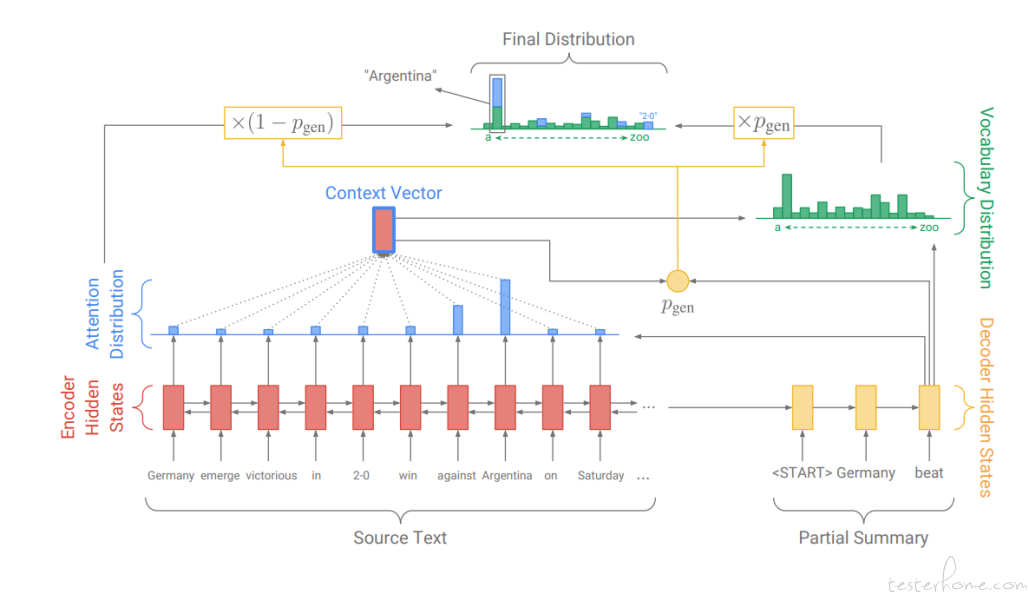
该方法的不足在于:概括的内容可能并非源文本的核心内容;生成的摘要都是相近的词或片段概括,没有更高层次的压缩概括;语句通畅性降低。
相比于抽取式,生成式的摘要更加灵活,强大,可以更好的引入外部知识。然而,生成过程往往缺少关键信息的控制和指导,无法很好地定位关键词语,难以生成流畅性的句子。
三、抽取与生成相结合的方法
考虑到抽取式和生成式各自的优缺点,目前很多研究已经将二者结合:用抽取的方式选择重要内容,基于重要内容指导生成网络的训练对内容进行改写。
Bottom-Up
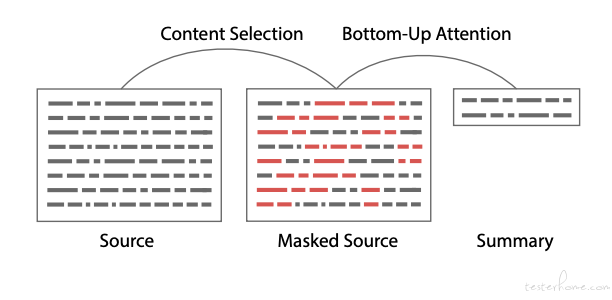
Bottom-Up 使用数据有效的内容选择器去确定应该作为摘要一部分的源文档中的短语。将此选择器用作自下而上的注意力步骤,以将模型约束成可能的短语。使用这种方法提高了压缩文本的能力,同时仍能生成流畅的摘要。
首先为源文档选择一个选择掩码,然后通过该掩码约束标准神经模型。这种方法可以更好地决定模型应选择哪些短语去作为摘要中的内容,而不会牺牲神经文本摘要器的流利性优势。此外,内容选择模型的数据效率很高,可以用不到原始训练数据的 1%进行训练。这为领域转移和低资源摘要提供了机会。
SPACES
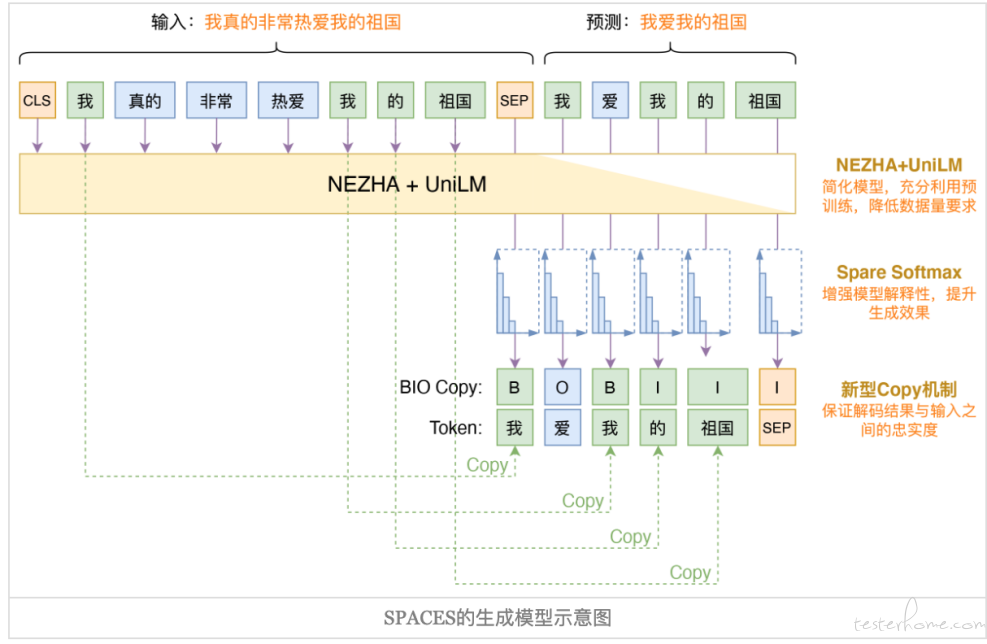
SPACES 以抽取出的关键句作为输入来生成新的总结、摘要文本。首先对文本进行分句,然后构建句子索引,并通过 transformer 对句子进行编码。然后在编码后的句子向量的基础上用 DGCNN 训练一个关键句分类的模型,判断每个句子是否为关键句。标签是通过一种自动的方式生成的,根据标准的总结,在原文中进行相似度计算,相似度较高的句子视为关键句其标签为 1,否则为 0。生成模型就是一个 Seq2Seq 模型,以抽取模型的输出结果作为输入、人工标注的总结作为标签进行训练,得到摘要生成模型。
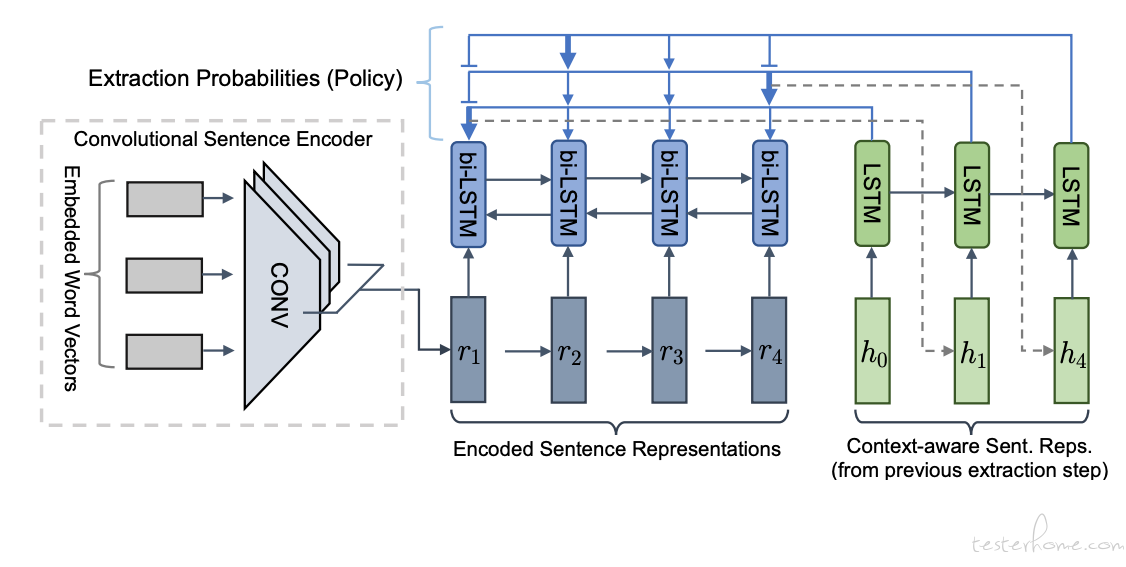
Fast-RL
Fast-RL 是基于强化学习的任务,首先使用抽取器 agent 选择重要的句子或突出显示的内容。然后使用生成器网络重写每一个被抽取的句子。抽取器利用分层神经模型来学习文档的句子表示,并利用 “选择网络” 根据其表示提取句子。使用时域卷积模型来计算文档中每个单独句子的表示形式。为了进一步结合文档的全局上下文并捕获句子之间的长期语义依赖关系,将双向 LSTM-RNN 应用于卷积的输出。基于抽取器提取的句子,添加另一个 LSTM-RNN 来训练 Pointer Network,以循环抽取句子。
生成器网络用于将提取的文档句子作为输入以生成摘要。使用标准的编码器 - 对齐器 - 解码器。 添加了复制机制以帮助直接复制一些词汇(OOV)单词。最后,将 RL 应用于端到端训练整个模型。
抽取 + 生成的结合形式有很多,融合了抽取式和生成式的优点,生成的文本内容逻辑清晰,语句的连贯性更强,有很大的研究价值和改进空间。
四、将预训练模型用于总结的生成
目前基于预训练模型进行下游任务微调的方法发展很快,迁移性很强,可以应用在多种下游任务上,在文本的总结上也有不错的效果。
基于 BART
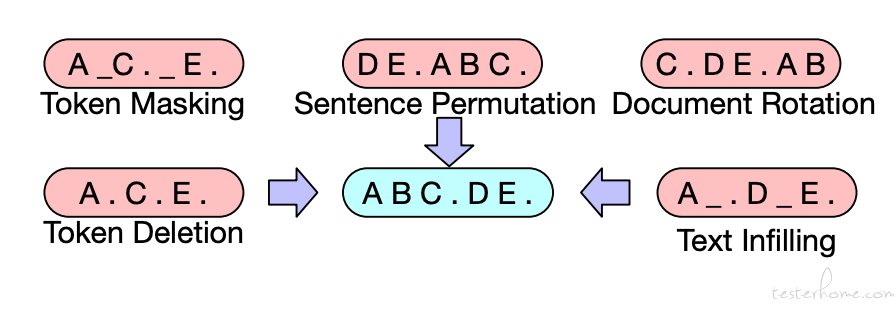
BART 的训练主要由 2 个步骤组成:(1) 使用任意噪声函数破坏文本。 (2)模型学习重建原始文本。BART 使用基于 Transformer 的标准神经机器翻译架构,可视为 BERT、GPT 等预训练模型的泛化形式。通过随机打乱原始句子的顺序,再使用文本填充方法 (即用单个 mask token 替换文本片段) 能够获取最优性能。BART 尤其擅长处理文本生成任务,同时在自然语言理解任务中的表现也是可圈可点。
基于 CPT
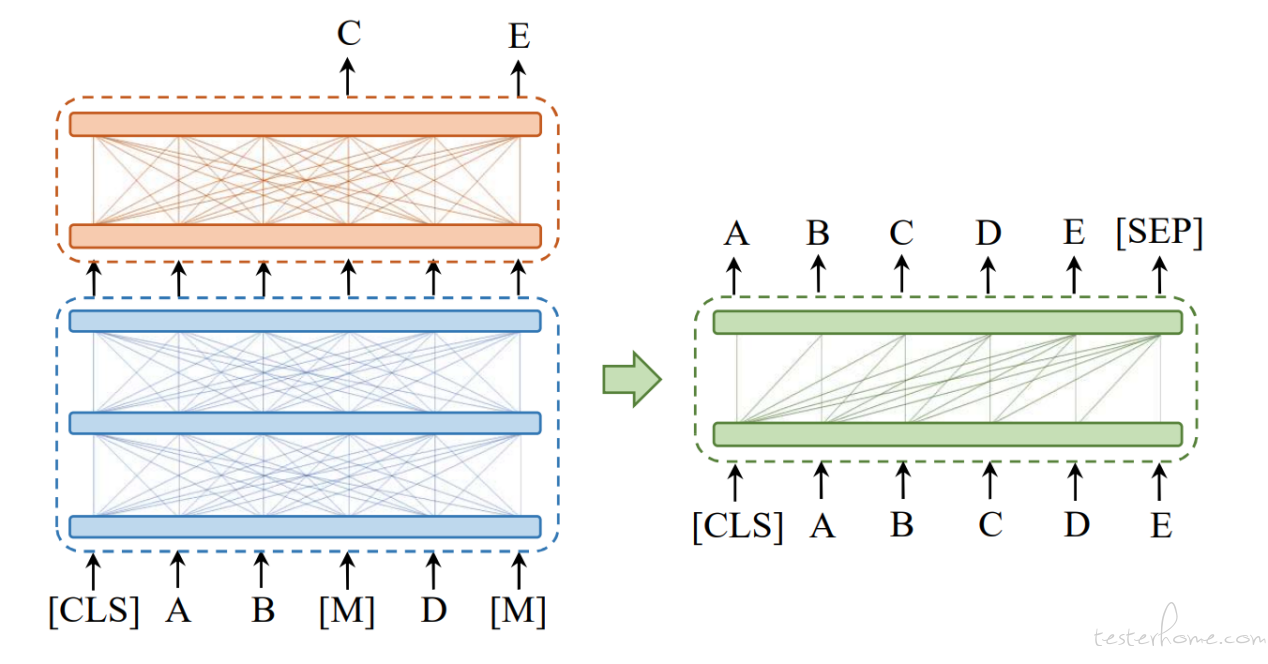
CPT 是在 BART 的基础上,提出兼顾自然语言理解(NLU)和自然语言生成(NLG)的模型结构。CPT 的具体结构可以看作一个输入,多个输出的非对称结构,主要包括三个部分:(1)S-Enc (Shared Encoder):共享 Encoder,双向 attention 结构,建模输入文本。(2)U-Dec (Understanding Decoder):理解用 Decoder,双向 attention 结构,输入 S-Enc 得到的表示,输出 MLM 的结果。为模型增强理解任务。(3)G-Dec (Generation Decoder):生成用 Decoder,正如 BART 中的 Decoder 模块,利用 encoder-decoder attention 与 S-Enc 相连,用于生成。
基于 PEGASUS
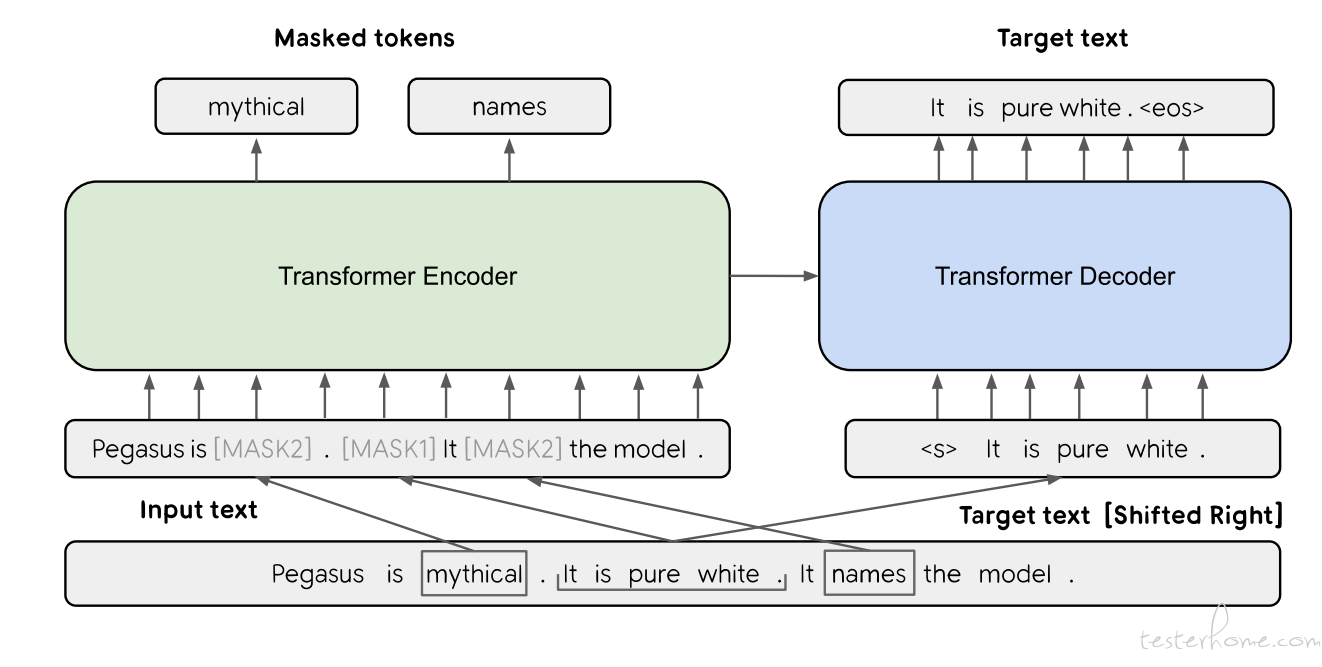
在 PEGASUS 中,将源文档中的 “重要句子” 删除或者遮蔽,再利用剩余的句子在输出中生成这些被删除或遮蔽的句子。这是一种基于间隙句子 (gap-sentences) 生成的序列 - 序列模型自监督的预训练目标,以适配 Transformer-based 的 encoder-decoder 模型在海量文本语料上预训练。由间隔句生成(GSG)和掩码语言模型(MLM)相结合,对于低资源任务数据集,通过微调 PEGASUS 模型,可以在广泛的领域实现良好的抽象摘要效果。
预训练模型可以应用在文本生成,文本分类,机器翻译等下游任务上。在数据量较少的情况进行微调也能取得不错的效果,值得持续关注。
效果展示
为了对更好的探索各种文本总结方法的具体表现,我们在现有的数据集上进行了一些实验,以下为在合适的方法下针对不同类型的文本数据进行总结的效果展示:
①. 人文科普文献(基于 TextRank)

②. 个人演讲(基于 PEGASUS)

③. 多人讨论会(基于 CPT)

④. 新闻内容(基于 SPACES)

总结
目前用于生成文本总结的方法有很多,并且处于持续更新的状态,本文所述的只是其中的一小部分方法。在实际应用时可根据具体场景选择合适的方法来帮助大家实现智能化的自动文本总结从而提升工作效率。同时,如果大家对如何进行音频会议的总结或纪要的生成感兴趣的话,可以持续关注我们的公众号,我们会一一为大家进行技术揭秘。