
移动测试开发 一种基于 LSTM 的音频质量检测方案
背景
随着网络技术的发展,各种各样的音视频产品应接不暇,应用场景也越来越多样,使人们的生活更加丰富多彩。与此同时,人们对音频的质量也有越来越高的要求,而如何准确评估音频质量好坏成为了相关行业的研究热点。音频质量评估方法主要分为主观和客观两类。主观方法是通过人根据听觉感受来打分。客观的方法是通过算法来计算评估的,主要分为有参考和无参考两种。有参考的方法在评估音频时需要一个对应的高质量无损音频作为参考,代表算法如 PESQ(Perceptual evaluation of speech quality);而无参考的方法直接对音频进行打分,代表算法如 P.563。
目前大多数客观的音频质量评估方法属于无参考这一类,这类方法往往更准确。而在现实生活中,人类在没有参考的情况下能直接分辨出音频质量的好坏,这意味着存在一种评价机制来直接对音频质量进行评估而不需要参考。设想一下,如果我们通过神经网络模型来训练学习这种机制,那么这个模型不就能准确评估任何语音的质量吗?基于这样的思路,我们探索和实践了基于 LSTM 深度学习模型的音频质量检测方案。
核心技术与架构图
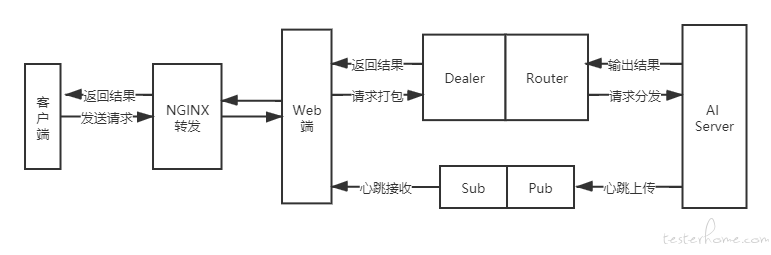
任务处理流程如图所示,整体方案主要分为四个部分:
- 客户端发送音频数据到服务端;服务端通过 nginx 转发请求到对应任务的 web 服务器
- web 服务器将数据加工处理打包,发送给代理端;代理端根据请求类型将数据发给对应的 AI 服务器去处理
- AI 服务器通过快速傅里叶变换(FFT)提取音频数据的频谱特征
- 将提取的频谱特征数据输入到双向 LSTM 网络中,输出音频质量评估结果,并按原路径返回到客户端。
技术优势
- 本方案不需要任何参考就可以对任意音频进行评估打分
- 本方案能够对任意长度的音频进行处理
- 本方案提取了频谱特征数据作为输入,优化了计算量,预测结果更为准确
核心技术实现
1.网络模型
对于音频数据来说,当前时刻的输出不仅与之前的状态有关,还可能与未来的状态相关,因此本方案采用了双向长短时记忆网络(BiLSTM)模型来提取输入信息,这样能够很好地整合全局信息。输出有 2 个,分别是逐帧级别的输出分数和最终的质量评分。
2.数据预处理
在之前的文章《音频质量检测模型中标准数据集的构建方法》中,我们已经具体介绍了数据集的构建方法。这里简要回顾下,使用 ST-CMDS 作为中文纯净语音数据集,并从 100 种噪声中随机挑选,以不同信噪比 (SNR) 的形式加入到纯净语音数据的随机位置上,这种噪音添加方法可以有效地模拟真实场景中的噪声,最后计算 PESQ 评分值。
3.损失计算
损失由两部分组成,第一部分是整体音频数据的均方误差(MSE),通过网络预测值和真实值计算得到;第二部分是帧级别的均方误差,这部分考虑到噪声在每一帧上的不平稳现象对预测结果的影响,同时通过设立一个权值区分不同水平的帧级分数对预测结果的重要性。
def frame_mse_tf(y_true, y_pred):
True_pesq = y_true[:,0,:]
loss = tf.constant(0, dtype=tf.float32)
for i in range(y_true.shape[0]):
loss += (10**(True_pesq[i] - 4.5)) * tf.reduce_mean(tf.math.square(y_true[i] - y_pred[i]))
return loss / tf.constant(y_true.shape[0], dtype=tf.float32)
def train_loop(features, labels1, labels2):
loss_object = tf.keras.losses.MeanSquaredError()
with tf.GradientTape() as tape:
# 预测结果
predictions1, predictions2 = model(features)
# 计算 loss
loss1 = loss_object(labels1, predictions1)
loss2 = frame_mse_tf(labels2, predictions2)
loss = loss1 + loss2
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
4.模型训练
将处理好的数据集载入,随机打散数据集,优化器使用 RMSprop 来训练。
def read_npy_file(filename):
data = np.load(filename.numpy().decode())
return data.astype(np.float32)
def data_preprocessing(feature):
feature, label1 = feature[...,0] , feature[0][0]
label2 = label1[0]*np.ones([feature.shape[0],1])
return feature, label1, label2
def read_feature(filename):
[feature,] = tf.py_function(read_npy_file,[filename],[tf.float32,])
data,label1, label2 = tf.py_function(data_preprocessing,[feature],[tf.float32,tf.float32,tf.float32])
return data, label1, label2
def generate_data(file_path):
list_ds = tf.data.Dataset.list_files(file_path + '*.npy')
feature_ds = list_ds.map(read_feature, num_parallel_calls=tf.data.experimental.AUTOTUNE)
return feature_ds
optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.001)
W = model.layers[0].get_weights()
# 读取数据集
ds = generate_data(train_file_path)
# 随机打乱
ds = ds.shuffle(buffer_size=1000).padded_batch(BATCH_SIZE,padded_shapes=([None, None], [None], [None, None])).prefetch(tf.data.experimental.AUTOTUNE)
for step, (x, y, z) in enumerate(ds):
loss = train_loop(x, y, z)
总结
本方案构建了一种自动评估音频质量的方法,网络采用双向 LSTM 模型,利用现有的中文纯净语音数据集 ST-CMDS 和 100 种噪声数据构建了训练数据集,在测试时不需要任何参考即可对音频进行评估。