
移动测试开发 音频质量检测模型中标准数据集的构建方法
背景
音频质量检测模型训练中,纯净高质量的音频数据集比较好获得,但是损伤音频的数据集比较少,而且损伤音频的质量得分也很难评估。我们采用了一种只依靠纯净高质量的语音数据集来制作低质量音频并打分的方法。
在语音质量评估中,有很多主观和客观的评价方法。主观的评价方法就是人通过听觉感受来评价音频质量的好坏,并进行打分,常用的评分标准是 MOS(Mean Opinion Score)。MOS 是国际电信联盟(ITU)在语音质量的主观评价方法 ITU-T P.800 标准里提出的,该标准是对电话传输系统中声音质量主观评价的概述,其本质就是 MOS 方法。同时给出语音质量主观评价的普遍方法和普遍测试环境,其他所有测试都遵循该建议,特别是测试环境(在所有的主观评价方法中基本相同)。为完成 MOS 评价得分,需要大量评测人员对音频质量进行打分,分值范围为 1-5 分,分数越高表示音频质量越好。一般情况下 MOS 值大于 4 的被认为是质量比较好的语音,小于 3 的则被认为语音质量不合格。

客观的语音质量评估方法即通过算法来评估语音质量,主要有 2 类,有参考和无参考的语音质量评估方法。两者的主要区别在于是否需要标准音频参考。有参考的除了待评估的音频,还需要一个对应的高质量无损伤的音频作为参考,代表算法如 PESQ(Perceptual evaluation of speech quality);而无参考的评估方法直接对待评估音频进行打分,代表算法如 P.563。我们的方法采用了 PESQ 算法。PESQ 算法需要带噪声的衰减信号和一个原始的参考信号。首先,将两个信号通过电平调整到标准听觉电平,再利用输入滤波器模拟标准电话听筒进行滤波。然后将两个信号在时间上进行对准,并通过听觉变换,变换包括线性滤波和增益变化的补偿和均衡。之后,根据两个听觉变换后的信号之间的谱失真测度间的差值,分析提取两个退化参数, 综合时域和频域特性得到评估值。最后,将这个评估值映射到 MOS 值范围,即得到 PESQ 分数。PESQ 值在-0.5-4.5 之间,同样分值越高,语音质量越好。
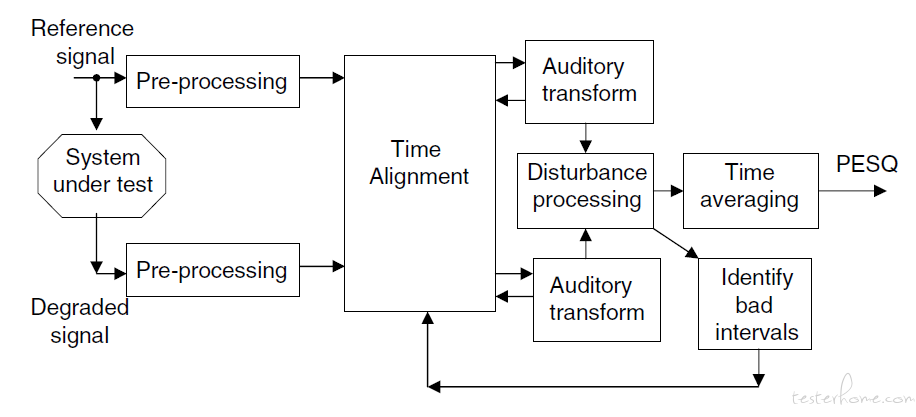
我们的方法是使用 ST-CMDS 作为中文纯净语音数据集,并从 100 种噪声中随机挑选,以不同信噪比 (SNR) 的形式加入到纯净语音数据的随机位置上,这种噪音添加方法可以有效地模拟真实场景中的噪声,最后计算 PESQ 指标作为每一份音频数据的 GroundTruth,步骤如下:
1.随机选择加入噪声的起始与结束段落
2.根据指定的信噪比计算加入噪声的强度值
3.在计算好的段落内加入随机选择的噪声种类
4.计算 PESQ 分数
技术实现
1.随机选择加入噪声的起始与结束段落
准备高质量的音频数据和噪声数据,将噪声随机一段数据插入到高质量的音频数据中。random_sample 函数中,比较高质量的音频数据和噪声数据的长度,选取较小的长度范围,生成随机片段。
def random_sample(n1, n2):
if n1 < n2:
start = random.randint(0, n1)
end = random.randint(start, n1)
else:
start = random.randint(0, n2)
end = random.randint(start, n2)
return start, end
2.根据指定的信噪比计算加入噪声的强度值
信噪比指为有用信号功率(Power of Signal)与噪声功率(Power of Noise)的比值。为了合成指定信噪比的混合语音,需要对噪声的能量进行调整。根据信噪比的计算公式,计算出噪声能量调整的倍数。
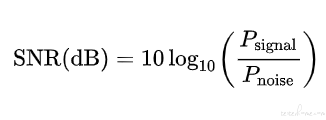
def add_noise(x, d, SNR):
P_signal = np.sum(abs(x) ** 2)
P_d = np.sum(abs(d) ** 2)
P_noise = P_signal / 10 ** (SNR / 10)
k = np.sqrt(P_noise / P_d)
return k
3.在计算好的段落内加入随机选择的噪声种类
读取高质量的音频数据和噪声数据,根据前 2 步生成的随机片段的位置和噪声能量的调整倍数,将调整后的噪声数据片段插入到高质量音频数据对应位置上,合成低质量的音频数据,并调用 librosa 库保存合成的音频数据。
def make_noise_data(high_wave_data,noise_sample_data):
c_start, c_end = random_sample(len(high_wave_data), len(noise_sample_data))
n_start = random.randint(0, len(noise_sample_data) - (c_end - c_start))
n_end = c_end - c_start + n_start
k = add_noise(high_wave_data, noise_sample_data[n_start:n_end], -10)
convert_data = high_wave_data[c_start:c_end] + k * noise_sample_data[n_start:n_end]
new_wave_data = np.concatenate((high_wave_data[:c_start], convert_data, high_wave_data[c_end:]))
librosa.output.write_wav("noise.wav", new_wave_data, sr)
4.计算 PESQ 分数
调用 python 中的 pesq 库,根据高质量纯净的音频数据和对应的低质量合成数据,计算出低质量合成数据的 PESQ 分值。sr 表示采样频率,‘nb’ 是窄带模式。
score = pesq(sr, high_wave_data, low_wave_data, 'nb')
总结
在现实场景中,我们评估一段音频的质量分值的时候,很难找到对应的高质量音频数据做参考,所以无法用 PESQ 算法来直接计算。我们可以通过神经网络模型来学习这种对应关系,用上面的方法由高质量音频数据构建出对应的低质量音频数据并计算出 PESQ 的分值;将构建好的两类数据输入给神经网络模型做训练,让神经网络学习内在的对应关系,并给任意输入的音频数据打分。当模型训练好后,我们就能对任意的音频数据进行评估打分,而不需要其对应的参考信号。