
移动测试开发 code2vec 代码的连续分布式矢量表示
背景
目前,互联网技术促进了开源软件和开源社区的发展, 这些大规模的代码和数据成为宝贵的资产。与此同时,深度学习也在软件工程领域开始得到应用。如何将深度学习技术用于大规模代码的学习,并实现协助软件工程任务,是人工智能与软件工程领域的共同期望。
代码分析问题可以从多角度衡量代码,可覆盖 code-code、code-text、text-code、text-text 等类别,包括代码克隆检测、代码缺陷检测、代码完形填空、代码补全、代码纠错、代码翻译、代码检索、代码生成、代码注释生成、代码文档翻译等任务。随着机器学习和深度学习的快速发展,我们正在进入智能化时代.越来越多的研究者将深度学习技术用于程序源代码分析中。
国内外概况和发展趋势
学界对于代码分析的研究由来已久,早期的代码分析研究以形式化的逻辑演绎方法为主。随着开源代码的兴起,大量高质量的开源项目诸如 Linux、MySQL、Django、Ant 和 OpenEJB 提供了源代码、代码注释、故障报告以及测试用例等各方面的程序信息。通过代码的统计学特性来获得人类可以理解的知识的思路出现了。人们意识到运用统计规律来分析代码信息是可行的。我们可以通过分析成千上万个编写良好的软件项目的文本,发现部分表征可靠,易于阅读且易于维护的软件的模式。随着机器学习和深度学习发展,现在程序分析侧重于使用人工智能的方法解决,最近,较为新的图神经网络也被研究用于代码分析中。
基于深度学习的代码分析的技术流程
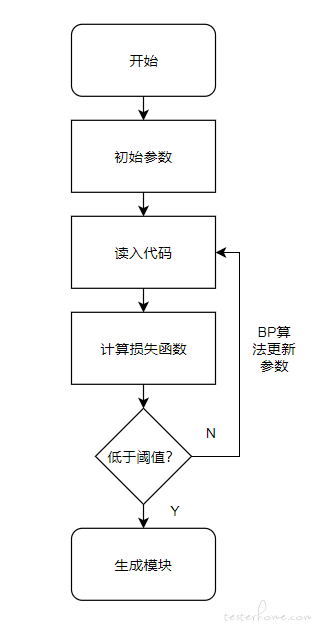
不管是用于什么用途,深度学习模型的训练都具有相似的技术流程。如图所示,在代码分析任务中,神经网络有一个初始的网络参数,在每次读入输入代码之后,神经网络根据任务目标计算损失函数,并设立阈值来判定是否用反向传播算法进行参数更新。当损失函数的值小于特定阈值之后,整个网络训练完毕,开始执行特定的代码分析任务。
程序的表征
上述深度学习的基础是对程序进行表征,喂给模型进行训练,最后执行代码分析任务。如何选择合适的形式 (Token 序列、抽象语法树、数据流图、 API 调用图) 来表示程序成为关键步骤。目前的程序理解研究中,程序的表示大多都只采用某一种表示方式,例如程序 token 序列级别的表示、AST 节点序列表示、程序中的数据流等。这些信息分别表示了程序的不同特性,例如程序的统计特性、结构性、 语义等,人们根据任务需求选用一种表示方式对程序的某种特性进行建模。其中,code2vec 选择 AST 路径代表程序,AST 代表一个语法结构,该表示蕴含了源代码的结构化性质,可以精准的定位到声明、赋值、运算语句等,更能准确的表征代码。
Code2vec 神经网络的体系结构高层次的概括
Code2vec 类似于自然语言中的 word2vec,是一种使用神经网络预测程序属性的新颖框架,主要思想是将代码变成嵌入向量,学习代码的分布式表示。分布式表示会将将语言的语义或者语法特征分散存储在一个低维、稠密的实数向量中,之所以叫分布式是可以将离散表示的一维取值为 1 分布到各个向量。代码嵌入使我们能够以自然有效的方式对代码段和标签之间的对应关系进行建模。将深度学习应用于编程语言得到代码的嵌入,就像将深度学习应用于 NLP 任务得到单词嵌入一样。
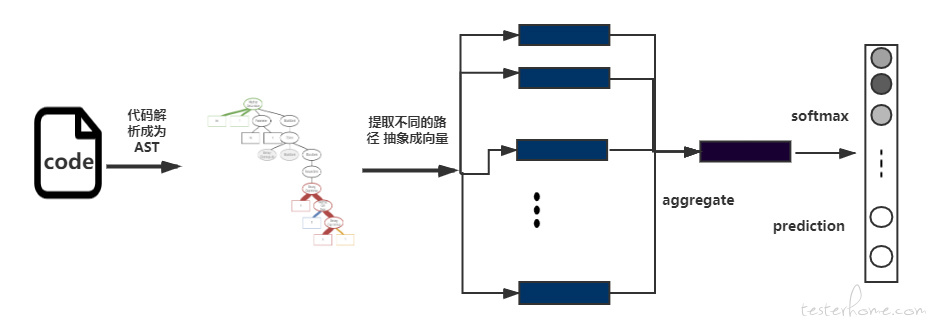
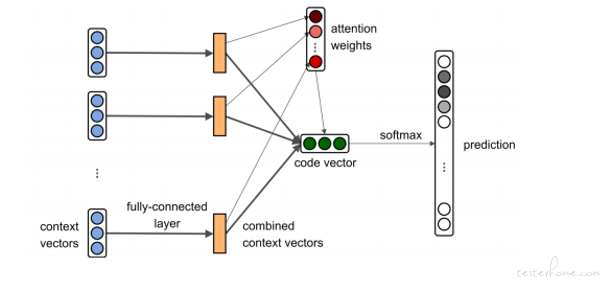
上述,是 code2vec 的关键步骤示意图,具体来说,代码首先通过 AST 提取器生成 AST 树
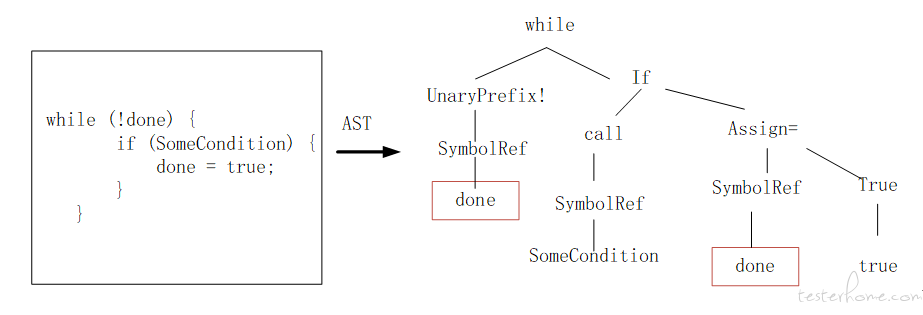
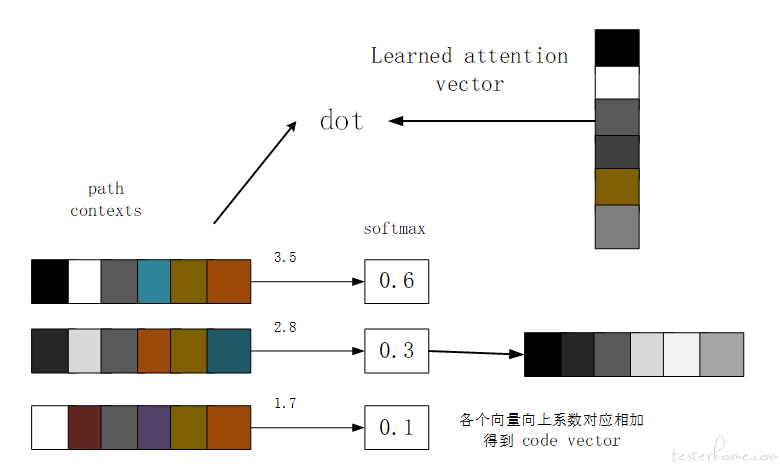
如上图所示,终端节点 done 到 done 的 AST path 为 (done,SymbolRef↑UnaryPrefix↑while↓If↓Assign=↓SymbolRef,done)。其中,done 和 done 表示成为 token vector,中间的路径表示成 path vector。通过 Tanh([W][token1 vector,path vector,token2 vector]) = path context,将得到的不同路径向量输入到全连接层,将每个向量元素重新缩放到 (-1,1) ,如下图得到多个 path context,利用 attention 注意力机制将多个路径汇总得到整个代码的向量,实现将 code 变成 vector 的转变。
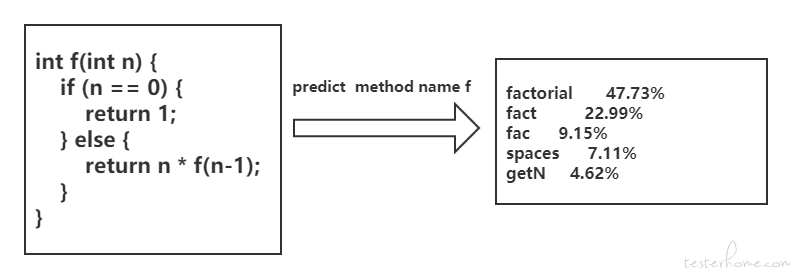
将代码进行向量化的表示之后,可以根据模型的不同需要选择不同的模型进行任务训练。例如,下图的 code2vec 的模型任务是预测函数名称,代码段名称预测的目标是自动预测此代码段的语义标签,下图的右侧显示左侧方法自动预测的标签。最可能的预测(47.73%)是 factorial。好的方法名称使代码更易于理解和维护,概括了其目的。理想情况下,如果您有很好的方法名称,则无需查看具体编码。具体只要将代码向量与模型函数名称的向量进行 softmax 即可进行 prediction 预测,生成最大概率的函数名称。
局限性
在目前的代码分析研究中,仍然一些方面具有相当的局限性。
① 程序的表示
不同的程序表示之间的差距较大。因此,适用的任务范围较小,很难迁移到其他任务中。若能设计更加泛化的程序表示方式,就可以构建更加通用的程序理解模型。
② 标注数据集的匮乏
标注数据集是解决有监督学习问题的根本。由于理解代码并进行标注需要大量的专业知 识,因此代码标注的成本和难度远远高于图片和自然语言。如何得到高质量的标注数据集成为了应用发展的一大难题。
③ 缺少领域知识的理解
要理解一段代码,除了代码本身的性质之外,学习这段代码所实现的业务逻辑也是必不可少的。现有的代码理解方法大多从代码本身的性质入手。深度学习的一大缺陷是难以考虑到代码背后的业务逻辑关系。
④ 模型的有效性分析
目前的程序理解任务缺乏通用的测试基准 (Benchmark),无法对各种程序理解模型进行直接对比。当前的评估指标大多参照自然语言处理任务中使用的评价指标 (例如 BLEU),而这些评价指标是否能直接用于评价程序理解模型还有待于进一步验证。因此,如何针对程序理解建立具有普适性的测试基准和评价度量体系也是程序理解研究中面临的一项挑战。
总结
在将代码向量化的基础上,我们可以实现例如代码摘要生成、两个代码相似度检测、代码复杂度预测等功能。
词嵌入技术和分布式假说赋予了深度学习工具强大的表征能力,代码的高层语义和结构信息以向量形式被编码进入神经网络中。首先,这种表征能力有利于填补代码与自然语言间的语义鸿沟,这使得深度学习尤其适合于代码分析任务。其次,表征能力使得深度学习可以以一种无监督的黑盒模式进行特征提取,从而省去了繁琐的人工特征工程。最后,强大的表征能力使得深度学习不像传统统计学方法那样受限于词表越界问题。
随着软件工程的发展,人们越来越重视代码数据的收集与表征,一些新颖的代码特定的神经网络也被提出,我们有理由期待深度学习方法在未来代码分析任务中的表现。