
MySQL 索引的建立对于 MySQL 的高效运行是很重要的,索引可以大大提高 MySQL 的检索速度。
索引方法
Mysql 的索引方法有两种,BTERR 和 HASH。

散列表(Hash Table)和 B+Tree 都是一些常用的数据结构,再数据结构前篇中介绍过一些,关于散列表和树的数据结构,后续也会在《数据结构后篇》中总结一下。
Hash
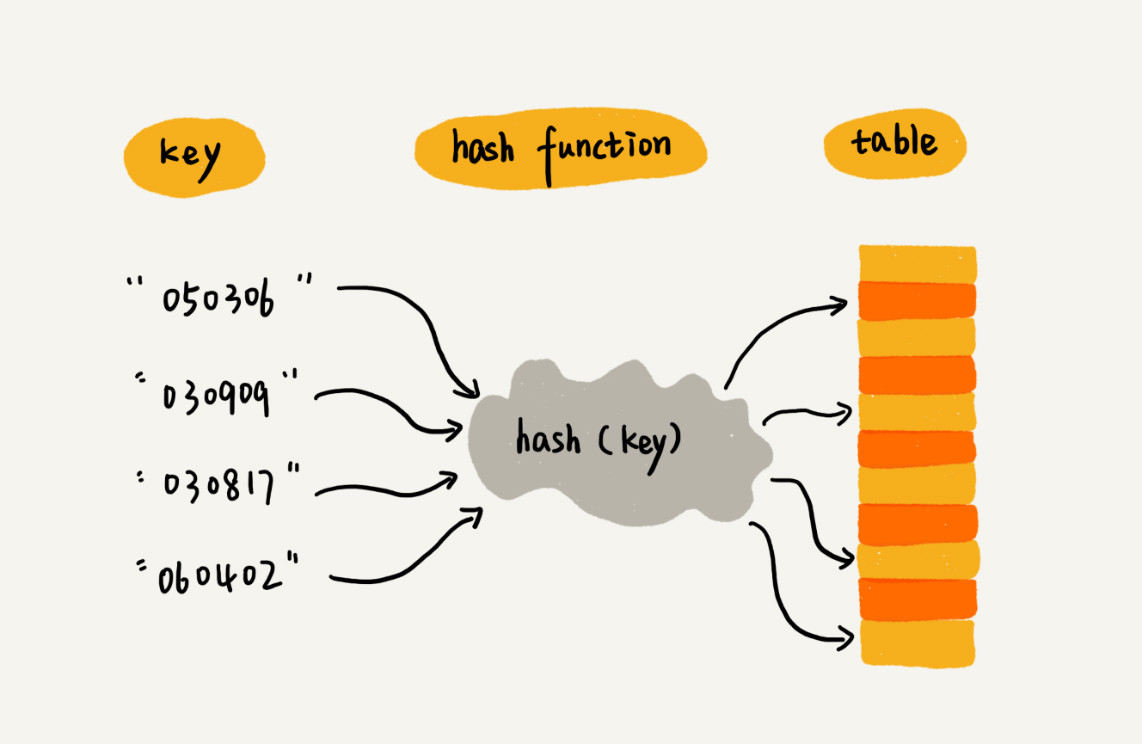
Hash 索引如何提高查询速度
Hash 索引是将索引键通过 Hash 运算之后,将 Hash 运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表 (可以是数组结构) 中。
那很显然采用 Hash 索引,在不考虑 Hash 冲突的情况下,通过 Hash 索引的可以一次定位数据,效率要比 BTree 高很多。
Hash 索引缺陷
Hash 函数对索引健运算后,索引无法保证与索引健值大小一致,所以 Hash 索引有明显缺陷,就是不支持范围查询;无法利用索引的数据来避免 sql 查询的排序运算;对组合索引而言因为是组合健值进行 Hash 运算,所以无法使用部分索引让组合索引生效。
Hash 索引使用场景
那只需要做等值比较查询,而不包含排序或范围查询的需求,都适合使用哈希索引
B+Tree
B 树 (B-Tree) 属于多叉树又名平衡多路查找树,那 B+ 数属于改进版的 B 树,
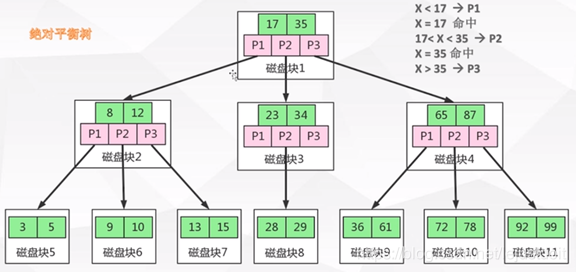
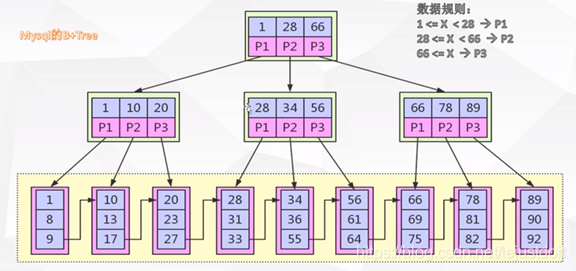
B 树跟 B+ 树的不同点
B+ 树中的节点不存储数据,只是索引,而B树中的节点存储数据
B 树中的叶子节点并不需要链表来串联。
B+Tree 如何提高查询速度
B+Tree 利用平衡查找树的有序性和高效遍历性,和 B+Tree 构建的有限高度的多叉树,通过 IO 次数的降低和查询遍历效率的提高,来提高查询速度。
平衡查找树的特点比较简单,后续也会在《数据结构后篇》中总结一下
已区间查询为例,B+Tree 数据结构中只需要定位到区间起点值对应在树中的结点,然后从这个结点开始,按照平衡查找树的遍历方法继续遍历,直到区间终点对应的结点为止,这期间遍历得到的数据就是满足区间值的数据。
类似于我们在《常用数据结构前篇》中提到的跳表的原理。利用局部数据,一层一层靠近查询数据。
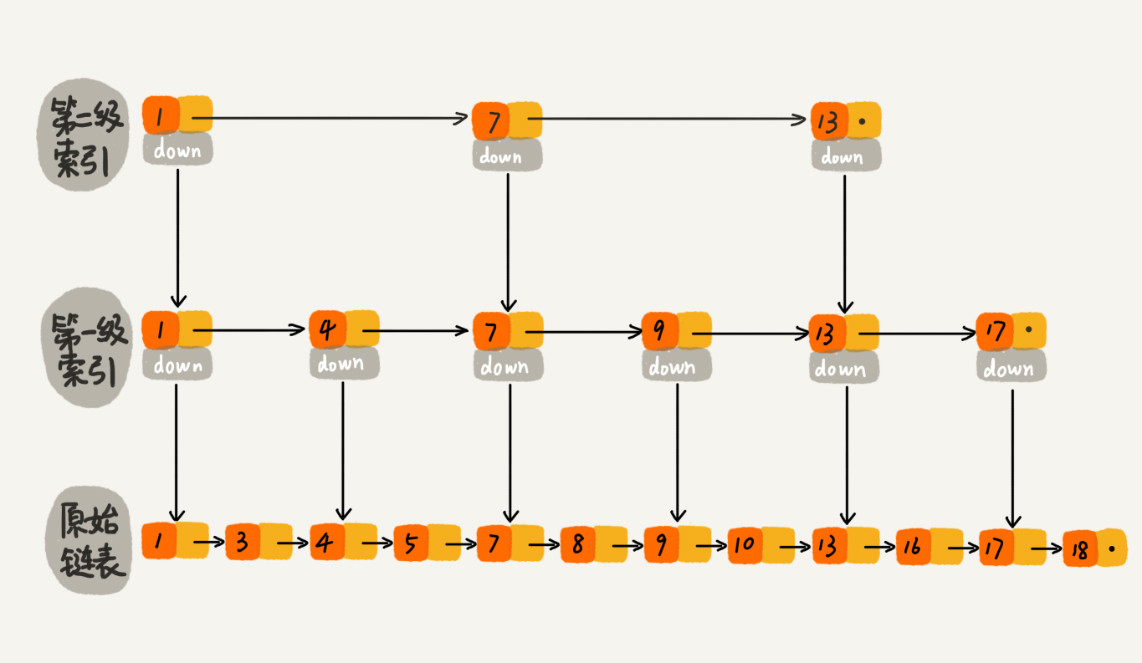
B+Tree 索引使用场景
Mysql 数据库中使用最为频繁的索引类型,不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理中 BTREE 索引也同样是作为最主要的索引类型
扫一扫,关注我
