
AirtestProject 2 行代码帮你搞定自动化测试的文字识别
此文章来源于项目官方公众号:“AirtestProject”
版权声明:允许转载,但转载必须保留原链接;请勿用作商业或者非法用途
前言
Airtest 是一款 基于图像识别原理 的跨平台 UI 自动化测试框架,它能够根据大量的 特征点 来识别一个截图在当前画面中的位置,但是它并不能识别出截图中具体包含了什么文字。
而在自动化测试的过程中,我们会经常遇到需要进行文字识别的场景,比如 识别验证码、识别截图中的文字、读取截图中的数值 等等,遇到这些情况时我们可以如何处理呢?
今天教大家用一款免费的开源图像 OCR 文字识别软件 -- Tesseract-OCR 来处理上述情况。
1.安装 Tesseract-OCR.exe
在网上搜索 “Tesseract”,我们可以找到很多 Tesseract-OCR 的下载链接和安装教程,大家可以选择其中一个版本下载到本地即可。
下载完成后双击进入安装,需要特别注意的是,在选择安装的组件时,我们需要把 Additional language data(download) 这一选项勾上,目的是 安装各个版本的语言包,后续我们就不用手动下载语言包来安装了。
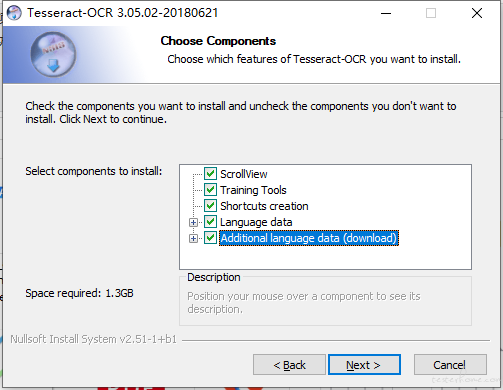
还有一点要注意的是,记住我们选择的软件安装路径,因为我们需要把这个路径添加到 系统环境变量 的 path 中:
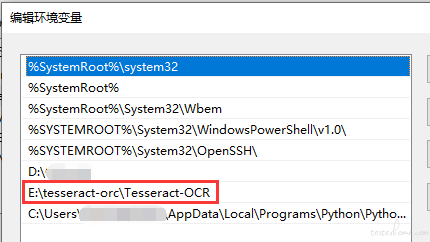
另外一个要新增的环境变量是 TESSDATA_PREFIX ,如下图所示,未设置在识别过程中会报 Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory 的错误:
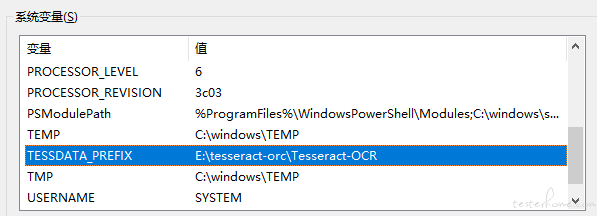
完成以上工作后,我们可以在命令行用 tesseract -v 验证环境是否配置成功:

2.在本地 python 环境中安装 pytesseract
因为我们最终要在 python 环境中使用 airtest 和 tesseract ,所以需要在本地的 python 环境中安装上 airtest 库和 pytesseract 库:
pip install airtest
pip install pytesseract
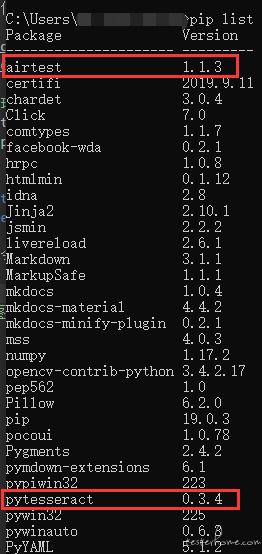
安装完毕后可以在命令行输入 pip list 检查安装结果:
3.用 airtest 截图并识别截图文字
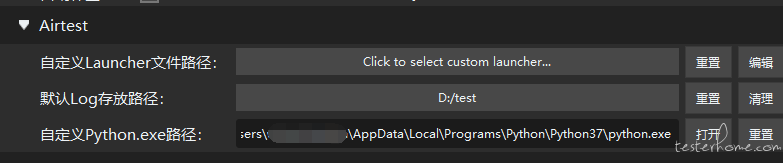
打开我们的 AirtestIDE,在 选项--设置--自定义python.exe路径 中设置我们刚才安装好对应库的 python 环境:
以之前官网提供的 poco demo 的界面为例,我们用 airtest 把红框部分的截图截取下来,然后再利用 tesseract 把截图中的文字识别并打印出来:

具体实现如下:
# -*- encoding=utf8 -*-
__author__ = "AirtestProject"
from airtest.core.api import *
from airtest.aircv import *
auto_setup(__file__)
from PIL import Image
import pytesseract
# 局部截图
screen = G.DEVICE.snapshot()
local = aircv.crop_image(screen,(132,58,380,126))
# 保存局部截图到指定文件夹中
pil_image = cv2_2_pil(local)
pil_image.save("D:/test/score0.png", quality=99, optimize=True)
# 读取截图并识别截图中的文字
image = Image.open(r'D:/test/score0.png')
text = pytesseract.image_to_string(image)
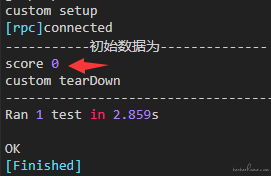
print("-----------初始数据为--------------")
print(text)
识别结果如下:
知识点:
① G.DEVICE.snapshot(),对当前设备画面进行截图并保存在内存中。
② crop_image(),局部截图的方法,需要传入俩个参数,一个是内存中的截图,就像这里的 screen,另一个是截取偏移 [x_min, y_min, x_max ,y_max]。
③ Image.open(),用来直接读取给定路径指向的图片
④ image_to_string(),用来解析图片中的文字
4.识别验证码
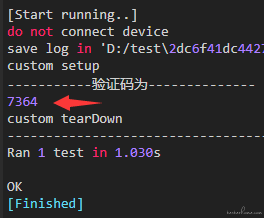
以下述验证码截图为例,该截图的保存路径为 D:/test/7364.jpg :

识别方式和结果如下:
# 识别验证码
image2 = Image.open(r'D:/test/7364.jpg')
text2 = pytesseract.image_to_string(image2)
print("-----------验证码为--------------")
print(text2)
log("验证码为:"+text2)
5.识别中文文字
识别中文的方法和识别数字与英文基本一致,但比较特别的是,我们需要在 image_to_string() 方法中指定中文的语言参数(示例代码中指定了简体中文来识别截图):

# 识别中文
image3 = Image.open(r'D:/test/3.png')
text3 = pytesseract.image_to_string(image3,lang='chi_sim')
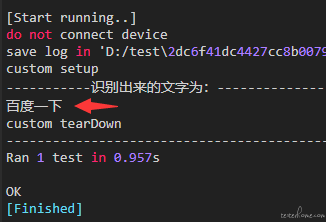
print("-----------识别出来的文字为:--------------")
print(text3)
log("识别出来的文字为:"+text3)
Airtest 官网:airtest.netease.com/
Airtest 教程官网:airtest.doc.io.netease.com/
搭建企业私有云服务:airlab.163.com/b2b
