
移动测试开发 Tidb 简介与应用实践
背景
当 mysql 的一个大表总数达上亿时,mysql 性能变的很差,且新增或修改字段、索引也需要花费很长时间,至少十几个小时。这种情况,一般的做法是分库分表,这种方法需要业务层根据规则,物理分库分表,比如按照时间分表,业务代码需要兼容。Tidb 是分布式 newsql 数据库,兼容了大部分 mysql 协议和操作,业务不需要调整,数据库性能也能保证。
Tidb 介绍
1.开源分布式的关系型数据库
TiDB 是开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案
2.整体架构
要深入了解 TiDB 的水平扩展和高可用特点,需要了解 TiDB 的整体架构。TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件。
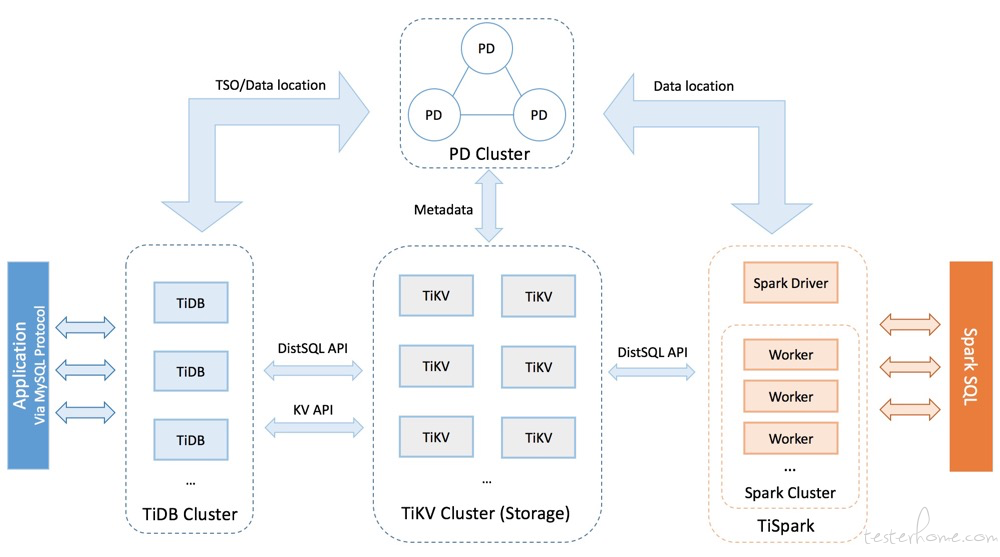
2.1.TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址。
2.2.PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
2.3.TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
2.4.TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
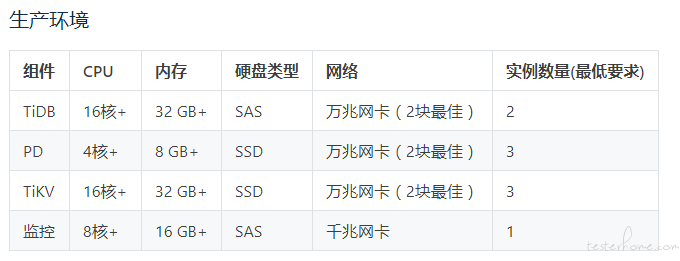
3.环境部署
Linux 操作系统平台建议为 CentOS7.3 及以上,同时也支持其他主流的 Linux 操作系统环境。
硬盘至少是 SSD 的机器,SAS 盘不行,推荐 pcie。
部署一套集群至少需要 5 台机器,2TiDB,3TikV,PD 可以和 TiDB 部署在同服务器上。
Tidb 优势
1.水平弹性无限制扩展
分布式的 TiDB 可随着你的数据增长而无缝地水平扩展,只需要通过增加更多的机器来满足业务增长需要,应用层可以不用关心存储的容量和吞吐。对比 mysql,需要 lvm 辅助磁盘扩容。
2.故障自恢复及异地多活
TiDB 使用多副本进行数据存储,并依赖业界最先进的 Raft 多数派选举算法确保数据 100% 强一致性和高可用。副本可跨地域部署在不同的数据中心,主副本故障时自动切换,无需人工介入,自动保障业务的连续性,实现真正意义上的异地多活。
3.一致性的分布式事务
可以把 TiDB 想象成一个单机的 RDBMS,ACID 事务可以在多节点间进行,无需担心一致性问题。 TiDB 对业务没有任何侵入性,是传统的数据库中间件、数据库分库分表等优雅的替换方案。
4.高度兼容 MySQL,零成本迁移
TiDB 的通讯协议与 MySQL 高度兼容,你可以轻松地像使用单机数据库一样,用 TiDB 替换 MySQL 来支持你的业务,而几乎无需修改代码。 MySQL 的客户端管理工具及社区所有的周边工具都可直接接入,极大降低学习和使用成本。
总之,迁移方便,不用分库分表,逻辑不用做兼容处理,程序调用也无需处理,mysql 的客户端工具正常使用。
5.更优的性能优势
TiDB 根据存储、网络、距离等因素,动态进行负载均衡调整,以保证更优的读写性能。TiDB 在大数据量下复杂查询方面,相比 MySQL 有绝对的性能优势。
5.1 大表建立索引快
5.2 大表修改列表快,比如加列,修改列属性
Mysql 大表建立索引和修改表需要花费大量的时间。
Tidb 的应用实践
在实际使用 tidb 过程中,总结了一下应用过程中的一些注意事项,比如和 mysql 的不同点,性能优化,优化工具等。
1.去掉自增 id
在传统的关系型数据库中,开发者经常会依赖自增 ID 来作为 PRIMARY KEY,但是其实大多数场景大家想要的只是一个不重复的 ID 而已,至于是不是自增其实无所谓,但是这个对于分布式数据库来说是不推荐的,随着插入的压力增大,会在这张表的尾部 Region 形成热点,而且这个热点并没有办法分散到多台机器。TiDB 在 GA 的版本中会对非自增 ID 主键进行优化,让 insert workload 尽可能分散。
建议:
如果业务没有必要使用单调递增 ID 作为主键,就别用,使用真正有意义的列作为主键(一般来说,例如:邮箱、用户名等)
可以使用分布式 id 生成算法生成唯一 key,具体方法可以参考上一篇文章 “基于 python 的分布式 id 生成算法实现”。
2.数据表的修改操作单一
创建完成一张数据表后,修改操作非常困难,有很多限制条件,可能也和分布式相关,不允许同时操作多个列,建议最好就把表的结构定义好,修改不要太频繁。
不支持同时创建多个索引
不支持同时创建多个列
不支持删除主键列或索引列
不支持修改索引
一次只能修改一列
3.版本问题
TiDB 一直在持续发展优化中,有些低版本的会存在一些问题,在应用过程中,发现 3.0 这个版本有如下问题:
插入主键重复的数据,一般情况下是会报字段重复,没有插入成功的错误。但这个版本不会报错。
索引长度没有限制,可以建很长字段的索引,这样会有性能问题。
升级至 3.1 版本后,以上 2 个问题都解决了。
4.避免反向筛选查询问题
反向筛选在所有关系型数据库里基本都是全表扫,not in,!=,%%,这些反向筛选操作用不到索引,均是全表扫。
不论在哪个集群反向筛选都是不允许的,会影响集群的 io,导致集群性能抖动,业务一定要极力避免全表扫。
5.大表的热点问题
在 TiDB 中新建一个表后,默认会单独切分出 1 个 Region 来存储这个表的数据,这个默认行为由配置文件中的 split-table 控制。当这个 Region 中的数据超过默认 Region 大小限制后,这个 Region 会开始分裂成 2 个 Region。
上述情况中,如果在新建的表上发生大批量写入,则会造成写热点,因为开始只有一个 Region,所有的写请求都发生在该 Region 所在的那台 TiKV 上,这个阶段属于表 Region 的预热阶段。
为解决上述场景中的热点问题,TiDB 引入了预切分 Region 的功能,即可以根据指定的参数,预先为某个表切分出多个 Region,并打散到各个 TiKV 上去。根据 PK,分为 2 种情况:
PK 是 int 类型
本业务写入是在正数范围内完全离散,在 Int64 空间内提前将表切散为 128 个 Region,语句如下:
SPLIT TABLE file_HOTSPOT BETWEEN (0) AND (9223372036854775807) REGIONS 128;
切分完成以后,可以通过 SHOW TABLE file_hotspot REGIONS; 语句查看打散的情况,如果 SCATTERING 列值全部为 0,代表调度成功。
PK 非 int 类型或没有 PK
对于 PK 非整数或没有 PK 的表,TiDB 会使用一个隐式的自增 rowid,大量 INSERT 时会把数据集中写入单个 Region,造成写入热点。
通过设置 SHARD_ROW_ID_BITS,可以把 rowid 打散写入多个不同的 Region,缓解写入热点问题。但是设置的过大会造成 RPC 请求数放大,增加 CPU 和网络开销。配合 pre_split_regions 一起使用,用来在建表成功后就开始预均匀切分 2pre_split_regions 个 Region。
pre_split_regions 必须小于等于 shard_row_id_bits。语句如下,带上 2 个优化参数
shard_row_id_bits=4 pre_split_regions=3:
create table t (a int, b int,index idx1(a)) shard_row_id_bits = 4 pre_split_regions=2;
●SHARD_ROW_ID_BITS = 4 表示 tidb_rowid 的值会随机分布成 16(16=24)个范围区间。
●pre_split_regions=3 表示建完表后提前 split 出 8 (23) 个 region。
在表 t 开始写入后,数据写入到提前 split 好的 8 个 region 中,这样也避免了刚开始建表完后因为只有一个 region 而存在的写热点问题。
注:针对 PK 为 int 类型的表增加这 2 个参数,回报如下错误。

6.单条记录大小限制
有个表的有个字段类型是 longblob,longblob 的最大为 4G,测试过程中发现最大是 6M,大于 6M 的内容插入不进去,查看文档说明后发现这是系统限制。
单条 KV entry 不超过 6MB
KV entry 的总条数不超过 30w
KV entry 的总大小不超过 100MB
单个事务包含的 SQL 语句不超过 5000 条(默认)
7.数据容灾
TIDB 副本建议是 3 个或以上,满足容灾需求,不需要数据双写,可以在 mysql 做数据定是备份。
如果上游操作,比如删除一个数据库,会导致副本的数据都丢失,可以做数据备份。
8.备份与恢复问题
tidb 的 br 物理备份,要求恢复时要全新集群(集群内不能有任何数据),目前业务这里没有恢复用的机器,还无法提供数据恢复。
9.索引长度的问题
3.0.6 版本加入了索引合法性创建检查。tidb 索引最大长度是 3072byte,utf8m64 字符集下 varchar 是 4 字节的,所以支持的最大索引长度是 768。
建立索引时,字段 varchar 太长,可以考虑换成对应的 md5 值。
10.支持 Grafana
Grafana 是一款开源监控显示软件,对数据库集群的各项指标进行可视化展现,Grafana 支持 Mysql 协议,也就支持 TiDB 数据源。将数据通过 Grafana 展示,不仅能够直观的看到数据的变动趋势,发现数据背后的规律,同时还能帮助做服务监控。
①增加 TiDB 数据源
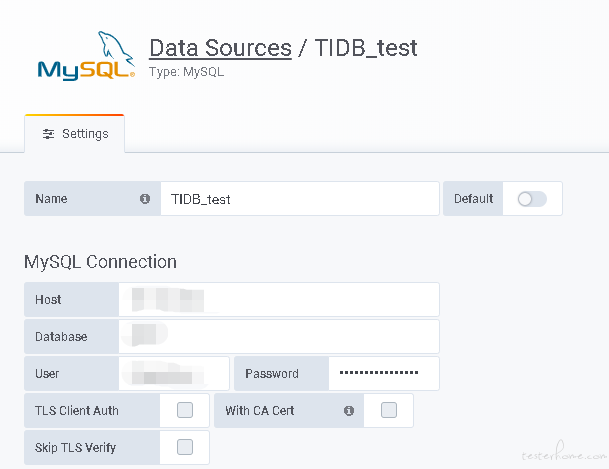
②数据展示
总结
分布式 TiDB 是 Mysql 分库分表的更好的替代方案,其有诸多优点,能够支持水平弹性扩容,兼容大部分 Mysql 协议,零成本迁移,支持各类 Mysql 操作工具,天生的容灾特性等。但是,有优势相对也有牺牲,搭建 TiDB 的生产环境要求比较高,部署一套集群至少需要 5 台高性能机器。
TiDB 这款产品在快速发展中,在实践过程中,会遇到各种问题,本文总结了 10 个相关问题和解决优化方法,旨在能够更好的帮助新手上手。
据了解,各大公司已经相继搭建和使用了 TiDB 集群,使用比较广泛,大家可以放心的将 TiDB 逐渐应用到需要的业务中。