
移动测试开发 Real Distributed APEX
背景
Google DeepMind 开源的强化学习库 tf2rl(https://github.com/keiohta/tf2rloff-policy 算法主要是使用 APEX 作为分布式训练的算法和框架支撑。)涵盖了几乎所有主流算法。其中
但是 APEX 的框架仍然是单机版本的多 explorer 模式,无法扩展到跨机器的 Real Distributed 模式,跨机器的目的是打破单一机器上的资源瓶颈,创造更多的 Actor。
强化学习收敛速度的瓶颈主要是 Actor 产生样本的速率,openai 的 env 里,由于是模拟环境,单 actor 能达到每秒上百个样本。公司中的项目几乎不可能达到这种速率,所以增加 Actor 的数量是提高收敛速度的重要手段,那么我们就需要实现跨机器的分布式强化学习。
APEX
apex 的框架结构比较简单,可以套用任何 off-policy 的算法,涵盖离散动作空间算法 DQN (including DDQN, Prior. DQN, Duel. DQN, Distrib. DQN, Noisy DQN),也包括处理连续动作空间的策略梯度算法,例如 DDPG(including TD3, BiResDDPG),SAC。
框架图:
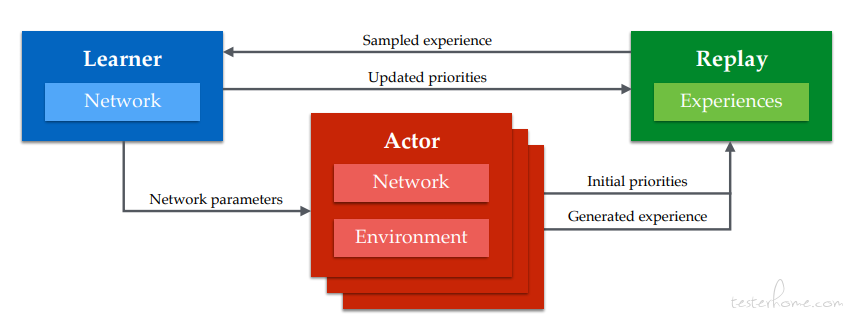
代码框架图:
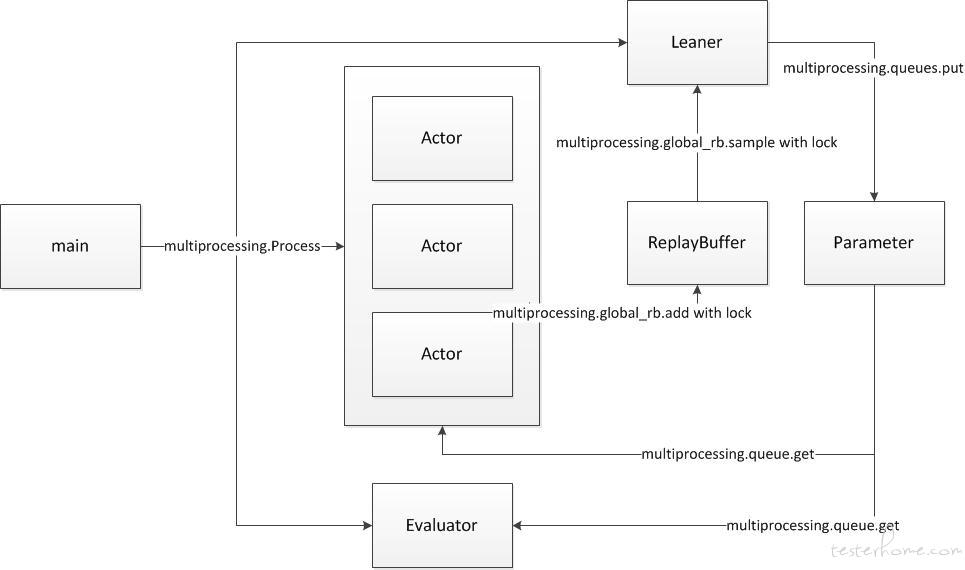
从代码框架中可以看出:
1.multiprocessing.Process 启动所有角色的节点
2.样本通过 multiprocessing 的跨进程对象 global_rb 来修改,因此使用跨进程锁 Lock
3.参数同步使用 multiprocessing 里的 Queue 通信,每个 Actor 分配一个独占的 Queue
APEX_Distributed
了解了 APEX 的代码结构后,如何修改就变的简单了,我们只要用分布式系统的常用方法替换掉进程间通信的方式即可。可以使用的中间件,例如消息队列、数据库都可以。
360 质量工程部采用的是 redis 的 pubsub 订阅消息队列以及数据结构,消息订阅松散式的结构可能会丢失数据(例如订阅早启动问题),但是对于长时间的运行影响很小。
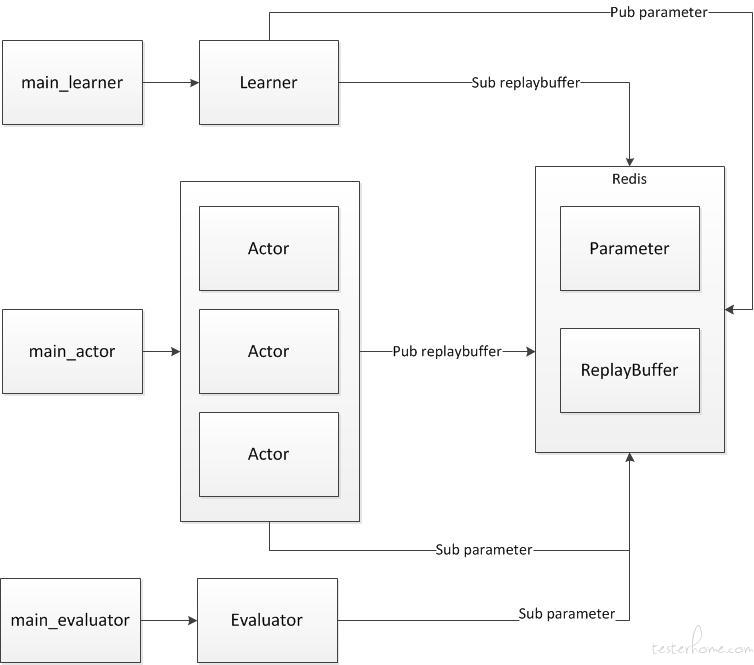
其他分布式训练框架
阿里开源的 EasyRL 也是一个选择,但是考虑到更新和维护的及时程度,所以没有使用,其主要改进点是实现了基于 tensorflow distributed 的多 Learner 学习节点。
并且其中列出了与很多其他开源框架的对比,有兴趣可以参考https://github.com/alibaba/EasyRL
*EasyRL 的结构图: *
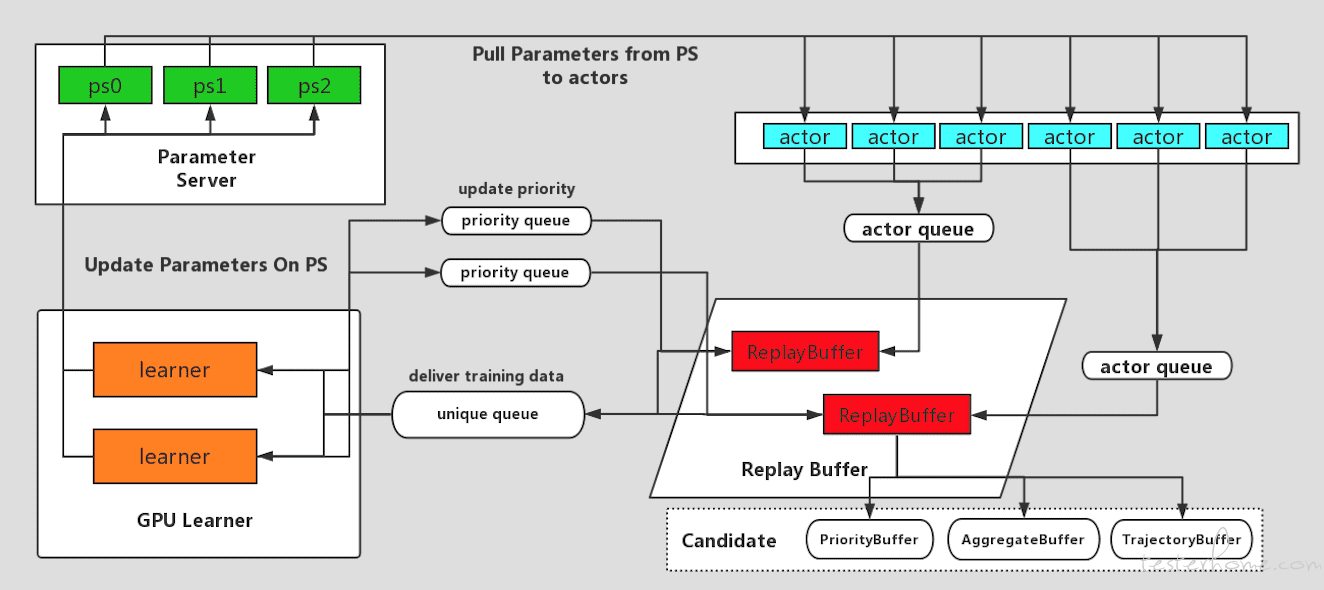
1.EasyRL 使用的是 tensorflow 的 PS 架构,实现的参数共享,不依赖其他中间件
2.多 Learner 的学习节点,提高并行学习的速度
Real Distributed APEX 也可以使用 tensorflow 的 ParameterServerStrategy 的模式,实现多 Learner 的并发学习。
结果预期
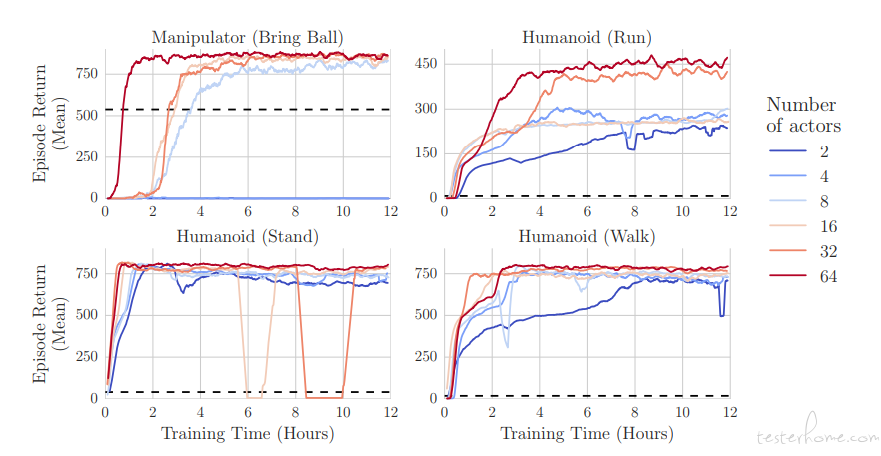
从 APEX 的 actor 数量对于收敛速度的影响图可以看出,增加 actor 的数量,会对提高训练收敛速度有显著的收益。
计划
本文并没有列出具体的代码,后续可能会公开代码方案(其实并不复杂)
改进框架只是第一步,后续我们会继续探索使用强化学习实现类人的智能测试,期望有兴趣的同学一起加入进来!