
「原创声明:保留所有权利,禁止转载」
在性能测试中,测试数据一般都是单独存在日志文件中,呈现出来的都是一些冰冷的数据,比如:
~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~ JSON ~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~
> {
> ① . "rt":186,
> ① . "total":3000,
> ① . "qps":160.90075820012837,
> ① . "excuteTotal":0,
> ① . "failRate":0.0,
> ① . "threads":30,
> ① . "startTime":"2020-02-18 21:30:15",
> ① . "endTime":"2020-02-18 21:31:15",
> ① . "errorRate":0.0,
> ① . "desc":"测试登录接口2020-02-18"
> }
~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~ JSON ~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~~☢~
虽然会把结果存在数据库中,结束之后也会通过Python的plotly进行图形化处理,如下:
- python plotly 处理接口性能测试数据方法封装
- 利用 Python+plotly 制作接口请求时间的 violin 图表
- Python2.7 使用 plotly 绘制本地散点图和折线图实例
- 利用 python+plotly 制作接口响应时间 Distplot 图表
但是在实际工作中这样很费劲,因为极大可能测试数据都是在服务器上,如果在服务器上执行Groovy压测脚本再去调用Python脚本会比较麻烦,而且调试结果和查看内容也得借助测试服务文件映射来查看。
综上所诉,最好能找一个 Groovy 兼容、纯文本形式的结果展示图,这样可以在shell界面或者直接在邮件中发送更加直观的测试数据,经过尝试,我搞定了,先放图:
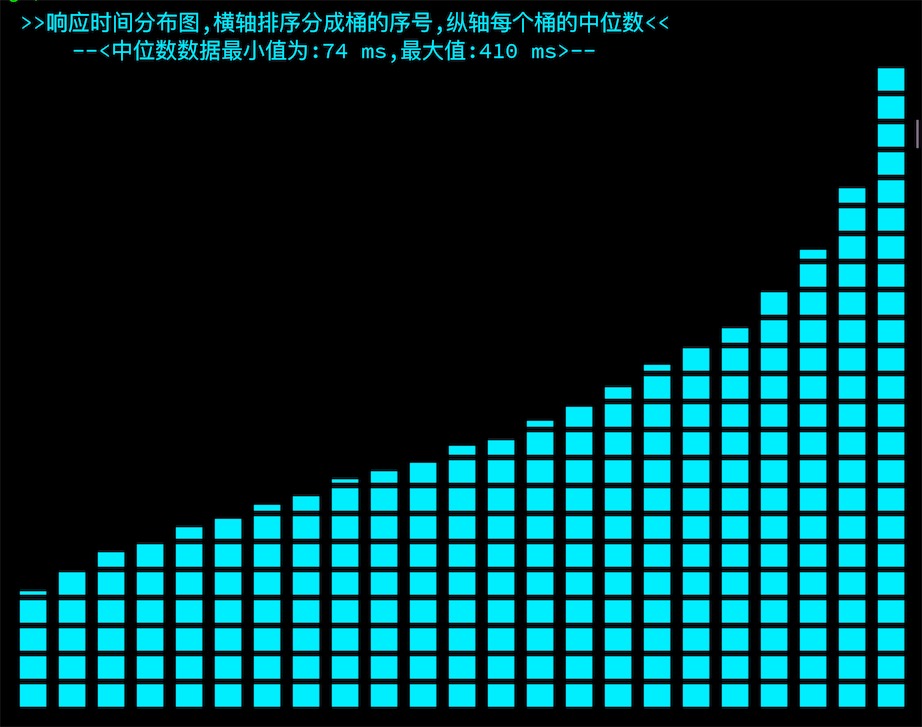
利用了特殊字符里面有一个全黑的正方形,分别有 8 等分的不同高度的横线,如下:
public static final String[] PERCENT = {" ", "▁", "▂", "▃", "▄", "▅", "▅", "▇", "█"};
思路如下:先对测试数据排序,平均分成 23 个桶,去每个桶的中位数作为代表。以最大的中位数为 800,然后计算各个中位数对应的黑格数,剩下的填充空格,再将生成的string[]里面的每一个string对象转换成char[],实际操作中还是string[],只是每一个的length都等于 1。这样我们就得到了一个二维数组string[][],但是这是横向的,我们需要竖排的,在对二维数组进行坐标转换就得到了最终的二维数组string[][],按照固定规则拼接StringBuffer即可。
下面是代码省去了测试数据的获取:
/**
* 将性能测试数据图表展示
*
* <p>
* 将数据排序,然后按照循序分桶,选择桶中中位数作代码,通过二维数组转化成柱状图
* </p>
*
* @param data 性能测试数据,也可以其他统计数据
* @return
*/
public static String statistics(List<Integer> data) {
int size = data.size();
int[] ints = range(1, BUCKET_SIZE + 1).map(x -> data.get(size * x / BUCKET_SIZE - size / BUCKET_SIZE / 2)).toArray();
int largest = ints[BUCKET_SIZE - 1];
String[][] map = Arrays.asList(ArrayUtils.toObject(ints)).stream().map(x -> getPercent(x, largest, BUCKET_SIZE)).collect(toList()).toArray(new String[BUCKET_SIZE][BUCKET_SIZE]);
String[][] result = new String[BUCKET_SIZE][BUCKET_SIZE];
/*将二维数组反转成竖排*/
for (int i = 0; i < BUCKET_SIZE; i++) {
for (int j = 0; j < BUCKET_SIZE; j++) {
result[i][j] = getManyString(map[j][BUCKET_SIZE - 1 - i], 2) + SPACE_1;
}
}
StringBuffer table = new StringBuffer(LINE + TAB + ">>响应时间分布图,横轴排序分成桶的序号,纵轴每个桶的中位数<<" + LINE + TAB + TAB + "--<中位数数据最小值为:" + ints[0] + " ms,最大值:" + ints[BUCKET_SIZE - 1] + " ms>--" + LINE);
for (int i = 0; i < BUCKET_SIZE; i++) {
table.append(TAB + Arrays.asList(result[i]).stream().collect(Collectors.joining()) + LINE);
}
return table.toString();
}
/**
* 将数据转化成string数组
*
* @param part 数据
* @param total 基准数据,默认最大的中位数
* @param length
* @return
*/
public static String[] getPercent(int part, int total, int length) {
int i = part * 8 * length / total;
int prefix = i / 8;
int suffix = i % 8;
String s = getManyString(PERCENT[8], prefix) + (prefix == length ? EMPTY : PERCENT[suffix] + getManyString(SPACE_1, length - prefix - 1));
return s.split(EMPTY);
}
不要问为啥选 23,问就是计算式计算 23 是被除数时比较快。
- 郑重声明:文章首发于公众号 “FunTester”,禁止第三方(腾讯云除外)转载、发表。
技术类文章精选
- Linux 性能监控软件 netdata 中文汉化版
- 性能测试框架第三版
- 如何在 Linux 命令行界面愉快进行性能测试
- 图解 HTTP 脑图
- 将 swagger 文档自动变成测试代码
- Selenium 4.0 Alpha 更新日志
- Selenium 4.0 Alpha 更新实践
- 如何统一接口测试的功能、自动化和性能测试用例
非技术文章精选

TesterHome 为用户提供「保留所有权利,禁止转载」的选项。
除非获得原作者的单独授权,任何第三方不得转载标注了「原创声明:保留所有权利,禁止转载」的内容,否则均视为侵权。
具体请参见TesterHome 知识产权保护协议。
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
暂无回复。