测试驿栈-由浅入深学性能 性能测试连载 (42)-记一次令人遗憾的 cpu 问题定位
概述
最近群里有一个小伙伴提了一个性能问题。大概描述是这样的。它的服务器 cpu 过载了。过载到什么程度呢?8 个逻辑 cpu 一分钟内平均负载最高达到了 529


平均负载解释
系统处于可运行状态和不可中断状态的平均进程数,平均活跃进程数。包括正在使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程
可运行状态进程:正在使用 CPU 或者正在等待 CPU 的进程,处于 R 状态(Running 或 Runnable)的进程
不可中断状态的进程:正处于内核态关键流程中的进程,不可打断。比如等待 IO
分析
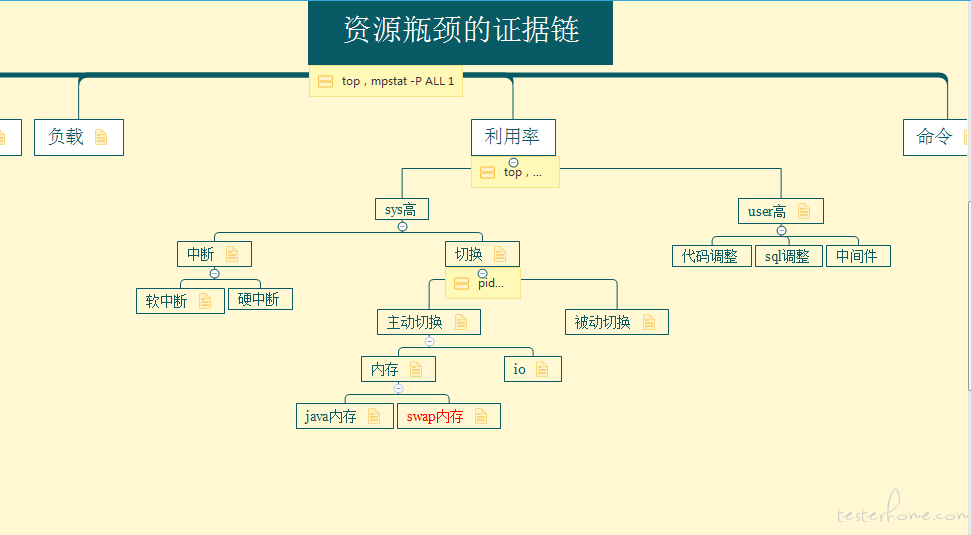
从这位小伙伴提供的两张截图可以看出
1:八个逻辑 cpu 的利用率都是 100%,而且 70% 左右的 cpu 时间消耗在了内核态(sy),几乎没有空闲
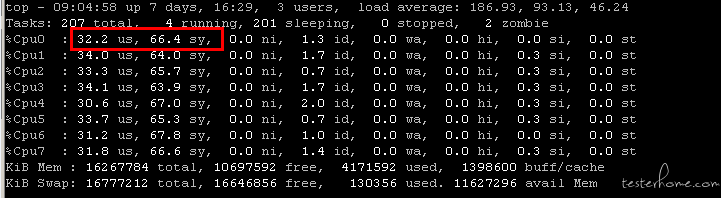
2:负载严重过高,估计有大量的进程堵在队列里面
针对负载过高的问题,我让他执行了一下 vmstat 1 10
果然,运行队列有 900 多。。。而且疯狂上下文切换(cs 严重超高)
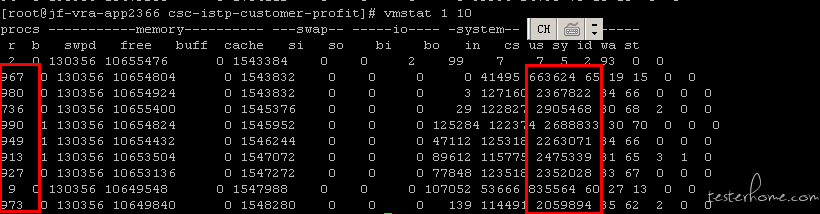
更奇怪的是,在堵塞如此严重的情况下,还安排了其它进程来插队
如下图,一个监控的进程优先级远远的排在了阻塞进程的前面。等于是堵车已经堵的昏天黑地了,又有一辆车强行加塞挤到我的前面。
定位问题
既然已经明确是进程阻塞的问题,那么就可以通过 dump 的方式来找到问题的根源
执行 bash show-busy-java-threads观察堆栈结果。映入眼帘的全是 runnable
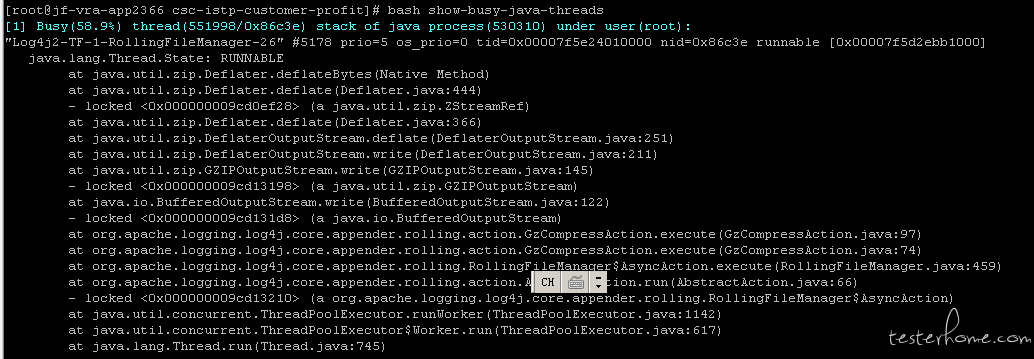
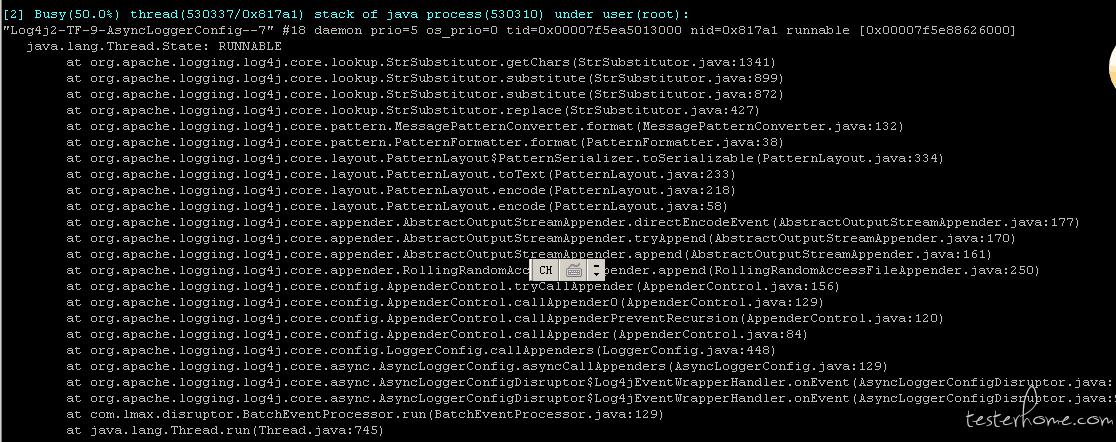
这个已经很明显了,疯狂的日志写入导致了线程的堵塞。于是让这位小伙伴检查了一下日志输出。果然是日志全开
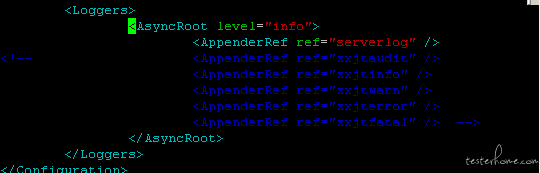
再观察其它的线程日志
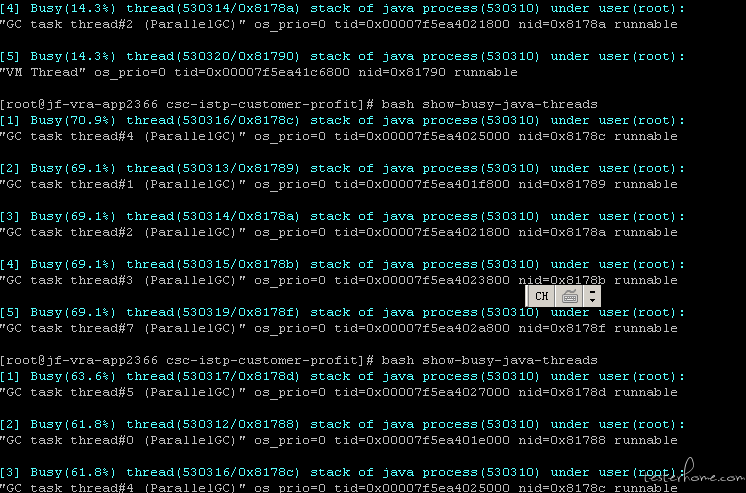
这全是 GC 导致的线程阻塞了。可能是 jvm 内存不足,也可能是内存分配比例有问题
后记
其实到现在为止定位的都是用户空间的问题,还有很大一部分内核空间的问题没有定位到。但是遗憾的是,这位小伙伴似乎已经觉得问题都发现了,就再也没有搭理过我。。。
本来还想再让他看监听一下系统调用呢,实在是可惜了
总结一下
分析 cpu 问题先看负载,再看利用率,利用率分用户空间和内核空间。用户空间就去线程 dump,内核空间就去监控系统调用。大致如下图