
背景:最近公司进行了很多 ES 的压测,那么压测时可以监控哪些指标呢。下面进行了总结。
一、工具:Kibana(Kibana 是一个开源的分析和可视化平台,设计用于和 Elasticsearch 一起工作。)
节点方面的监控:
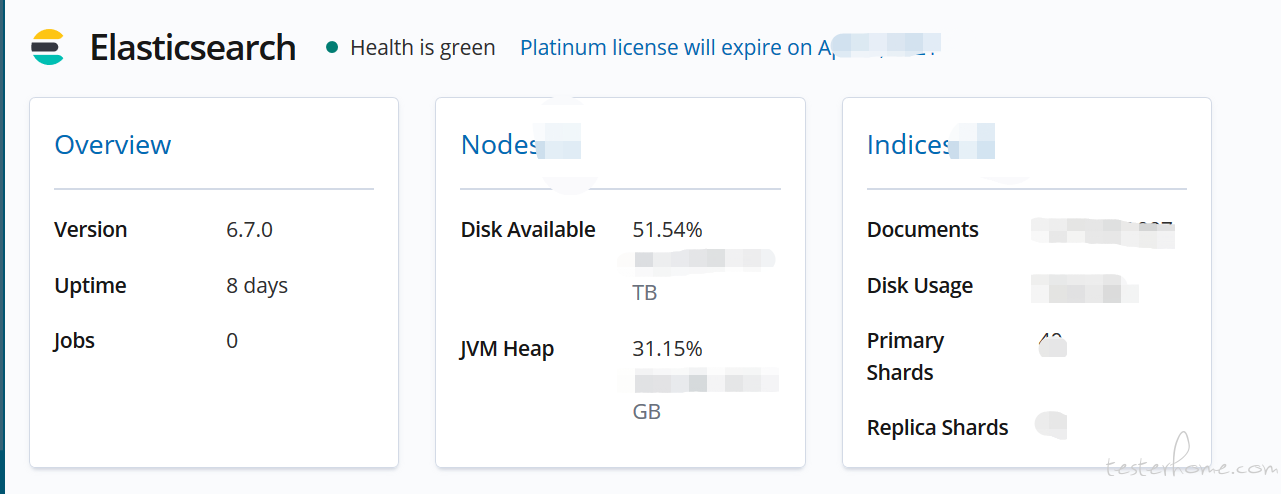
查询和搜索的吞吐率和速度
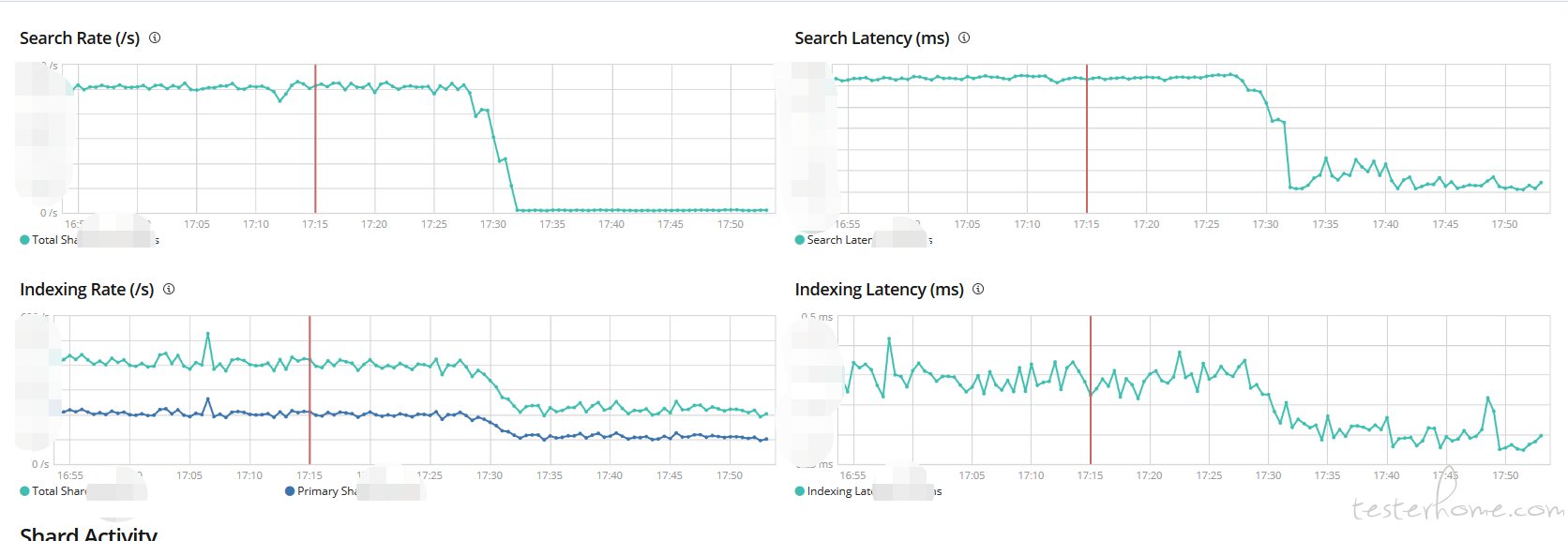
搜索性能指标的要点:
Query load:监控当前正在进行的查询数量可以让您了解群集在任何特定时刻处理的请求数量。您可能还想监视搜索线程池队列的大小,稍后我们将在本文中进一步解释链接。
Query latency: 虽然 Elasticsearch 没有明确提供此度量标准,但监控工具可以帮助您使用可用的指标来计算平均查询延迟,方法是以定期查询总查询次数和总经过时间。 如果延迟超过阈值,则设置警报,如果触发,请查找潜在的资源瓶颈,或调查是否需要优化查询。
Fetch latency: 搜索过程的第二部分,即提取阶段通常比查询阶段要少得多的时间。 如果您注意到这一指标不断增加,可能是磁盘性能不好、highlighting 影响、requesting too many results 的原因。
索引指标:
索引性能指标的要点:
Indexing latency: Elasticsearch 不会直接公开此特定指标,但是监控工具可以帮助您从可用的 index_total 和 index_time_in_millis 指标计算平均索引延迟。 如果您注意到延迟增加,您可能会一次尝试索引太多的文档(Elasticsearch 的文档建议从 5 到 15 兆字节的批量索引大小开始,并缓慢增加)。
如果您计划索引大量文档,并且不需要立即可用于搜索。则可以通过减少刷新频率来优化。索引设置 API 使您能够暂时禁用刷新间隔:
curl -XPUT :9200//_settings -d '{
"index" : {
"refresh_interval" : "-1"
}
}'
完成索引后,您可以恢复为默认值 “1s”
Flush latency: 在 flush 完成之前,数据不会被固化到磁盘中。因此追踪 flush latency 很有用。比如我们看到这个指标稳步增长,表明磁盘性能不好。这个问题将最终导致无法向索引添加新的数据。
可以尝试降低 index.translog.flush_threshold_size。这个设置决定 translog 的最大值(在 flush 被触发前)
二、通过命令的方式可以查询一些指标

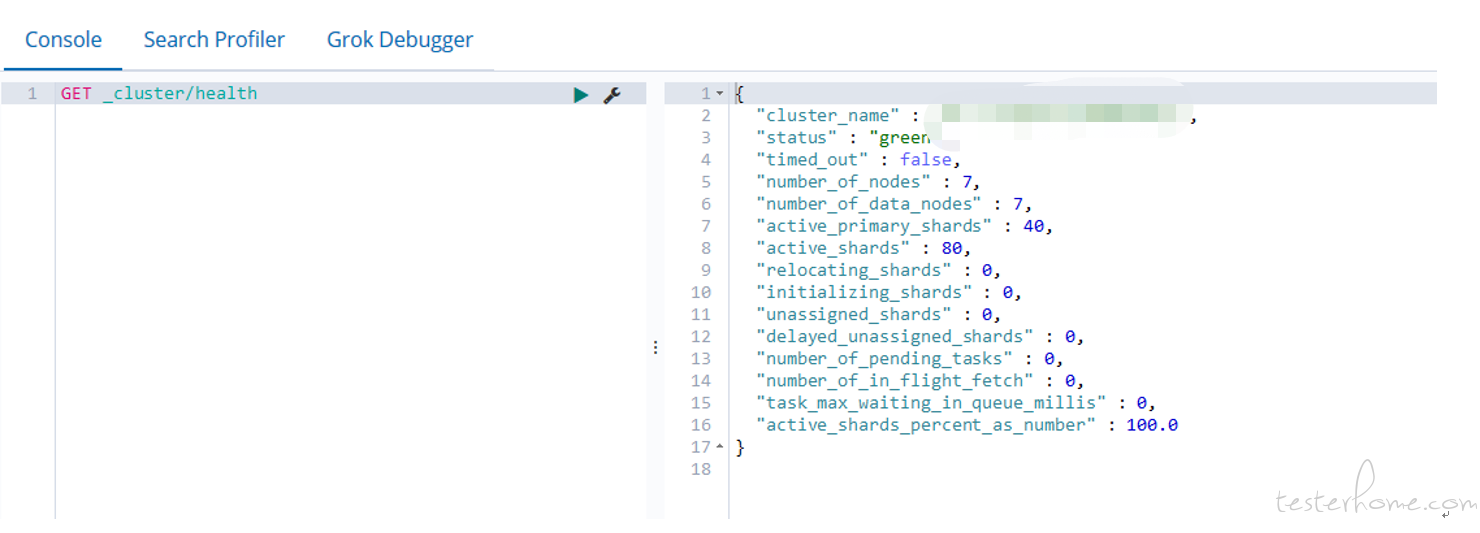
三、除了查看是否搜索慢或索引慢之外,还需要考虑 es 分片设置的是否合理 shard 设置的是否合理