
移动测试开发 如何从代码层提高产品质量
本文的主题是如何从代码层提高产品质量,目前基本的方法是通过静态代码扫描和二进制文件扫描,获取产品代码的漏洞,本文在此基础上,对获取的产品代码漏洞进行了深挖探索。
下面主要从 4 个方面说明。
1.产品代码漏洞检查的背景和方法
2.代码漏洞的搜索深挖技术
3.提高产品质量的方法
4.总结与展望
一、产品代码漏洞检查的背景和方法
① why-为什么要检查产品代码的漏洞
一般情况下,产品质量的问题多数与程序代码相关。比如银行软件出现漏洞,导致十几个客户信用卡被盗刷。2003 年阿丽亚娜 5 型火箭升空爆炸造成 5 亿美元的损失。由于电控系统的软件问题导致大面积停电事故,给交通,通信,居民生活造成严重影响等等,都是和产品代码相关。代码的漏洞检查与分析可以帮助用户从根源上减少 70%-80% 的产品崩溃和安全性问题。只有代码中的崩溃和安全缺陷得以及时消除,最终形成的产品才能具备较高的质量,有效降低整个产品风险。



② when-什么时候检查产品代码的漏洞
在产品开发测试发布过程中,流程越往后,漏洞造成的影响越大。漏洞发现的越早,修复成本越低。
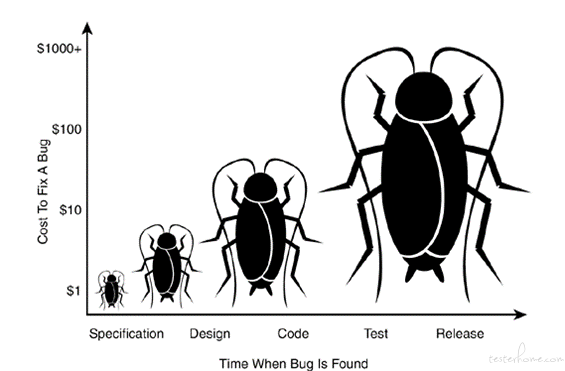
如下图中红色的曲线,横坐标是产品发布流程,纵坐标是修复缺陷成本,可以看出,在测试阶段,修复成本比较低,在产品发布之后,修复成本是成指数增长的。
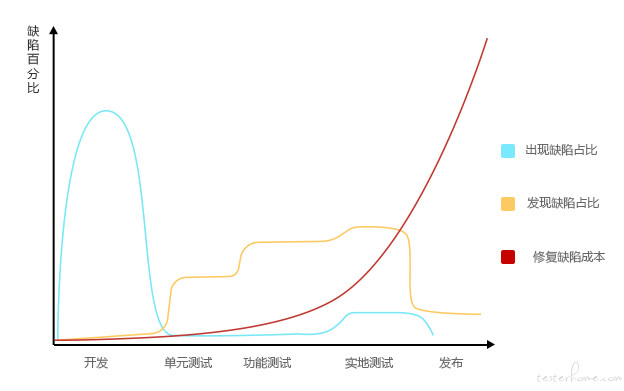
所以在产品测试阶段,最好把产品代码中的漏洞都检查出来。那怎么对产品代码的漏洞进行检查。
③ how-检查产品代码漏洞的方法
现阶段一般有 2 种方法,而且这 2 种方法我们团队已经实现了。
一种是源代码的漏洞扫描与检查,主要方法是对编码规范的检查,常见的编码规范有 4 类,分别是错误类,安全类,禁用类和建议类,具体内容详见下图。自定义代码规范的制定与实时更新,根据具体业务场景的代码规范的制定等等方法都能很好的检查出产品代码的漏洞。

另外一种是对二进制文件的漏洞扫描与检查,比如 google 提供的 veridex 工具,可以扫描非法 API 调用,该工具将非法 API 分了 3 类。

④ 深度挖掘产品代码漏洞的方法
通过上面介绍的 2 种方法,只能对特定代码或二进制进行检查,但是对产品,乃至整个公司的代码仓库,隐藏的 bug 却是惊人的。

此外,经过调研发现,国外也有类似的研究,NASA,microsoft 等机构已经利用代码搜索技术,发现了多个 0 日漏洞。
二、代码漏洞的搜索深挖技术
① 代码搜索的问题和挑战
主要是 6 个困难点,如下图所示。代码特征的确定,搜索速度慢,代码信息量太少,不好定位漏洞。代码入库非常缓慢,过滤条件不好兼容,数据量大,搜索数据量高达千万级代码文件。
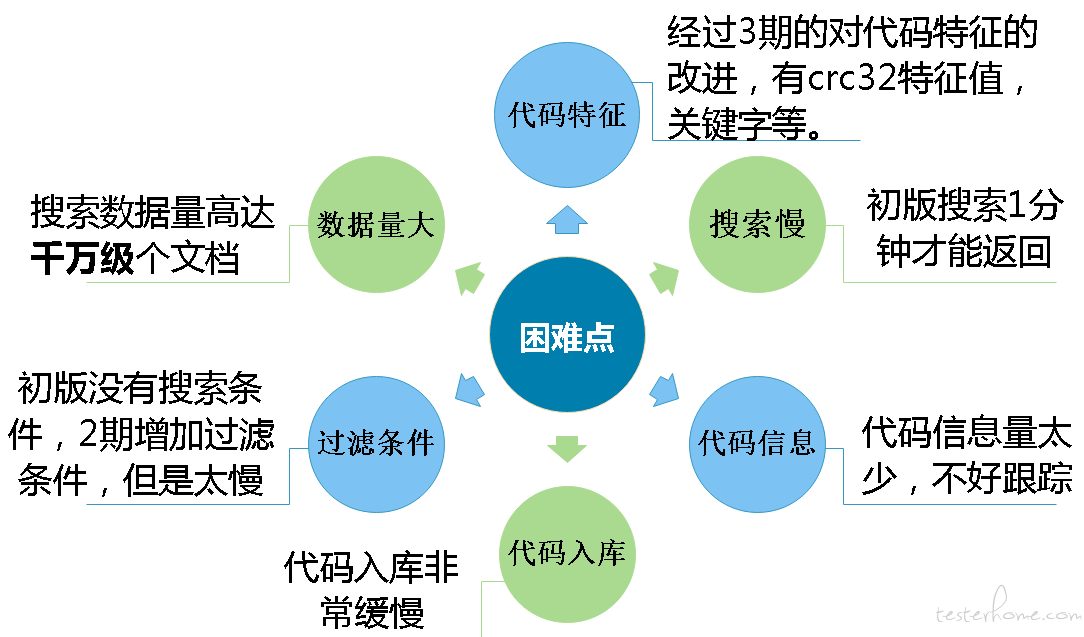
针对这些问题我们做了一序列的优化和改进。
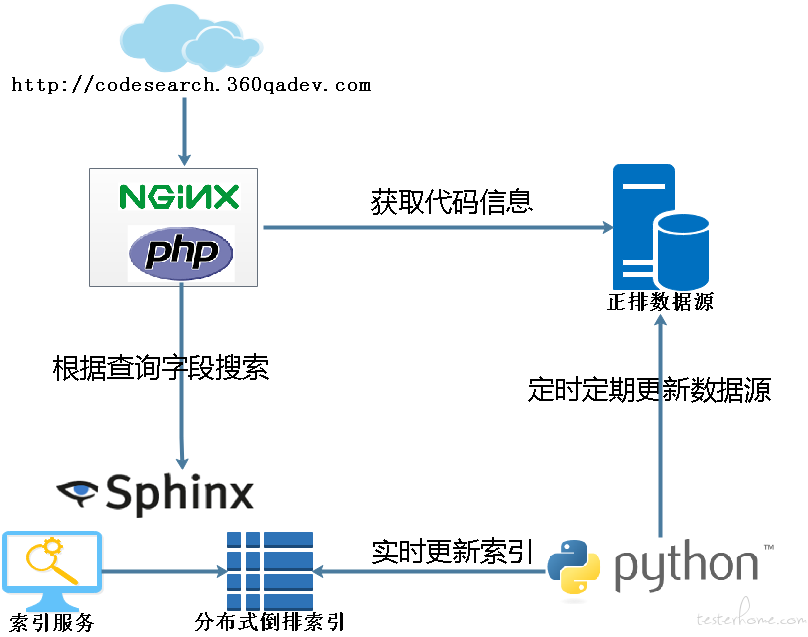
② 代码搜索的技术架构
主要是 5 部分,如下图所示。python 后台部分用于增量更新数据源信息和实时更新索引。正排数据源,主要采用 mysql 数据库,包括表结构的设计,索引和分表设计等。Sphinx 实时分布式索引,用于提供索引创建服务和搜索索引服务等。Php+nginx 服务端部分,为前端提供接口服务。前端部分,用于展示搜索结果和后台管理等。
③ 代码搜索的服务端
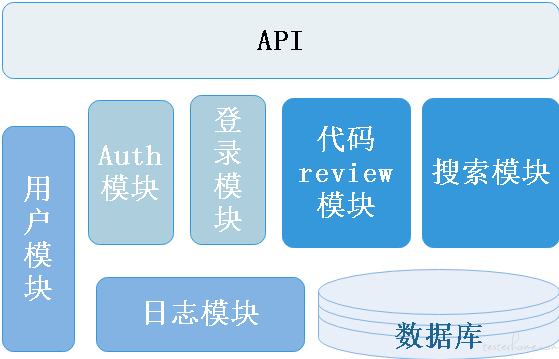
代码搜索的服务端为前端或其他系统提供 API 接口,一共有 6 大模块,包括搜索模型,登录模型,校验模型,用户模块,日志模块,代码 review 模块。数据库为上述 6 大模块提供数据支持。
④ 代码搜索的后台
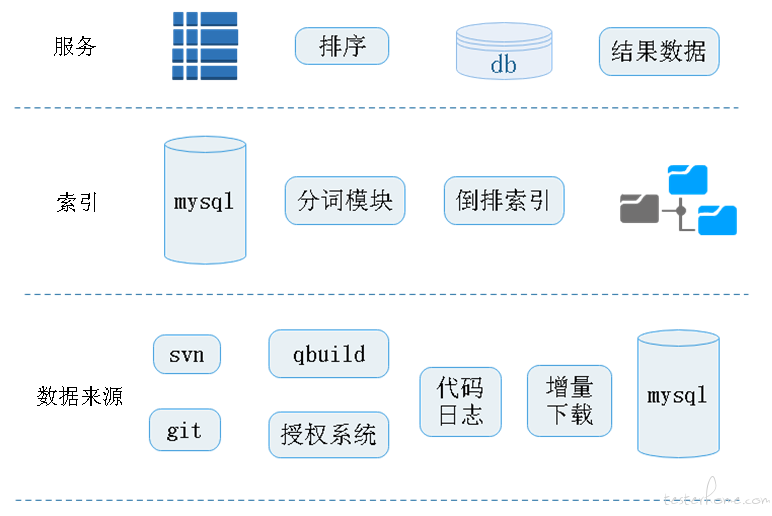
大致分为 3 层,最下面一层数据来源层,支持 svn 和 git 的代码仓库,来源包括 qbuild 系统和授权系统,获取代码日志,增量下载文件,最后存储在数据库中。
索引层主要是从数据源中获取文档信息,然后经过分词模型,倒排索引算法,将索引存储在文件系统中。服务层主要是 sphinx 索引工具提供的索引服务,通过排序,获取索引文档信息后,从正排数据库中拿到文档全部信息,返回结果数据。
⑤ 数据源增量入库方案
代码搜索的困难点之一的是数据源入库非常慢,针对这个问题,我们有如下的优化方案,数据源的增量入库方案。

主要是 8 个步骤,分别是从 qbuild 或授权系统获取代码地址,获取当前代码地址的提交日期,根据提交日期获取代码提交日志,通过解析日志,获取增量文件列表。然后每个文件进行下面的处理,先进行去重判断,然后下载该文件,再进行去重判断,存储在数据源中,经过分词工具,最终实时存储索引。这个过程比较长,但是分解到每一步,却比较容易实现,比如获取代码提交日志和代码文件下载,svn 对应的命令可以参考如下。
svn log -r {0} --xml -v "{1}" --username "{2}" --password "{3}" --non-interactive --no-auth-cache --trust-server-cert> {4} </br>
svn export -r {0} "{1}" "{2}" --force --username {3} --password "{4}" --non-interactive --no-auth-cache --trust-server-cert </br>
在数据源增量入库方案中,有一个很大的问题需要解决,就是重复的问题。可以看一下,对于 svn 有路径包含重复的问题,下面那个路径是包含上面那个路径的,上面那个路径将会被入库 2 次。
http://svn.example.com/svn/testxxx/111/222/333
http://svn.example.com/svn/testxxx/111
Git 也有相似的问题,分支重复,不同分支代码会有大量重复提交的记录。
http://git.example.com/root/11 分支:master
http://git.example.com/root/11 分支:v1.1
我们的去重方法是,针对 svn,利用模块 id+revision 的方式,对于 svn,同一个模块 id 下的 revison 是递增的,不会有重复问题。相应的,git 是通过仓库 id+ 提交 sha1 值去重的,对于同一个仓库,提交的 sha1 值是唯一的。
⑥ 实时分布式索引技术
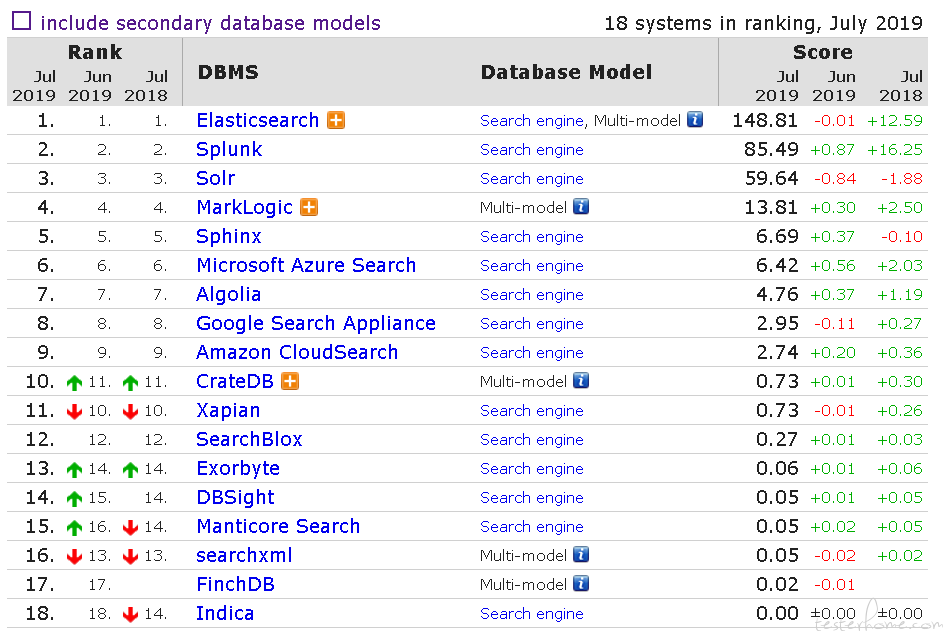
代码搜索系统遇到的另外一个困难是搜索太慢,为此我们引入了 sphinx 索引工具,为什么选择 sphinx 索引工具呢。该工具支持高达数十亿个文档,数 TB 的数据和每秒数千个查询。支持各种数据源,包括 xml,sql,python 等。支持结果的各种过滤聚合功能,快速高效的索引,应用场合广泛,比如维基百科,优酷土豆,github 等。下图是今年的索引工具的排行榜,可以看到 sphinx 排在第 5,受众范围广。
1.sphinx 工具使用
Sphinx 主要包括 3 个可用的工具,分别是 index 实时索引工具,主要是对数据源的数据进行倒排索引,并存储,使用命令如下,sphinx.conf 是 sphinx 的配置文件。
/usr/local/sphinx/bin/indexer -c sphinx.conf code
Searchd 搜索服务工具,php 可以通过 sphinx 扩展,访问该服务,使用命令如下。
/usr/local/sphinx/bin/searchd -c sphinx.conf&
Search 搜索工具,客户端搜索工具,可以用该工具测试索引的正确性,一般只是测试使用。
/usr/local/sphinx/bin/search -c sphinx.confmykeyword
可以看到这 3 个命令都用到了 sphinx 的配置文件,那么这个文件怎么配置。
2.sphinx 实时分布式的配置详情
一般情况下,最初会采用主索引和增量索引的方式,但是随着数据的增加,服务和运维都有压力,通过优化,我们最终采用实时分布式的方式。实时索引的好处有,代码索引无延时,没有额外的定时程序更新和合并索引服务,降低运维成本,提高搜索精确性和可靠性。分布式的好处有,资源利用率提高,搜索效率提高,搜索并发性提高等实时分布式的配置如下,第 1 个实时索引的配置,type 是 rt,也就是 realtime,path 表示该索引存储的位置,下面几行是字段的定义,rt_field 就是需要索引的字段,rt_attr_uint 和 rt_attr_timestamp 是索引字段的属性,一个是 int 类型,一个是时间戳类型。第 2 个配置是分布式配置,type 是 distributed,下面几行是分布式位置。第 3 个配置是索引服务配置,9312 接口是提供索引服务的,9306 是接收实时索引服务的,下面 2 行是日志位置。
indexcoderealtime
{
type = rt
path = user/local/sphinx/indexer/files/coderealtime
rt_field = content
rt_field = filename
rt_attr_uint = rpid
rt_attr_timestamp = cdate
}
indexcodedistributed
{
type = distributed
local = coderealtime
agent = localhost:9312:crt1
agent = localhost:9312:crt2
}
searchd
{
listen = 9312
listen = 9306:mysql41
log = /user/local/sphinx/indexer/logs/searchd.log
query_log = /user/local/sphinx/indexer/logs/query.log
}
3.代码搜索排序方法
代码搜索最重要的一个指标就是排序方法,本方案,主要从 3 个方面对代码结果进行排序,分别是词组评分,代码提交时间,和 BM25 算法。这 3 个指标中最重要的是 BM25 算法,下面简单的介绍该算法的实现方法,公式如下:
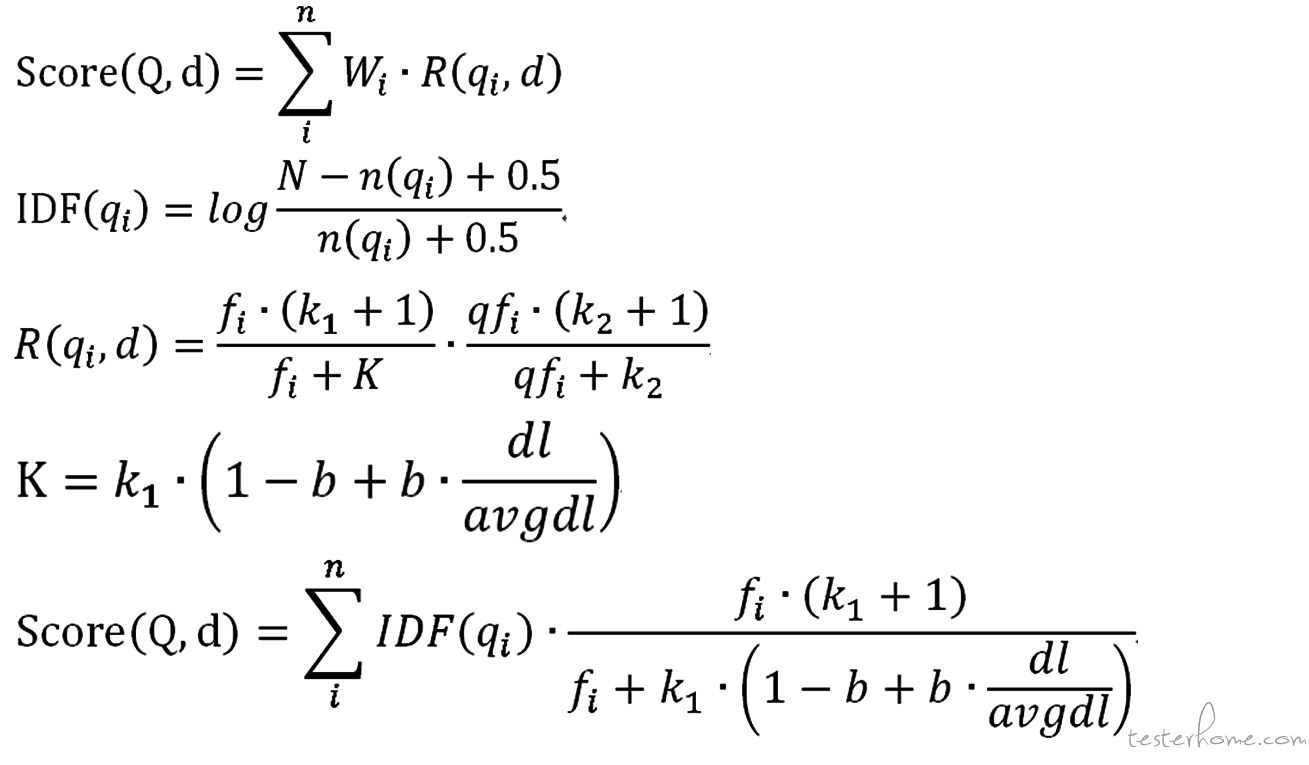
Score(Q,d) 是衡量某次 query 查询和文档的相关性计算公式,d 表示当前文档,Q 是 query 中所有的关键字集合,qi 是其中的某个关键词,n 是 Q 的长度,Wi 是这个词的权重,R(q,d) 是这个词和文档的权重。Wi 默认是 IDF 值,N 表示所有文档数,n(qi) 表示包含该关键词的文档数,0.5 是避免 n(qi) 为 0 的情况。大致的意思是关键词在所有文档中出现频率越多说明越普遍,就越不重要,权重越低。R(q,d) 是这个词和文档的权重,大致的意思是某个关键词在该篇文档出现的次数越多,说明越重要。
Wi 突出的全局的权重,R(q,d) 表示的局部权重。举个通俗的例子,在图书查找过程中,比如 [作者] 这个词,几乎在所有书中都会出现,所以他的权重很低,[人工智能] 这个词不常见,如果某个图书中经常提到人工智能这个词,大概率这本书再讲人工智能。BM25 算法通过统计的方法,就能对代码进行合理的排序。
三、提高产品质量的方法
如何利用代码搜索技术提高产品质量,主要是 2 种方法。
第 1 种方法是结合业务督促开发修复代码漏洞,一方面根据前面介绍的检查产品代码漏洞的 2 种方法,根据这些检查出来的漏洞进行深度搜索,将产品和公司代码库中隐藏的漏洞都修复了,去除产品隐患,另一方面结合业务,比如某个函数实现有漏洞,可以根据函数名进行搜索,查看函数调用的模块,避免代码漏洞的扩散。
第 2 种方法是对产品代码的敏感词的检查,比如代码审计系统的敏感词和禁用 api 的检查,文件签名系统的敏感签名信息的检查等。
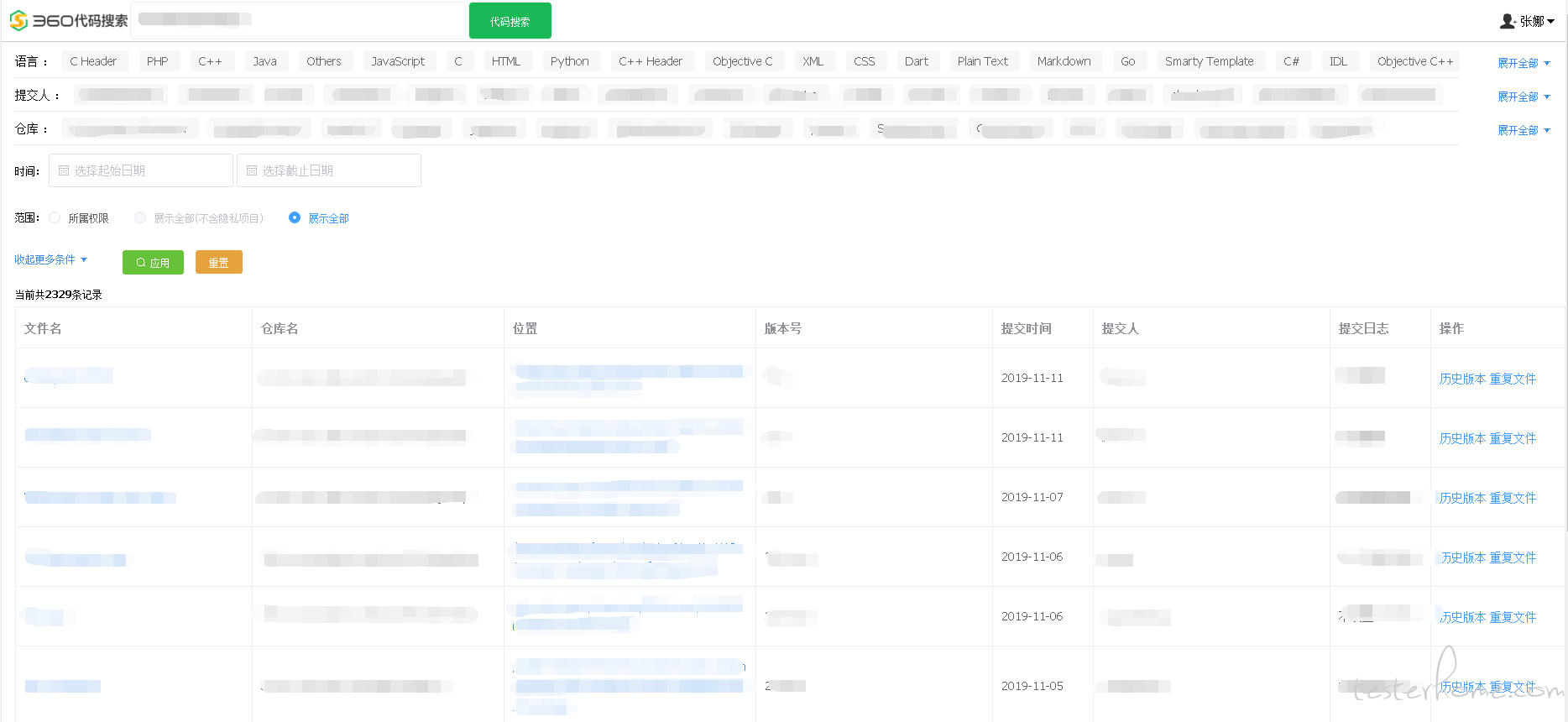
下面这个图是代码搜索的一个 demo,主要有 3 部分构成,最上面是搜索输入,左边是过滤条件,包括时间,代码语言,归属人,代码仓库。右边是搜索的结果,主要包括文件名,仓库名,文件位置,版本号,提交日期和归属人,测试人员可以根据仓库和归属人信息找到对应的开发负责人,进而督促修复漏洞。
四、总结与展望
本文主要从 3 个部分阐述了如何从代码层提高产品质量,第一部分是产品代码漏洞检查的背景和方法,主要讲了检查产品代码漏洞的 2 种方法,即源代码漏洞扫描与检查、二进制文件漏洞扫描与检查,但是这 2 种方法只能对特定项目的代码进行检查,隐藏的 bug 量是巨大的,从而引出第二部分,代码漏洞的搜索深挖技术。第二部分是本文的重点,展开讲了代码搜索的技术方案及实现细节,第三部分从 2 个方面说明了如何利用代码搜索技术提高产品质量。
代码搜索系统能够快速定位问题,通过对细节的不断探索,搜索速度显著提升,搜索排序质量提高了,本系统辅助优化了产品代码质量。接下来,我们将从 2 方面进一步优化,分别是代码推荐结合代码语义上下文和 AI 的方法,进一步提升代码推荐的精确度,以及函数式的代码推荐。