
移动测试开发 高性能高维向量的 KNN 搜索方案
背景
机器学习以及深度学习中经常会使用向量表示原始数据(例如图片、视频、自然语言中的 embedding 等),而且通过查询词(例如图片搜索、视频搜索、词向量空间近似计算等)计算 KNN 是强需求。
在此业务需求背景下产生了高性能高维向量 KNN 搜索方案。
KNN
KNN 算法(K 近邻法)是简单常用的监督学习方法,模型简单无需训练,但是应用范围广而且变形多,近些年深度学习广泛应用于推荐系统,但是对比由 KNN 等基线算法,效果受到很大挑战
KNN 算法通过多数投票的方式进行预测,可以应用于分类与回归,利用训练数据将特征向量空间进行划分。
由三个基本要素组成:
1.K 值的选择(该超参数直接影响效果)
2.距离度量的方法(例如闵可夫斯基距离、马氏距离、相关系数、余弦夹角等,不同的距离衡量方法,导致结果不同)
3.决策规则(回归经常采用均值,分类是多数投票)
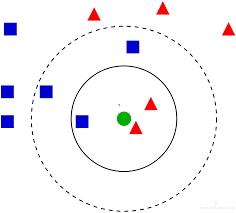
结构化数据可以直接应用 KNN 方法,非结构化数据需要先转成抽象含义的向量,然后应用 KNN 方法。
为了实现快速的 KNN 计算,暴力搜索的复杂度是 N,基本不会被采用。常用的是 KDTree、BallTree 等树状结构算法,将复杂度降低到对数量级。
高性能搜索方案
除了 KDTree 等算法之外,近些年工业界产生了大量的高性能方案,这些方案的主要特点是毫秒级延迟、可处理亿级数据、利用 GPU 分布式计算、可接受精度损失
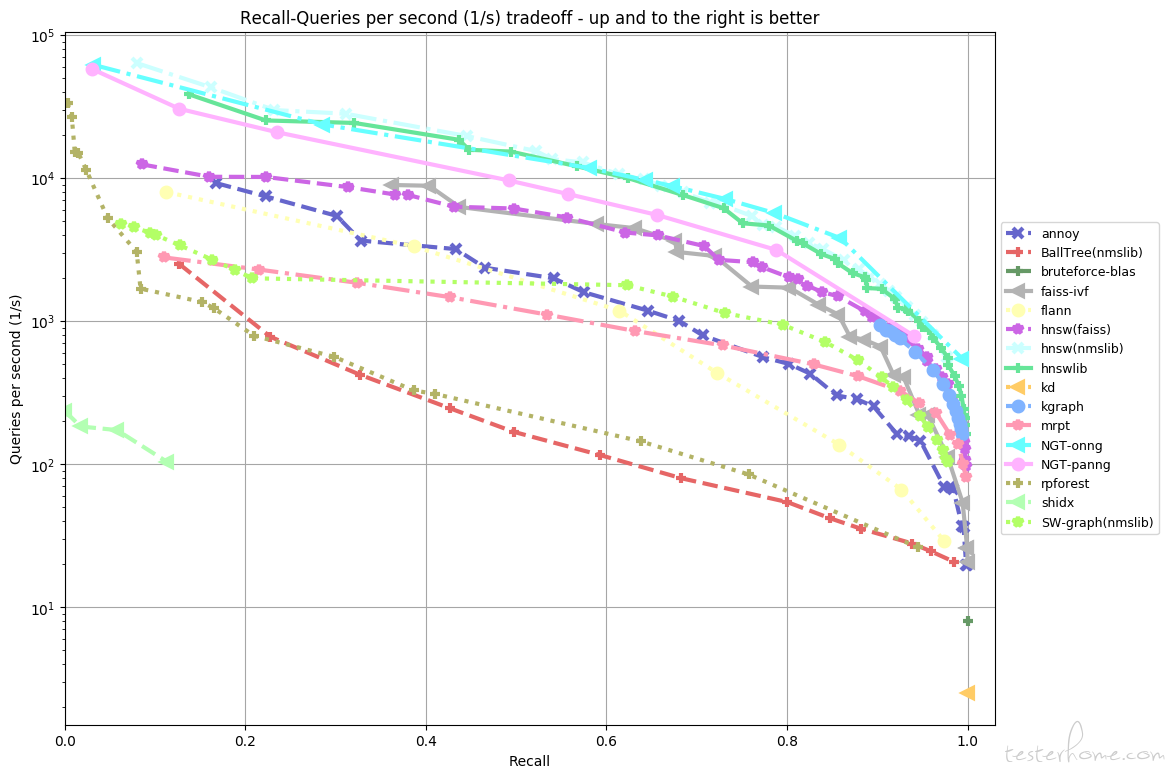
其中速度最快属于 nmslib,faiss 应用最广,因此后续介绍下 faiss 如何使用
FAISS(Facebook AI Similarity Search)
faiss 使用 C++ 实现,封装了 python 调用接口,支持 CPU 和 GPU 的异构计算方案,GPU 上的运行速度相比 CPU 大致提升了一个量级。
如果使用 GPU,需要安装 cuda(支持最新版 10.1)
向量是 32 维,百万数据集上进行 K=4 搜索:

用时 29.438 秒,单个数据耗时都在微秒量级。
参考链接:
https://arxiv.org/abs/1907.06902
https://github.com/erikbern/ann-benchmarks#glove-100-angular
https://github.com/facebookresearch/faiss
https://github.com/alibaba/x-deeplearning/wiki/%E6%B7%B1%E5%BA%A6%E6%A0%91%E5%8C%B9%E9%85%8D%E6%A8%A1%E5%9E%8BTDM)(