自动化工具 【开源】落地两年,一款基于 pytest 的接口自动化测试框架--AoMaker
前言
这个项目在刚入司不久就开始搞了 (最早的项目雏形其实是在上家公司搞的),利用业余时间弄了差不多 3 个月发了 1.0 版本,当时也是一直在研究httprunner的 v1,v2 版本,受到了很多启发,就依葫芦画瓢开始做,其实一开始定位还不是很清晰,在接口定义和 case 该直接写代码还是用模板之间反复摇摆,结果就都兼容了,你爱写代码可以支持直接写,不爱写,也提供了一套模板解析引擎。在后来长时间的项目实践中才慢慢确定了定位和方向,所以有了 2.0 版本,本文的介绍将基于此(目前最新 v2.4.0)。
当时做这个项目时,我司的自动化现状是:多条产品线,各玩各的(有的甚至还没有自动化...),有用httprunner的、有用jmeter的、有用RF的也有用pytest原生的,可谓 “群雄割据”。
为了统一管理,也为了后面测试平台的接入和运维实施快速在客户环境快速验证,另外我司是做云计算的,说起来那么多产品线,其实都是基于云平台的,所以其实是需要一款框架将各产品线的项目集成在一起的,因而这个项目的开发也是得到了老大的鼎力支持。
但是后来还是花了差不多 1 年的时间,才完成了真正的统一,期间迭代了很多版,也做了很多培训分享,好在结果是好的。目前已经服役两年多,逐渐稳定下来,给各个产品线和实施团队都带来了很大的便捷,也完美接入到测试平台(和市面上大多平台方案不一样,后面有机会可以讲讲),所以是骡子是马,还是拉出来溜溜,也希望能得到各位同行的宝贵意见,让它越来越好。当然,如果对这个项目感兴趣,也欢迎交流、共建。
好了,闲言少叙,开始正文介绍!
下文将着重介绍核心思想和特性,如果想看更详细介绍,可戳《aomaker 使用指南》

Quickly Arrange,Quickly Test!

介绍
一、核心思想
AoMaker,即 Api object Maker,那什么是API Object呢?
API Object是Page Object设计模式在接口测试上的一种延伸,顾名思义,这里是将各种基础接口进行了一层抽象封装,将其作为 object,通过不同的 API 对象调用来组装成不同的业务流场景。
举个简单例子:
有一个购物车功能,它有如下接口:
- add,将物品添加到购物车
- list,查看购物车内所有物品
- delete,清空购物车内所有物品
那么,我们通过ao 的思想来封装这个功能所有接口:
class ShoppingTrolley:
def add(self):
"""添加物品到购物车"""
pass
def delete(self):
"""清空购物车"""
pass
def list(self):
"""查看购物车内所有物品"""
pass
当我们需要测试购物车的增 - 查-删流程时,只需要实例化ShoppingTrolley 类,通过调用对应的接口对象,即可完成业务场景的组装:
class TestShoppingTrolley:
def test_shopping(self):
"""测试购物车增-查-删流程"""
st = ShoppingTrolley()
# 1.添加物品到购物车
st.add()
# 2.查看购物车内物品
st.list()
# 3.清空购物车
st.delete()
解释了API Object,那Maker又怎么理解呢?
Maker其实就是框架本身提供各种辅助手段帮助快速的去编排ao 和case 。
什么手段?怎么辅助呢?
栗子:
class Instance(BaseApi):
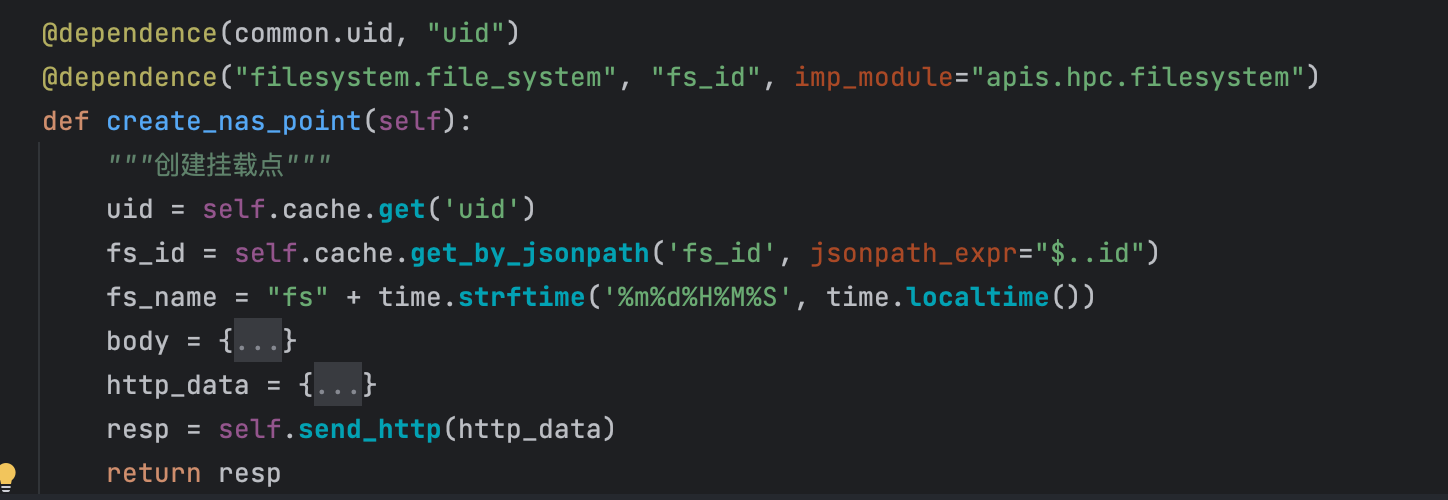
@aomaker.dependence(image_api.describe_images, "describe_images")
@aomaker.dependence("instance.describe_instance_types", "instance_types", imp_module="apis.iaas.instance.instance")
@aomaker.async_api(ins_listener, "instances")
def create_instance(self, test_data: dict, **kw_params):
"""创建主机"""
kw_params["describe_images"] = self.cache.get_by_jsonpath("describe_images", "$..image_id")
kw_params["instance_types"] = self.cache.get_by_jsonpath("instance_types", "$..instance_type_id")
kw_params["cpu"] = test_data["cpu"]
kw_params["memory"] = test_data["memory"]
params_model = model.RunInstanceModel(**kw_params)
resp = self.send_http(params_model)
return resp
对于一个接口的封装,其实核心的处理就是接口参数进行参数化处理,一个接口的参数一般可分为以下三种情况:
- 常量:即不需要参数化的参数,写死即可
- 上游依赖变量:即该参数需要调用另一个接口,从其返回值中提取
- 测试数据:即需要从用例层传入的测试数据,一般会做数据驱动
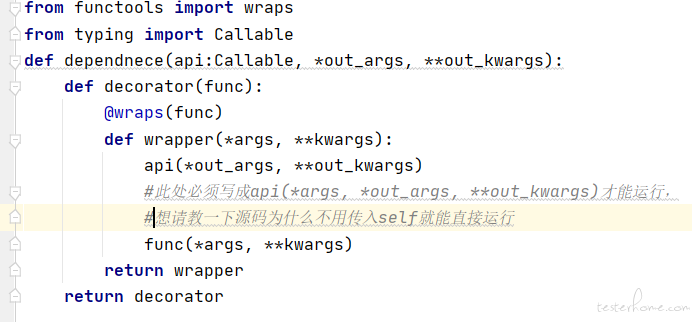
其中,对于上游依赖变量的处理是每个接口测试框架必须要面对的问题,aomaker的解法是通过@dependence装饰器去标注该接口的依赖,让其自动识别并调用依赖,并结合aomaker特殊的变量管理机制去灵活存取依赖值。
此外,如果该接口是一个异步接口,那么还需要对其进行异步处理,aomaker的解法依然是通过装饰器标注,通过@async_api指定该接口的异步处理函数,在接口调用并正常收到返回后,将进行异步处理。
通过上面的栗子可以看出,aomaker对于一个接口的定义,包括:
- 前置:接口的上游依赖调用(同一个依赖只会调用一次)
- 定义:对接口进行 http 协议填充,包括接口参数的参数化处理、请求发送(
headers等公共数据隐藏在基类中自动处理) - 后置(如果是异步):在接口调用完成并得到正常反馈后,开始自动进行轮询处理,直到得到异步任务完成的反馈
这样的目的是为了保证接口定义功能单一、简洁,方法中只有接口的定义,没有过多的数据处理、逻辑判断等操作,另一方面,提高了复用性,不用反复处理前后置并且同样的依赖不会重复调用。
当完成了这样一个ao的定义,就可以供上层(用例层或业务层)调用,在调用层不用再去关心该怎么处理它的依赖关系,该怎么处理后置操作,只需要调用ao这块积木去组装你的用例或业务即可,内部 细节全由框架自动帮你完成。
aomaker 早期 1.0 版本中,其实还提供了两种自动生成ao和case的方式:
- 通过
yaml模板自动生成(包括har和swagger转换) - 通过流量录制自动生成
当时受httprunner 的影响较大,陷入了一些思维定式,觉得通过模板转换自动生成代码感觉很高效,但经过长时间的项目实践,发现模板会有很多条条款款的限制,每个项目又不尽相同,这样反而限制了灵活性(没有说httprunner不好的意思,hr 设计得非常优秀,收益良多,可以说没有 hr 就没有 aomaker),处处掣肘不能放飞自我策马奔腾。所以后来在 2.0 版本中,基本弃用了这两种方式(但代码依然保留,或许有人喜欢呢),还是更推荐直接撸代码来得快,aomaker只是提供了一些辅助工具,帮你撸得更快更稳更方便,可扩展性还是非常高的,不会限制你的发挥。
二、定位
一款基于pytest ,将接口通过ao 对象方式来编排管理的接口自动化框架,让测试人员能快速完成自动化项目搭建和高可维护性脚本的编写,快速开始测试。
三、结构
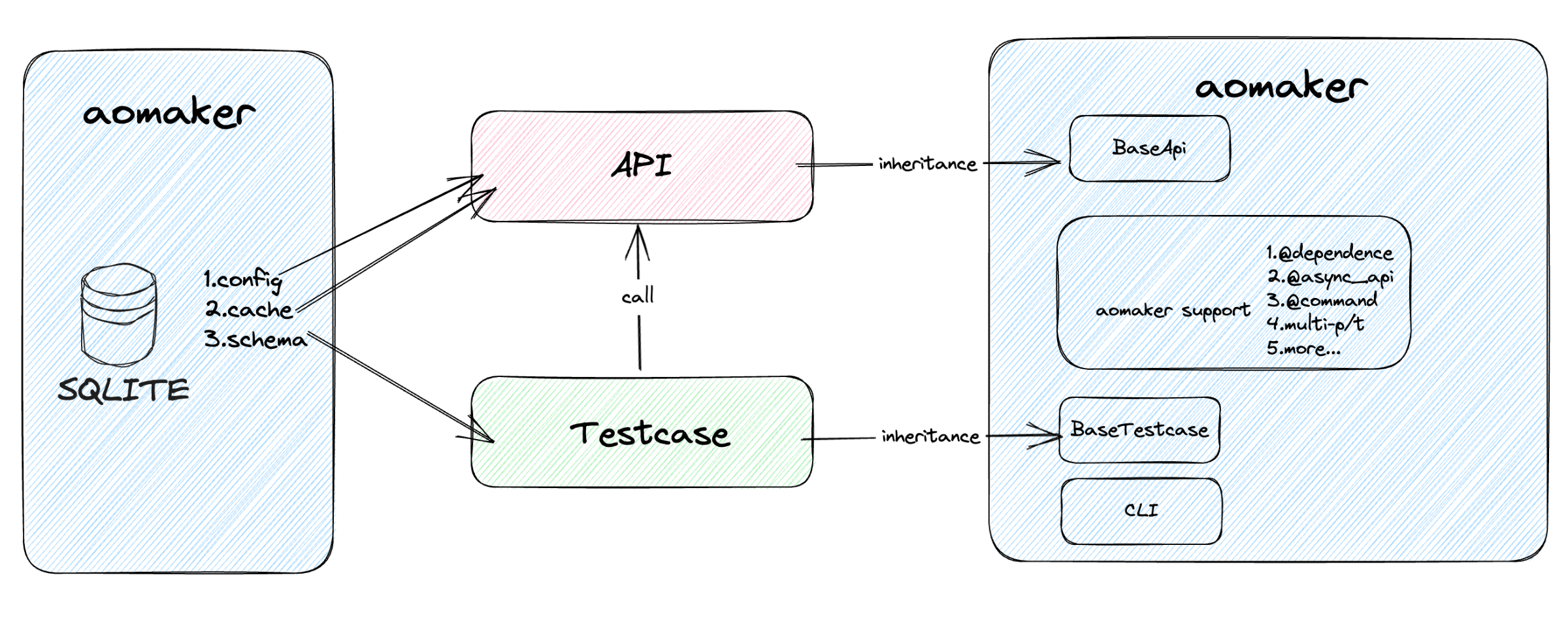
BaseAPI 提供 API 的公共操作,包括请求发送封装、config 和 cache 的连接对象初始化、日志打印模板、参数模型解析、公共参数初始化等。
BaseTestcase 提供 case 层的断言操作。
该两层已内置封装到 aomaker 中,只需要导入继承即可。
如需扩展,继承即可。
四、特性
- 提供 CLI 命令
- 提供脚手架一键安装,开箱即用
- 变量管理简单
- 简洁处理依赖和异步接口
- 不同粒度的重试机制
- 三种方式快速编写 ao 和 case
- 支持多进程和多线程
- 易扩展
- 丰富的断言
- 支持流量录制
- 支持 pytest 所有用法和插件
- allure 报告优化
- 测试报告消息通知
- ...
1、变量管理
为了对多任务运行测试用例有更好的支持,aomaker 采用了本地数据库sqlite的方案来存储管理整个测试生命周期的变量(包括全局配置变量、接口上下游之间的依赖变量、缓存变量等等),sqlite是一个非常轻量的本地文件数据库,可以直接访问存储文件,而且不需要任何安装配置~
SQLite 是一个进程内的库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。它是一个零配置的数据库,这意味着与其他数据库不一样,您不需要在系统中配置。
就像其他数据库,SQLite 引擎不是一个独立的进程,可以按应用程序需求进行静态或动态连接。SQLite 直接访问其存储文件。
当使用 aomaker 创建完脚手架后,会在database目录下创建aomaker.db数据库文件,并且 aomaker 内置了三张数据表,来分别管理全局变量、接口依赖参数、jsonschema,这三张表分别是:
- config:存储配置文件中的全局变量,如账户信息,环境 host 等配置信息,当启动测试任务后,会根据当前选择的测试环境,自动读取
config.yaml中的配置存到config表中,该配置会固化不清理,除非更改了测试环境。 - cache:存储测试过程中上下游接口之间的依赖接口的响应,会搭配后文将要讲到的
dependece装饰器使用 。当一个依赖接口被调用后,会存储它完整的 response·,如果后续有其它接口也依赖这个接口,那么该接口将不会再被调用,而是直接从该接口存储的 response 中去读取需要的依赖参数。整个测试任务结束后,会自动清理cache表。 - schema:存储接口的
jsonschema信息,当一个接口第一次被调用后,会自动从它的response中解析出response.json()的jsonschema,在用例层进行断言时,可以对此次接口响应的结构体与schema表中存储的结构体进行比较,检测是否有参数变动。(后文细讲)
三张表的结构其实都非常简单,就是键值对:
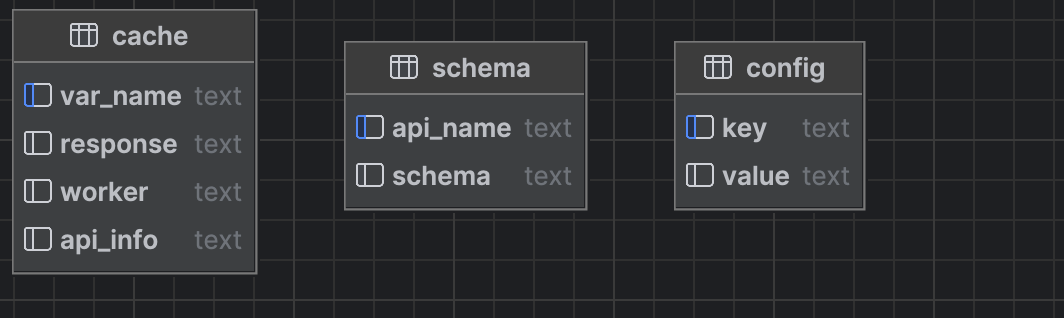
在aomaker的baseapi中,初始化了cache和config两张表的连接对象,因为所有接口都是继承于baseapi的,所以所有接口都可以通过self.config和self.cache来拿到连接对象,当有了连接对象就可以通过封装好的set()和get()方法来存取变量了。
1.config
在整个测试生命周期里,可以在任何地方通过config 对象来存取配置变量。
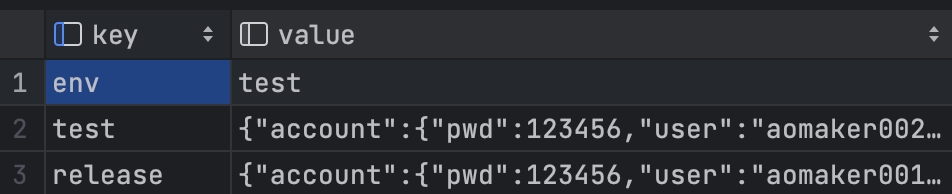
假设全局配置如下:
conf/config.yaml
# 当前运行环境
env: test
# test环境配置
test:
account:
pwd: 123456
user: aomaker002
host: http://test.aomaker.com
# release环境配置
release:
account:
pwd: 123456
user: aomaker001
host: http://release.aomaker.com
当aomaker 开始运行后,会自动把conf\config.yaml 中的所有配置全部存到config表中:
当在BaseApi 的子类中想获取env信息,可以直接self.config.get("env")即可获取到;
当在其它地方想获取env信息,比如用例层,可以:
from aomaker.cache import config
def test_demo():
env = config.get("env")
asssert env == "test"
特别地,整个config表内存储的配置信息是固化的,不会随着测试结束而清理,当配置发生变更后,如环境切换了,config表会自动更新,不需要人为操作。
2.cache
同样的 cache 这张表,也是在全生命周期内都可以任意调用,不同的是cache 是用来存放本次测试过程中的一些临时变量,如headers 、接口上下游之间的依赖变量等,在测试结束后,会全部清空。
调用方式同config ,
当在BaseApi 的子类中想获取headers,可以直接self.cache.get("headers")即可获取到;
当在其它地方想存放某个变量,比如用例层,可以:
from aomaker.cache import cache
def test_demo():
name = "aomaker"
cache.set("name",name)
def test_demo2():
name = cache.get("name")
assert name == "aomaker"
需要注意的是,cache表的var_name是唯一键,如果cache.set 一个已存在的var_name 会自动忽略,如果想要修改已存在的var_name的值,可以调用cache.update 方法进行修改。
3.schema
后文断言扩展中详细介绍。
2、api 参数模型
先看一下正常情况下,一个简单接口的接口定义:
class Instance(BaseApi):
def get_instances(self):
http_data = {
"owner": self.owner,
"action": "DescribeInstances",
"reverse": 1,
"status": ["pending", "running", "stopped", "suspended", "rescuing"],
}
resp = self.send_http(http_data)
return resp
可以看到,这个接口的参数其实很简单,这么写是 ok 的。
但是如果一个复杂的接口,可能会有几十上百个参数,比如:
class Instance(BaseApi):
def run_instance(self, 入参可能太多省略...):
body = {
"image_id": image_id,
"instance_type": instance_type,
"cpu": cpu,
"memory": memory,
"instance_name": instance_name,
"count": count,
"vxnets": vxnets,
"nics": nics,
"security_group": security_group,
"login_mode":login_mode,
"login_passwd":login_passwd,
"login_keypair":login_keypair,
"need_newsid": need_newsid,
"need_userdata":need_userdata,
"userdata_type":userdata_type,
"userdata_value":userdata_value,
"userdata_path":userdata_path,
"userdata_file":userdata_file,
"volumes": volumes,
"graphics_protocol": graphics_protocol,
"graphics_passwd": graphics_passwd,
"boot_dev": boot_dev,
"instance_class": instance_class,
"usb": usb,
"hypervisor": hypervisor,
"repl": repl,
"gpu": gpu,
"gpu_class": gpu_class,
"ivshmem": ivshmem,
"features": features,
"nic_mqueue": nic_mqueue,
"stop_on_error": stop_on_error,
"sriov_nic_type": sriov_nic_type,
"ib_sriov_type": ib_sriov_type,
"private_pkey": private_pkey,
"os_disk_encryption": os_disk_encryption,
"cipher_alg": cipher_alg,
"cmk_id": cmk_id,
"enable_webssh": enable_webssh,
# 此处省略100个
}
resp = self.send_http(http_data)
return resp
这海量的参数对调用方和维护者来说都是巨大的负担,实际必传的参数可能只有几个,但是在定义接口时,我们又希望定义完整和接口文档保持一致,包括参数该传什么类型,哪些必传,哪些非必传,默认值是什么。
从 django 和 fastapi 中找到一些灵感,那就是参数模型。
针对这种有海量参数的接口,可以将参数定义单独抽象一层,由模型来管理,编写者通过模型来维护参数即可。
具体用法:
推荐在对应ao(接口定义) 目录下,定义一个model.py 模块

导入aomaker.dataclass ,对对应的参数类进行装饰即可,然后用这个类的类属性来管理接口的所有参数。
如:
model.py
from aomaker import aomaker
from apis.iaas.instance.constants import LoginModeEnum
__all__ = ["RunInstanceModel", "DescribeImagesModel"]
@aomaker.dataclass
class RunInstanceModel:
action: str = "RunInstances"
image_id: str
instance_type: str
cpu: int = None
memory: int = None
instance_name: str = None
os_disk_size: int = None # 单位GB
count: int = 1
login_mode: LoginModeEnum = LoginModeEnum.passwd.value
login_passwd: str = "Zhu@88jie123"
login_keypair: str = None
vxnets: str = None # 是否加入私有网络
security_group: str = None # vxnets包含基础网络才需要
volumes: str = None
hostname: str = None
need_newsid: int = None # 默认0,只对windows类主机有效
instance_class: int = None # 主机性能类型
cpu_model: str = None # CPU指令集,有效值: Westmere, SandyBridge, IvyBridge, Haswell, Broadwell
cpu_topology: str = None
gpu: int = None
gpu_class: int = None
nic_mqueue: int = None # 网卡多队列,0关闭(默认),1开启
@aomaker.dataclass
class DescribeImagesModel:
action = "DescribeImages"
provider: str = "system"
status: list = ["pending", "available", "suspended"]
offset: int = None
limit: int = None
sort_key: str = "order_name"
os_family: list = ["centos"]
search_word: str = ""
模型中会定义每个接口的所有参数及其类型,当设置为 None 时,代表该参数非必填,在发送请求时,请求构造器会自动过滤掉这些非必填且没有传值的参数。
那么在一个接口定义中如何使用呢?
from apis.iaas.instance import model
def run_instances(self, **kw_params):
"""创建主机"""
params_model = model.RunInstanceModel(**kw_params)
resp = self.send_http(params_model)
return resp
这个接口的所有入参,通过不定长关键字参数传入,
如果传入了参数,那么会替换模型中的默认值;
如果传入了模型中没有的参数,会直接报错;
如果什么都不传,则默认取参数模型中的值,不过,要注意模型中是否有必传参数。
这样,整个接口定义会非常清爽,而复杂的接口参数管理可以通过接口文档自动生成我们规定的模型格式,单独管理,调用方也能非常清晰的知道每个参数的含义、是否必传或默认值等详细信息。
3、依赖处理
1.当该接口有依赖接口,参数中有依赖上个接口的返回怎么办?
aomaker提供了一个依赖接口装饰器:@dependence,只需要标记依赖哪个接口,就会在请求该接口前,先去请求依赖接口,并将依赖的返回保存在cahce中,具体用法:
import json
from aomaker.base.base_api import BaseApi
# 从aomaker导入depedence装饰器
from aomaker.aomaker import dependence
# 导入依赖接口的接口对象
from apis.cluster import cluster
class Job(BaseApi):
# dependence标记依赖参数
@dependence(cluster.get_cluster_list, 'hpc_cluster_id', cluster_type='hpc')
def submit_hpc_job(self, test_data):
body = {
# 从cache中获取依赖参数
"cluster_id": self.cache.get_by_jsonpath('hpc_cluster_id', jsonpath_expr='$..cluster_id'),
"hpcqueue_id": self.cache.get_by_jsonpath('hpc_queue_id', jsonpath_expr='$..hpcqueue_id'),
"scheduler_queue_name": "medium",
"cmd_line": test_data["cmd_line"]
}
http_data = {
"method": "post",
"api_path": "/portal_api",
"params": {'action': 'job/submitJob'},
"data": {
'params': json.dumps(body)
}
}
resp = self.send_http(http_data)
return resp
使用步骤:
-
from aomaker.aomaker import dependence导入装饰器 - 导入依赖接口对象
- 在模板接口上使用
@dependence装饰器,该装饰器接收 2 个必传参数:- 第一个参数,依赖接口对象
- 第二个参数,需要从依赖接口响应中提取的参数名
- 如果依赖接口本身需要从外部传入参数,那么可以以关键字参数的形式传入
- 在 body 中,当需要引用依赖接口的参数时,直接调用
self.cache.get_by_jsonpath方法,该方法接收 2 个必传参数:- 第一个参数,依赖参数的参数名,即
cache表中的key名 - 第二个参数,从依赖接口的响应中,提取出依赖参数值的
jsonpath表达式 - 非必填,
jsonpath表达式提取出的值是list,可以根据自身需求指明需要提取哪个,默认值为0
- 第一个参数,依赖参数的参数名,即
如果要提取的值,不需要使用jsonpath 来提取,也可以使用self.cache.get(key_name) 提取。
2.如果依赖的接口,是同一个类的方法怎么办?
@dependence的第一个参数需要以字符串的形式传入,如"Job.job_list",同时,还需要告诉装饰器,接口对象来自哪个模块,传入imp_module="apis.job"。
class Job(BaseApi):
# dependence标记依赖参数
@dependence("Job.job_list", 'job_id',imp_module="apis.job")
def submit_hpc_job(self, test_data):
3.如果有多个依赖接口,怎么办?
只需要继续加 “帽子” 即可,需要注意装饰器的执行顺序是从上往下执行。
class Job(BaseApi):
# 依赖从上往下执行
@dependence(cluster.get_cluster_list, 'hpc_cluster_id', cluster_type='hpc')
@dependence(queue.get_queue_list, 'hpc_queue_id')
def submit_hpc_job(self, test_data):
...
return resp
4、异步接口处理
当接口是异步接口,怎么做判断异步结果?
aomaker提供了@async_api来标记异步接口,示例如下:
from aomaker.base.base_api import BaseApi
from aomaker.aomaker import dependence, async_api
from apis.cluster import cluster
from utils import wait_job
class Job(BaseApi):
@async_api(wait_job, 'hpcjob_uuid')
@dependence(cluster.get_cluster_list, 'hpc_cluster_id', cluster_type='hpc')
def submit_hpc_job(self, test_data):
...
return resp
使用步骤:
-
from aomaker.aomaker import async_api导入@async_api装饰器 -
@async_api装饰器接收两个必传参数:- 第一个参数,自己编写的轮询函数(注意接收的是函数对象,不要加括号直接调用)
- 第二个参数,从目标接口的响应中根据 jsonpath 表达式提取异步任务 id
- 非必填参数,
jsonpath表达式提取出的值是list,可以根据自身需求指明需要提取哪个,默认值为0 - 若轮询函数需要接收参数,也可以通过关键字参数传入
当一个接口被打上这个标记,那么会在接口被请求完成后,会开始执行自己编写的轮询函数,来判断该异步接口的异步任务结果是否得到预期结果。
5、自定义参数和 hook
1.@command
aomaker 提供的自定义参数注册,是对 pytest 提供的注册机制的一种补充,两者并不冲突。
由于 aomaker 提供了多任务模式,如果通过 pytest 注册了一些全局 cli 参数,它的执行时机是在子进程\线程内,这可能会导致一些全局配置的设置失败,而 aomaker 注册的 cli 参数,是在主进程\线程内执行,即会早于 pytest 且整个运行过程只执行一次。
pytest 注册用法:
conftest.py
import pytest
# 1.注册参数
def pytest_addoption(parser):
parser.addoption("--zone", help="切换可用区")
# 2.编写处理函数
@pytest.fixture(autouse=True, scope="session")
def switch_zone(request):
# 获取参数值
zone = request.config.getoption("zone")
config.set("zone", zone)
可以看到,pytest 的注册分为两部分:
- 声明注册参数
- 编写参数处理函数,写起来较为繁琐也不直观。
而 aomaker 在写法上做了一定层度优化,aomaker 注册方式如下:
hooks.py
from aomaker.aomaker import command
@command("--zone", help="切换可用区")
def switch_zone(zone):
config.set("zone", zone)
aomaker 提供了@command 装饰器(在工程根目录下的hooks.py文件中进行注册),将参数申明、属性配置和处理函数绑定在一起,更加直观简洁,且函数接收的参数即为参数对应的值,不需要再做额外处理。
command 接收的第一个参数为参数名,以 “-” 或 “–” 开头,后面提供的参数以关键字形式接收,支持的配置参数:
- help:参数的说明文本。
- required:该参数是否是必须的,类型为布尔值。如果设置为 True,则必须在命令行中提供该选项的值。默认值为 False。
- default:选项的默认值。如果未在命令行中提供选项,则将使用该默认值。
- show_default:是否在帮助消息中显示默认值,类型为布尔值。默认为 False。
- type:参数的类型,例如,如果设置为 int,则选项将被转换为整数类型。默认为字符串类型。
- multiple:参数是否可以多次出现在命令行上,类型为布尔值。如果设置为 True,则可以在命令行上多次提供该选项。默认为 False。
- action_store:参数后面可以加参数值,接收一个布尔值,如果为 True,表示传递该参数,值为 True,不传,值为 False。
2.@hook
其实pytest 也提供了丰富强大的hook 注册机制,为什么aomaker 要重复造轮子?
其实原因同@command,这里并不是重新造轮子,而是pytest和aomaker多任务模式下的一种补充。
在aomaker的多任务模式下,pytest注册的 session 级别 hook 函数,只会在子进程/线程内执行,而aomaker注册的 hook 函数是在主进程/线程内执行的,在执行顺序上,aomaker hook是先于pytest hook的,而在主进程\线程内,我们可以通过@hook自定义做很多启动配置,来提供给 pytest 使用。
具体用法:
hooks.py
from aomaker.aomaker import hook
@hook
def echo_hello():
print("echo hello~~~~~")
注册后,该 hook 函数将会在aomaker进行配置初始化时自动调用 (启动 pytest 前)。
6、多任务
aomaker 提供了多线程和多进程两种方式来加速用例运行速度,提供了三种粒度来合理控制线程/进程 worker,此外,多线程模式下,对allure 报告也做了优化,不会像pytest-parallel可能会出现无法正常生成测试报告的问题。
aomaker 的运行流程如下:
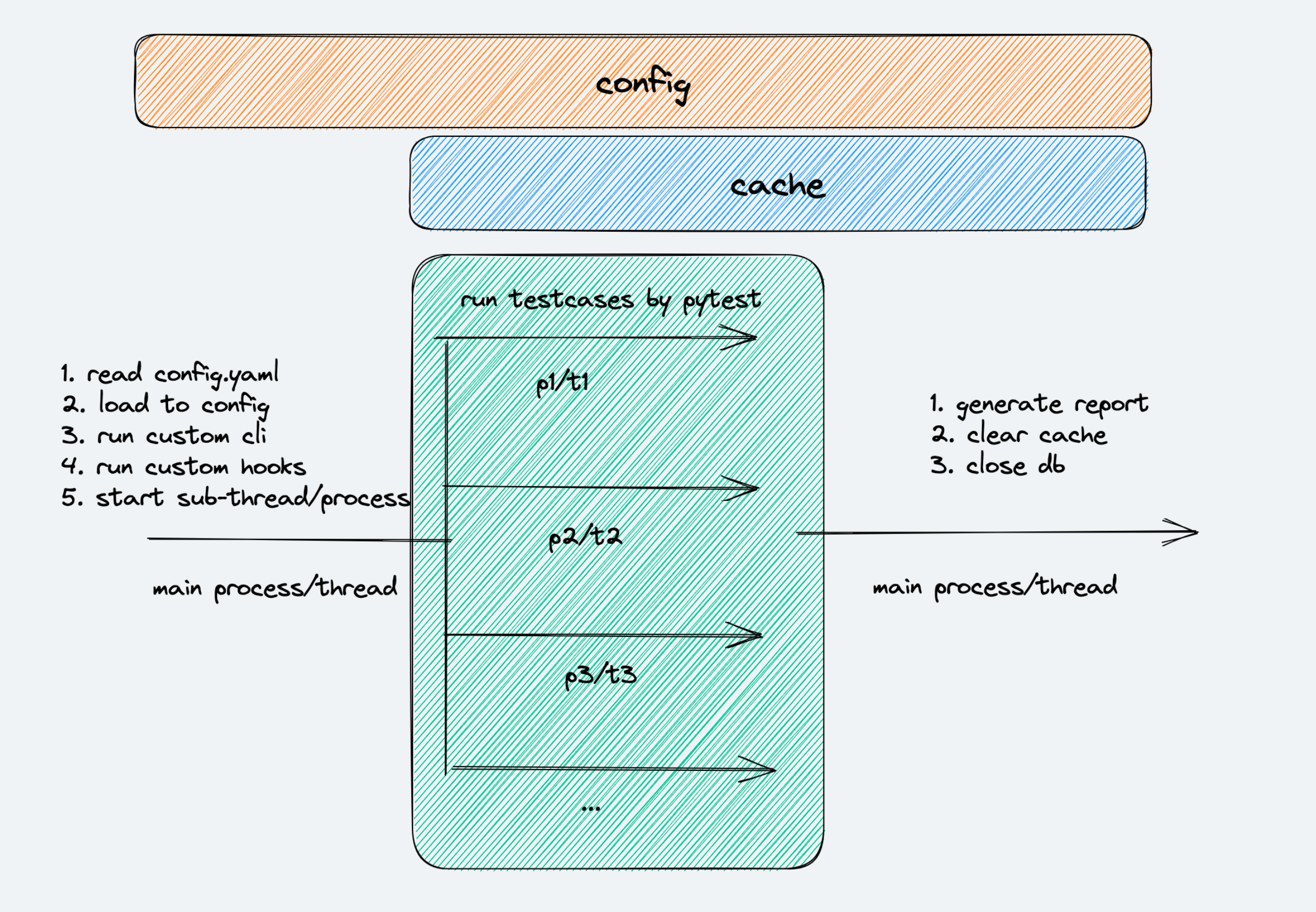
启动后,
- 读取
config.yaml配置文件 - 加载配置文件
- 运行
hooks.py中的自定义 cli 和 hook(如果有) - 开始根据 cli 指定的多任务方式和分配模式开启多线程/进程(如果在
aomaker.yaml中指定了 worker 分配策略,将会以该策略进行分配) - 在子进程/线程内启动
pytest进行用例运行 - 所有子任务执行完成后,进行报告收集、聚合和环境清理,结束
1.多线程(推荐)
启动方式
aomaker提供了两种启动多线程:CLI和run.py
- cli
multi-run:
--mp, --multi-process
specifies a multi-process running mode.
--mt, --multi-thread specifies a multi-thread running mode.
--dist-suite DIST_SUITE
specifies a dist mode for per worker.
--dist-file DIST_FILE
specifies a dist mode for per worker.
--dist-mark DIST_MARK [DIST_MARK ...]
specifies a dist mode for per worker.
命令行输入:arun --mt --dist-xxx xxx或者aomaker run --mt --dist-xxx
- run.py
run.py
from login import Login
from aomaker.runner import threads_run
if __name__ == '__main__':
threads_run(['-m ehpc','-m hpc'], login=Login())
分配模式
为了更加精细和合理的去分配任务给子线程,aomaker提供了三种分配模式,颗粒度由细到粗分别是:
- 按标记分配
即按照pytest提供的mark功能来分配任务给子线程,比如说你希望将标记为demo1、demo2、demo3的三组 case 分配给三个不同子线程去跑,那么你需要做的就是:提前给用例打上对应mark,然后:
- cli:
arun --mt --dist-mark "demo1 demo2 demo3" - run.py:
run.py
from login import Login
from aomaker.runner import threads_run
if __name__ == '__main__':
# 注意第一个参数传入的是列表
threads_run(['-m demo1','-m demo2','-m demo3'], login=Login())
这样启动后,会开启三个子线程,去分别执行三组 case。
注意:
1.每组 mark 下的 case,一定要保证是独立的!
2.提供多少个 mark,就开启多少个线程
- 按测试模块分配
即按照测试文件来分配任务给子线程,比如在testcases\test_api目录下有test_demo1.py、test_demo2.py、test_demo3.py三个测试模块,你希望这三个模块下的测试 case 分别由三个子线程接管执行,那么只需要:
- cli:
arun --mt --dist-file testcases\test_api,即告诉aomaker测试文件所在目录既可 - run.py:
run.py
from login import Login
from aomaker.runner import threads_run
if __name__ == '__main__':
# 注意第一个参数传入的是key名为path的字典
threads_run({"path":"testcases/test_api"}, login=Login())
注意:
1.每个测试模块下的 case,一定要保证是独立的!
2.指定目录下有多少个测试模块,就开启多少个线程
- 按测试套件分配
即按照测试目录来分配任务给子线程,比如在testcases\test_scenario目录下,有test_scenario1、test_scenario2、test_scenario3等三个测试目录,每个目录下还有若干测试模块,你希望这三个目录下的所有测试 case 分别由三个子线程接管执行,那么只需要:
- cli:
arun --mt --dist-suite testcases\test_scenario,即告诉aomaker测试套件所在目录既可 - run.py:
run.py
from login import Login
from aomaker.runner import threads_run
if __name__ == '__main__':
# 注意第一个参数传入的是字符串
threads_run("testcases/test_scenario", login=Login())
注意:
1.每个测试模块下的 case,一定要保证是独立的!
2.指定目录下有多少个测试套件,就开启多少个线程
2.多进程
aomaker目前暂时不支持在 windows 上创建多进程,linux、mac 是完美支持的。
启动方式
aomaker同样提供了两种启动多进程:CLI和run.py
- cli
multi-run:
--mp, --multi-process
specifies a multi-process running mode.
--mt, --multi-thread specifies a multi-thread running mode.
--dist-suite DIST_SUITE
specifies a dist mode for per worker.
--dist-file DIST_FILE
specifies a dist mode for per worker.
--dist-mark DIST_MARK [DIST_MARK ...]
specifies a dist mode for per worker.
命令行输入:arun --mp --dist-xxx xxx或者aomaker run --mp --dist-xxx
*注意📢:使用 mark 分配模式时,需要加引号,如 arun --mp --dist-mark "m1 m2 m3" *
- run.py
run.py
from login import Login
from aomaker.runner import processes_run
if __name__ == '__main__':
processes_run(['-m ehpc','-m hpc'], login=Login())
分配模式
分配模式和多线程是一样的,区别是任务是分配给子进程,而不是子线程,具体分配模式请参考多线程。
3.worker 策略分配配置
当我们的用例工程比较庞大时,需要同时并行很多不同的 mark 用例,如arun --mp --dist-mark "m1 m2 m3 ...m30",在 cli 里指定会导致命令很长。
因此,aomaker 在 v2.3.0 推出了多任务 worker 策略配置,目的是支持更多标签并行执行,可以更灵活、更方便的去配置多任务分配策略,从而提升执行效率。
在conf目录下有一个策略配置文件:aomaker.yaml。
conf/aomaker.yaml
target: ['iaas','hpc']
marks:
iaas:
- iaas_image
- iaas_volume
hpc:
- hpc_sw
- hpc_fs
参数说明:
- target:list,代表下方具体策略目标
- marks:dict[dict],代表标签分类,每个分类下是一个列表,其中每个元素代表一个测试标签。
上述策略配置,最终会生产 4 个标签:iaas_image,iaas_volume,hpc_sw,hpc_fs,分配给 4 个 worker 同时执行。
注意📢:这里配置的每一个标签,一定是独立、不互为依赖的!
有时候,我们可能有不同的测试场景,需要跑不同的用例,即不同的标签,又不想每次重新配置。所以在此基础上,还支持多策略配置,具体用法如下:
conf/aomaker.yaml
target: ['iaas.smoke','hpc']
marks:
iaas:
smoke:
- iaas_image
- iaas_volume
p2:
- iaas_image_p2
- iaas_volume_p2
- iaas_network_p2
hpc:
- hpc_sw
- hpc_fs
比如 iaas 分类下,想增加两组多任务策略:一组用来跑冒烟-smoke,一组用来跑 p2 级用例-p2。
当要跑 iaas 冒烟时,修改配置文件中的 target 为 iaas.smoke;
当要跑 iaas p2 时,修改配置文件中的 target 为 iaas.p2;
假如 target 为 ['iaas.p2','hpc'],最终会生产 5 个标签:iaas_image_p2,iaas_volume_p2,iaas_network_p2,hpc_sw,hpc_fs,分配给 5 个 worker 同时执行。
原有的三种分配模式依然支持,即--dist-mark,--dist-file,--dist-suite。
现在,当你想使用策略配置时,只需在命令行输入:
- 多进程:
aurn --mp - 多线程:
arun --mt
即,当不输入分配模式参数时,会根据策略配置文件去获取任务分配给 worker;
当输入分配模式参数时,会按照输入的参数去分配给 woker。
7、重试机制
为了增强测试代码的健壮性,aomaker提供了一种重试机制,下面针对三种使用场景来做说明。
1.网络请求
在aomaker的BaseApi中,对发送 http 请求若遇到请求状态码大于 400,会自动进行重试。
class BaseApi:
IS_HTTP_RETRY = False
HTTP_RETRY_COUNTS = 3
HTTP_RETRY_INTERVAL = 2 # 单位:s
def __init__(self):
self.cache = Cache()
self.config = Config().get_all()
self._host = self.config.get('host')
self._headers = self.cache.get('headers')
self._response_callback = response_callback
这里有三个参数来控制 http 请求时的重试逻辑:
- IS_HTTP_RETRY :总开关,默认关闭重试
- HTTP_RETRY_COUNTS:重试次数,默认 3 次
- HTTP_RETRY_INTERVAL:每次重试间隔的时间,默认 2 秒(单位秒)
那如何来修改这些参数呢?
前面说过,项目的所有 ao 都是继承于这个基类,所以可以继承该基类,实现一个项目的子类。
from aomaker.base.base_api imoort BaseApi
class MyBaseApi(BaseApi):
IS_HTTP_RETRY = True
HTTP_RETRY_COUNTS = 5
HTTP_RETRY_INTERVAL = 3
然后所有的 ao 继承于该类即可,这样当所有 http 请求如果出现网络请求状态码>400 后,将会每 3 秒重试一次,总共重试 5 次。
2.业务层面
除了在网络请求层面,还可以在业务层面加入重试,进一步加强健壮性。
比如,可以根据业务接口的业务码来做重试(大部分项目都会有),
假如这里有个项目的所有业务接口的响应都会返回一个ret_code,当这个code为 0,代表业务正常,非 0 表示异常,那我希望当非 0 时,进行一定程度的重试,怎么做呢?
导入 aomaker 的重试模块:
from aomaker import aomaker
class Instance(BaseApi):
@aomaker.retry(counts=2, interval=3, retry_condition=lambda resp: resp.get("ret_code") != 0)
def get_instances(self):
http_data = {
"owner": self.owner,
"action": "DescribeInstances",
"reverse": 1,
"status": ["pending", "running", "stopped", "suspended", "rescuing"],
}
resp = self.send_http(http_data)
return resp
@aomaker.retry(counts=2,interval=3,retry_condition=lambda resp: resp.get("ret_code") != 0) ,解释下这个装饰器:
- counts: 表示重试次数
- interval:表示重试间隔
- retry_condition:表示重试条件,这个参数接受一个 bool 值,为 True 就将进行重试,这里会提取被装饰函数的返回值来进行判断
除了这几个参数,该装饰器还有一个参数:exception_type
该参数可以指定特定异常,当触发该异常时,将会进行重试。
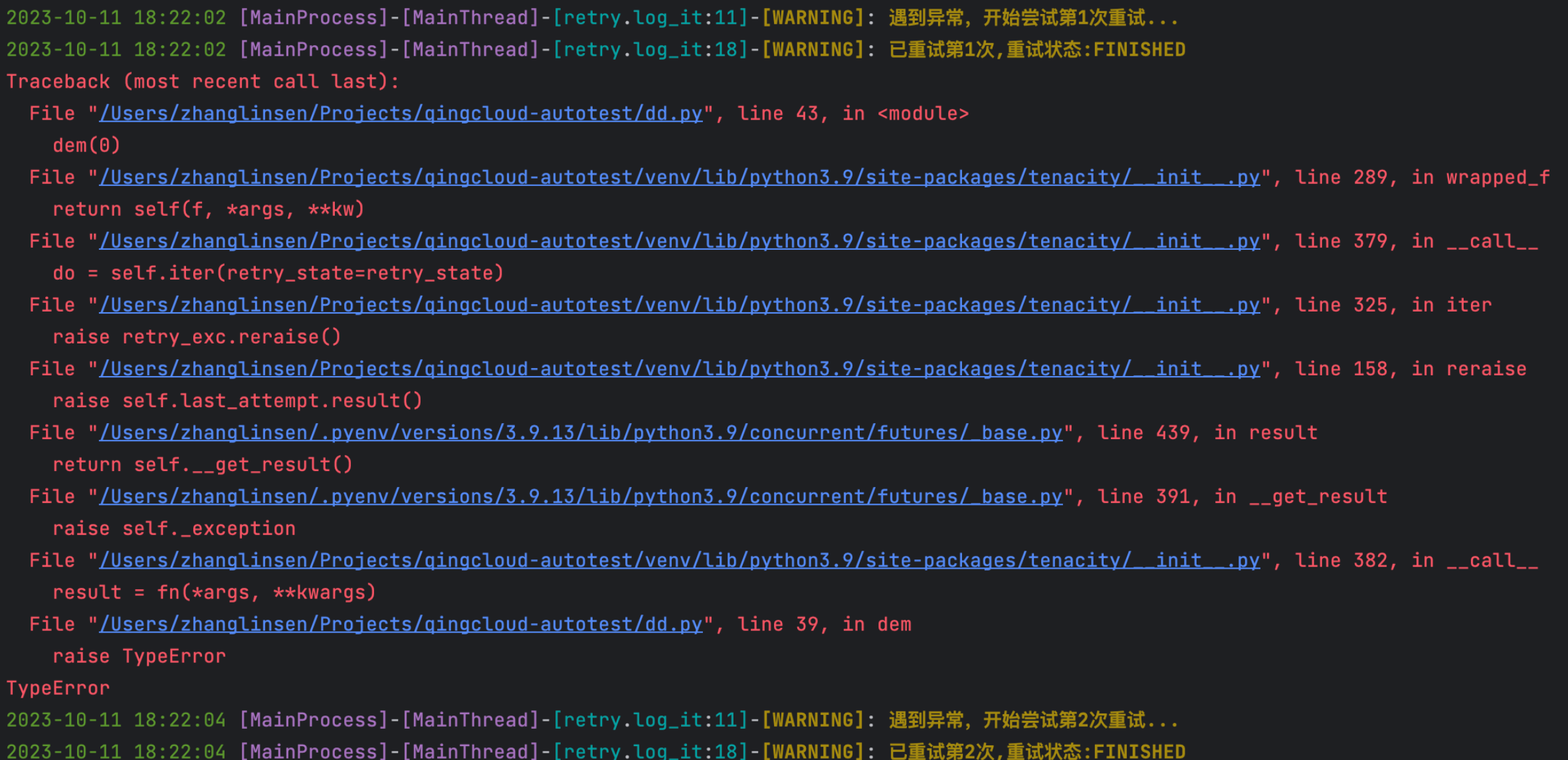
栗子:
@aomaker.retry(counts=2, interval=2, exception_type=TypeError)
def dem(num):
if num==0:
raise TypeError
return num
dem(0)
3.代码片段
除了对函数、方法级别进行重试,还可以针对某段代码片段进行重试。
使用方法和上面的装饰器略有不同,看栗子:
先导入AoMakerRetry
from aomaker.aomaker import AoMakerRetry
def get_random_num():
num = 6
return num
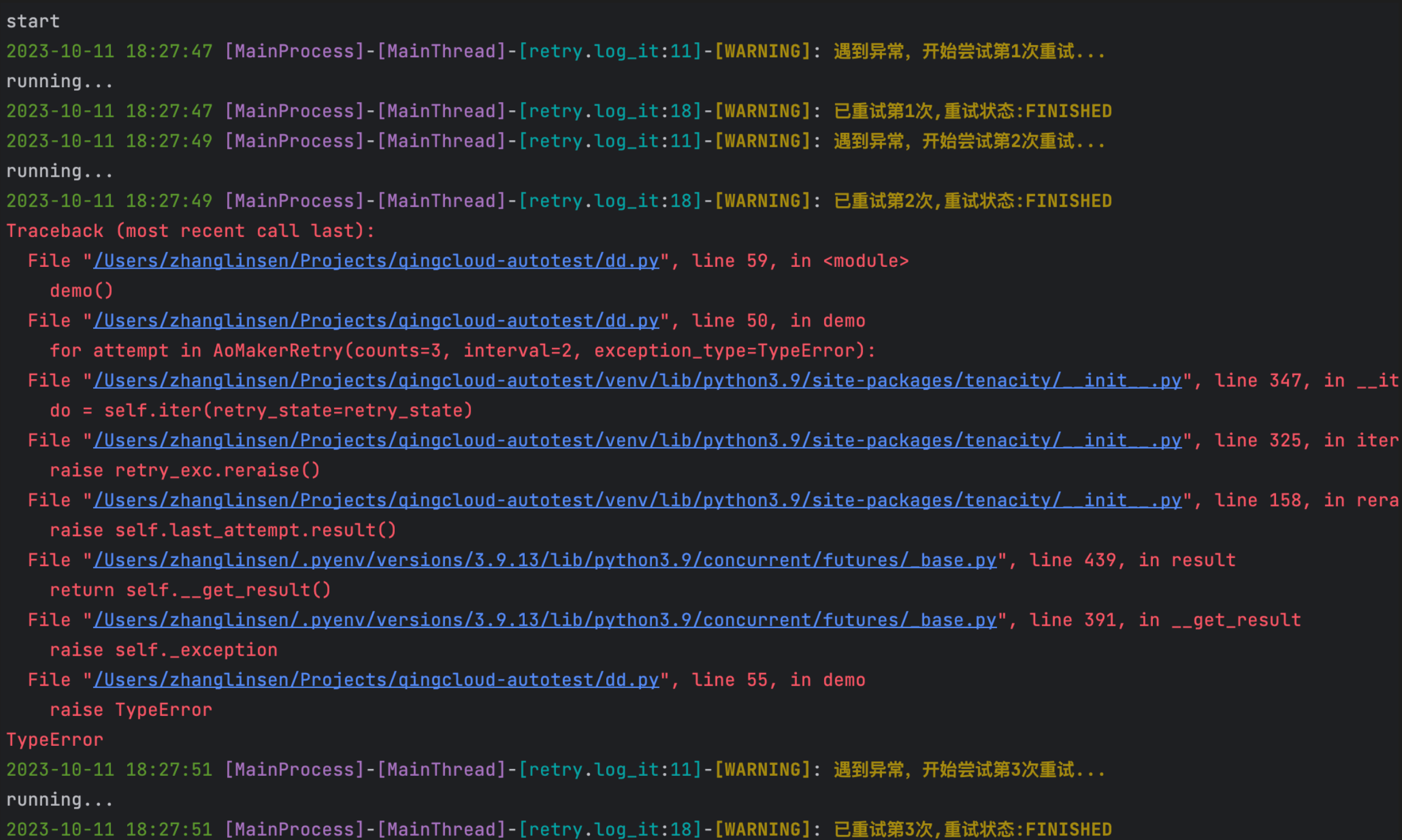
def demo():
print('start')
for attempt in AoMakerRetry(counts=3, interval=2, exception_type=TypeError):
with attempt:
print('running...')
random_ = get_random_num()
if random_ == 6:
raise TypeError
print('end')
demo()
这里需要用for x in AoMakerRetry() with x: 这样固定的结构体,将需要重试的代码片段包裹起来,而AoMakerRetry类所接受的参数和上面装饰器是一样的。
上面代码的输出结果:
8、schema 断言
有时,我们的接口响应数据体积会非常庞大,字段也非常多,我们常规的断言可能只会去关注某几个关键字段,但是这不够健壮,有时候后端 “悄悄咪咪” 加了某个字段或者删了某个字段或者改了某个字段的类型,我们可能很难察觉到,这就会导致一些隐藏的 bug 逃逸,所以我们需要加强断言的健壮度,要对整个响应内容结构有一个基本的把控。
怎么做呢,这就需要用到jsonschema了。
JSON Schema 是基于 JSON 格式,用于定义 JSON 数据结构以及校验 JSON 数据内容。 JSON Schema 官网地址:http://json-schema.org/
比如有一个 json 字符串:
{
"name": "aomaker",
"age": 2,
"desc": "api framework"
}
这其中name和age是必填字段,字段类型分别是string和int,可选字段是desc,字段类型是string,假如我想要每个这样的 json 字符串,都符合上面的约束,那我怎么自动去校验呢?这就需要安装jsonschema的语法去写约束条件。
jsonchema 语法
{
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "TestInfo",
"description": "some information about test",
"type": "object",
"properties": {
"name": {
"description": "Name of the test",
"type": "string"
},
"age": {
"description": "age of test",
"type": "integer"
}
},
"required": [
"name",
"age"
]
}
开始校验
from jsonschema import validate
x = {
"name": "aomaker",
"age": 2,
"desc": "api framework"
}
schema = {
"$schema": "http://json-schema.org/draft-04/schema#",
"title": "TestInfo",
"description": "some information about test",
"type": "object",
"properties": {
"name": {
"description": "Name of the test",
"type": "string"
},
"age": {
"description": "age of test",
"type": "integer"
}
},
"required": [
"name"
]
}
validate(x, schema)
如果校验通过,会没有返回,也没有报错。
假如不小心把age传成了字符串"2",jsonschema检测到后,会立即报错
jsonschema.exceptions.ValidationError: '2' is not of type 'integer'
Failed validating 'type' in schema['properties']['age']:
{'description': 'age of test', 'type': 'integer'}
On instance['age']:
'2'
假如不小心没有传必填字段name,也会立即报错
jsonschema.exceptions.ValidationError: 'name' is a required property
Failed validating 'required' in schema:
{'$schema': 'http://json-schema.org/draft-04/schema#',
'description': 'some information about test',
'properties': {'age': {'description': 'age of test',
'type': 'integer'},
'name': {'description': 'Name of the test',
'type': 'string'}},
'required': ['name', 'age'],
'title': 'TestInfo',
'type': 'object'}
On instance:
{'age': 2, 'desc': 'api framework'}
通过这种手段是不是对我们测试过的接口更有信心了?
1.扩展 jsonschema 断言
但是~ 有没有发现,jsonschema虽然很好,但是你得手动去写jsonschema校验语法,上面的示例还好,只有几个字段,但实际业务中,响应的字段可能要比这个多得多得多吧?那每个接口这么去写,成本也太高了!
所以, aomaker提供了一种手段,可以自动去生成jsonschema校验语法~其实上文有提到过,aomaker.db数据库中,有一张表叫schema,其实它就是存放请求过的每个接口响应的jsonschema校验语法的。aomaker会自动记录每个请求第一次返回响应时的jsonschema,当在 case 层去做断言时,aomaker提供了一个jsonschema的断言在BaseTestcase中:
class BaseTestcase:
...
@staticmethod
def assert_schema(instance, api_name):
"""
Assert JSON Schema
:param instance: 请求响应结果
:param api_name: 存放在schema表中的对应key名
:return:
"""
json_schema = Schema().get(api_name)
if json_schema is None:
logger.error('jsonschema未找到!')
raise SchemaNotFound(api_name)
try:
validate(instance, schema=json_schema)
except ValidationError as msg:
logger.error(msg)
raise AssertionError
在 case 层进行断言:
class TestJob(BaseTestcase):
def test_hpc_submit_job(self):
resp = job.submit_hpc_job()
ret_code = resp.get("ret_code")
self.assert_eq(ret_code, 0)
# schema断言
self.assert_schema(resp, 'submit_hpc_job')
会根据第二个参数,去schema表中取对应 key 的jsonschema
schema 表

需要注意的是,schema表中的jsonschema是在接口被调用的时候自动存储的,所以不需要手动操作,但是也是因为这个原因,有可能会存储接口异常时的响应的结构体,所以当要做 jsonschema 断言时,请检查该表,确保该表对应接口的 jsonschema 是符合预期的,当然,aomaker 也提供了一个genson()方法,你可以通过该方法手动获取预期的jsonschema,然后自己存储到schema表中,schema表是固化不会自动清理的,你可以持续校正和维护该表。
2.如何使用genson
只需要传入 json 字符串,genson 会自动返回其jsonschema。
# 导入genson
from aomaker.aomaker import genson
x = {
"age": 2,
"desc": "api framework"
}
schema = genson(x)
print(schema)
# 输出:
# {'$schema': 'http://json-schema.org/schema#', 'type': 'object', 'properties': {'age': {'type': 'integer'}, 'desc': {'type': 'string'}}, 'required': ['age', 'desc']}
8、allure 报告优化
1.自动收集 allure 报告
在每次执行完测试任务后,aomaker会自动收集allure的测试报告,报告位置在项目根目录下的reports\html下,只需要打开该目录下的index.html文件即可。
2.自动记录用例的依赖调用信息
在查看 allure 报告时,可以看到每个 case 的测试步骤,即该 case 调用了哪些接口,并记录每个接口的请求、响应和响应时间等信息:
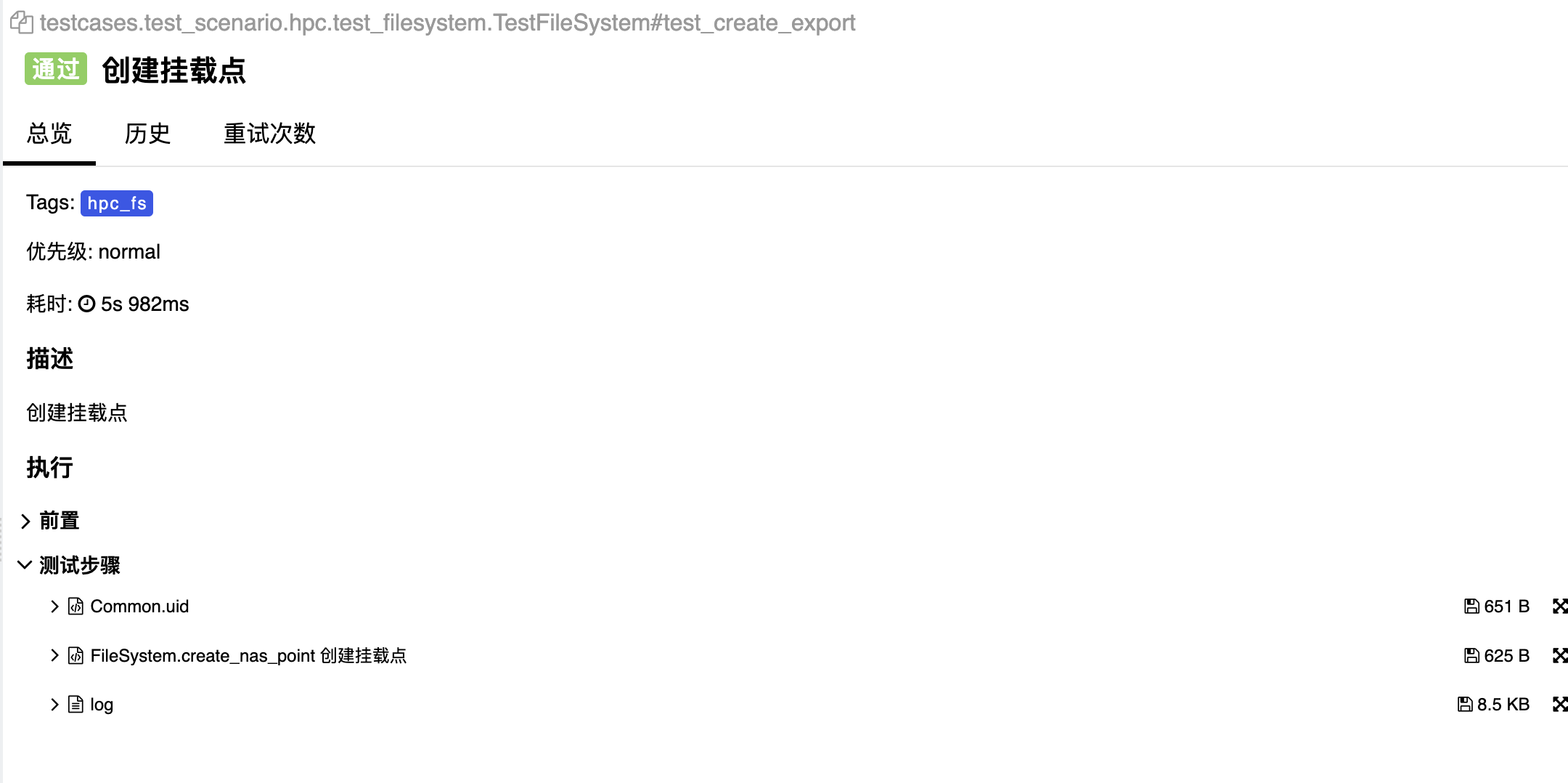

这里可以不用显示去调用allure.step ,每个接口所需要的依赖都会自动记录,如果要标明每个接口的名称,可以在接口的注释中进行注释,allure 报告中会显示每个步骤名为:接口类名.接口方法名 + 接口注释(如果有)。
3.自动记录每个 case 的日志信息
此外,aomaker会自动记录该 case 的所有相关日志信息

篇幅有限,更多特性可以戳可戳《aomaker 使用指南》查看。
交流
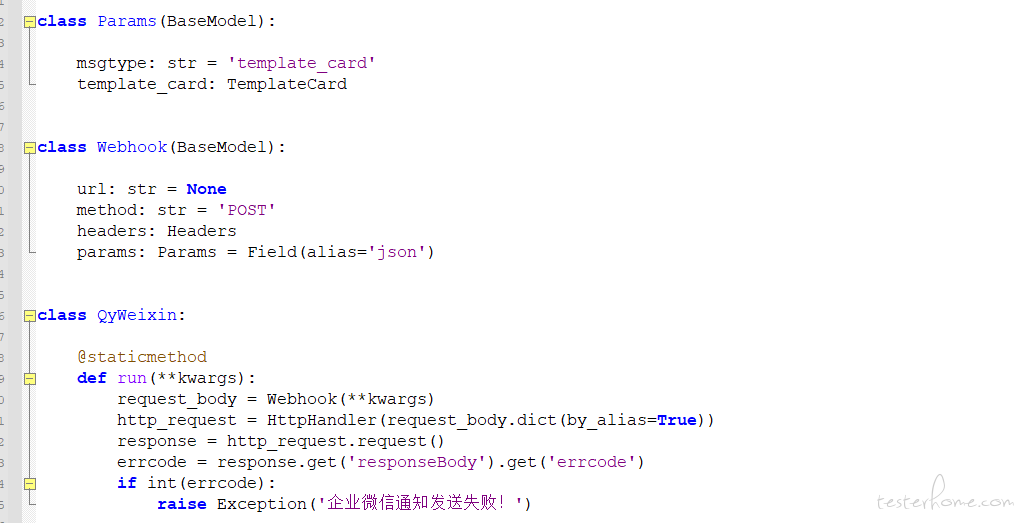
欢迎交流噢,可加 v:ae86sen
鸣谢
最后,必须要感谢httprunner、seldom等优秀框架,从中得到了很多灵感,也学习了很多,像大佬们致敬,也要感谢 j 导在很多疑难问题上给了很好的建议,还要感谢我老大全程的鼎力支持!respect!salute!


 )
)