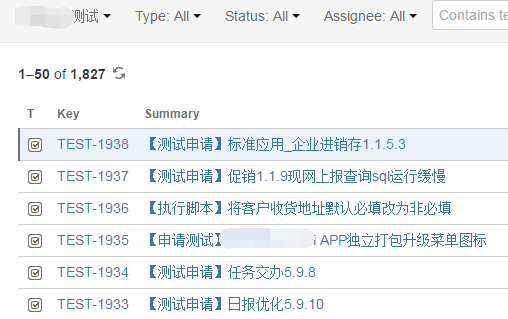
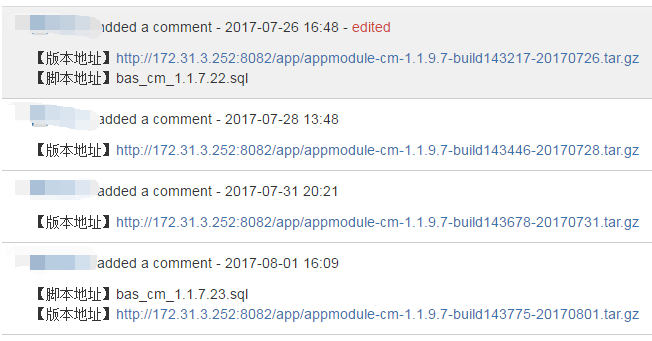
我司也不例外,所有的需求、测试等全在 jira 上面,所有的测试申请都是由开发同学在 JIRA 建一个 TEST 的申请,然后转到测试同学,每一轮测试结束后,开发同学会在 comment 中添加版本地址(内部成为 build),这次介绍的脚本主要用于统计测试申请及每个测试申请的 build 数目
如下面两张图所示:
首先 JIRA 就不多做介绍了,应该没有同学没接触过 jira 吧,很多公司都在用它来管理版本、需求、缺陷等。
我司也不例外,所有的需求、测试等全在 jira 上面,所有的测试申请都是由开发同学在 JIRA 建一个 TEST 的申请,然后转到测试同学,每一轮测试结束后,开发同学会在 comment 中添加版本地址(内部成为 build),这次介绍的脚本主要用于统计测试申请及每个测试申请的 build 数目
如下面两张图所示:
首先安装 jira,同其他第三方库,直接可以 easy_install jira
导入 jira
from jira import JIRA
如果没有报错则说明安装成功
连接 jira
jira = JIRA('http://172.31.3.252',basic_auth=('username','password'))
查询指定 issue 及查看 summary、description、comment
issue =jira.issue('TEST-xxxx')
summary =issue.fields.summary
description =issue.fields.description
comment =issue.raw['fields']['comment']['comments']
网上相关介绍很多,这边只介绍了下面要用的一些,其他的如 add issue、add comment 、modify issue 等操作,由于没用到所以不描述过多
主要分为两个部分,一个是直接在编辑器中 print 出来,一个是通过 xlsxwriter 写入表格中
首先第一部分,直接查询出 issue 和 comment,直接 print
def issue_search():
jira = JIRA('http://172.31.3.252',basic_auth=('xxxxxx','xxxxx'))
issues = jira.search_issues('project = "TEST" and created >= "-10d"',maxResults=10,fields='summary,description,comment')
return issues
#print issue summary
def get_issue():
for issue in issue_search():
issue = str(issue) + issue.fields.summary.encode('utf-8')
print issue
return issue
#print build
def get_comment():
for issue in issue_search():
comments = issue.raw['fields']['comment']['comments']
i = 0
while i < len(comments):
comment = comments[i]['body'].encode('utf-8')
pattern = re.search(r"http://172.31.3.252:8082(.*?)gz",comment)
if pattern != None:
print pattern.group()
i = i+1
return comments
与 jira 建立连接后,直接通过 jql 查询
其中 issues = jira.search_issues('project = "TEST" and created >= "-10d"',maxResults=10,fields='summary,description,comment')
查询 10 天之内创建的,project 为 TEST 的 issue,这边查询条件可以自定义,可以切换为 due , assignee , reporter 等等其他条件,project 也可以切换为其他项目,
fields 只要是下面要用到的,由于我只需要 summary,description,comment,所以这边只加了这三个
用到了简单的正则用来匹配,build 的 url 地址
查询 issue 结果如图所示:
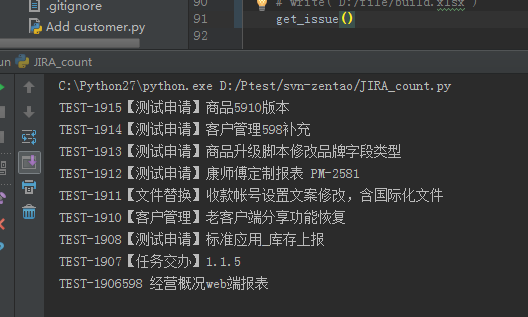
第二部分是将 issue 和 comment
这部分代码和上面不同的就是多了个操作表格的内容,实际上大同小异
#write data
def write(filename):
workbook = xlsxwriter.Workbook(filename)
worksheet_test = workbook.add_worksheet('Test')
worksheet_build = workbook.add_worksheet('build_count')
format1 = workbook.add_format({'bold':True,'align':'left','valign':'vcenter','border':1})
worksheet_test.set_column("A:A",100)
worksheet_build.set_column("A:A",120)
#read and write summary
issues = issue_search()
for i in range(len(issues)):
issue_write = str(str(issues[i]).encode('utf-8') + issues[i].fields.summary.encode('utf-8'))
print issue_write
worksheet_test.write_string(i,0,issue_write,format1)
#read and write build
sum = 0
for i in range(len(issues)):
for issue in issues:
comments = issue.raw['fields']['comment']['comments']
for n in range(len(comments)):
sum = 1 + sum
comment = comments[n]['body'].encode('utf-8')
pattern = re.search(r"http://172.31.3.252:8082(.*?)gz",comment)
if pattern != None:
worksheet_build.write(sum-1,0,pattern.group(),format1)
else:
sum = sum-1
workbook.close()
return workbook
表格格式自定义部分也没做过多编辑,所以实际效果不是很美观,但是能解决问题就行了,不在纠结格式了
以上就是所有脚本介绍,欢迎交流学习
