前言
上一次我们介绍了大数据的一些历史历程和基础。今天我们来讲一讲 spark 的基础吧。 首先 spark 支持 java,scala,R 和 python。大家一定对 java 或者 python 已经熟悉了。 不过我还是建议大家使用 python 或者 scala 来进行 spark 的开发。因为 spark 的 API 大量的使用了函数式编程。java 的语法真的不太适合搞 spark。
搭建学习环境
下载 spark
我使用的是 spark1.6.2。 下载地址:http://spark.apache.org/downloads.html
我们直接下载,然后解压。我们看看里面的目录

python-shell
我们运行 bin/pyspark 之后就进入了 spark 的 python shell。我们为了验证是否成功了,可以运行下面的代码
lines = sc.textFile("README.md")
print lines.first()
接下来就会看到打印出一条信息:# Apache Spark。 spark 提供的 python shell 是我们良好的学习平台。我们可以在里面随意的调用 spark 提供的 API。
IDE 环境
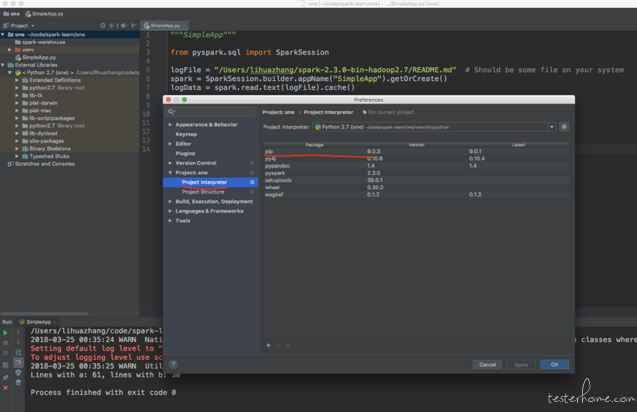
可能有些同学已经习惯了 IDE 带来的好处 (例如我),所以也希望能通过 IDE 来进行学习和开发。 但是 spark 并没有提供任何 python 模块给我们下载使用, 也就是说,你无法通过 pip install 的方式下载 spark 模块。 这一点就不如 java 和 scala 了,maven 是可以直接集成 spark 的。 所以我们要做一点额外的事情以让 pycharm 能够拥有开发 spark 程序的能力。
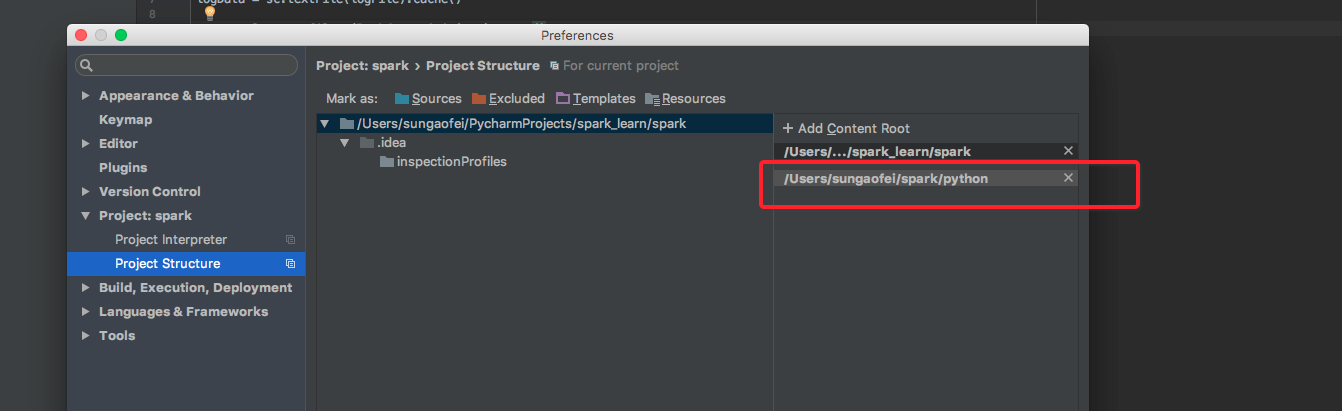
在 pycharm 找到 Project Structure 把解压的目录中的 python 目录加进去
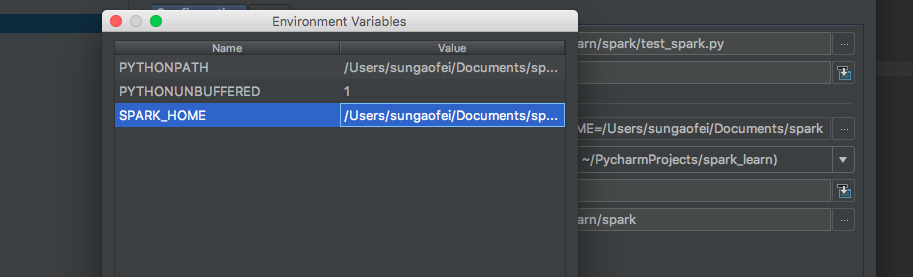
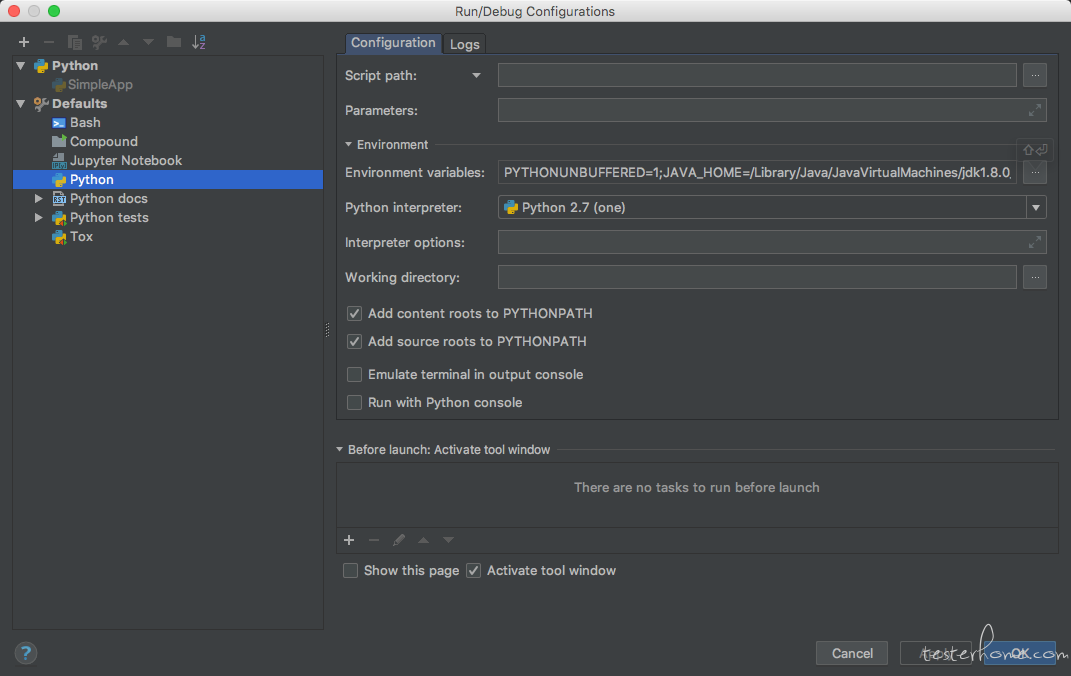
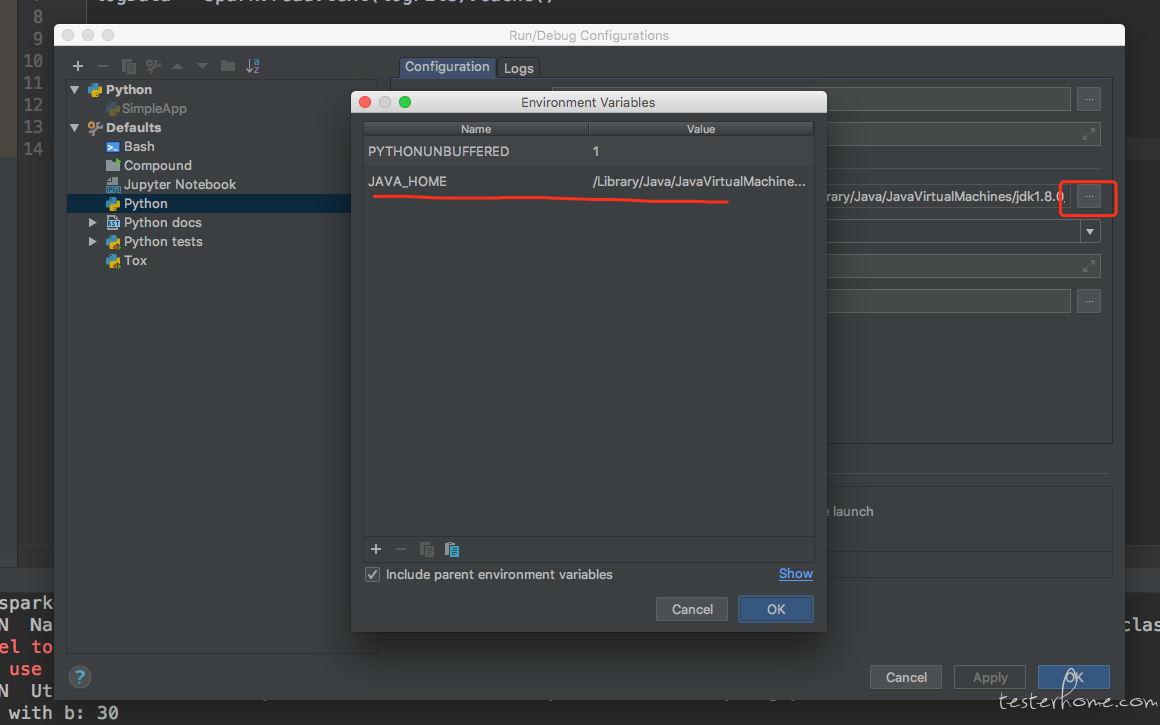
添加 run-->Edit configurations。 添加一个运行配置。并配置 SPARK_HOME 环境变量为解压目录。然后配置 PYTHONPATH 环境变量为解压目录中的 python 目录。
然后各位就可以在 pycharm 上编写 spark 代码并运行了。
"""SimpleApp"""
from pyspark import SparkContext
logFile = "/Users/sungaofei/Documents/spark/README.md"
sc = SparkContext("local","Simple App")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
temp = logData.first()
print temp
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))
从 demo 中学习
"""SimpleApp"""
from pyspark import SparkContext
logFile = "/Users/sungaofei/Documents/spark/README.md"
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
temp = logData.first()
print temp
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))
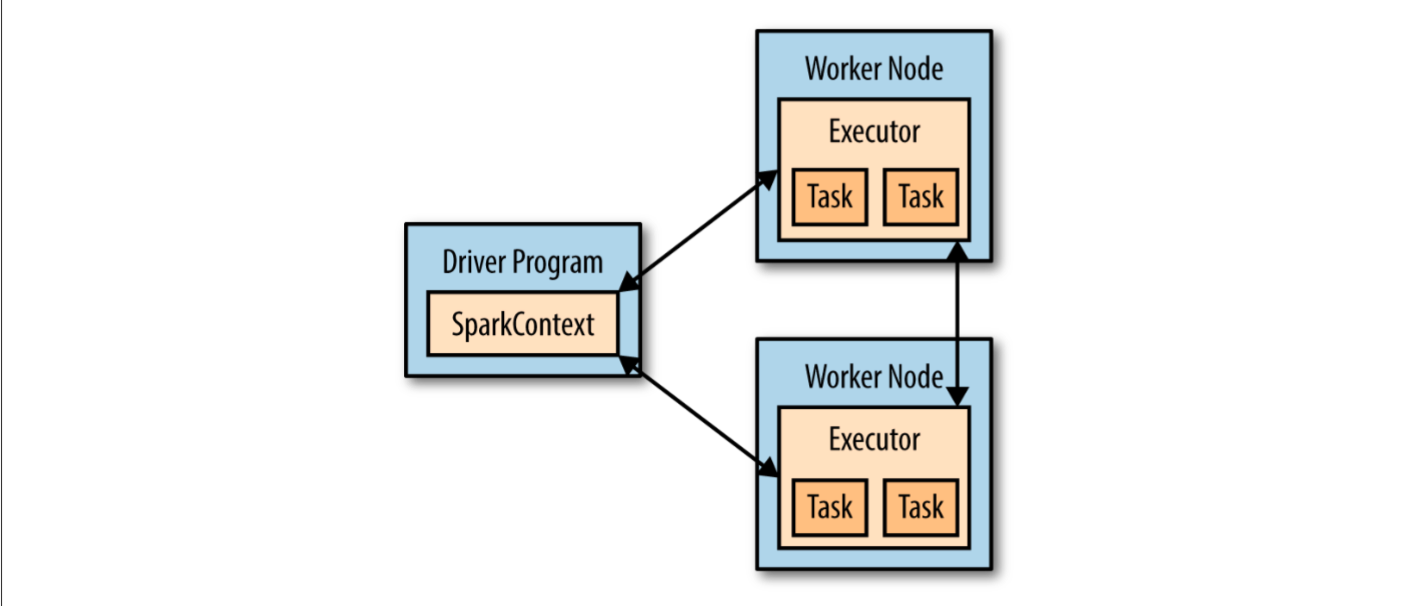
在全局的 level,spark 的应用是由一个驱动程序在集群中发起并行的多个操作。这个驱动程序包含了你的应用的 main 函数并定义了你的分布式数据集合。在上面的例子中,我们可以理解 SparkContext 对象就是 spark 的驱动。它负责连接集群,我们用local模式告诉 spark 我们使用本地集群模式以方便我们学习和调试。在你有了这个驱动之后,我们就可以随意的创建 RDD 了,RDD 是 Spark 的分布式数据集合的定义,我们暂时只需要知道它是存储数据的地方,之后会详细说明一下。 sc.textFile() 是从一个文本中读取数据并转换为 RDD 的方法。当我们有了 RDD 之后,就可以随意调用 spark 提供给我们的方法。例如上面例子中的 filter(熟悉 python 的朋友一定觉得这个方法很熟悉) 以及 count 方法。 在我们上面的操作中。 驱动程序会在集群中管理一定数量的 executor。 例如当我们调用 count() 方法的时候。集群中不同的机器会各自读取这个文件中的一部分并分别计算各自的行数,当然了现在我们使用的是 local 模式。所以我们的应用是运行在单机上的。整个过程差不多是下面这个样子的。
在这个 demo 中,我们是可以看到 spark 是支持函数式编程的,大部分的方法都要求传递一个函数进去。例如上面的 filter 方法。这是一个过滤函数,上面的 demo 中我们分别取包含字母 a 和 b 的行。熟悉 python 的小伙伴一定对 lambda 表达式不陌生了。
RDD 基础
上面提到过 RDD,它是 spark 定义的固定不变的分布式数据集合
- 说它固定不变是因为它一经创建后你就无法改变它的内容了。你只能通过当前的 RDD 调用一些方法来生成新的 RDD,但是你永远都无法真正改变一个 RDD 的数据。例如刚才的 demo,我们调用 filter 方法过滤掉一些数据,但我们并没有改变原有 RDD 的数据,你在其他地方调用原 RDD 的时候仍然是全量的未经过滤的数据。 filter 方法返回的是一个新的 RDD
- 说它是分布式数据集合是因为每一个 RDD 都由多个 partitions(分片) 组成。上一篇我们讲到 HDFS,所以首先数据是分布在不同的机器上的。在 spark 读取数据的时候会根据一定的规则 (可以是默认 64M 一个 partition,也可以指定 partition 数量)。 这些分布在不同 partition 也就是数据分片组成了 RDD。spark 在运行的时候,每个 partition 都会生成一个 task。他们会跑在不同的计算资源上。我们知道 java 中万物皆对象,在 spark 中所有数据皆 RDD。可以说 RDD 就是 spark 的一切,就如 MapReduce 就是 Haddop 的一切一样。
我们可以使用两种方式创建 RDD
- 通过 sc.textFile() 从外部文件中读取。就如我们的 demo 一样
- 通过从一个集合中初始化一个 RDD。如下:
lines = sc.parallelize(["pandas", "i like pandas"])
transformations and actions
RDD 支持两种操作,transformation 和 action。ransformation 的操会返回一个新的 RDD,就如我们在 demo 中看到的 filter() 方法,是一种组织和准备数据的方式。为之后的 action 执行计算提供数据基础。action 的操作是真正产生一个计算操作的过程。例如 demo 中的 count()。 action 不会返回一个 RDD,它会返回实际的操作结果或者将数据保存到外部文件中。spark 提供了很多函数,如果你分不清哪些是 transformation 哪些是 action。 只要看它的返回值就好了。返回一个新 RDD 的就是 transformation,不返回的就是 action。 区分一个函数是哪种操作很重要,因为 spark 处理这两种操作的方式很不一样。
transformation
transformation 是一种返回一个新的 RDD 的方法。它遵循延迟计算的规则。也就是说 spark 在运行的时候遇到 transformation 的时候并不会真正的执行它,直到碰到一个 action 的时候才会真正的执行。我们稍后会专门讨论延迟计算的规则。这里我们知道有这个概念就好。大部分 transformation 都是按行元素处理,就是说他们同一时间只处理一行数据 (有少数 transformation 不是的)。就像上面说的,spark 大部分的函数都是函数式编程,要求我们传递一个函数作为参数。那么所有 transformation 都是需要传递至少一个函数作为参数的, 这个参数就是我们指定的如何处理数据的逻辑。spark 会将数据拆成一行一行的并作为参数调用我们指定的函数。就如 demo 中的 filter,spark 会将 RDD 的每一行作为参数传递给我们自定义的函数。
action
像之前说的 RDD 可以使用很多的 transformation 来组织和准备数据,但是光准备数据还是不行得,我们终究要用数据计算一些东西,这时候就需要我们的 action,就如我们 demo 中的 count() 用来计算数据的行数. 我们还可以使用 frist() 取出第一条数据,用 take(n) 来取出前 n 条数据,saveAsTextFile() 用来把数据存储到外部文件。也就是说 action 是我们真正使用数据来进行计算的方式,真正实现数据的价值的方式。
延迟计算
之前提到过,transformation 的操作是延迟计算的。意思是说 spark 在运行的时候,运行到 transformation 的时候实际上并不会真正的执行 transformations。直到碰到了这个 RDD 的 action 的时候,才会一股脑的执行之前所有的操作。也许这对刚接触大数据处理的同学来说有点难以理解,但如果我们仔细的想一想就会发现其实这样的设计相当的合理。 因为我们在实际情况中面对的是非常庞大的数据。如果我们在一开始就执行所有的数据操作并将数据载入内存中那将是一种很大的浪费。例如在 demo 中,如果我们使用的不是 count 这种操作全部数据的方式而是使用了 first() 或者 take(n) 这种只取了一部分数据的操作。那么事先就执行 transformation 的操作并将所有数据载入内存的话,那将是极大的浪费。所以取而代之的,spark 在每次遇到 transformation 的时候并不会立刻执行,而是通过一些元数据记录 RDD 的操作轨迹,在遇到 action 的时候再推断出最优的解决方案。
常见的 transformation
map
除了我们在 demo 中看到的 filter() 方法来过滤数据,我们还可以使用 map() 这种 MapReduce 时代保留下来的函数。看下面的 demo
nums = sc.parallelize([1, 2, 3, 4])
squared = nums.map(lambda x: x * x).collect() for num in squared:
print "%i " % (num)
刚才我们说大部分 spark 的 transformation 是单行处理的。所以当我们把 lambda 定义的匿名函数传递给 map 的时候。 map() 会把数据中的每一行取出来作为参数进行调用。它和 filter 的区别可以用下图来表示。
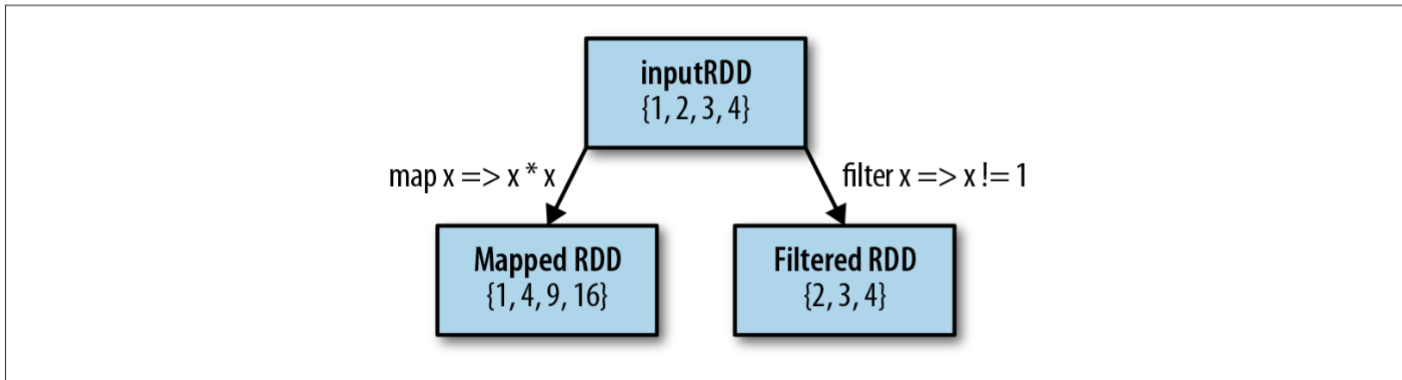
flatMap()
与 map() 很相似的一个方法是 flatMap()。map 的操作是处理每一行的同时,返回的也是一行数据。 flatMap 不一样,它返回的是一个可迭代的对象。也就是说 map 是一行数据转换成一行数据,flatMap 是一行数据转换成多行数据。例如下面的 demo
lines = sc.parallelize(["hello world", "hi"])
words = lines.flatMap(lambda line: line.split(" "))
words.first() # returns "hello"
words.count() # returns 3
下图可以表示 map 和 flatMap 的区别
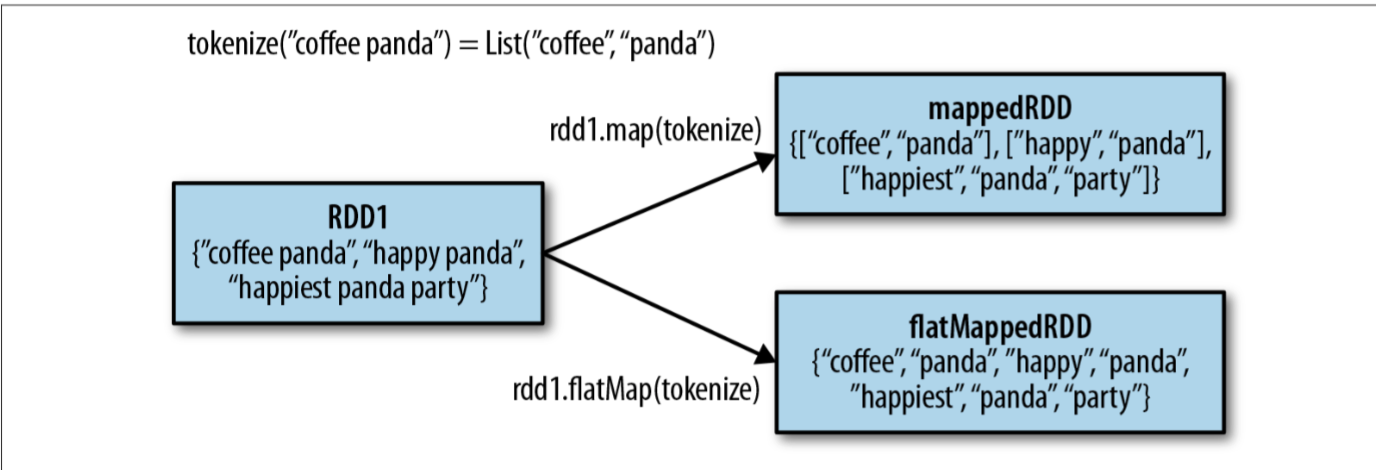
集合操作
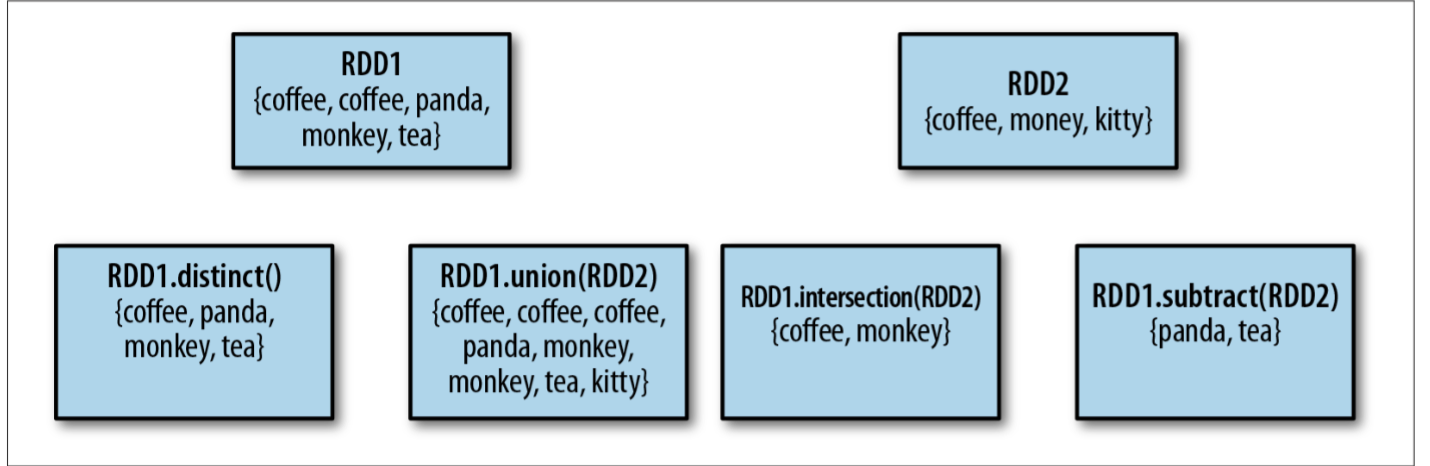
上图表示了 4 种集合操作。
action
reduce
最常用的 action 操作是我们在 MapReduce 时期就熟悉 reduce 操作,此操作是一个聚合方法。demo 如下:
rdd = sc.parallelize([1,2,3,4,5])
sum = rdd.reduce(lambda x, y: x + y)
reduce 接受一个函数当做参数,而这个函数也接受两个参数 x 和 y。 这俩个参数代表着 RDD 中的两行,reduce 是聚合函数。 它会不断的将之前计算出的两行传递给函数进行聚合计算。上面 demo 中的 sum 为 15.因为 reduce 做了一个累加的操作。
其他
此外还有我们早就见过的 count(),以及一些其他的例如:
- collect():返回 RDD 中所有的数据
- countByValue():统计每一个 value 出现的次数
- take(n):取出前 N 行数据
- foreach:循环 RDD 中的每一行数据并执行一个操作
persist
我们上面说过从性能上考虑 RDD 是延迟计算的,每遇到一个 action 都会从头开始执行。这样是不够的,因为有的时候我们需要重复使用一个 RDD 很多次。如果这个 RDD 的每一个 action 都要重新载入那么多的数据,那也是很蛋疼的。 所以 spark 提供了 persist 函数来让我们缓存 RDD。
lines = sc.parallelize(["hello world", "hi"])
a = lines.flatMap(lambda line: line.split(" ")).persist()
a.count()
a.take(10)
上面我们使用 persist 函数缓存了 RDD。所以再调用 count() 和 take() 的时候,spark 并没有重新执行一次 RDD 的 transformation。spark 有很多缓存的级别。可以参考下面的图表
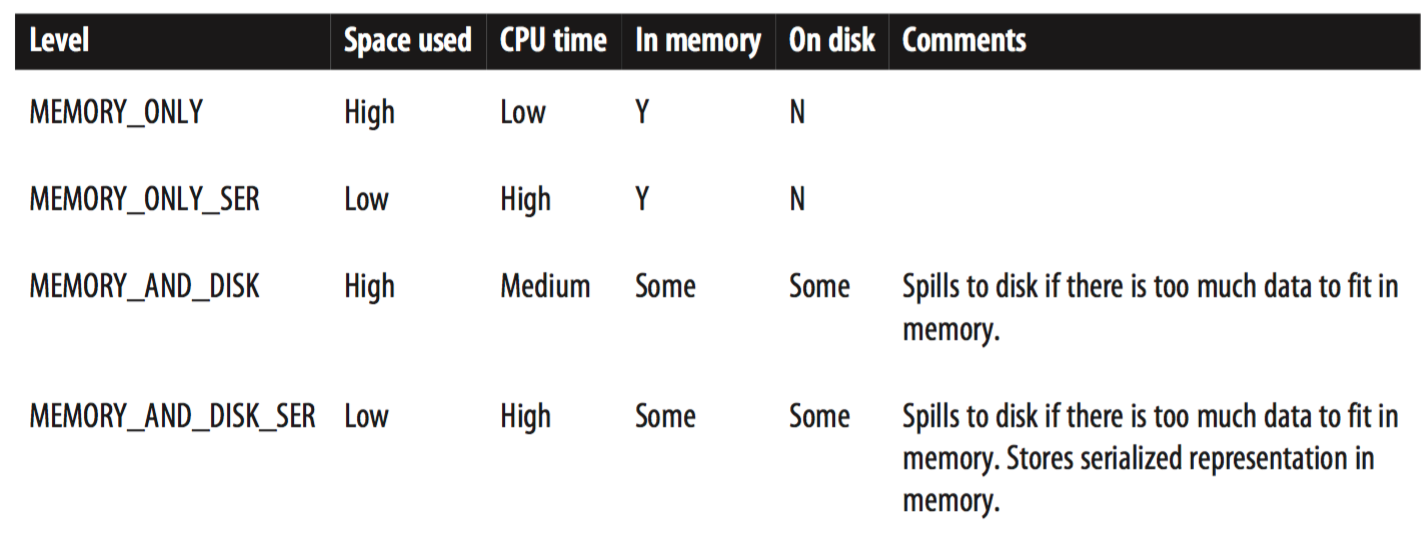
可以使用 persist(storageLevel='MEMORY_AND_DISK'),像这样的方式指定缓存级别。 默认是 MEMORY_ONLY。
总结
spark 的一些基础就讲的差不多了。 知道这些基本的知识基本上就可以写写 demo 了。 之后的帖子我会讲讲 spark sql,键值对的 RDD,shuffle 等方面的东西。 可能有的同学觉得学这些没多大用,我们测试用不着这些。 恩,一般的测试类型确实用不着。 我讲这些也是给数据测试和人工智能测试做个铺垫。 因为大数据是这些测试类型的基础。
 学习了
学习了 天哪噜,测试开发这么难啊
天哪噜,测试开发这么难啊