春节结束,公司就要开始讨论接口自动化测试的议题了。
遇上参考了 testerhome 中接口测试的文档,自己写了一个接口自动化测试的原型。
因为没有接触过接口自动化测试,都是自己凭空想象的,肯定有很多不足的地方,希望大家指教。
语言:python2.7
数据驱动:execl
自动化测试对象:http 协议的接口,返回值是用 json 解析的。
第一步,参数
我以前做过一段时间单元测试,那个时候等号右边的叫做输出值,等号左边的叫做输入值。
于是我拿以前做单元测试经验来设计,我们的 request 就好比一个输入值,那么 response 就是一个输出值。
request 里其实就是很多参数的组合排列,如果想做一次覆盖率相对高的接口测试的话,个人觉得先把每个参数可能的值罗列出来
比如 有一个参数 n ,根据文档他可以是 -1,25950,25951,25952,25923 中的任意一个数,那么我们设计的时候处了这 5 个输入值考虑进入,还要考虑
0,
边界值:-2,0,25949,25924,
任意值:10 之类的,
空:就没有改参数没有写。
单单参数的排列组合,我觉得就是一个庞大的数字了。
作为覆盖率高为目标的话,我觉得要把这些排列组合都列出来,然后根据实际情况对 case 进行删除。
如果排列组合出来的 case 数量可以接受,也可以直接使用。
那我就先把参数进行一次排列组合
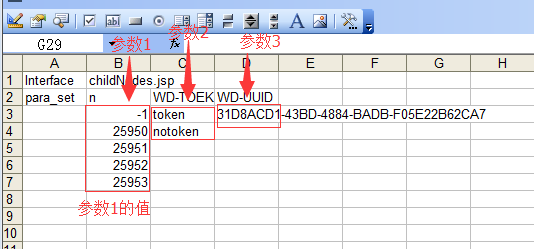
根据参数运行函数 init_para.py
生成了 work sheet,里面存放着 request 的参数的值进行排列组合后的全 case
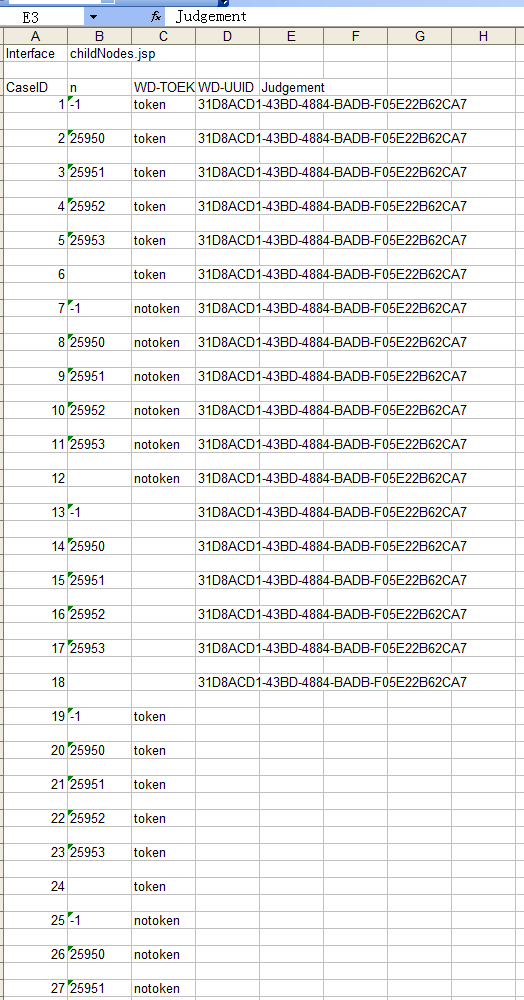
第二步,发送 request,得到 response。
这个在社区里有很多列子了,百度也可以查到,就不需要多讲了。
第三步,解析 json
正如我前面说的,我们拿到了一个 json,我们就需要解析他。
我们先来看下我做的 json 解析的效果。
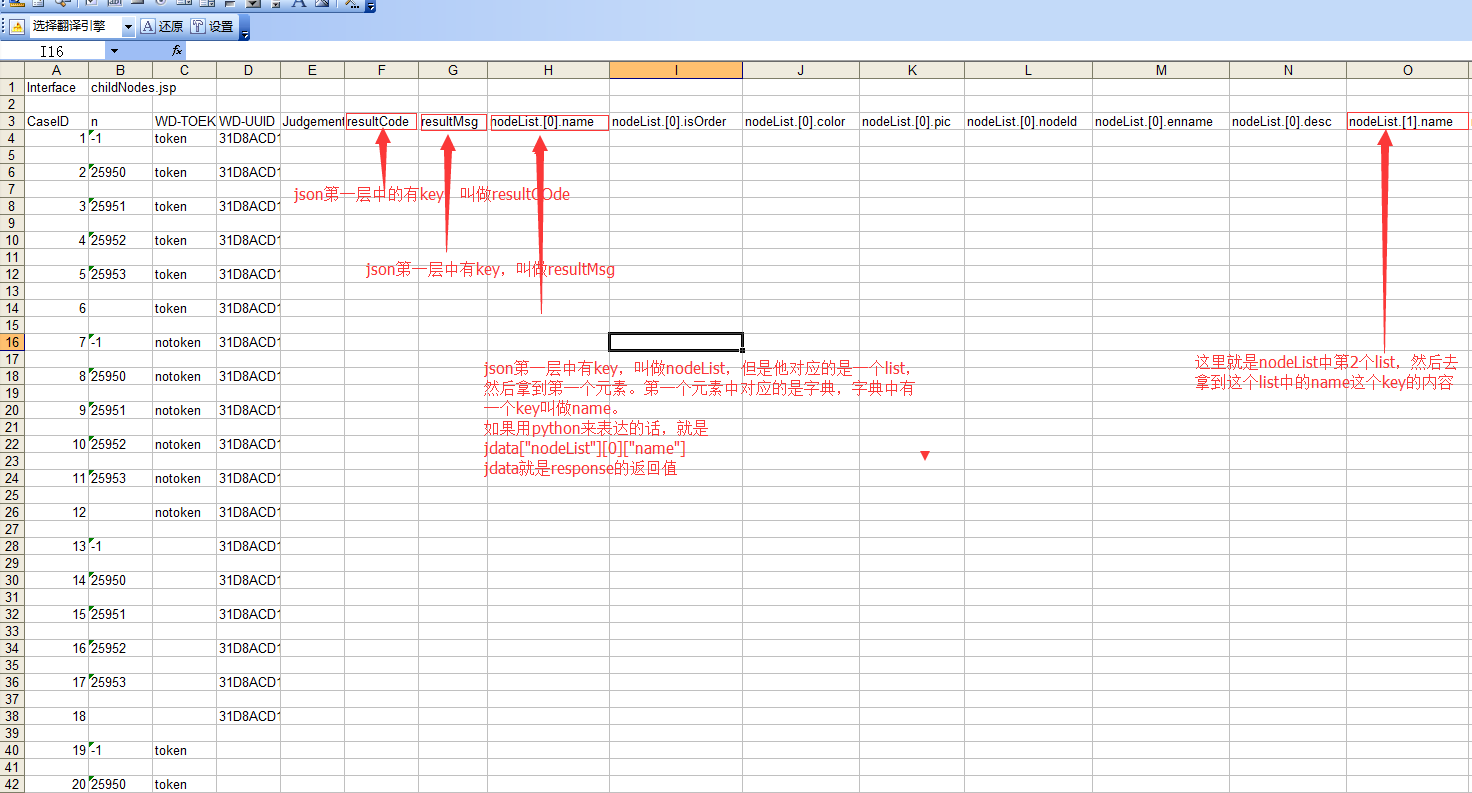
可以看到经过处理,我们可以拿到每个有实际内容的 json 的路径。
当然了,这个用一次制定的的参数提交的 request,然后拿到的 response 的 json 进行的解析,如果想拿到最大范围的解析,一定要仔细设计这次 request 的参数
第四步,期待值得设置
有了输入和输出,那么就需要写预期值。
我想到了 3 种预期值得输入方法。
1.手工填写
根据接口文档,去手动填写相对应的预期值。
这个绝对是一个体力活,除非 case 相对较少,不然不推荐。但是绝对精确(如果真的有人可以有耐心去正确填写完全部的预期值)
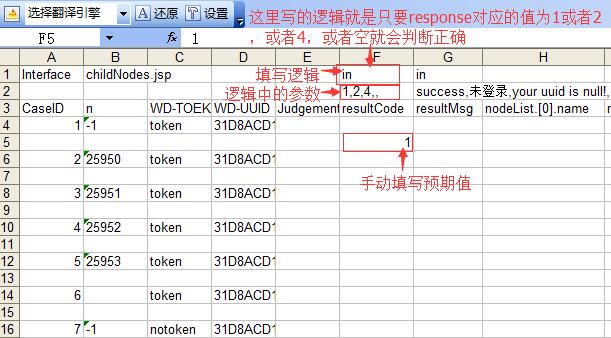
2.用逻辑去判断
比如返回值是在某个数组的当中
逻辑判断最大的有点是,如果你写的是一个 sql 语句,那么预期值就是直接冲数据库里动态拿到,这个我觉得是最重要的。
3.运行一次程序,得到 case 的相对应的结果,然后把结果复制给预判值。
这种方法适合用于回归测试,因为这种做法的前提就是假定当前的接口是没有错误的。
第五步,返回结果和预期值的比较
看图说话

底色为蓝色说明这个返回值因为没有给过期待值,但是和逻辑判断中的值符合
底色为绿色说明这个返回值和预期值一致。
底色为红色说明这个返回值和预期值不一致或者说没有和逻辑判断中的值符合
我能想到的接口测试框架暂时就这么多了。不足的地方,请大家指教。
很多细节的地方还没有考虑到,或者因为没有经验根本没有想到。
接下来就是请大家解惑。
- execl 宽是有限制的,我这个 execl 版本比较老,超过 256 个字段就不行了。 如果用 js + mysql 的话 应该可以比 256 个多的多。 到底在真实的工作中,那种组合用的比较多 python+execl js+mysql
2.如果接口自动化要推广,肯定需要一个相对易用的界面。有多少公司用了图形界面,有多少公司用的是命令行,或者直接使用脚本的?
3.我们在实际工作中接口测试真的会做到那么细致吗?
主要我把 request 的参数做了一次全遍历的组合,发现真的要到达一个高覆盖率的测试的话,case 可能是万级别的。
response 的 json 数据真的要去完全分析的话,可能都要分析到百级别的。
我看到社区很多自动化接口测试基本上都是基于回归测试,也就是说录制接口的返回数据脚本,生成一个预期值,再跑第二次,进行一次 diff。感觉就是项目中期介入。
如果是项目初期就开始设计接口测试,大家应该是怎么做的?
代码我这里就不贴了。
需要参考可以去这里看
https://git.coding.net/lunamagic/test_of_api.git