这两天趁着有时间,我疯狂的码字了~~
我们公司是做人工智能平台的,什么是人工智能呢? 大数据 + 机器学习。大数据运行的基本就不快。机器学习算法运行起来也是慢的让人泪流满面。在我们的集群配置下,我使用一个 5M 的数据从数据引入到数据处理,特征工程,模型训练和评估报告等等一整套线下模型调研流程要 10 分钟左右。所以单线程执行测试用例是不靠谱的。而 UI 自动化在一台机器上只能是单线程执行。所以多台机器同时运行 case 的分布式处理方案呼之欲出。
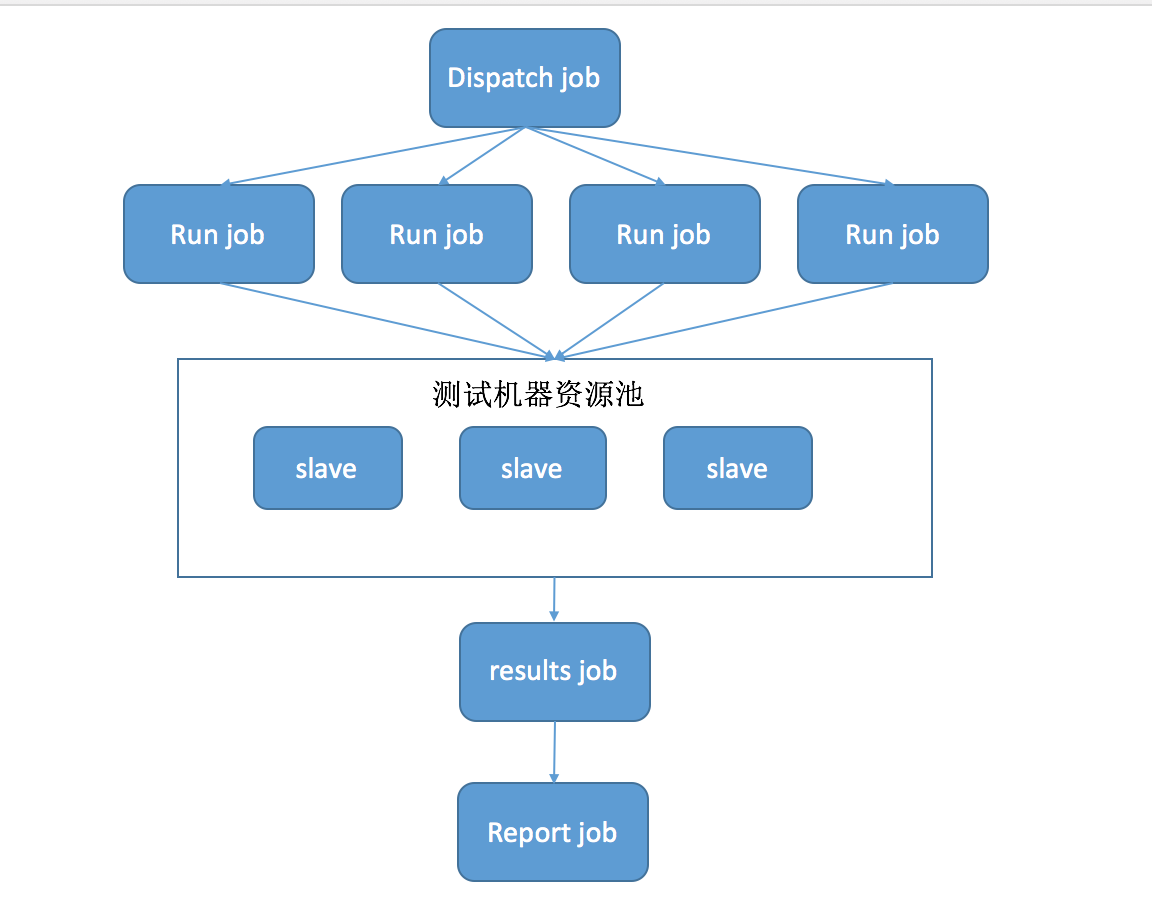
原理其实很简单。 我分步骤说一下
总结一下我们需要多台测试机器和 4 个 job。分别是 dispatch job,run job,results job 和 report job。 大概的样子如下:
这个比较简单,大家可以到网上找详细的教程。只需要记得创建的 node 要统一一个 label 比较好管理。如下:

这个 job 基本就是由 shell 脚本构成的,通过 shell 来调用 jenkins 的 API。如下:
#!/bin/sh
#输出构建者的信息
echo $BUILD_USER_EMAIL $BUILD_USER > tigger_user_info
#检查是否有任务还在跑
STATUS=`curl -v --silent "http://jenkins.4paradigm.com/job/prophet-test-run/api/json?tree=builds\[result\]" 2>&1 | grep -o "{\"result\":null}"`
#测试任务URL
RUN_JOB_URL="http://jenkins.4paradigm.com/job/prophet-test-run/buildWithParameters?token=prophet"
if [ "$STATUS" = "" ]; then
curl "$RUN_JOB_URL&env=$env&branch=$branch&group=atomTest.xml"
curl "$RUN_JOB_URL&env=$env&branch=$branch&group=model_train.xml"
curl "$RUN_JOB_URL&env=$env&branch=$branch&group=dataload.xml"
curl "$RUN_JOB_URL&env=$env&branch=$branch&group=smoke.xml"
printf "下发测试任务成功!\n"
else
printf "测试服务器繁忙,下发测试任务失败!\n"
exit -1
fi
#任务下发成功后删除上次构建产生的结果
rm -rf ../../prophet-send-report/workspace/allure-results/*
逻辑比较简单,首先检查当前还有没有 run job 在执行,如果有,那么执行失败。其实应该等待的执行结束的,只是暂时还没加这段逻辑。如果没有 run job 在执行。那么调用 run job 的 API 把测试任务分发下去。其中要把一些参数传递过去。例如运行环境,测试代码分支,测试用例的 group
这个 job 比较常规,配置有点多我不详细的列举了。无非就是配置 git lab,拉取测试代码并 build 运行测试。其中 slave 测试机是注册在这个 job 里的。有一个需要注意的地方是 run job 运行结束后触发下一个 results job,需要传递一个比较重要的参数-- build number。因为下一个 job 需要知道 run job 的 build number 好去归集测试结果。如下:
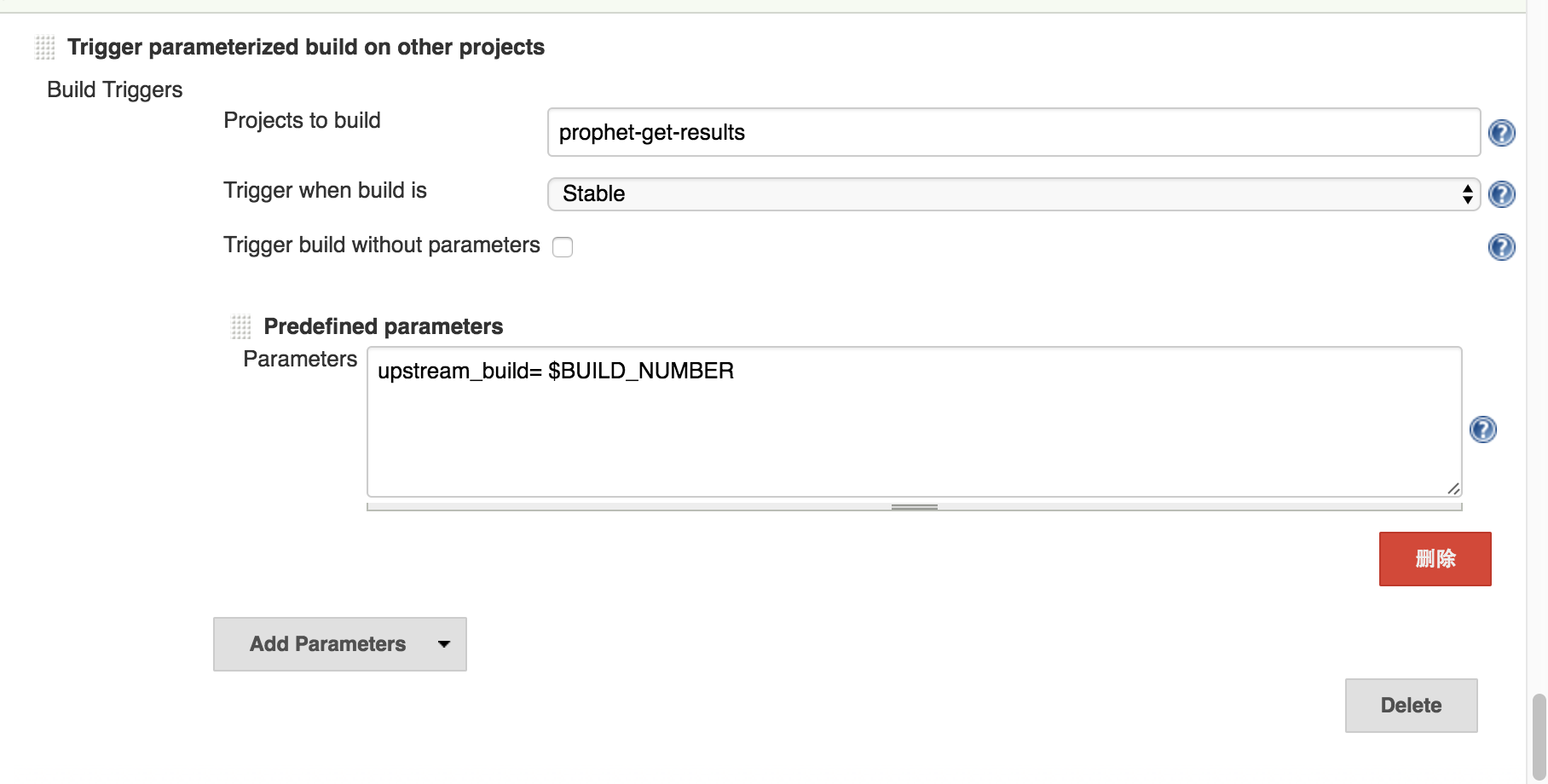
对了还有一个特别重要的东西。为了要把测试结果从 slave 测试机上拉到 jenkins 上。我们需要剑走偏锋。配置如下:
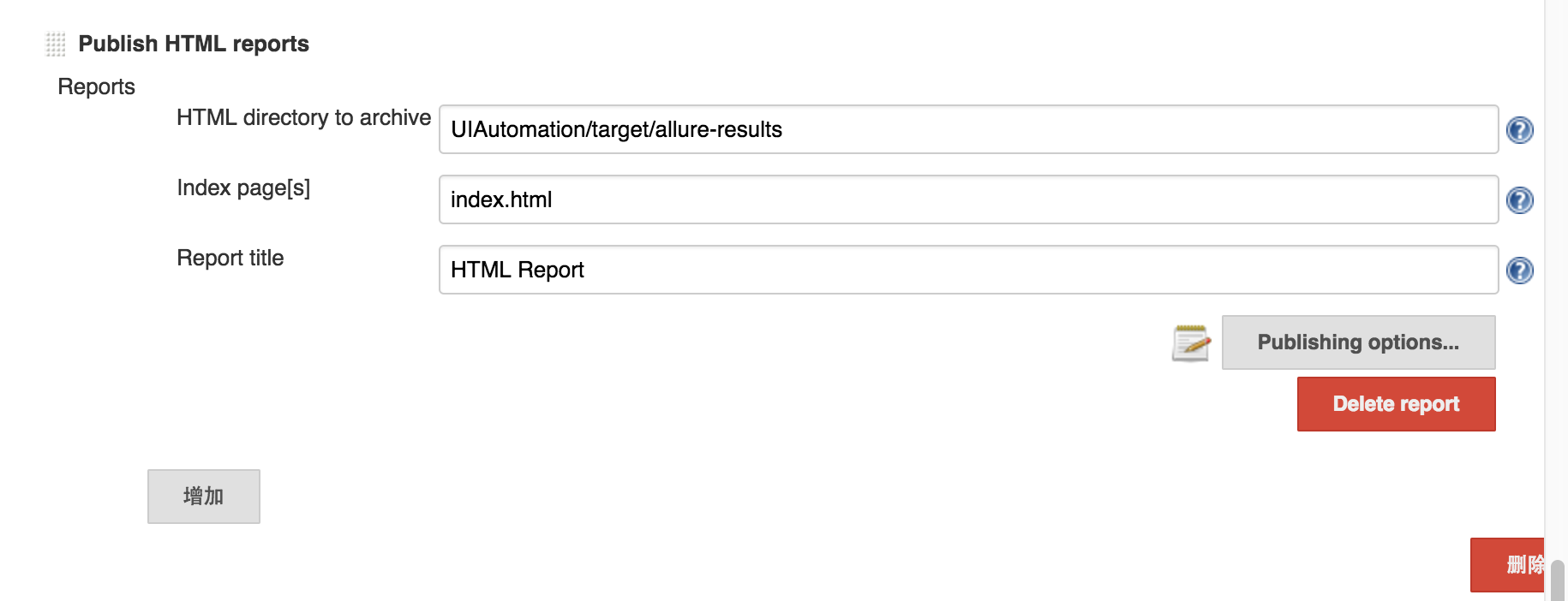
其实这个时候我们并不希望在 run job 上就生成 html 的 report,我们指向的目录也不是 report 的目录。而是存放测试结果的 xml 文件的目录。jenkins 默认是不会从 slave 测试机上拉取这些文件的。为了让 jenkins 拉取这些文件,所以我们利用这个 html report 插件强行让 jenkins 把他们拉取上来。
这也是一个有 shell 构成的 job。脚本如下:
#!/bin/sh
sleep 5s
# 通过run job传递的build number 将测试结果保存到特定目录下
folder="../../prophet-test-run/builds/$upstream_build/htmlreports/HTML_Report"
if [ -d "$folder" ]; then
cp -r "$folder" ../../prophet-send-report/workspace/allure-results/$upstream_build
fi
#获取测试执行Job里是否有未完成的任务
STATUS=`curl -v --silent "http://jenkins.4paradigm.com/job/prophet-test-run/api/json?tree=builds\[result\]" 2>&1 | grep -o "{\"result\":null}"`
if [ "$STATUS" = "" ]; then
#获取构建人信息
user_email=`awk '{print $1}' ../../prophet-task-dispatch/workspace/tigger_user_info`
user_name=`awk '{print $2}' ../../prophet-task-dispatch/workspace/tigger_user_info`
#邮件任务URL
EMAIL_JOB_URL="http://jenkins.4paradigm.com/job/prophet-send-report/buildWithParameters?token=report"
#触发发送报告任务
curl "$EMAIL_JOB_URL&user_email=$user_email&user_name=$user_name"
printf "下发邮件发送任务!\n"
else
printf "还有测试任务正在执行!\n"
fi
逻辑也十分简单,根据 run job 传递 build number,copy 测试结果到特定的目录。 这里简单说明一下 jenkins 的目录结构。每个 job 都是存放在一个叫 jobs 的目录下,job 目录里面有 builds 和 workspace 两个文件夹。builds 目录分别存放每一个 build 的执行结果,results job 就是跑去 run job 的 builds 目录 copy 执行结果到 reports 的 workspace 目录下 (run job 传递过来的 build number 起作用了). workspace 目录就是 jenkins 上看到的工作控件了。我们 shell 就是在这个目录下运行的。 还有一个事,每个 run job 都会调用 results job 的。但是我们只希望最后一个 run job 结束后才让 results job 调用下游的 report job 来生成 report 并发送邮件。所以我们的 shell 脚本中才会有判断当前还有没有 run job 运行的逻辑。没有了才会调用 report job
终于到了 report job。我们做了一堆配置,写了一堆脚本就是为了能成功合并测试结果并生成 html 的 report。这个 job 的任务非常简单,results job 已经把之前运行的所有测试的结果 copy 到了 report job 的 workspace 下。所以它要做的事情只有两件事,合并测试结果生成 report 以及发送邮件。 由于我用的 report 框架是 allure,所以直接用的 jenkins 上针对这个框架的插件。所以配置基本是很简单的。如下:

每一种 report 框架都会有 merge 测试结果的机制。大家根据自己的使用情况选择吧。
我澄清一下我使用的框架吧。 语言是 java,框架主要用的 testng,selenide,maven。 report 框架为 allure。所以才有上面一整套的配置。如果大家用的技术体系不一样,上面的分发任务和生成 report 的配置可能是不一样的。
这个所谓的分布式执行处理的最大的难点其实就是测试结果的归集和 html report 的生成。我们起码有一半的工作都是为了达到这个目的。所以选取一个好的 report 框架是比较重要的。因为我是 java 系么。所以选择了 allure。allure 在 merge 测试结果方面挺方便的,同时我觉得 allure 是流程测试中尤其是 UI 自动化测试中最好的 report 框架。所以在这里还是小推销一下。它的效果图如下:
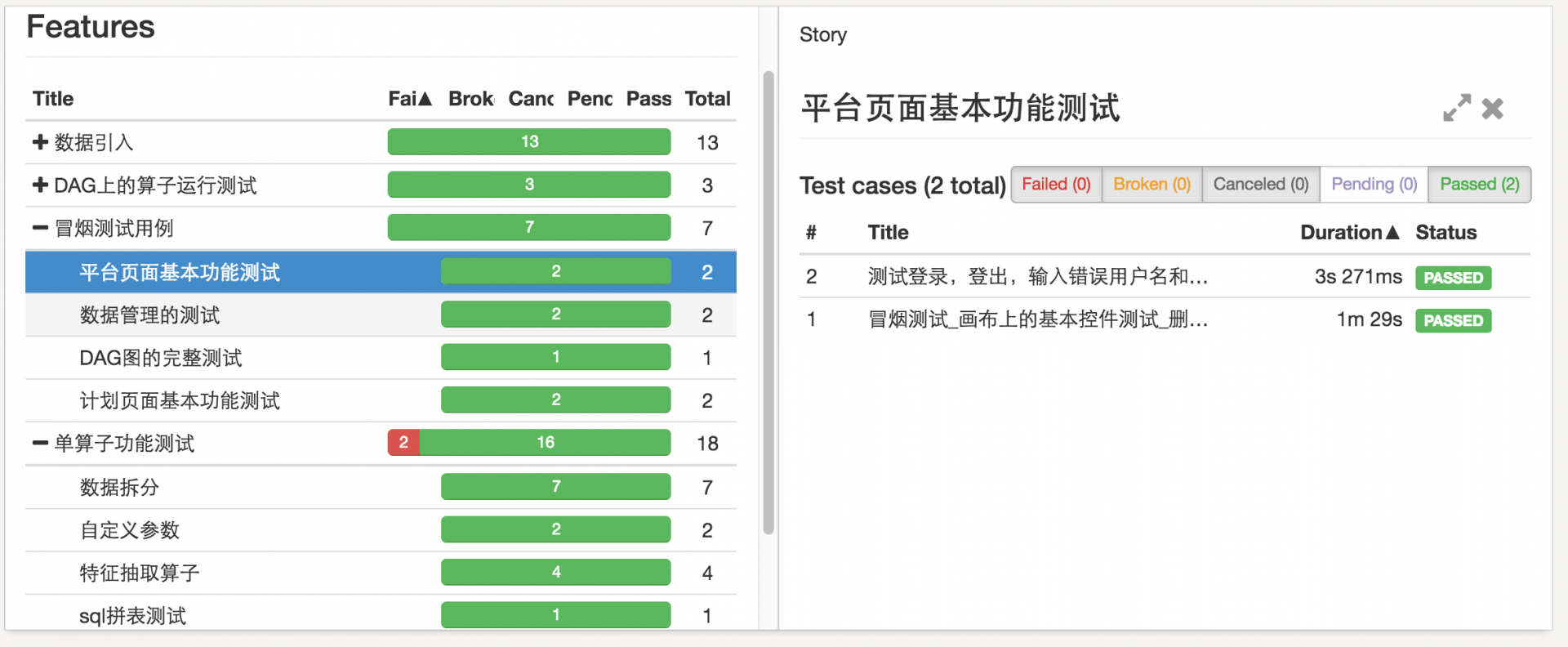
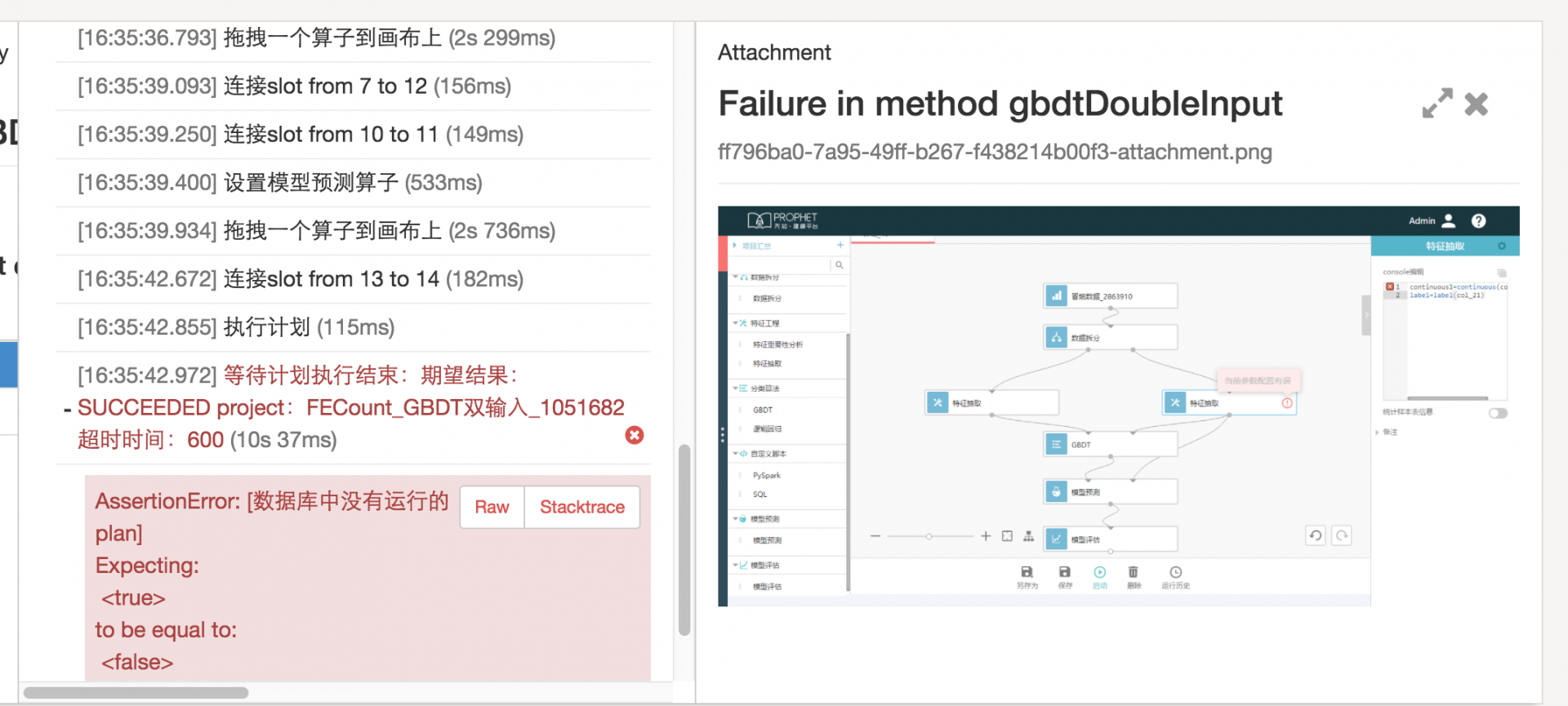
可以看到它不仅有强大的测试分类功能。还可以详细的记录你每一步的操作并展示在 report 中。显示截图的功能也很棒。另外还有不同维度统计功能。例如这个时间统计:
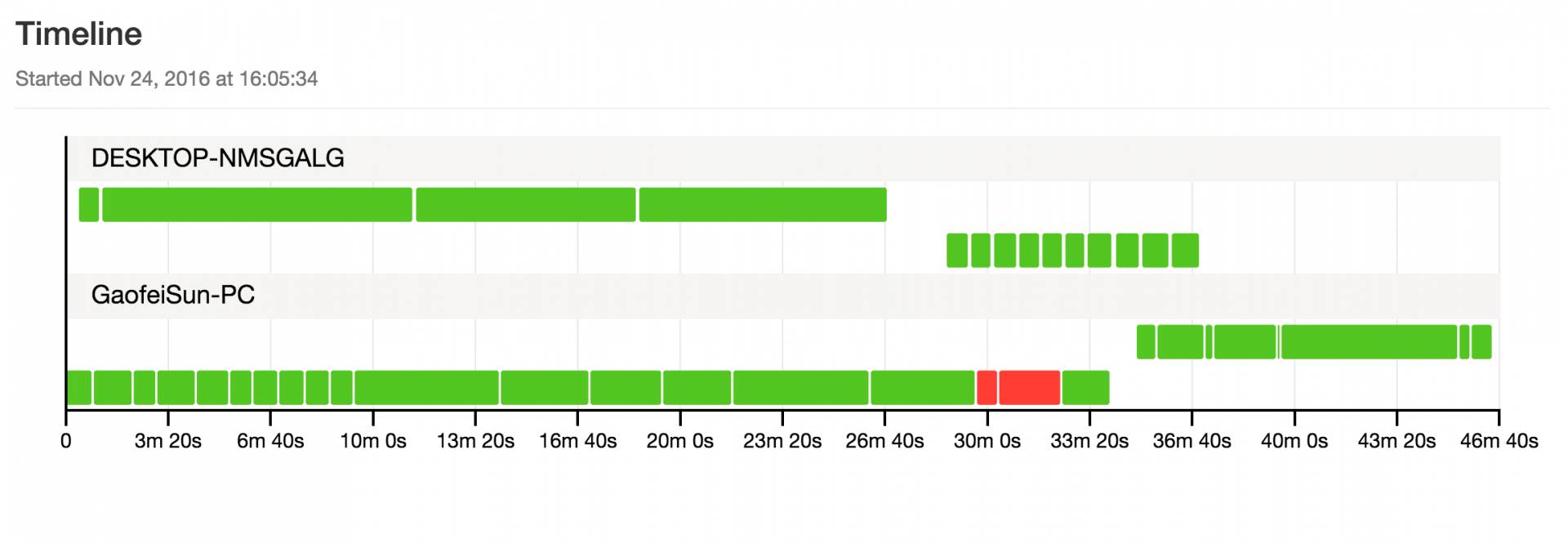
可以看到它展示了每台 slave 测试机上的 case 运行时间。可以让你调整用例的分组策略。不会让某一个 group 运行时间过长影响整体运行效率。下面是只列出失败的 case:
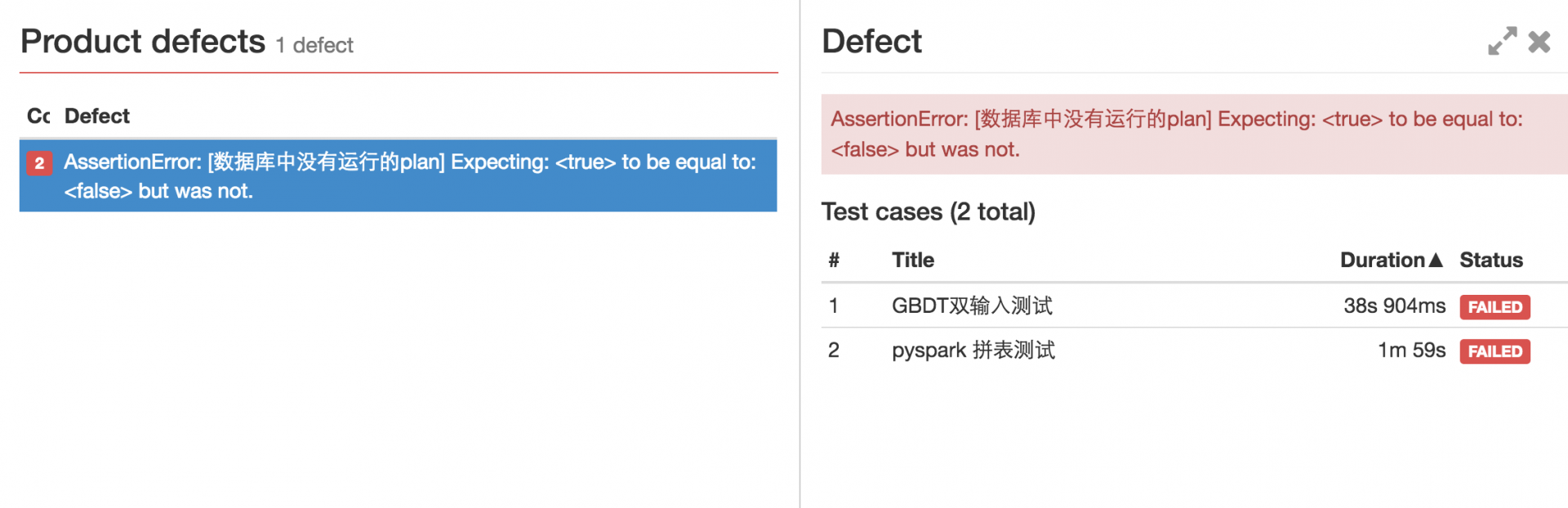
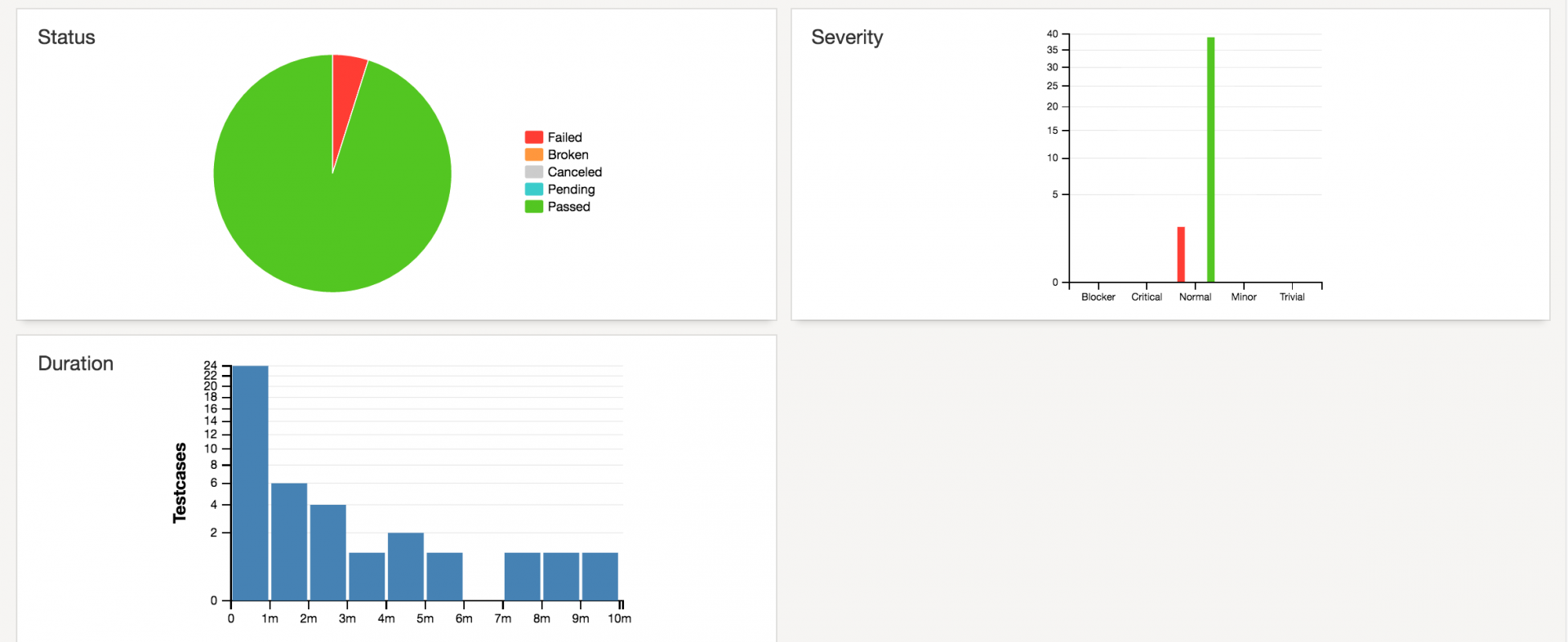
下面是统计仪表盘:
具体的使用攻略大家翻一翻我之前的帖子吧。我有一些详细说明。 也可以到 git hub 上直接看官方的 wiki。
OK 今天爆发了,连写了 3 篇。 之前大概快一个月没写文章了。今天就当补上了吧。其实这个方案是用 jenkins 的机制临时糊出来分布式执行。记得之前有人分享过自己开发的分布式框架。我感觉成本还是太高了,需要开发比较长的一段时间。 虽然用 jenkins 糊出来的这个方案看上去有点不伦不类的,但是够用。搭建起来也快,按着这篇文章搞,估计一两天也就把坑踩完,投入使用了。
