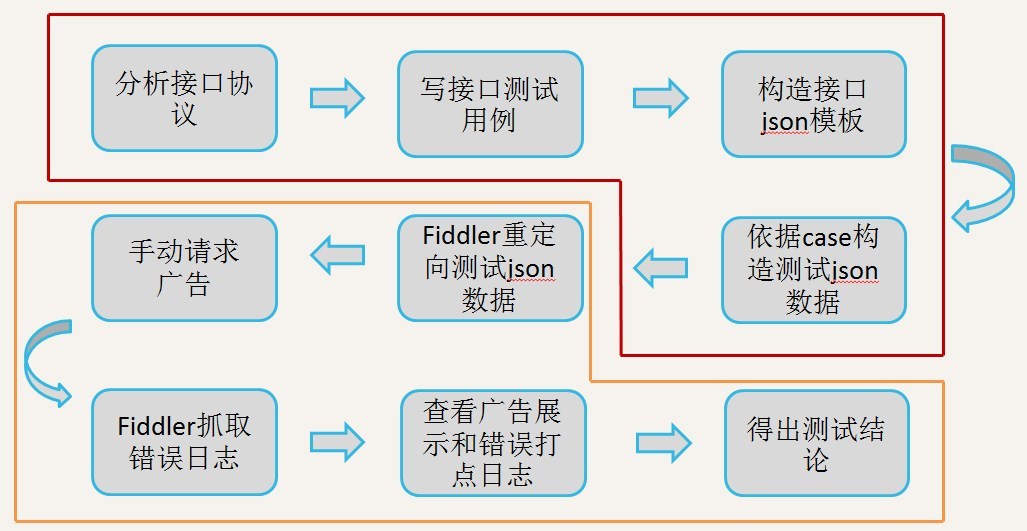
读完整篇文章可能需要 15 分钟,文章太长,分了两部分发
关键字:移动端 SDK 的 mock 测试、自动生成 case、anyproxy、正交表、pairwise、PICT
最近和小伙伴们做了一件事,这件事从我提出这个想法、到执行、到完成的整个过程中,都充满了争议,包括团队内部、团队外部、我的内心,都充斥着各种不同的声音:“这件事价值不大”,“没有给手工测试减少多少工作量”,“弄的东西太虚” 等等。我也一度在怀疑这件事的价值,但是在这种情况下仍然坚持完成了,也取得了一定的收效。做完后,我咨询了一些比较有想法的同行前辈,有认同也有疑问,因此我想放到社区里听听更多更有想法的同行们的声音。如果能给大家带来一些启发,再好不过,如果不能,各位权当一个反面教材。
说在前头:
0.整这个东西是为了显得高大上,显得很牛逼么?
A:自动生成 case 一直是心里潜伏已久的想法,然而肚子里墨水有限,每天都在点点点,觉得不做点什么和咸鱼没区别。发出来不是来吹牛逼的,而是我知道:1)我们落地了想法;2)我们的思维是片面的,期望能抛砖引玉
1.针对的是单接口还是单业务场景?
A:我们 SDK 项目的特点之一:接口单一,没有复杂关联,最多就是某种返回会触发二次回传打点,因此非常适合做试点。而单业务场景可能会涉及很多接口的配合,比如登录场景
2. 接口测试用例的自动化生成?
A:我们没有自动生成 request 的各种请求参数,而是通过一些方法生成了 response 的 json 结果,用来 mock 测试 SDK 中各种异常处理以及打点回传数据,其目的之一是解决服务端开发同步太慢的问题,后面会介绍。
3.通过暴力组合来 fuzz,脱离了业务逻辑考虑,很多 case 是无意义的
A:两个问题:我们的做法不是通过暴力排列组合穷举,比如一个 int 字段,各种数字、特殊符合、空、空格、字母的输入来进行校验?不是的,我们会制定一个模版,模版的内容类似字段 adsType:[0,1,2,3,],~[a,null,空格,@#$%,...],其中前面的部分是正常的业务允许的取值范围,后面的负面测试数据,并非完全毫无目的的自由组合
4.复杂业务场景怎么办、关联接口依赖怎么处理、字段加密、签名校验、token、随机数组装
A:我们的 SDK 业务没有这些复杂关联,而字段加密,签名,随机数都可以在定制模版的时候完成
5.response 返回到客户端后,展示广告怎么测?下载、外开跳转、广告渲染怎么测?
A:我们大部分的设计是为了校验异常测试的,正常的功能测试依然是人工 + 部分自动化来实现
6.自动生成的 case 肯定有遗漏的地方
A:没错,但是比人工设计 case 覆盖要更全面,执行速度更快,更新速度更快,为什么可以,后面给大家介绍。
更多的问题我相信很快就有了,言归正传,开始介绍吧。
广告 SDK 项目是为应用程序 APP 开发人员提供移动广告平台接入的 API 程序集合,其形态就是一个植入宿主 APP 的 jar 包。提供的功能主要有以下几点:
在项目推进的过程中,逐渐暴露了一些问题:
协议字段示例图
{
"ads": [{
"action": { "path": "" },
"adw":920,
"adh":900,
"template": "",
"action_type": 2,
"adid": "123123123",
"adm": "",
"adm_type": 0,
"deep_link": "",
"impid": "*******",
"tk_act": [""],
"tk_imp":[ ""],
"tk_ad_close": [""],
"tk_clk": [""],
"tk_dl_begin": ["" ],
"tk_dl_btn": [ ""],
"tk_dl_done": [""],
"tk_dp_suc": [],
"tk_ins": [ ""],
"tk_open": [""]
}],
"errno": "0"
}
手动测试过程示意图
上述几个问题,其中 1、2、3 都会对我们的测试工作产生影响,但是属于项目管理范畴,不在本文讨论范围内。那么针对 4、5、6、7 几个问题,应该如何解决呢?
首先分析一下问题:
Q: 缺少服务端测试环境,可模拟的真实广告内容太少
A: 由于服务端团队在人力上的不足,无法为我们提供测试环境,通过沟通协商,方法暂定为由服务端同事预先配置好线上广告物料,即固定的线上广告资源,能够覆盖提测的广告类型,在服务端完成功能逻辑之前,先利用 mock 方式测试客户端的功能逻辑以及展示,此时客户端和服务端后台无需交互。
Q: 协议字段太多,传统的测试用例设计方法容易出现遗漏,尤其是异常情况处理
A: 制定一个可靠的测试用例设计策略,以最少的 case 覆盖最多的情况。
Q:测试用例设计极容易受需求影响,变更起来非常麻烦,成本很高
A: 对测试用例进行拆分,分为正常返回情况和异常处理两部分。正常的处理包括系统环境、网络切换、下载、轮播、缓存、正常打点、安装卸载、UI 检查等等需要人工检查的情况,因此这部分我们先梳理 checklist,先组内 review,再约产品和研发一起 review,确保需求的完整性,另外开发过程中的需求变更是不可避免的,对于需求的变化要做到实时更新 case,这部分 case 覆盖的点要足够全,而文字描述要尽量的精简,确保更新起来能快速响应节奏的变化。而异常的部分,我们的做法是批量自动化生成 case,生成策略会在下面详细描述。
Q:手工测试方法效率低,且容易漏测
A: 正常的功能我们通过手工测试的方法覆盖,而对于客户端拿到的异常情况的 error code 要有全量的覆盖,比如我们的错误代码约定了 21 种,那么针对所有可能出现的错误代码都要想办法触发,这一部分工作希望从 case 生成到用例执行能 100% 的自动化实现。
有了解决思路,那么需要想办法把想法落地。我们提炼出几个需要攻克的技术难点:
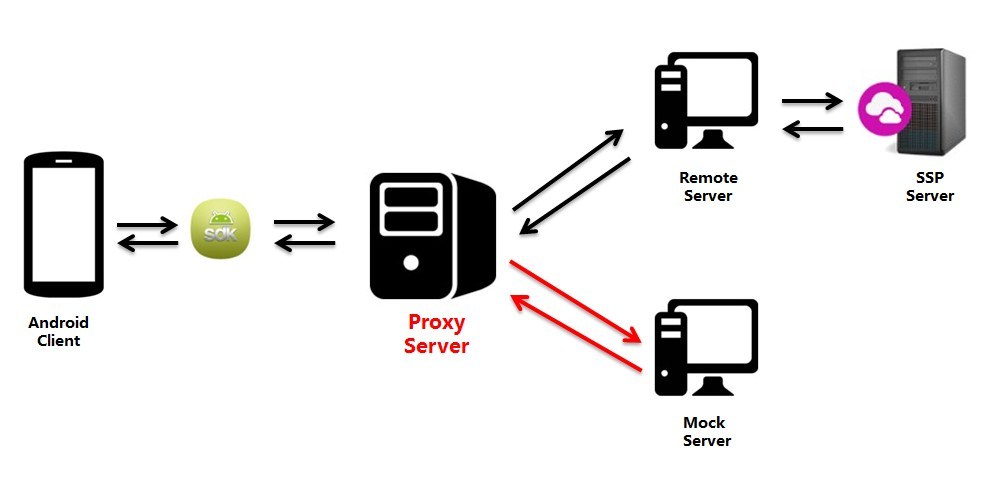
做过单元测试的同学应该了解 “桩(stub)测试”,即通过 hard code 方式验证函数的输入输出是否准确和健壮,而 mock 测试和桩测试类似,功能要更加丰富一些,可以模拟产品交互环节中的部分场景,换句话说,可以让测试工作提前介入研发流程中。多用于需要联调的环节,比如支付场景,购买流程,第三方插件调用等等业务。之前我们采用的 Fiddler 重定向请求结果到本地文件的方式模拟服务端的 response 来欺骗客户端,也可以理解为 mock 测试。
最初我们计划自己写一个 proxy server 监听指定端口,截取所有的 http/https 请求,再替换 response 内容完成 mock 测试,后来一次偶然的机会接触了阿里开源出来的 anyproxy(http://anyproxy.io/cn/),了解了一下该工具,发现这款工具刚好满足了我们的几个需求:
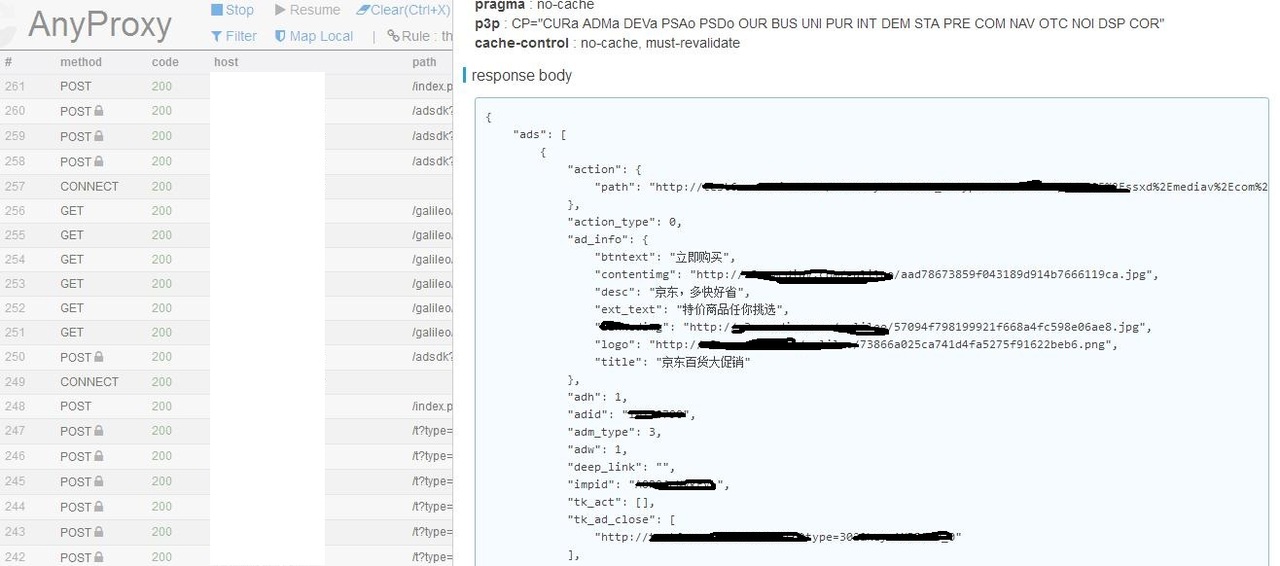
实际使用截图(我们对 response 展示做了点优化):
在讨论接口测试用例设计之前,我们需要预先圈定一个思考范围,以免过度的思维发散。结合我们的业务特征,由于 SDK 的功能大部分是单接口,少部分是关联接口,因此我们的设计基于单接口而非单个业务场景。
接口的测试用例设计有别于其他测试用例,其业务逻辑主要体现在字段的取值上,每个取值体现了一种业务逻辑,我们做了一些调研,学习了其他业务团队的接口测试用例写法,发现测试人员喜欢这样设计 case:
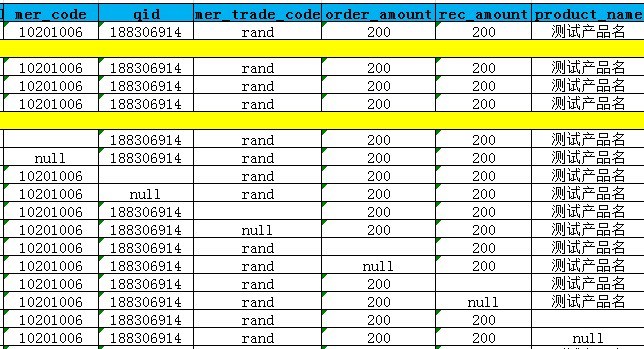
这样的 case 无疑是工整、直观的,可读性比较强,很方便的复制粘贴,再通过修改其中的一个或者几个值,形成一个庞大的二维数组。
看到这个表格,一些熟练的测试工程师会立马联想到边界值、等价类设计、正交试验法等。然而要想保证每一个场景都被完整的覆盖,理论上我们需要测试所有字段的笛卡尔积,这种方式可以保证任何取值都会被覆盖到,但是当字段比较多的时候,测试用例的数量会呈爆炸式的增长,毫无疑问这种方式是不可行的。我们需要一个算法,能做到以下几点:
1、 以最少的组合覆盖尽可能多的场景
2 、覆盖所有字段的所有取值
3 、有统计学支撑,生成的数据有规律可循
有了需求,我们开始进行了可行性方案的研究,秉承不重复造轮子的理念,我们查阅了国内外很多的资料,逐渐的缩小了范围,在说出解决方案之前,先给大家简单介绍两个重要的算法:“ OATS(Orthogonal Array Testing Strategy)” 和 “Pairwise/All-Pairs Testing”,简称 “正交表法” 和 “配对测试法”。
正交表法
正交表法有两个重要的特性,大家尝试着理解一下:
1.每列中不同数字出现的次数相等
备注:这一特点表明每个因素的每个水平与其它因素的每个水平参与试验的几率是完全相同的,从而保证了在各个水平中最大限度地排除了其它因素水平的干扰,能有效地比较试验结果并找出最优的试验条件。
2.在任意两列其横向组成的数字对中,每种数字对出现的次数相等
备注:这个特点保证了试验点均匀地分散在因素与水平的完全组合之中,因此具有很强的代表性。
举个例子:有三个字段,每个字段可以取三个值,设字段表现为 A(A1,A2,A3)、B(B1,B2,B3)、C(C1,C2,C3),可以组成的集合恰好可以表现为一个三维空间图,如下图所示:
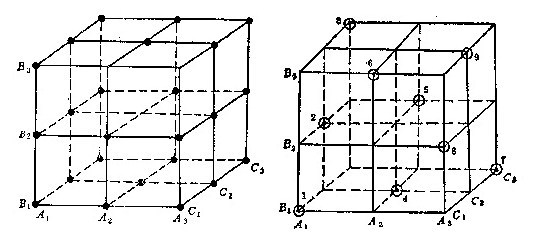
图中的正方体中每个字段的每个水平代表的是一个面,共九个面,任意两个字段的水平之间都存在交点,共 27(3x3x3)个,这就是笛卡尔积。按照两大特性设计出的正交表如右图所示,试验点用⊙表示。我们看到,在 9 个平面中每个平面上都恰好有三个点而每个平面的每行每列都有一个点,而且只有一个点,总共九个点。这样的试验方案,试验点的分布很均匀,试验次数也不多。
国外有一个网站能查询正交表的结果案例:http://www.york.ac.uk/depts/maths/tables/orthogonal.htm
配对测试法
配对测试法(Pairwise)是 L. L. Thurstone( 1887 – 1955) 在 1927 年首先提出来的。他是美国的一位心理统计学家。Pairwise 是基于数学统计和对传统的正交分析法进行优化后得到的产物。
定义:Most field faults were caused by either incorrect single values or by an interaction of pairs of values." If that's generally correct, we ought to focus our testing on the risk of single-mode and double-mode faults. We can get excellent coverage by choosing tests such that 1) each state of each variable is tested, and 2) each variable in each of its states is tested in a pair with every other variable in each of its states. This is called pairwise testing or all-pairs testing.
大概意思是:缺陷往往是由一个参数或两个参数的组合所导致的,那么我们选择比较好的测试组合的原则就是:
1)每个因子的水平值都能被测试到;
2)任意两个因子的各个水平值组合都能被测试到,这就叫配对测试法。
参看:http://www.developsense.com/pairwiseTesting.html
Pairwise 基于如下 2 个假设:
因此,pairwise 基于覆盖所有 2 因子的交互作用产生的用例集合性价比最高而产生的。国外也有一份类似的数学统计:

我们通过一个订飞机票的实际例子来看一下,配对测试法是怎样从笛卡尔积中提炼出局部最优解的。
依然是三个字段的组合,分别是 Destination(Canada, Mexico, USA),Class(Coach, Business Class, First Class), Seat Preference(Aisle, Window),所对应的笛卡尔积共有 3x3x2=18 中测试组合,如下表所示。
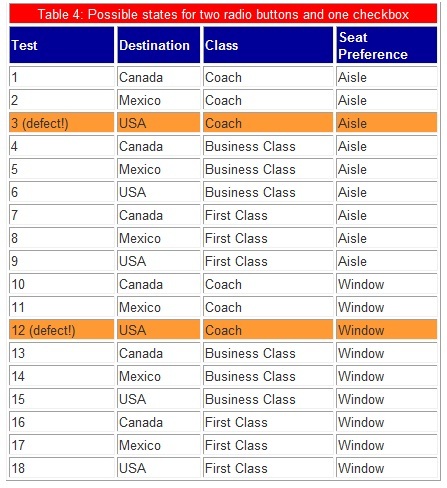
经过配对测试法筛选后,结果如下:

经过筛选以后,我们的测试用例变成了 9 条,case 数量精简了 50%。简单总结 pairwise 的筛选原理就是,发现两两配对在全集中有重复的就去掉其中之一,这样筛选也有副作用,每次筛选完了条数是固定的,但是结果却不尽相同。但是通过上面的介绍我们不难比较出两种算法的差异。
说了那么多,再回到我们之前提到的设计策略几个需求,可以认为 pairwise 算法的特征基本满足了我们的需求。
确定了用例设计的算法策略后,我们信心十足的准备开始设计我们的 response 返回值 case 了,我们套用文献中的排列分布方式应用到实际接口 json 中,悲伤的发现我们要组合的字段不是 3 个,而是 20-35 个左右,如果通过人工的方式来进行 case 设计的话,就算只考虑最多两个字段的值发生变化,数量也是非常惊人的,WWWWWWhat???

本着 “偷懒是人类进步的第一动力” 的想法,我们自然不会前功尽弃,自动化测试是我们的必选之路,接下来要做的就是调研目前已经存在的基于 pairwise 算法的工具有哪些,下面是经过调研后得到的工具列表。
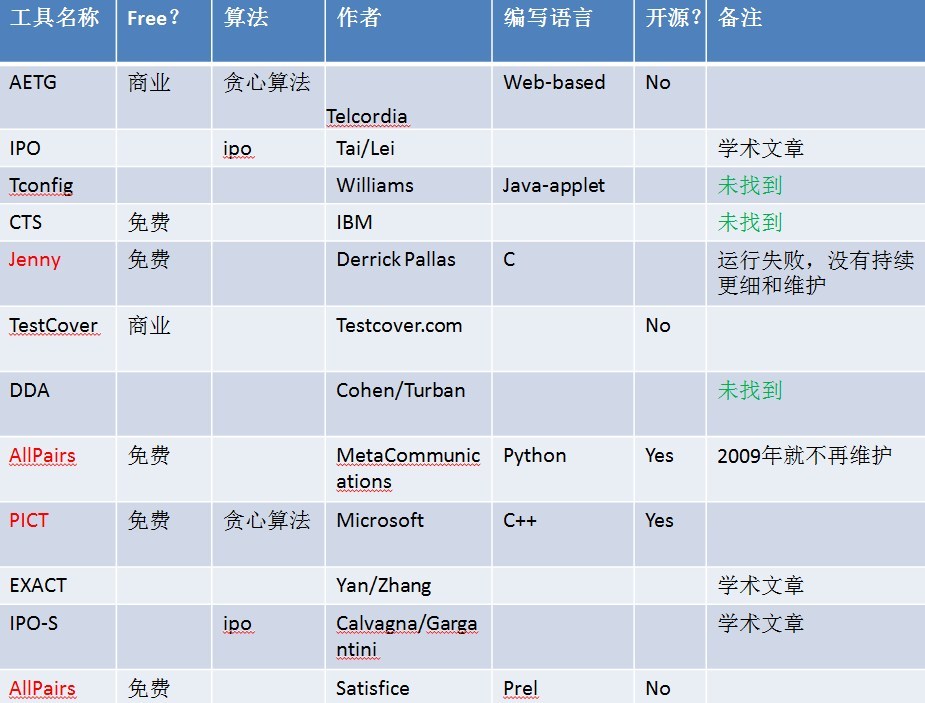
基于 pairwise 算法的工具如此之多,那么相同模型设定下产生的结果是否存在差异呢?我们看一下这张图:
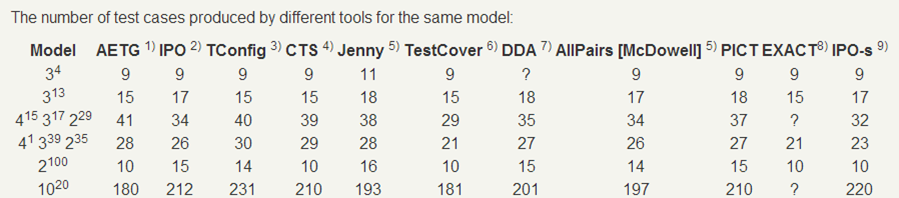
综合比较各工具产生的数据结果后,我们可以发现不同工具之间的结果差异并不大,基本上能够满足我们现有的需求。经过一番讨论后,我们决定采用微软的 PICT(https:\/\/github.com\/Microsoft\/pict)作为 case 生成工具,原因有几点:
1. 代码开源可扩展
2. 源码依然在维护,贡献比较活跃
3. 产品成熟,语法丰富
4. 基于贪心算法,局部最优解
难点四:测试用例生成的设计
用例生成过程分为五个步骤:
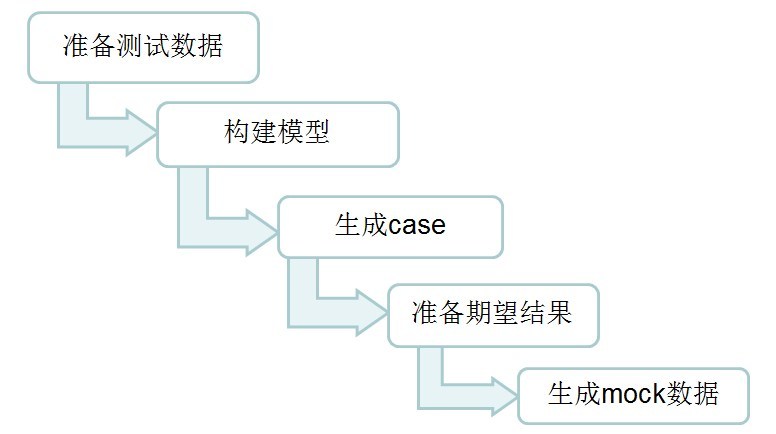
1. 准备字段值
根据 Wiki 的接口文档,测试人员理清字段结构,字段类型,字段取值范围后,结合传统的 case 设计理念,构造出每个字段的赋值,存放到整理好的 excel 中,大概是这样的:

有的同学可能会问:你这样整理也挺麻烦,感觉人工也没省多少事儿。这样设计的好处是,当字段发生变化的时候,只需要从源头修改字段属性、值、层级、甚至删除,后面整个流程中的 case 都会统一生效,字段集中管理,牵一发而动全身。和 UI 自动化用到的 page-object 设计类似。
2. 构建模型
有了面粉了,还需要加工一下才能变成我们想要的面包,我们需要把准备的数据整理成可以批量生成的可识别文件,即模型文件。PICT 的模型文件有自己的格式,类似这样:
参数定义
[子模型定义]
[约束定义]
举个例子,前面提到的订票系统的例子加工成模型文件是这样的,后面会给大家介绍语法含义:
Destination: Canada, Mexico, USA
Class: Coach, Business Class, First Class
Seat Preference: Aisle, Window
{Destination, Class} @ 2
3. 生成 Case
通过 pairwise 工具将模型文件组装成我们想要的 case,那么上面的模型生成的 case 会是这样:
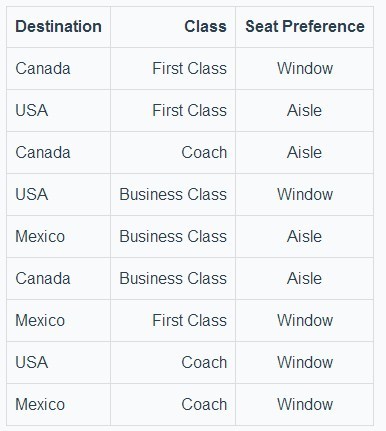
注:选择强度为 2,因此上面的矩阵是两两变化的。如前面所说,这里生成的矩阵内容不是固定的!
4. 准备期望结果
输入数据已经准备好了,那么相对于 case 而言,是不是还缺一个期望结果呢?在这里我们碰到了一个难题,可能做过 case 自动生成的同学都会遇到的,就是生成排列组合是非常简单的,如何让这些组合变得有意义,体现在我们的期望结果上,那么一次性生成如此多的 case,如何让输入值和期望结果对号入座呢?
我们的做法是:拆分了 postive testing 和 negative testing(合法输入测试和非法输入测试或负面测试),通过整理接口 case 我们不难发现,合法输入的 case 其实占整个 case 的比重并不大,工作量比较大的是各种参数的异常数据输入,相应的会产生 error code 或二次请求。只需要我们在整理数据的时候给出对应的 error code 即可,如图所示:

有的同学会问:我们协议还不稳定,error code 也不明确,有些输入也不知道对应什么 error code,怎么破?别急,后面告诉大家。
5. 生成 mock 数据
完成了以上准备工作以后,剩下的就是生成我们 mock 需要的 response json 数据了。解析 Wiki 协议中的 json 模版,给对应的 json 字段赋上生成的值,这里需要写一段代码来完成,在此不做赘述。
在使用过程中,我们发现工具 PICT 不能满足业务场景的复杂度要求,主要有两点:
在 case 设计中多个异常值输入是很常见的测试场景,虽然 pict 提供负面测试(negative testing)功能,即如果模型文件中,有值被标记为异常值(默认的异常值标识符为 “~”),则 case 中会随机出现一个异常输入的值,但是 PICT 限制每个 case 只能有一个异常值存在,原因是多数异常值的组合虽然可能会引发问题,但是代码在 catch 了一个异常值造成的异常后,不会再去处理另一个异常值。
先通过一个示例来感受一下 pict 的负面测试。示例模型文件如下:
Destination: Canada, Mexico, USA, ~Japan
Class: Coach, Business Class, First Class
Seat Preference: Aisle, Window, ~Door
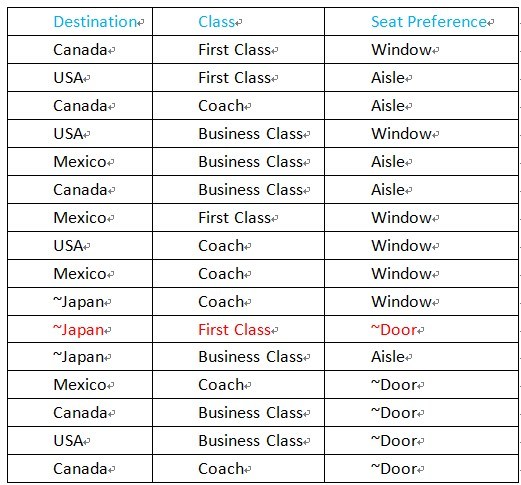
产生的 case 如下:
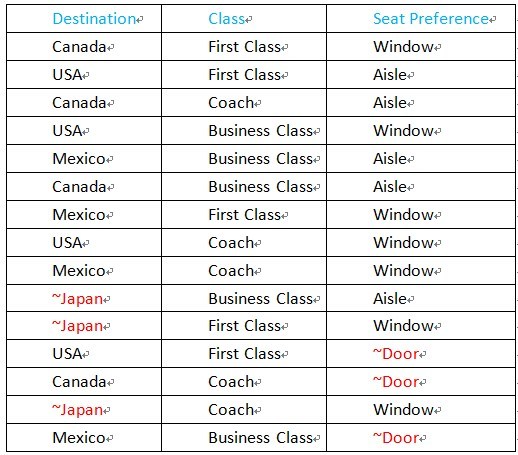
通过上图可以看出,PICT 同时保证了正常值的组合,也保证了异常值的组合,但是我们不难发现,每个 case 只会出现一个异常值,那么 ~Japan,First Class, ~Door的 case 就会遗漏,显然 case 覆盖率不够,不能满足我们的需求。
针对这个问题,在对 PICT 的源代码进行了详细的解读后,我们对代码进行了二次开发,扩展了负面测试的覆盖范围,彻底解决了这个问题,修改后的模型文件如下:
Destination: Canada, Mexico, USA, ~Japan
Class: Coach, Business Class, First Class
Seat Preference: Aisle, Window, ~Door
~{Destination, Seat Preference}
增加一行公式,在模型文件中指定了 Destination 和 Seat Preference两个字段可以进行异常值组合,数量不限。
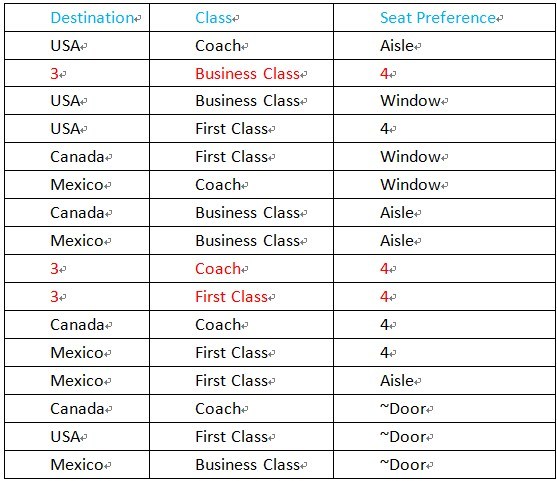
扩展后的 case 生成是这样的:
PICT 支持 IF[ ] THEN[ ] 格式的约束规则。但是约束规则中 LIKE 关键字的通配符操作只支持 * 和?(分别表示任意多个字符和任意一个字符)。显然简单的通配符操作限制了约束规则的表达能力。因此,我们在原有的基础上,引入 C++ 的 regex 库支持正则表达式,修改后支持了更丰富的正则表达式。
如下示例中,增加一条规则,如果 Destination 字段为数字类型(”\d”),那么 Seat Preference 字段也为数字类型。
Destination: Canada, Mexico, USA, 3
Class: Coach, Business Class, First Class
Seat Preference: Aisle, Window, 4
If [Destination] like "\d" then [Seat Preference] like "\d";
生成的 case 如下图:
有了强大的正则表达式,再加上多异常组合输入的支持,目前已经完全能覆盖我们需要的任何场景,向开源致敬!
