利用 ELK 技术栈来监控内测和线上的质量已经是很成熟的实践了
已经有越来越多的公司使用上了这一个强大的武器. 质量监控是个很大的话题, 我先做个简单的铺垫.
从狭义上讲. 他可以做到如下的目标
能做到这一切, 得益于数据分析相关技术的发展.
之所以决定现在发这个文章, 是看到之前有同学已经陆续分享了 ELK 的构建.
比如 @neven7 发布的 https://testerhome.com/topics/4280
当时很多人并没有明白这个技术栈给测试和业务带来的价值.
所以我今天就简单介绍下我的经验, 给这个优秀的技术栈加加热度. 也当是自己的日志记录.
技术架构为:
埋点数据 + 接口数据 -> Kafka -> LogStash -> ElasticSearch -> Kibana -> 监控
核心数据:
用户 id + 业务埋点 + 接口 + 版本号标记 + 时间戳
logstash 的配置示例, 从 Kafka 读取数据
input {
kafka {
topic_id => 'topic_name'
zk_connect => '${zookeeper的地址}:2181/kafka'
}
}
filter {
csv{
separator => "|"
columns => [ "host", "request", "http_user_agent"]
}
date {
match => ["log_time", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
elasticsearch {
index => "logstash-topic-%{+YYYY.MM.dd}"
}
}
从 csv 中读取配置示例
input {
file {
path => "/data/ELK/data/*.csv"
start_position => beginning
}
}
filter {
csv{
columns =>[ "log_time", "real_ip", "status", "http_user_agent"]
}
date {
match => ["log_time", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
elasticsearch {}
}
docker run -d —name logstash \
-v "$PWD":/config-dir \
logstash logstash -f /config-dir/logstash.conf
docker run -d --name elasticsearch \
-v "$PWD/data":/usr/share/elasticsearch/data \
-e ES_MAX_MEM=8g \
-p 9200:9200 -p 9300:9300 elasticsearch
docker run -d --name kibana \
-e ELASTICSEARCH_URL=http://x.x.x.x:9200 \
-p 5601:5601 kibana
访问当前机器的http://x.x.x.x:5601/ 即可访问 kibana 来制作各种报表了
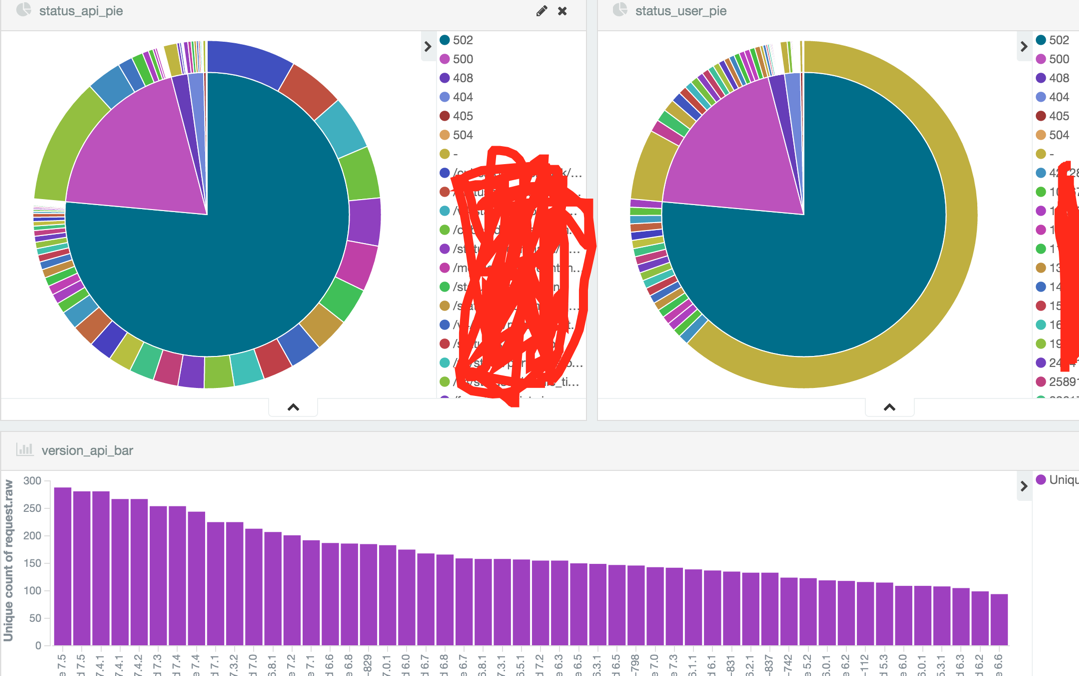
通过小版本号可以识别是那个测试阶段.
通过 uid 可以识别是哪些测试人员在测试
通过使用到的 api 和总的 api 数量来评估测试充分度
比如
这个技术栈对技术的要求比较高. 大家可以先逐渐熟悉并接触这套技术栈. 也许你不一定能在半年内用上它, 但是知道他的用途会为你理解测试提供一个新的视野.
