系列:《让 AI Agent 真正交付测试结果》· 连载第 1 篇
你让 AI 写了 20 条测试用例,它 3 分钟就给你了。格式工整,覆盖点看起来也不错。
然后呢?
你拿着这 20 条 case 去执行,发现:环境没确认、工具没选对、证据没留下、结论是猜的。最后,团队花在补救和返工上的时间,反而超过了手写用例本身。
这不是 AI 不行,是我们对 AI 测试的期待放错了位置。
一个公式
会写测试用例 ≠ 能交付测试结果
测试用例只回答 “应该验证什么”。但真实测试交付还要回答:
当前应该走哪条流程?
环境前提满足了吗?
用什么工具执行?
证据能归因到具体 case 吗?
异常怎么解释?
报告口径是什么?
这些问题,Agent 不会自动帮你想清楚。
测试交付的完整链路:
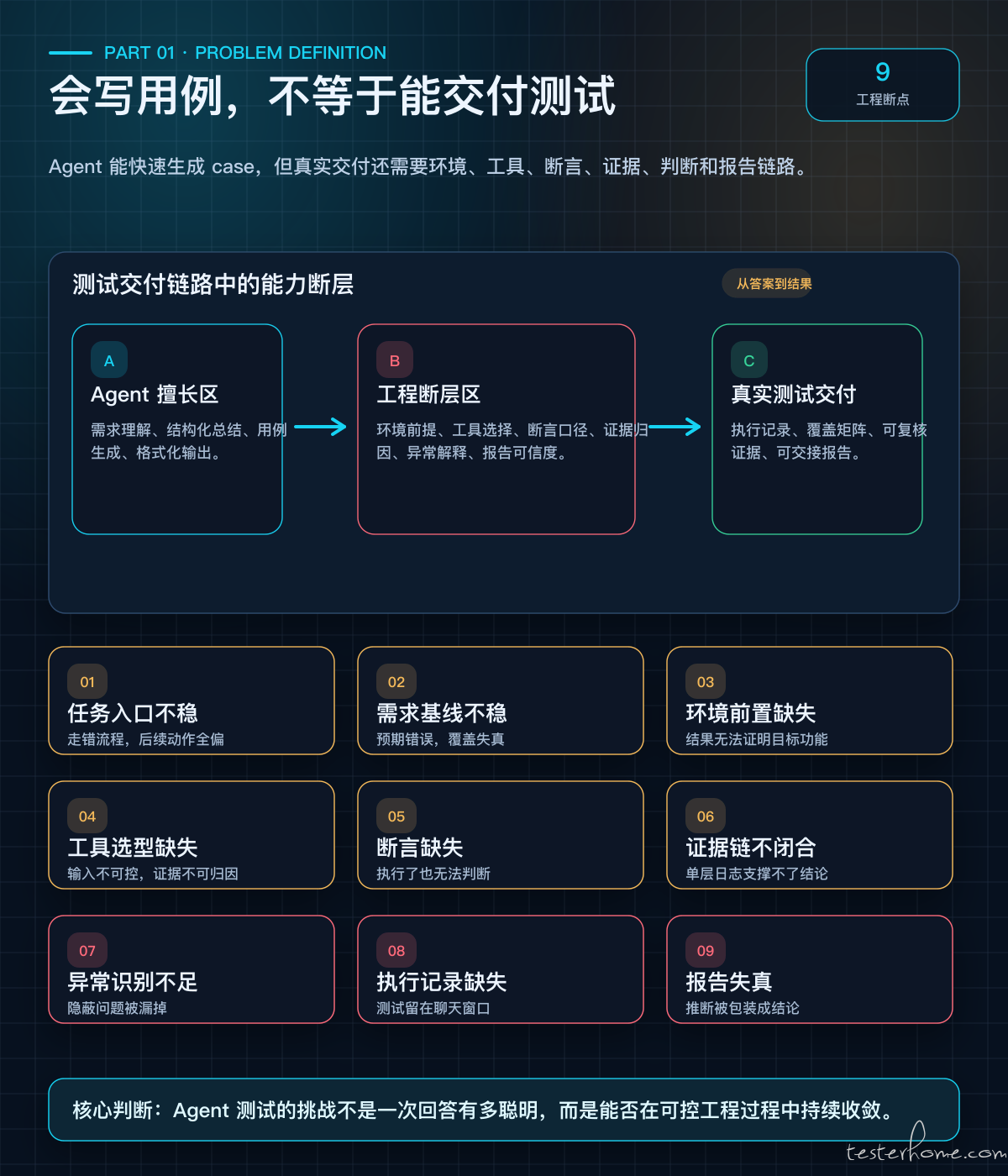
Agent 在真实测试中的九大断点
我们在实际项目中观察到,Agent 在功能测试中有九个容易断裂的地方。
用户说 “测试一下”,Agent 直接开始下单或查日志,后续动作服务于错误目标。
没有对齐通知、代码、分支之间的差异,用例预期会从一开始就偏掉。
没有确认包、二进制、配置、env、启动参数,case 结果无法证明目标功能。
用背景流量观察替代定向验证,输入不可控,证据也无法归因。
只执行动作,不定义通过标准,最后无法判断通过还是失败。
只看单层日志或单个报告,结论缺少复核基础。
只核对预期断言,不检查额外异常,隐蔽问题很容易被漏掉。
测试结果停留在聊天窗口,后续无法交接和复查。
把推断写成结论,隐藏阻塞项,团队同步会被误导。
为什么 “加提示词” 解决不了
你可能想:那我把规则写详细点,提示词加长点,是不是就行了?
不行。原因有四个。
第一,上下文压缩。
长对话中,早期规则会被模型压缩或遗忘。你在第 1 条消息里写的 “必须先确认环境”,到第 20 条消息时,Agent 可能已经忘了。
第二,任务切换。
从一个任务切到另一个任务时,前置约束容易被忽略。Agent 不会自动把上一个任务的教训带到下一个任务。
第三,临场判断。
Agent 可能认为某个步骤 “不需要” 而自行跳过。它觉得 “环境应该没问题”,就直接开始执行了。
第四,会话中断。
跨会话时无法恢复到中断前的执行进度。你昨天做到第 3 步,今天重新开聊天,Agent 不知道你做到哪了。
核心洞察
Agent 测试的关键,不在于某一次回答是否漂亮,而在于它能否沿着可控的工程过程持续收敛。
换句话说,真正需要建设的不是更长的提示词,而是一套能稳定约束 Agent 行为的工程系统。
要点总结
用例生成只是测试交付链路中的一环,离 “可交付结果” 还有很长一段工程距离。
Agent 的不确定性主要来自缺少工程约束,而不是单纯的模型能力不足。
提示词和规则文档是必要条件,但无法独立承担流程控制、证据闭环和结论约束。
真正可落地的 Agent 测试体系,需要一套能持续收敛行为的分层机制。
下篇预告
第 2 篇:六层约束——把 Agent 从 “随机应答” 拉回工程轨道。
我们将展开一个完整的分层约束模型:任务路由、需求与用例、测试实施设计、执行证据、判断基线、交付与沉淀。每一层解决一类不确定性,六层叠加形成闭环。
本文基于真实期货交易系统测试项目实践总结。
