精准测试与 AI 结合的技术探索
摘要
本文围绕一套精准测试平台,系统介绍精准测试与 AI 结合的设计思路、平台能力与工程实现路径。文章首先讨论传统黑盒测试与白盒覆盖率分析在可追溯性、可解释性和回归决策上的局限,再说明精准测试如何通过运行时探针采集、调用链追踪、静态结构分析与版本比对,建立测试场景与代码逻辑之间的双向追溯关系。在此基础上,进一步分析 AI 如何参与缺陷诊断、性能分析、测试推荐和代码关系融合,从而让平台从 “可观测” 演进到 “可理解、可建议、可协同”。文章还结合系统快照、增量覆盖率、变更影响分析等真实平台能力,给出典型应用场景,并讨论当前方案的边界、挑战与后续演进方向。
关键词
精准测试、运行时探针、调用链追踪、覆盖率分析、版本比对、影响范围分析、测试推荐、缺陷诊断、AI 智能体、LangChain4j
前言:为什么是 “精准测试 + AI”
在软件研发过程中,测试团队经常面临几个长期存在的问题:
- 测试执行了很多轮,但很难准确回答 “这次到底覆盖到了哪些关键代码逻辑”;
- 代码改动之后,只能依赖经验判断需要回归哪些场景,容易出现 “全量回归成本高、选择性回归又怕漏测” 的矛盾;
- 覆盖率工具给出了一串数字,但无法解释 “哪些业务场景覆盖了这些代码”“为什么某些代码一直没有覆盖”;
- 出现线上缺陷或性能退化时,调用链、日志、源码、版本变化之间缺少统一视角,定位高度依赖专家经验;
- 平台沉淀了大量测试与运行数据,但没有真正转化为智能建议和决策支持。
精准测试解决的是 “测试与代码之间看不见的关系” 问题,AI 解决的是 “数据有了之后如何理解、分析和建议” 的问题。
因此,本文讨论的重点,不只是把测试数据采集出来,更是希望构建一套从运行时采集、调用链追踪、覆盖率计算、版本变更分析,到 AI 智能诊断、测试推荐与多轮交互的完整闭环,让平台从 “能看见” 升级到 “能理解、能分析、能建议”。
一句话概括:
精准测试与 AI 的结合,核心是把精准测试的数据能力与 AI 的推理能力结合起来,形成面向研发测试协同的智能测试分析平台。
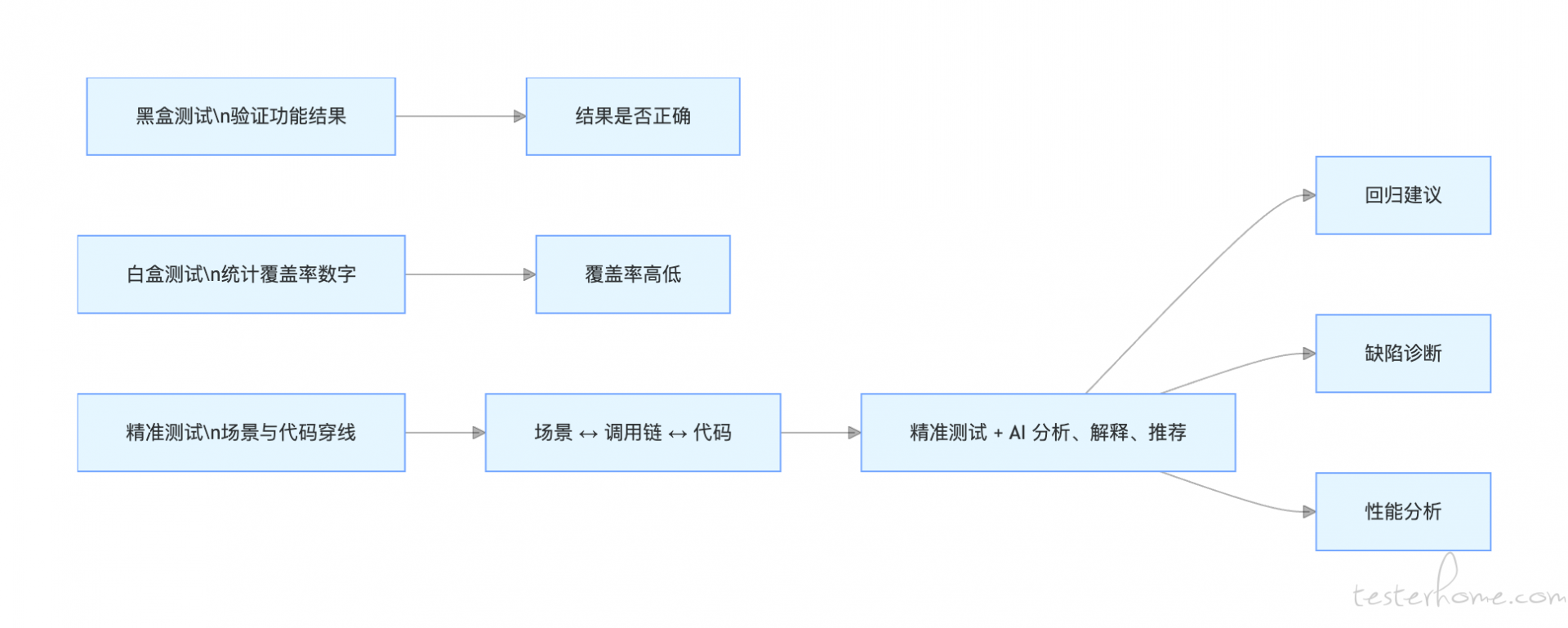
一、什么是精准测试
精准测试是一套计算机测试辅助分析系统,其核心在于建立测试用例与代码逻辑的双向追溯关系,是一种灰盒测试模式。
传统测试中:
-
黑盒测试关注功能是否正确,但无法感知代码内部到底执行了哪些逻辑;
-
白盒测试可以统计覆盖率,但通常只停留在数字层面,无法回答 “这段代码是由哪个业务场景跑到的”;
-
精准测试则是在两者之间 “穿线”,把测试场景、调用链、代码行、分支路径串起来,让测试执行结果具备可追溯性、可解释性和可分析性。
从理念上看,精准测试要解决的不是 “有没有覆盖率”,而是:
- 哪个测试场景覆盖了哪个类、哪个方法、哪一行、哪个分支;
- 哪些改动代码已经被历史测试覆盖过;
- 哪些变更没有被任何已有测试触达;
- 哪些代码虽然覆盖率高,但实际关键路径仍存在风险;
- 哪些场景应当优先回归,哪些可以复用已有测试结果。
它通过运行时探针以无侵入方式采集运行态数据,结合静态结构分析与版本差异比对,并在此基础上叠加 AI 分析能力,实现从:
-
测试场景 → 调用链 → 代码行 / 分支 的正向追踪;
-
代码变更 → 影响范围 → 关联测试场景 的反向追踪。
二、为什么精准测试还要加 AI
如果说精准测试解决的是 “数据从哪里来、关系如何建立”,那么 AI 解决的就是 “这些数据如何被理解和使用”。
在没有 AI 的情况下,平台可以告诉用户:
- 覆盖率是多少;
- 哪些方法被执行过;
- 哪些调用链存在差异;
- 哪些类被变更了。
但在真实工作中,测试人员和研发人员真正关心的是:
- 这次改动最值得优先回归哪些场景?
- 为什么这个接口新版本变慢了?
- 正常请求和异常请求的根因差异在哪里?
- 哪些低覆盖代码风险最高?
- 哪些测试场景应该新增、补测、删减或合并?
这些问题都不是简单检索能回答的,而是需要在多维数据基础上做理解、推理和归纳。AI 恰好适合承担这一层任务。
因此,引入 AI,不是为了 “做一个聊天窗口”,而是为了把平台中原本分散的测试、代码、链路、覆盖率、版本、性能等数据连接起来,形成智能分析和建议能力。
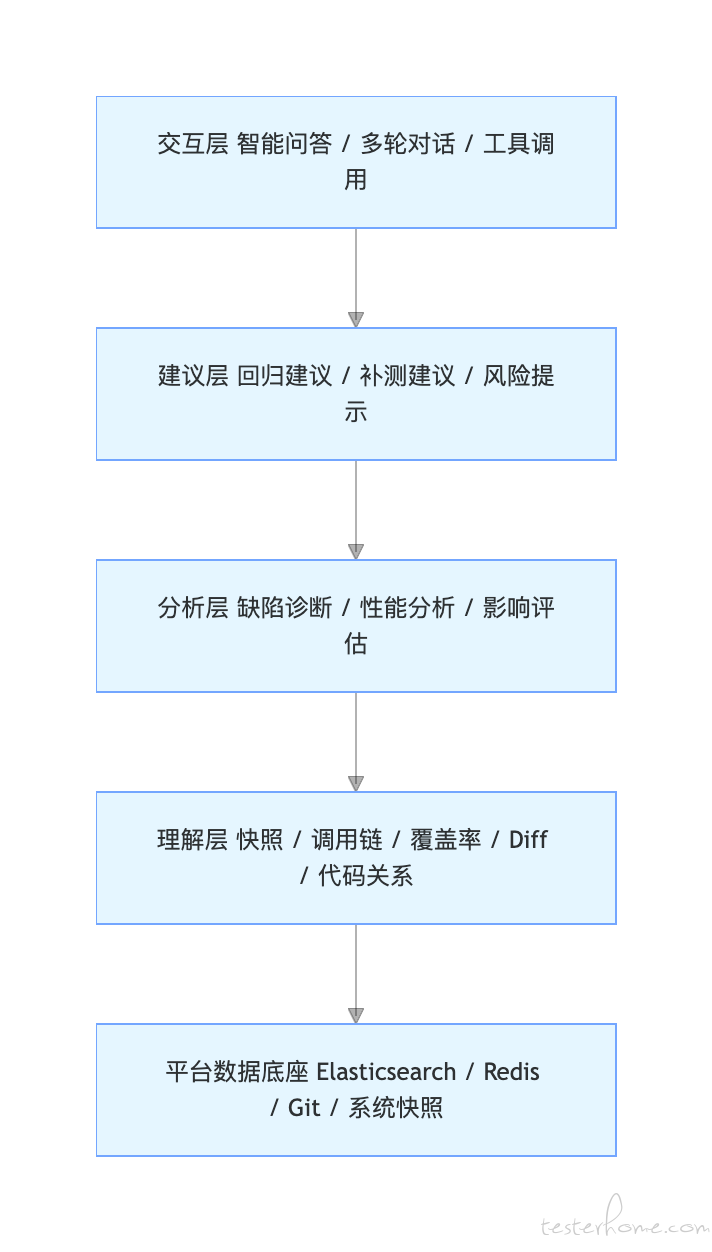
AI 在平台中的四层角色
1)理解层
AI 从平台中读取和理解结构化数据:
- 系统快照
- 调用链节点
- 类 / 方法 / 行 / 分支覆盖率
- 版本 Diff
- 静态代码关系
- 用例、场景、缺陷反馈
2)分析层
AI 基于这些数据做归纳和推理:
- 正常 / 异常链路差异分析
- 覆盖率盲区识别
- 性能回归判断
- 缺陷根因推断
- 变更影响评估
3)建议层
AI 把分析结果转换成可执行建议:
- 补测哪些场景
- 优先回归哪些接口
- 哪些类风险高
- 哪些节点最可疑
- 哪些代码需要重点关注
4)交互层
AI 通过智能问答、多轮对话、工具调用,把复杂的平台能力转成自然语言交互入口,让测试和研发人员以更低门槛使用平台。
三、技术发展与平台定位
历史演进
精准测试在中国的发展经历了几个阶段:
-
2014 年:在国际软件测试大会上首次发布,当时叫 “穿线测试”(Threading Test),建立了用例与代码的追溯关系;
-
2017-2019 年:精准测试白皮书逐渐形成完整体系,覆盖示波器、双向追溯、智能回归、覆盖率分析、缺陷定位等能力;
-
2020 年后:互联网公司开始自研精准测试平台,覆盖范围从单元测试扩展到接口级、链路级和系统级;
-
当前阶段:随着 AI 技术成熟,精准测试进入智能化阶段,从 “可观测、可追溯” 升级为 “可分析、可推荐、可解释”。
平台定位
这类平台在精准测试领域的定位,不只是搭建一套链路和覆盖率平台,而是围绕 “精准测试 + AI” 做纵深增强:
-
请求级覆盖率:精确到 “哪个测试场景覆盖了哪个方法的哪一行、哪一条分支路径”;
-
分支路径级覆盖:不仅有简单的 true / false 分支统计,还支持对分支实际走向的不同路径进行更细粒度的追踪;
-
双向追溯:既能从测试场景追到代码,也能从代码变更反查影响的测试场景;
-
AI 智能分析:从被动展示数据,升级为主动分析问题、推荐测试、解释变化;
-
测试智能闭环:形成 “采集—沉淀—分析—推荐—验证—再沉淀” 的持续优化循环。
四、平台总体介绍
这是一类围绕 Java 应用运行态观测、调用链追踪、覆盖率分析、版本差异比对与 AI 辅助诊断构建的测试与分析平台。
项目通常主要由两部分组成:
- 采集端:通过 JavaAgent 注入目标应用,采集运行时链路、代码栈以及各类中间件交互数据;
- 服务端:负责接收采集数据、生成系统快照、展示覆盖率报告、进行版本比对,并提供 AI 能力扩展。
典型平台结构
精准测试平台
├── 采集端 # 目标系统探针/采集端
├── 服务端 # 平台服务端聚合工程
│ ├── 智能分析模块 # 大模型集成 / 智能工具 / 分析编排
│ └── Web 模块 # 快照、覆盖率、版本、资源、搜索等核心业务
└── README.md
平台总体架构
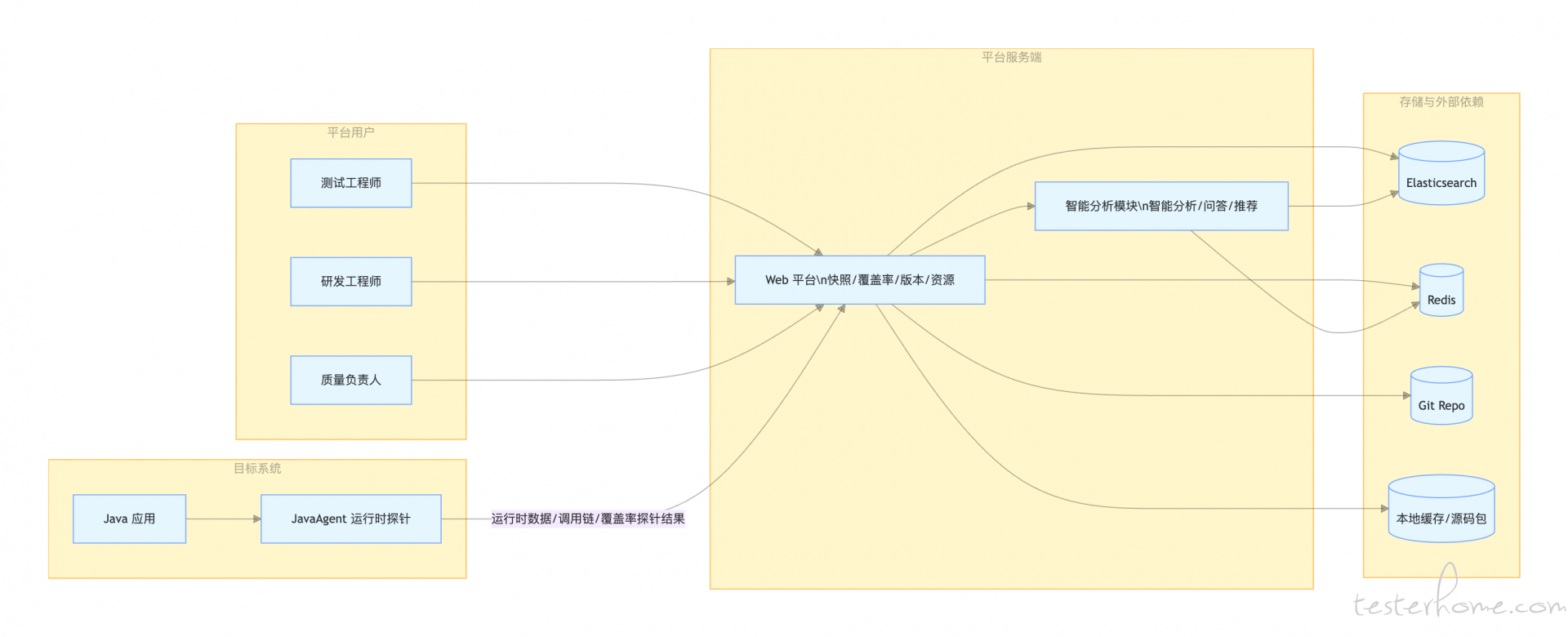
平台核心目标
- 对目标 Java 系统进行无侵入运行态采集;
- 沉淀系统快照、调用链路与源码结构信息;
- 生成全量 / 增量覆盖率报告,支持趋势、对比、树形分析、源码着色;
- 支持版本比对、资源缓存、报告导出;
- 在服务端叠加 AI 能力,辅助代码理解、缺陷排查、性能分析和测试推荐。
五、平台核心能力地图
为了更清楚地理解平台能力,可以将其分为两大能力域:精准测试能力 与 AI 智能能力。
传统测试、精准测试与智能化增强对比
平台能力地图
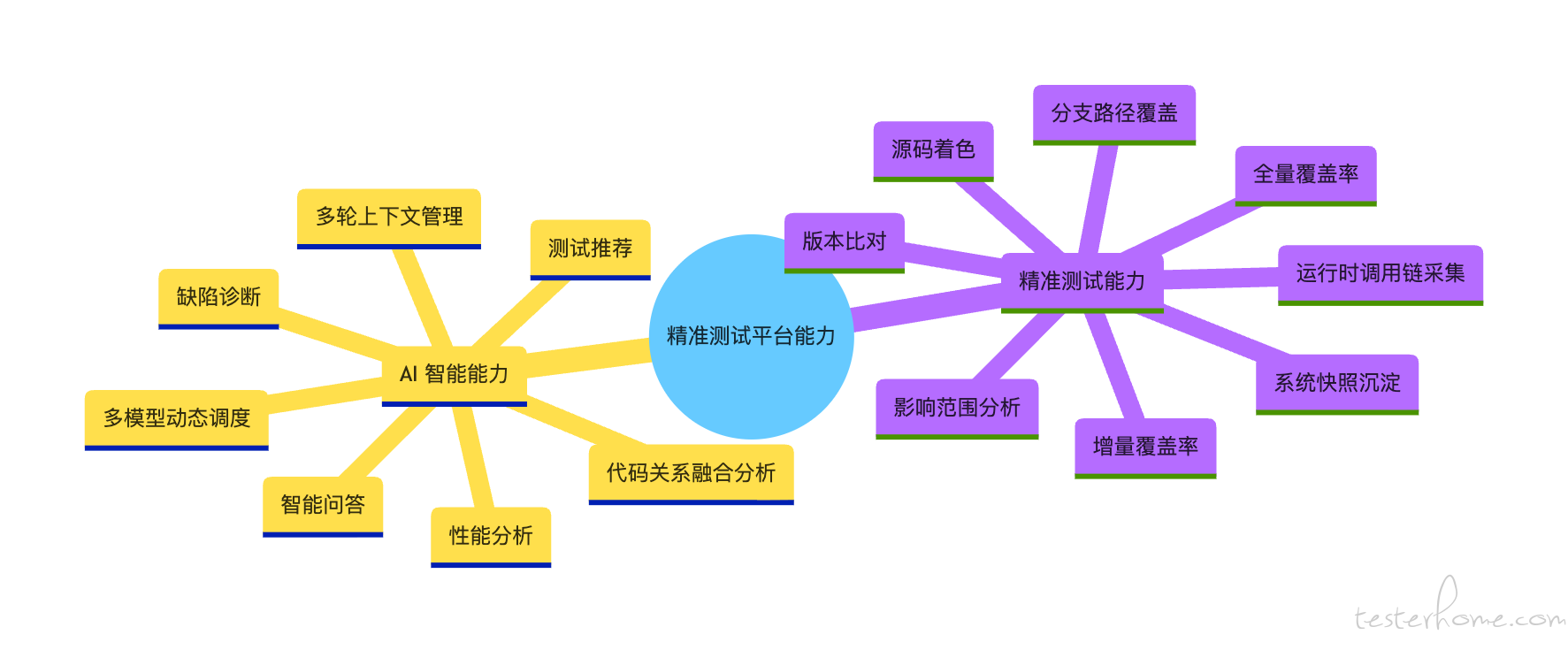
5.1 精准测试能力
1)运行时调用链采集
通过运行时探针以无侵入方式接入目标应用,采集:
- Web 请求入口
- 数据库调用
- 缓存访问
- 服务间远程调用
- 消息队列链路
- 服务内部方法调用及其代码执行关系
2)代码覆盖率分析
支持:
- 类级覆盖率
- 方法级覆盖率
- 行级覆盖率
- 分支路径级覆盖率
- 圈复杂度统计
- 源码着色
3)系统快照与测试场景沉淀
每次真实请求、接口调试或测试执行之后,可沉淀为系统快照,保存:
- 系统标识信息
- 版本信息
- 调用链拓扑
- 代码覆盖信息
- SQL / 中间件调用细节
4)版本比对与变更影响分析
支持:
- 基于 Jar / War 的字节码比对
- 基于 Git Commit 的源码 Diff
- 识别变更类、变更方法、变更行
- 追溯受影响的测试场景与接口
5)全量 / 增量覆盖率报告
支持:
- 全量覆盖率生成
- 增量覆盖率生成
- 覆盖率趋势分析
- 版本间对比
- Excel 导出
5.2 AI 智能能力
1)缺陷诊断
对正常与异常调用链进行智能比对,分析差异节点、传播路径与可能根因。
2)性能分析
从接口、链路、节点多个维度分析耗时变化和性能瓶颈。
3)测试推荐
根据覆盖率盲区、代码变更和调用关系,推荐补测场景。
4)代码关系融合分析
将静态代码关系与动态调用链融合,帮助理解 “定义关系” 和 “实际运行关系” 的差异。
5)AI 智能问答
面向测试和研发场景,支持围绕快照、覆盖率、代码关系、缺陷和性能问题的智能问答。
6)多模型动态调度与记忆管理
根据任务复杂度和上下文长度动态选择模型,并支持渐进式摘要压缩与多轮对话记忆。
六、平台工作原理
6.1 数据采集:Agent 无侵入接入目标系统
这一部分解决的是 “目标系统运行了什么、测试到底触达了什么” 难以被统一采集的问题。
平台使用 JavaAgent 方式接入目标应用,通过类加载期插桩实现对运行时行为的采集。
平台涉及两类字节码处理技术:
-
Javassist:用于协议层和入口层增强,适合快速织入基于 Java 语义的代理逻辑;
-
ASM:用于行级与分支路径级探针注入,便于对覆盖率采集做到更细粒度控制。
6.2 为什么同时使用 Javassist 和 ASM
二者各有分工:
-
Javassist 更适合做方法入口 / 出口增强,例如记录 HTTP 请求参数、SQL 语句和服务调用信息;
-
ASM 更适合做底层、细粒度的覆盖率探针注入,例如为每一行代码、每一个条件跳转点插入探针。
通过两者协同,平台既能看见 “调用了什么”,又能精确记录 “执行到了哪里”。
6.3 精准覆盖率的关键改进
这一部分解决的是 “传统覆盖率工具能统计数字,但难以支撑复杂业务系统的精准评估” 问题。
相比传统覆盖率工具,平台针对复杂业务系统中常见误差问题做了改进:
-
分母完整:在类加载阶段和系统启动阶段扫描 classpath,确保所有类、方法、代码行和分支结构都被纳入统计口径;
-
请求级隔离:将每次请求的覆盖率与唯一调用标识一一绑定,避免不同请求之间的数据混杂;
-
分支路径级追踪:通过区分分支最终进入的不同目标路径,避免覆盖率分析只停留在粗粒度的 true / false 统计层面;
-
MC/DC 条件级分析基础:对每个条件跳转分别记录命中与未命中情况,为更高阶的条件覆盖分析打基础;
-
异步线程上下文透传:在异步线程池场景下保持链路与覆盖率采集的连续性。
6.4 从采集到分析的闭环
平台形成如下闭环:
- 运行时采集目标系统请求和调用链;
- 结合静态结构信息生成覆盖率数据;
- 将链路、快照、报告、源码结构沉淀到平台;
- 结合 Git 版本比对识别变更与影响;
- 通过 AI 对快照、链路、覆盖率和 Diff 数据进行智能分析;
- 输出测试建议、缺陷诊断和性能结论;
- 测试再次执行,形成新的系统快照和报告,完成数据闭环。
测试场景、调用链与代码覆盖的双向追溯
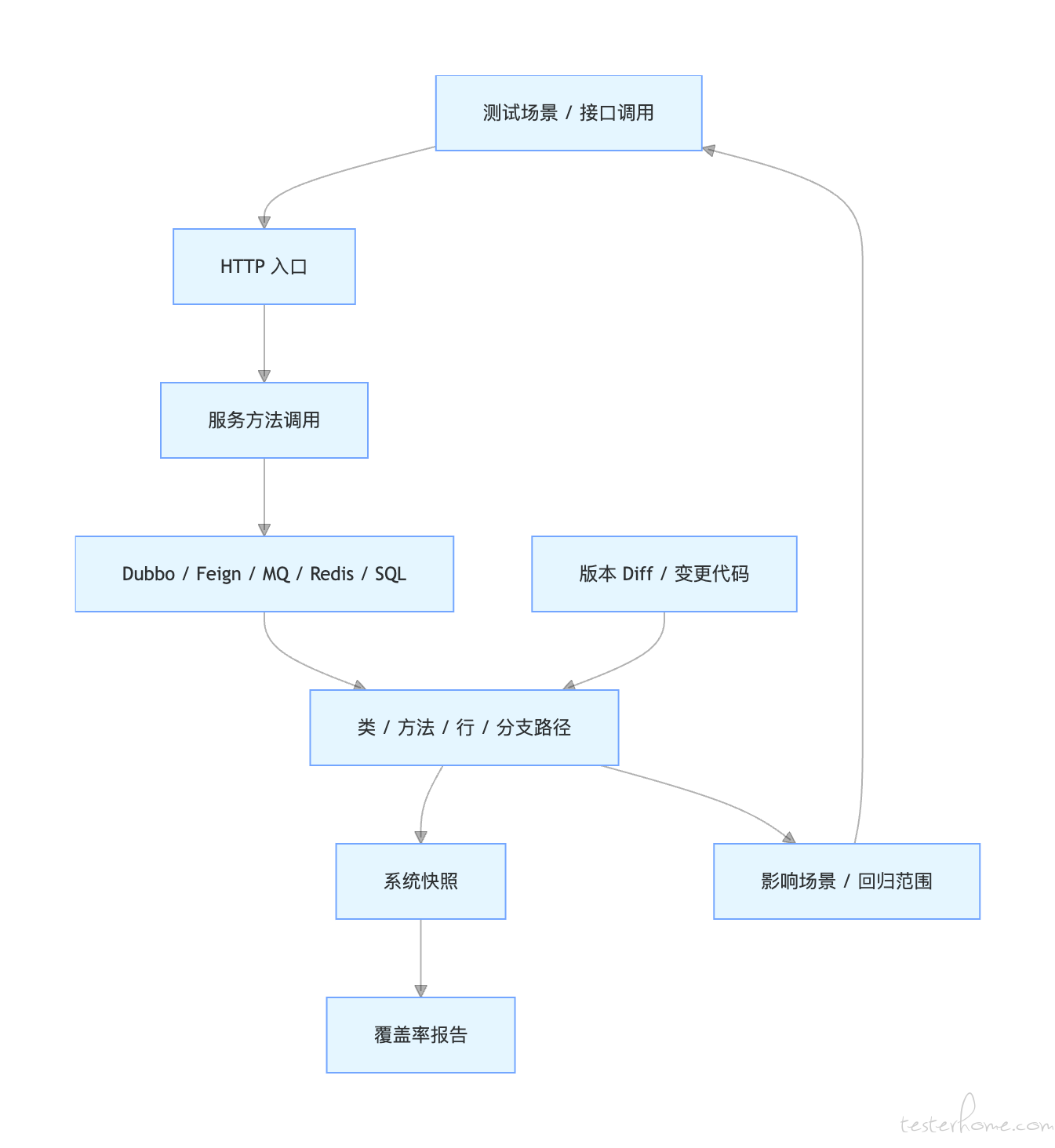
七、平台重点功能介绍
7.1 监控台
监控台是平台采集与观察的实时入口,主要解决 “运行时行为不可见、测试执行过程难复盘” 的问题。
1)实时监控
通过 HTTP 接口实时获取协议、调用链和代码相关信息,展示:
- 请求 URL、参数、状态码、耗时;
- SQL 语句与耗时;
- Redis 命令与 Key;
- Dubbo / Feign / MQ 调用信息;
- 代码堆栈与执行方法路径。
2)我的快照
用户可以把实时链路保存为 “我的快照”,用于后续分析和对比。
3)调用链与链路分析可视化
平台同时提供:
- 服务与中间件层的拓扑图;
- 方法与方法之间的代码关系图谱;
- 节点级查看方法名、执行代码行数、覆盖率和圈复杂度。
4)代码覆盖率查看
对于某次快照,可查看:
- 覆盖到的类与方法;
- 行级覆盖情况;
- 方法级覆盖率;
- 分支路径级覆盖情况。
7.2 应用中心
应用中心主要解决 “快照、版本、覆盖率、影响分析分散在不同维度,难以形成统一工程视角” 的问题。
1)在线应用
展示已接入 Agent 的应用列表及运行状态。
2)系统快照
系统快照用于沉淀一次真实请求或测试执行的全链路信息,包括:
- 基本信息:traceId、版本、创建时间;
- 流程图:服务与中间件调用拓扑;
- 堆栈列表:链路中的代码与协议节点;
- 详情:SQL、数据库、HTTP 节点等扩展信息。
3)版本比对
支持两种方式:
-
字节码级比对:上传 Jar / War 包,通过 ASM 解析对比类 / 方法变化;
-
源码级比对:基于 Git Commit,使用 Git 差异计算两个版本之间的变更,定位到具体的变更行号。
比对完成后,可查看:
版本变更影响分析

4)覆盖率中心
全量覆盖率
统计当前版本下所有系统快照覆盖到的代码,生成完整报告。
增量覆盖率
只统计 Git Diff 范围内的变更代码覆盖情况,帮助聚焦本次迭代风险。
趋势与对比
支持:
源码着色
平台从 Git 仓库下载源码文件,并结合覆盖率明细对源码逐行着色:
- 🟢 绿色:已覆盖
- 🔴 红色:未覆盖
- 🟡 黄色:部分覆盖
八、AI 功能重点介绍
AI 模块不是平台边缘功能,而是贯穿平台 “理解、分析、建议” 的智能中枢,主要解决 “数据已经可见,但问题仍难解释、建议仍依赖经验” 的问题。
AI 在平台中的角色分层
8.1 缺陷诊断
AI 会对正常请求与异常请求的调用链进行对比,并从以下维度分析差异:
再按照以下结构输出结果:
- 首次异常位置
- 异常传播路径
- 性能突变点
- 新增 / 缺失节点
- 最终根因推断
- 修复建议
AI 缺陷诊断流程

这使得缺陷分析从 “人工看链路” 提升到 “平台辅助解释链路”。
8.2 性能分析
AI 根据调用链和时间区间统计:
- 接口平均耗时
- P90 / P95 / P99
- 错误率
- 节点级耗时分布
- 性能回归阈值变化
当检测到如下情况时,可触发性能回归判断:
- 平均耗时增幅超过阈值
- P90 显著上升
- 错误率明显增加
并进一步指出:
- 变慢的是哪个节点;
- 是本地逻辑、数据库、还是下游依赖;
- 哪个版本开始出现变化。
8.3 测试推荐
测试推荐解决的是 “知道哪里没覆盖,但不知道下一步该怎么测” 的问题。
AI 综合以下信息生成测试建议:
- 覆盖率盲区
- 低覆盖高复杂度类
- 代码变更范围
- 调用链实际运行关系
- 历史系统快照
推荐的测试场景可覆盖:
AI 测试推荐闭环
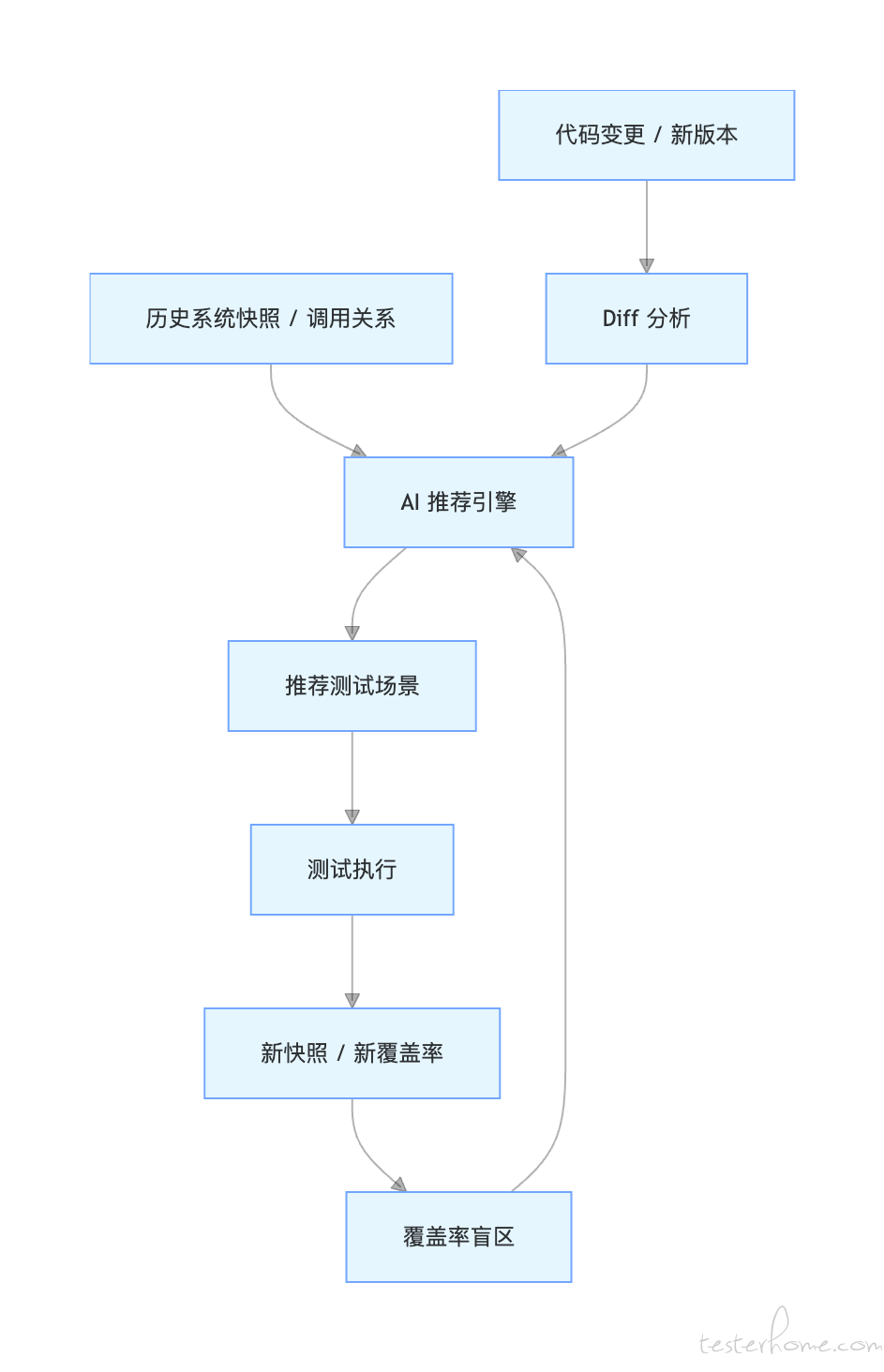
这样测试推荐不再只是 “凭经验补几个 case”,而是建立在真实代码和运行行为之上的智能建议。
8.4 代码关系融合分析
AI 将静态代码关系和动态调用链关系融合到一个视图中:
-
静态维度:谁调用谁、谁依赖谁;
-
动态维度:运行时到底有没有执行到;
-
差异集合:定义了但从未实际跑到的调用关系;
-
风险识别:代码结构复杂但动态覆盖不足的热点区域。
8.5 多模型动态调度
平台中的 AI Agent 并不依赖单一模型,而是根据任务类型做动态切换:
- SIMPLE:轻量问答
- COMPLEX:复杂分析
- CODE:代码理解
- VISION:图谱理解
- LONG_CONTEXT:长上下文推理
同时具备:
- 模型故障自动切换
- Tool Calling 多层兜底
- 不同模型能力的适配策略
8.6 多轮对话上下文管理
面向测试领域,AI 模块支持:
- 意图识别:覆盖率、调用链、性能、缺陷、版本等主题识别;
- 意图追踪:记录用户关注点的演变;
- 摘要压缩:保留长期对话核心信息;
- 多轮衔接:支持围绕一个问题持续追问与细化。
这让 AI 不只是一次性回答,而更像测试人员的长期协作助手。
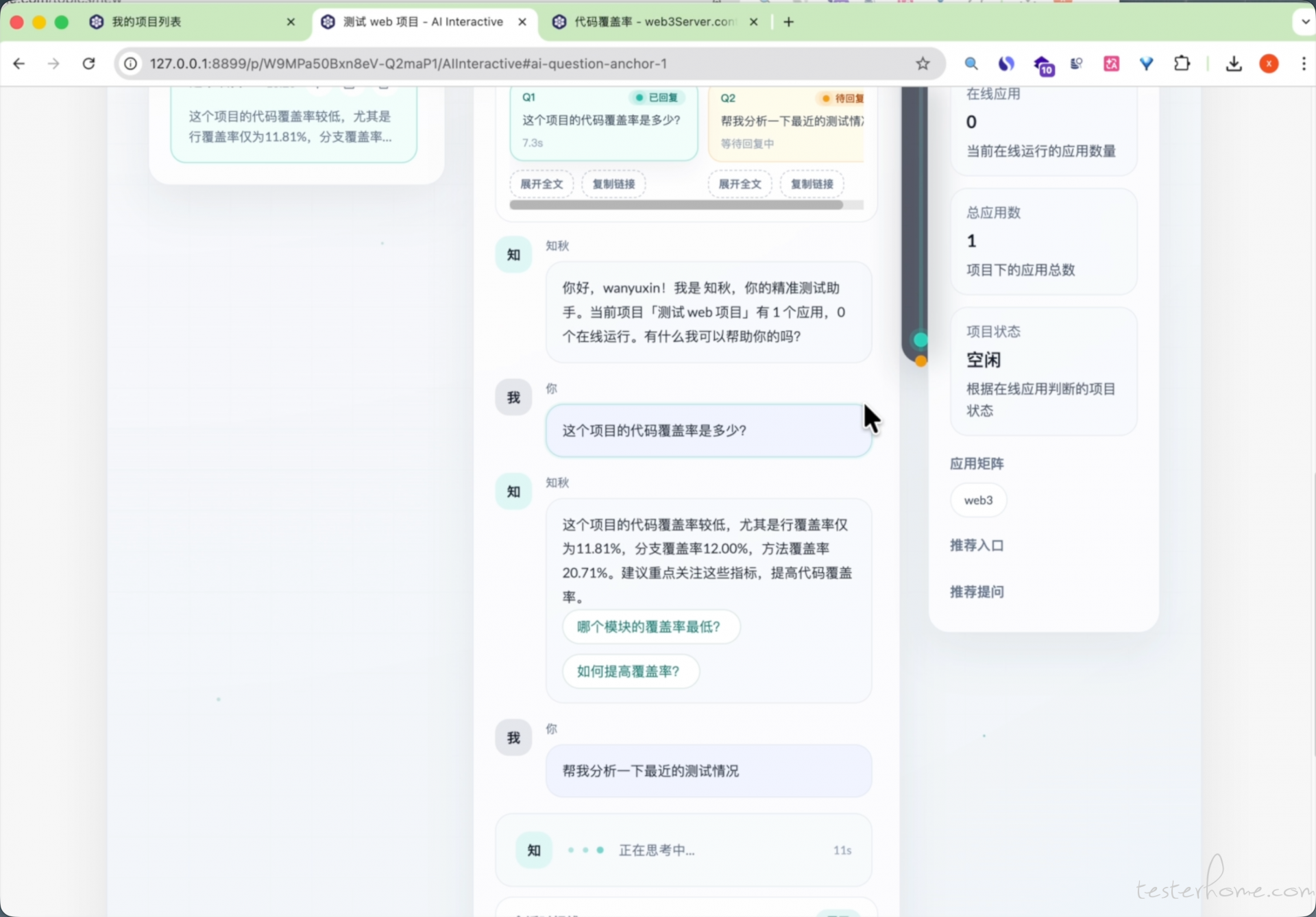
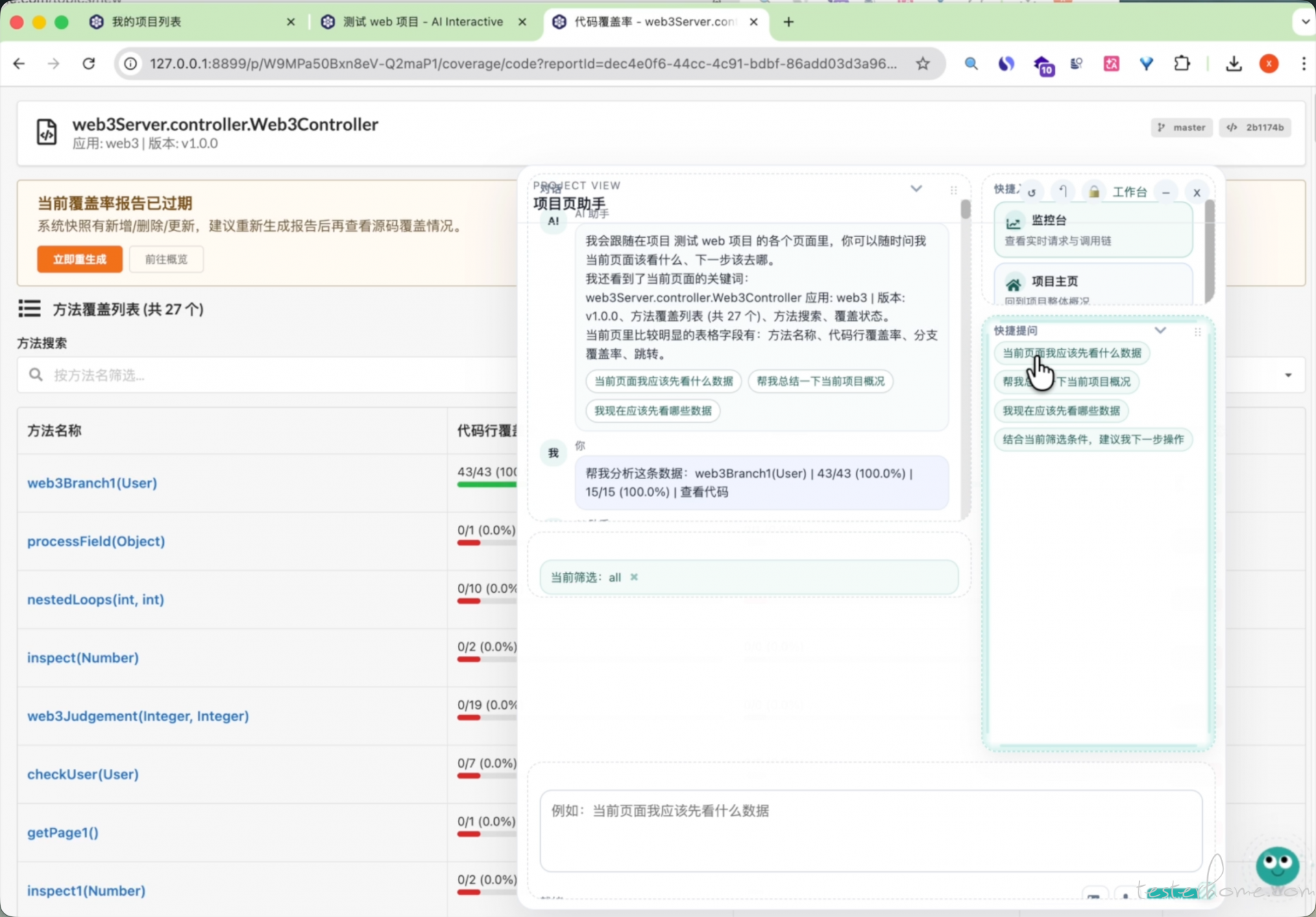
九、典型场景举例
下面用几个更贴近真实工作的场景,说明平台中的精准测试与 AI 是如何协同发挥作用的。
场景一:版本上线前的精准回归
问题
某次迭代中,订单服务修改了折扣计算和库存校验逻辑。测试团队知道 “代码改了”,但不知道该优先回归哪些业务场景。
平台处理过程
- 使用 Git Diff 比较两个 Commit;
- 平台识别变更类、变更方法和变更代码行;
- 从历史系统快照中反查哪些测试场景和接口触达过这些代码;
- 生成 “影响范围 + 影响快照 + 影响接口” 的可视化报告;
- AI 结合变更点和覆盖率盲区,推荐还应补充的边界与异常测试场景。
输出示例
- 已覆盖历史场景:下单、优惠券校验、库存预扣减;
- 高风险未充分覆盖场景:并发下单、库存不足、优惠券叠加冲突;
- 建议优先回归接口:订单确认、库存锁定、优惠券结算。
价值
- 避免全量回归过重;
- 避免选择性回归漏掉关键路径;
- 回归范围从 “经验判断” 变成 “数据支持 + AI 建议”。
场景二:线上缺陷快速定位
问题
同一个接口在测试环境正常、线上偶发异常,但异常难以稳定复现,研发排查成本很高。
平台处理过程
- 提取正常请求与异常请求的系统快照;
- AI 对比两条调用链在节点、状态、耗时上的差异;
- 标识 “首次异常位置” 和 “异常传播路径”;
- 结合代码关系图谱分析可疑方法;
- 输出结构化根因分析结论。
输出示例
- 正常链路中存在缓存命中节点,异常链路缺失该节点;
- 异常链路新增一次下游库存服务重试调用;
- 某个 SQL 节点平均耗时从 30ms 上升至 450ms;
- 根因推断:缓存失效后触发库存表慢查询,进而导致接口超时。
价值
- 缩短故障定位路径;
- 让链路图不只是 “展示图”,而成为可解释的诊断依据;
- 降低对资深专家人工经验的依赖。
场景三:低覆盖高风险模块补测
问题
某模块覆盖率长期偏低,但类的圈复杂度很高,测试团队知道有风险,却不知道优先补哪些用例。
平台处理过程
- 平台识别低覆盖率且高复杂度的类;
- 结合调用链关系找到关键入口接口;
- 分析该模块已覆盖与未覆盖的代码区域;
- AI 自动生成补测建议,按正常 / 边界 / 异常 / 权限 / 并发分类给出测试场景。
输出示例
- 正常场景:标准参数下的正常下单流程;
- 边界场景:库存为 0、优惠额度为 0、数量为 1 的边界校验;
- 异常场景:库存服务超时、参数缺失、非法折扣值;
- 权限场景:无权限账号调用;
- 并发场景:多个用户同时抢购同一商品。
价值
- 覆盖率报告变成测试设计输入;
- 把 “看数字” 变成 “补场景”;
- 让测试策略更聚焦高风险区域。
场景四:性能回归分析
问题
版本发布后,核心接口平均耗时上升,但很难快速判断是本地代码、数据库还是下游服务导致。
平台处理过程
- 对比发布前后两个时间窗口的系统快照和链路统计;
- AI 分析 avg / p90 / errRate 的变化;
- 找出耗时突增节点;
- 结合版本变更点和调用链差异给出原因判断。
输出示例
- 平均耗时上升 28%;
- P90 上升 42%;
- 错误率变化不大;
- 新版本新增一次规则引擎调用;
- 可疑瓶颈节点:规则引擎远程调用、订单明细 SQL 查询。
价值
- 把性能问题从 “经验排查” 变成 “结构化对比”;
- 更快判断是代码问题、依赖问题还是配置问题;
- 为性能优化给出直接线索。
十、平台核心价值总结
从平台能力角度看,其价值主要体现在四个方面。
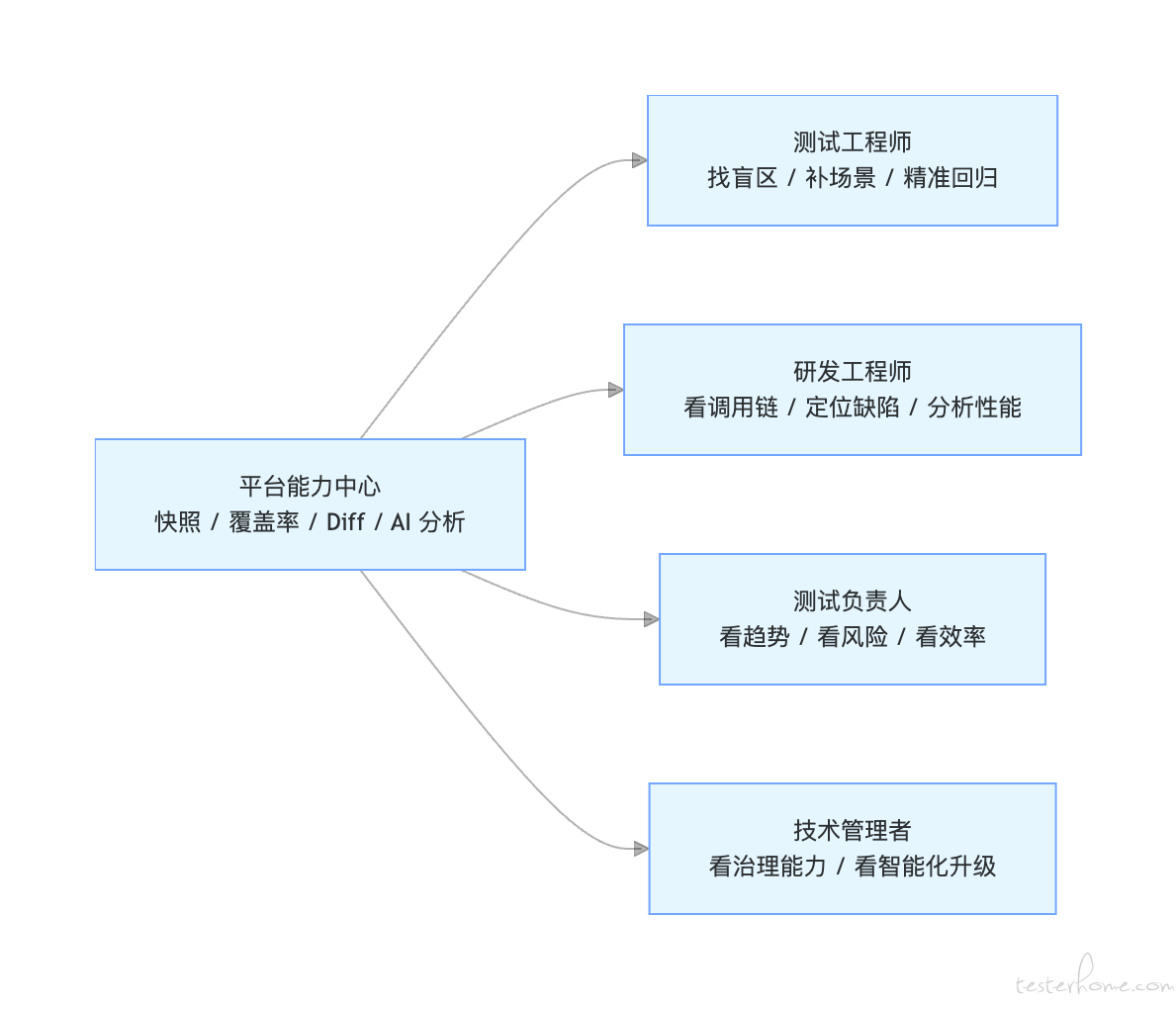
多角色用户价值
1)让测试过程可追溯
平台把测试场景、调用链、代码执行路径、覆盖率结果连接起来,使测试过程从 “结果可见” 升级到 “过程可追溯”。
2)让代码变更可评估
平台能把版本变更与历史系统快照关联起来,识别影响范围和回归重点,使代码变化从 “看 Git Diff” 升级到 “看测试影响”。
3)让测试决策可智能化
AI 结合覆盖率盲区、代码变更和调用关系,自动推荐场景和优先级,使测试决策从 “拍脑袋” 升级到 “有依据的建议”。
4)让缺陷分析更高效
AI 基于正常 / 异常链路和性能变化做根因推断,使问题排查从 “人工读链路” 升级到 “平台辅助解释链路”。
可以把平台的价值概括为:
让测试从 “执行行为” 变成 “数据资产”,再从 “数据资产” 变成 “智能能力”。
十一、适用对象
这类平台并不是只服务测试团队,而是面向多角色协同的平台。
测试工程师
- 看覆盖率、找盲区;
- 做测试场景补充;
- 做精准回归范围筛选;
- 借助 AI 提升测试设计效率。
开发工程师
- 看调用链与代码关系;
- 分析缺陷根因;
- 理解版本变更的影响;
- 快速定位性能瓶颈和异常传播路径。
测试负责人 / 质量负责人
- 看覆盖率趋势;
- 看版本风险;
- 看回归效率;
- 看平台沉淀是否真正形成质量治理能力。
架构师 / 技术管理者
- 看平台是否建立统一的测试与运行数据底座;
- 看是否形成从观测到决策的闭环;
- 看 AI 是否真正增强了研发测试协同效率。
十二、与传统方案的区别
在技术实践中,很多团队会自然提出一个问题:既然已经有 JaCoCo、APM、日志平台、链路追踪系统,为什么还需要这样一套精准测试平台?
这个问题非常关键。因为其价值,并不在于替代单一工具,而在于把多个本来割裂的能力组合成 “测试场景—调用链—代码逻辑—版本变更—AI 分析” 的统一闭环。
12.1 与传统覆盖率工具的区别
传统覆盖率工具(如 JaCoCo)更擅长回答:
- 某个测试执行后,哪些类、方法、代码行被跑到了;
- 当前工程总体覆盖率是多少。
但它通常不擅长回答:
- 这些覆盖率是由哪个真实业务场景产生的;
- 某次版本变更具体影响了哪些测试场景;
- 哪些未覆盖代码是真正高风险区域;
- 哪些场景应该优先补测。
换句话说,传统覆盖率工具更偏 “代码统计工具”,而这类平台更偏 “测试追溯与决策支持平台”。
| 对比维度 |
传统覆盖率工具 |
精准测试平台 |
| 类 / 方法 / 行覆盖率 |
支持 |
支持 |
| 分支路径级分析 |
一般较粗 |
支持更细粒度路径追踪 |
| 请求级覆盖率隔离 |
通常不支持 |
支持 |
| 测试场景到代码追溯 |
弱 |
强 |
| 代码变更到测试场景反查 |
通常不支持 |
支持 |
| 覆盖率结果与业务链路结合 |
弱 |
强 |
| AI 补测建议 |
不支持 |
支持 |
12.2 与普通 APM / 可观测平台的区别
APM 和链路追踪平台更擅长回答:
- 某个接口慢不慢;
- 哪个调用节点耗时高;
- 哪个依赖服务出错了;
- 当前请求链路长什么样。
但它们通常不关心:
- 这个请求到底覆盖了哪些代码行和分支;
- 当前链路对应的代码变更范围是什么;
- 哪些测试场景已经触达了这段代码;
- 如何把观测结果直接转成回归测试建议。
因此,普通可观测平台更偏 “运行态诊断”,而这类平台更强调 “运行态诊断 + 测试追溯 + 变更影响分析 + AI 决策建议” 的联动。
| 对比维度 |
普通 APM / 可观测平台 |
精准测试平台 |
| 请求链路追踪 |
支持 |
支持 |
| SQL / Redis / RPC 观测 |
支持 |
支持 |
| 代码覆盖率分析 |
通常不支持 |
支持 |
| 变更影响分析 |
通常不支持 |
支持 |
| 快照沉淀与复盘 |
部分支持 |
强化支持 |
| 回归场景推荐 |
不支持 |
支持 |
| 测试与研发协同分析 |
弱 |
强 |
12.3 与 “覆盖率 + APM + 日志平台拼装方案” 的区别
理论上,一个团队也可以把以下工具拼装起来:
- JaCoCo 负责覆盖率;
- SkyWalking / Zipkin / Pinpoint / APM 负责链路追踪;
- ELK 负责日志检索;
- Git 平台负责查看 Diff。
这类拼装方案当然有价值,但在实际落地时通常会遇到两个问题:
1)数据之间没有天然主键
- 覆盖率数字是一套口径;
- trace 是另一套口径;
- Git Diff 是第三套口径;
- 测试场景管理又是第四套口径。
这些数据之间往往缺少统一关联键,导致团队只能依赖人工拼接理解。
2)无法形成可直接使用的测试决策闭环
即使链路、日志、Diff、覆盖率都能分别看到,也仍然很难自动回答:
- 本次最该回归哪些场景;
- 哪些代码虽已覆盖但仍高风险;
- 哪些问题是变更引起的;
- 哪些缺陷已经能够从链路和覆盖率差异中推断根因。
而这类平台的重点,正是把这些数据统一沉淀到平台内部,通过快照、覆盖率、变更、调用链和 AI 工具形成联动分析。
12.4 平台的核心技术辨识度
其独特性不在于单点能力 “绝对新”,而在于以下几个能力被统一打通:
-
请求级覆盖率:把覆盖率与 traceId / 场景绑定,而不是只保留全局统计数字;
-
双向追溯:既能从测试场景追代码,也能从代码变更反查场景;
-
版本影响分析:把 Git Diff、字节码差异和历史快照关联起来;
-
动态链路与静态结构融合:同时理解 “定义关系” 和 “运行关系”;
-
AI 智能分析:在已有精准测试数据底座之上做缺陷诊断、性能分析和测试推荐。
换句话说,如果说传统工具链回答的是 “局部问题”,那么这类平台更希望回答的是:
在一个真实版本演进过程中,哪些代码变了、哪些链路跑了、哪些场景覆盖了、哪些风险未消除,以及下一步最该怎么测。
十三、技术与实现补充说明
13.1 核心技术栈
| 领域 |
技术 |
用途 |
| 字节码插桩 |
Javassist |
协议入口和方法代理拦截 |
| 字节码插桩 |
ASM |
行级与分支级覆盖探针注入 |
| 链路追踪 |
ThreadLocal + InheritableThreadLocal |
请求级上下文传递 |
| 版本比对 |
JGit + ASM |
Git Diff 与字节码结构比对 |
| 数据存储 |
Elasticsearch |
快照、链路、覆盖率、版本、源码结构信息 |
| 缓存与会话 |
Redis / Redisson |
缓存、锁、会话支持 |
| AI 分析 |
LangChain4j |
LLM 接入、Agent 编排、工具调用 |
13.2 无损插桩思路
平台采用可理解为 SABI(SourceCode Analyzer ByteCode Instrumentation) 的模式:
-
观测与分析在源码结构维度:预先分析类、方法、行号、分支等结构;
-
插桩在字节码维度:探针注入为非常轻量的布尔赋值;
-
读取在运行时低开销完成:通过布尔数组记录覆盖情况,避免复杂同步和 IO。
13.3 数据架构
| 存储介质 |
用途 |
| Elasticsearch |
覆盖率报告、类覆盖率、系统快照、链路节点、静态源码信息、版本中心、用例中心 |
| Redis |
缓存、会话管理、分布式锁 |
| Git 仓库 |
版本管理、Diff 计算、源码下载 |
| 本地文件系统 |
Git 仓库缓存、源码 ZIP 包、比对文件缓存 |
十四、当前挑战与边界
1)复杂异步链路的完整还原仍有挑战
平台已经支持基于 “线程上下文” 与上下文包装的链路透传,但在复杂线程切换、跨进程异步编排、多级消息回调等场景下,调用链完整还原仍然具有挑战性。
2)AI 分析质量依赖数据完整性
AI 的能力本质上建立在平台沉淀的数据质量之上。如果系统快照不完整、调用链采集不连续、版本信息不准确,AI 给出的分析和推荐也会受到限制。
3)测试推荐目前仍然属于辅助决策
AI 可以根据覆盖率、变更范围和调用关系给出推荐,但是否采纳、如何调整优先级,仍需要结合业务语义、测试策略与团队经验综合判断。
4)不同业务系统的接入复杂度并不完全相同
虽然 JavaAgent 方式本身是无侵入的,但不同团队的类加载器体系、中间件组合、自定义线程模型与部署模式不同,仍可能导致接入、配置和过滤规则存在差异。
5)覆盖率高并不等于风险低
平台可以精确说明 “哪些代码被跑到”,但无法天然保证 “测试断言是否有效”“业务规则是否完全正确”。因此精准测试与 AI 更适合做风险识别与决策支撑,而不是替代完整的测试设计。
十五、下一步的探索方向
“引入 AI” 不是给平台增加一个问答入口,而是代表平台演进方向的变化。下一步可以继续深入四个方向。
测试智能闭环图

1)从 “分析” 走向 “生成”
未来可以探索:
- 自动生成测试场景草案;
- 自动生成接口级测试数据建议;
- 自动生成缺陷复现步骤与修复说明草案;
- 自动生成覆盖率提升建议列表。
2)从 “推荐” 走向 “协同决策”
未来可以进一步支持:
- 基于版本风险自动排序测试任务;
- 根据历史缺陷分布调整回归优先级;
- 基于覆盖率、复杂度和变更范围给出上线风险提示;
- 面向测试负责人生成质量看板和行动建议。
3)从 “单次问答” 走向 “长期学习”
未来可通过反馈机制沉淀:
- 历史分析结果;
- 用户采纳与否;
- 测试推荐有效性;
- 常见问题模式与解决策略。
从而逐步构建测试领域的长期知识库与学习机制。
4)从 “平台工具” 走向 “测试智能体”
进一步的发展方向,是让 AI 不只是平台中的一个模块,而是成为测试人员和研发人员的智能协作助手:
- 理解用户问题;
- 自动调用覆盖率、快照、版本比对、代码关系等工具;
- 给出结构化结论;
- 在多轮对话中持续跟踪同一问题;
- 逐步参与测试分析、测试设计与回归决策。
结语
精准测试与 AI 的结合,并不是把 “精准测试” 和 “AI” 做简单叠加,而是在平台能力、数据结构和使用方式三个层面同时升级。
它所探索的,不只是:
- 如何采集调用链;
- 如何计算覆盖率;
- 如何比对版本差异;
更重要的是:
- 如何让测试过程变得可追溯;
- 如何让代码变更变得可评估;
- 如何让平台数据变得可理解;
- 如何让 AI 真正参与测试分析与决策。
最终,这类平台想要构建的是一条完整的测试智能闭环:
采集运行数据,沉淀测试资产,理解系统变化,分析质量风险,推荐测试动作,持续反馈优化。
这既是精准测试平台的升级方向,也是 “测试平台走向智能平台” 的一次探索。
从工程实现上看,这一探索已经可以在当前仓库中找到较清晰的落点:采集端负责运行时采集与覆盖率探针,服务端负责快照、版本、覆盖率与展示能力,智能分析模块负责分析、工具调用与上下文协同。也正因为这些模块已经具备相对独立的职责边界,这类平台才有机会在现有精准测试能力之上继续向 “测试智能体” 演进。
参考文献
中文参考
[1] 吴恩达.《Agentic AI:构建能够推理、使用工具并完成任务的智能体》. Available at: https://www.deeplearning.ai/
[2] 李宏毅.《生成式人工智能导论》. Available at: https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php
[3] 黄佳.《大模型应用开发:从 Prompt、RAG 到 Agent》. Available at: https://www.manning.com/books/ai-agents-and-applications
[4] 王树森.《从大语言模型到智能体:技术演进与系统设计》.
[5] 机器之心.《从 Prompt Engineering 到 Agent Engineering:大模型应用的工程化路径》. Available at: https://www.jiqizhixin.com/
[6] InfoQ 中文.《RAG、Tool Calling 与 Agent:大模型应用架构的三条主线》. Available at: https://www.infoq.cn/
英文参考
[7] Anthropic. Building Effective Agents. Available at: https://www.anthropic.com/engineering/building-effective-agents
[8] OpenAI. Prompt Engineering Guide. Available at: https://platform.openai.com/docs/guides/prompt-engineering
[9] Yao, S., Zhao, J., Yu, D., et al. ReAct: Synergizing Reasoning and Acting in Language Models. Available at: https://arxiv.org/abs/2210.03629
[10] Lewis, P., Perez, E., Piktus, A., et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Available at: https://arxiv.org/abs/2005.11401

↙↙↙阅读原文可查看相关链接,并与作者交流