
一、 现场:CPU 爆表与消失的 200
【用户反馈】:系统登录不上了。
【技术排查】:
网关层突发异常:单个 APISIX Pod 的 CPU 飙升至 Limit 临界点(99%),随后触发 K8S 告警:Readiness probe failed: dial tcp i/o timeout。
下游 “稳如泰山”:排查发现下游微服务的响应耗时并无波动。
网关日志惨烈:线上网关日志出现大量 404 错误。
【紧急处理】: 立即重启 CPU 满载的 Pod。重启后大面积报错消失,但诡异的是,线上仍持续遗留少量的 404 错误。
二、 深度复盘:从 “配置调通” 到 “架构韧性”
Pod 状态虽然恢复,但那段长周期的 404 报错成了我心中的刺。顺着架构图,我揪出了两个潜伏在系统里的 “隐形杀手”:

三、 极致投入:混沌实验的真实反馈
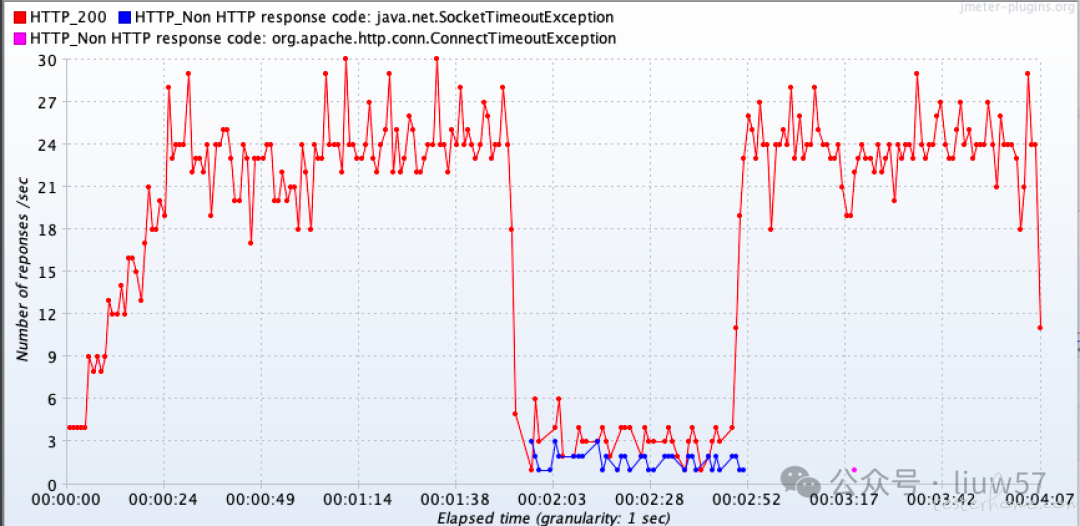
为了验证推论,我配置了 JMeter 进行压测复现:连接超时 $3000ms$,响应超时 $5000ms$,6 线程持续发压。
混沌实验结果:
失效期间的 “震荡”:手动 Kill 掉 Pod 期间,HTTP 200 与 404 并存,这种状态持续了约 1 分钟。
恢复期间的 “丝滑”:失效 Pod 恢复瞬间,返回码几乎全绿(200),无波动。
【结论】:恢复平滑是因为就绪探针挡住了未就绪的流量;但失效时的 1 分钟 404,说明整个链路还存在优化空间。
四、 进一步治理方案:构建确定性的防护网
针对以上漏洞,还有三个方面可以尝试优化:
重构探针策略:强制挂钩业务 Health Check 接口。设置 periodSeconds: 3、failureThreshold: 3。不再只看端口在不在,而是看业务能不能干活,确保第一时间主动摘流。
优化解析机制:在 Nginx resolver 指令中显式设置 valid=5s(甚至更短)。强制 Nginx 定期刷新 DNS 指向,终结 “刻舟求剑” 的尴尬。
横向冗余策略:将 APISIX 实例扩展至 7-8 个 的规模。通过增加横向维度,稀释单点故障的爆炸半径,利用网关层的重试逻辑(Retry)实现用户侧完全无感。
五、 碎碎念:让 “事故” 死在 “混沌” 中
引入 Chaos Mesh 等专业工具:不再依赖偶发的线上故障来驱动改进,而是通过主动注入 Pod Kill、Network Latency、CPU Stress 等实验,在开发和测试阶段就逼出系统底层的 “隐疾”。
构建系统性韧性:混沌工程的本质不是制造混乱,而是通过 “有意的伤害” 来验证系统的容错深度。我们要从探针策略、DNS 解析、网关熔断等每一个微小环节入手,提前完成架构的 “进化”。
