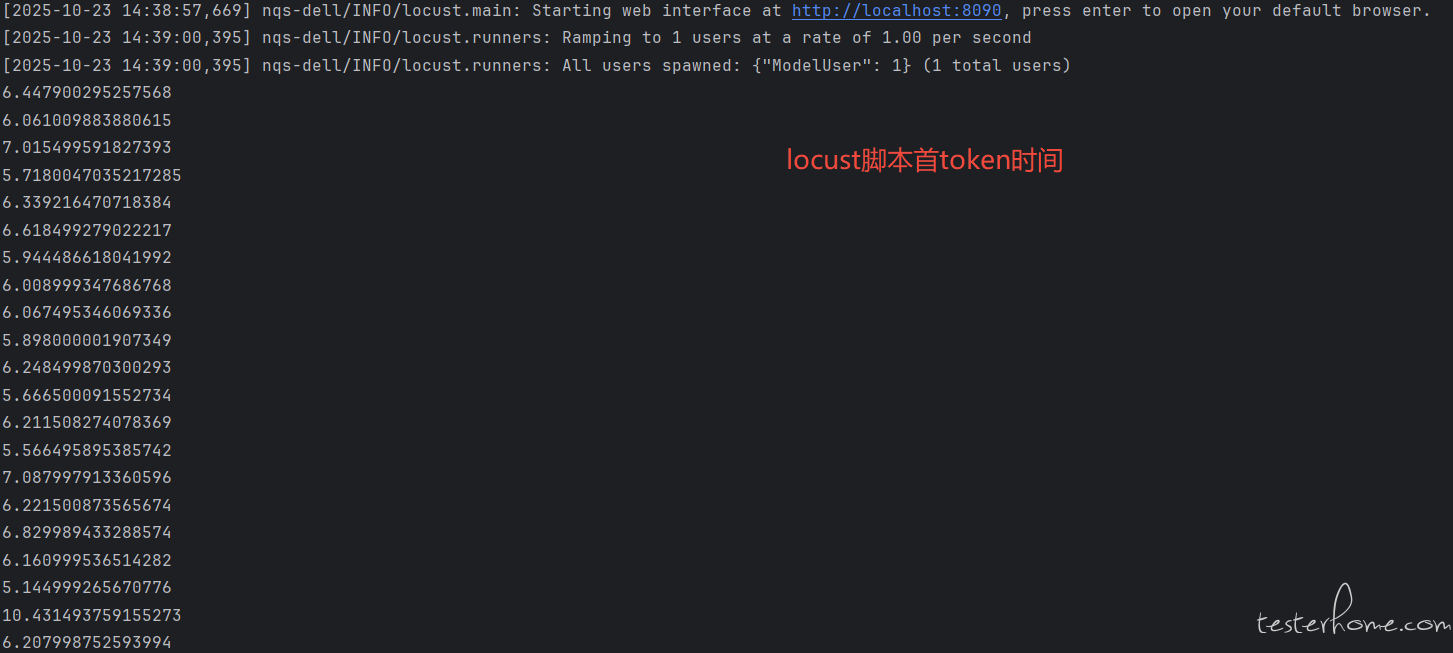
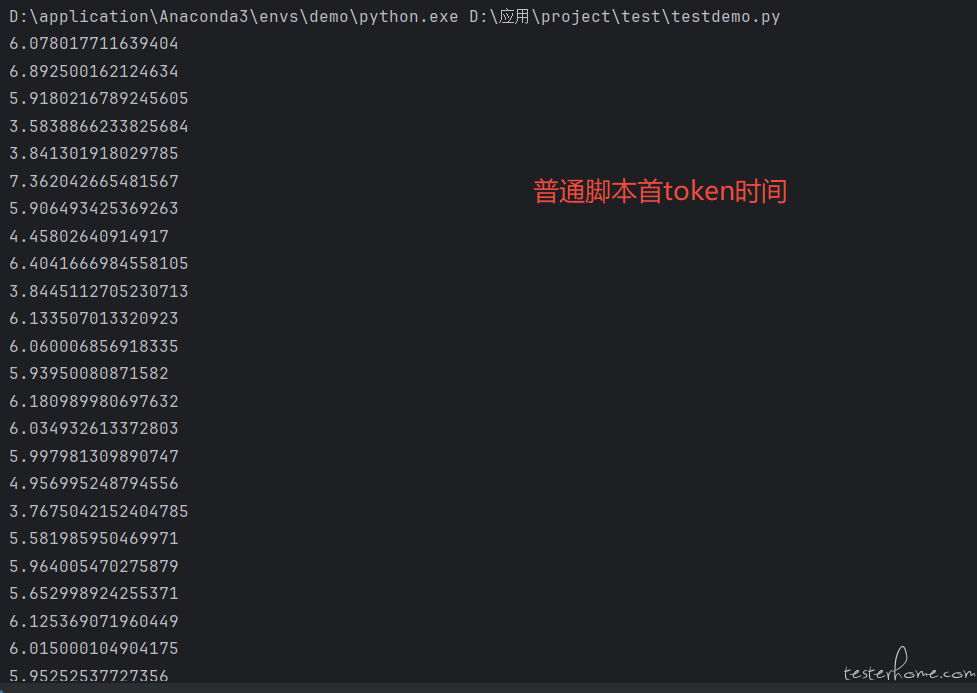
结果如上,因为首 token 时间这个指标请求不会返回只能自己计算。locust 单用户的情况下,首 token 时间整体比普通单用户请求高了 1~2 秒左右。之前几十用户并发的时候,首 token 时间整体甚至高了几秒左右。后面 token 吐字率因为也和时间也关系,估计也是算不准的。我查了一下没合适的答案,问 AI 解释是 locust 内部协程切换需要时间导致。
不知道各位之前使用 locust 遇到这种情况是怎么处理的。
最近用 locust 做大模型问答的性能测试,发现使用 locust 下大模型的首 token 时间会长一点。一开始以为是并发下压测机出现瓶颈导致变慢,切换其他压测机还是会出现问题。后面发现,在 locust 单用户的情况下,大模型的首 token 时间也会比普通请求的大模型首 token 长一点。
为了方便各位佬查看,我把脚本最简化,省略了业务逻辑,对比了 locust 脚本和循环脚本,只打印出大模型首 token 的时间。
"""locust脚本"""
import json
import requests
import urllib3
urllib3.disable_warnings()
import time
from locust import TaskSet, task
from locust.contrib.fasthttp import FastHttpUser
class ModelRequestSet(TaskSet):
def on_start(self):
data = {"account": "xxxx",
"password": "e01fe316609bfa4c374abfe4ff9fa081d298c9a1d0102f991557eefdcd6903c1a229e03f24a483b5f63d74677b8c4a66"}
response = requests.post('http://192.168.224.171:58033/chat/user/login', json=data)
self.login_token = response.json()['result']['token']
@task
def send_request(self):
data = {
"inputs": {"rag": "True", "deep_think": "True", "online_search": "False"},
"query": '十一、请问在建设初期,在解决饮水问题、增加产值、改善生态环境等方面,xxxx的预期效益如何?',
"conversation_id": "",
"files": []}
headers = {"accept": "text/event-stream", "X-Access-Token":self.login_token}
start_time = time.time()
has_executed = False
response = requests.post('http://192.168.224.171:58033/chat/askChat', json=data, headers=headers, verify=False,
stream=True)
for chunk in response.iter_lines(chunk_size=None):
chunk = chunk.decode('utf-8')
if chunk.startswith("data"):
chunk_str = chunk.split('data:', 1)[1].strip()
chunk_json = json.loads(chunk_str)
if chunk_json['event'] == 'message':
if not has_executed:
first_packet_time = time.time()
first_elapsed_time = first_packet_time - start_time
# 打印首token时间
print(first_elapsed_time)
has_executed = True
class ModelUser(FastHttpUser):
tasks = [ModelRequestSet, ]
host = 'http://192.168.224.171:58033/'
"""普通脚本"""
import json
import requests
import time
data = {"account": "xxxx",
"password": "e01fe316609bfa4c374abfe4ff9fa081d298c9a1d0102f991557eefdcd6903c1a229e03f24a483b5f63d74677b8c4a66"}
response = requests.post('http://192.168.224.171:58033/chat/user/login', json=data)
login_token = response.json()['result']['token']
headers = {"accept": "text/event-stream", "X-Access-Token":login_token}
data = {
"appId": "",
"conversation_id": "",
"conversation_type": "chat",
"files": [],
"inputs": {"online_search": "True", "deep_think": "True", "rag": "False"},
"query": "十一、请问在建设初期,在解决饮水问题、增加产值、改善生态环境等方面,xxxx的预期效益如何?"
}
for i in range(0,100):
start_time = time.time()
has_executed = False
response = requests.post('http://192.168.224.171:58033/chat/askChat', json=data, verify=False, headers=headers, stream=True)
for chunk in response.iter_lines(chunk_size=None):
chunk = chunk.decode('utf-8')
if chunk.startswith("data"):
chunk_str = chunk.split('data:', 1)[1].strip()
chunk_json = json.loads(chunk_str)
if chunk_json['event'] == 'message':
if not has_executed:
first_packet_time = time.time()
first_elapsed_time = first_packet_time - start_time
# 打印首token时间
print(first_elapsed_time)
has_executed = True
结果如上,因为首 token 时间这个指标请求不会返回只能自己计算。locust 单用户的情况下,首 token 时间整体比普通单用户请求高了 1~2 秒左右。之前几十用户并发的时候,首 token 时间整体甚至高了几秒左右。后面 token 吐字率因为也和时间也关系,估计也是算不准的。我查了一下没合适的答案,问 AI 解释是 locust 内部协程切换需要时间导致。
不知道各位之前使用 locust 遇到这种情况是怎么处理的。
