引言
大语言模型(LLM)在自然语言理解和生成方面表现卓越,但它们在训练时使用的是静态数据集,缺乏对最新信息的掌握。为了让模型适应特定领域或完成复杂任务,研究人员提出了 微调、检索增强生成(Retrieval‑Augmented Generation,RAG) 以及 代理(Agent) 等技术。
本文对这些技术进行梳理,并结合近两年(截至 2025 年)的最新研究成果,阐述其背景、核心方法和前沿趋势。
大模型微调
1. 全参数微调与对齐方法
为了在特定领域产生更准确、符合人类偏好的结果,需要对预训练的大模型进行微调。常见流程包括:
-
监督微调(SFT):在高质量人工标注示例上继续训练模型,使其输出符合特定任务需求。
-
奖励模型训练:收集人类对模型输出的偏好排名,训练一个奖励模型用来评估输出质量。
-
强化学习微调(RLHF/DPO):使用强化学习算法(如 PPO 或 DPO)优化模型,使其在奖励模型评分下得到更高回报,并通过 KL 正则化限制模型偏离预训练分布。
近年来还出现了 RLAIF 等减少人工反馈的新算法,由于 RLHF 消耗显存巨大,通常结合后文介绍的参数高效微调技术。
2. 参数高效微调(PEFT)
当模型规模不断增长时,完整微调所有参数成本高昂。参数高效微调(PEFT) 只更新少量额外参数,既降低了计算和存储成本,又能在许多任务上达到接近全量微调的性能。Hugging Face 文档指出,PEFT 方法通过微调少量新增参数显著减少计算和存储成本,同时仍能获得与完整微调相当的效果。
2.1 选择性微调
这种方法在原模型中只更新部分权重:
-
冻结层(Freeze Layers):仅微调模型最后几层,其余层保持冻结。
-
BitFit:仅调整模型中的偏置项或部分偏置项。
-
PASTA:只微调特殊标记(如
[CLS]、[SEP])的嵌入,训练参数约占总数的 0.029%,却能接近完整微调性能。
-
自动选择方法:包括 Masking、Diff‑Pruning、FISH、AutoFreeze、Child‑Tuning 等,通过学习二进制掩码或利用 Fisher 信息自动选择需要更新的参数。
优点是无需添加额外模块,参数更新少;缺点是难以捕捉复杂任务模式。
2.2 加性微调(适配器)
加性微调在模型各层间插入小型 适配器 模块,只更新适配器参数:
-
瓶颈适配器(Bottleneck Adapter):将输入降维后通过非线性激活再上投影,并加入残差连接。
-
多适配器(Multi‑Adapter):为不同任务训练多个适配器并在推理时融合,如 Adapter Fusion、AdaMix、MAD‑X 等;MAD‑X 利用语言适配器、任务适配器和可逆适配器应对跨语言迁移。
-
适配器稀疏化:如 AdapterDrop 随机丢弃适配器层以提高训练速度。
2.3 重参数化微调(LoRA 及其变种)
LoRA(Low‑Rank Adaptation) 通过添加低秩分解矩阵 A、B 为权重提供旁路,只更新这两个矩阵,显著减少显存需求。
后续改进包括 KronA、QLoRA、LoRA‑FA、IncreLoRA、Delta‑LoRA 及 MPO 分解等,以提高表达能力或降低量化误差。
2.4 提示微调
提示微调通过在输入或模型内部引入可学习的 “提示” 而不修改原始权重:
-
硬提示:人工设计模板,例如 Pattern‑Exploiting Training(PET)。
-
软提示:学习连续向量表示,例如 Prefix Tuning、Prompt Tuning、P‑Tuning v2 等。
2.5 方法对比表
| 类型 |
核心思想 |
代表方法 |
优点 |
| 全参数微调 |
更新全部参数并通过监督数据和 RLHF 调整行为 |
SFT + 奖励模型 + RLHF |
性能高,适合复杂任务 |
| 选择性微调 |
只更新部分权重(偏置、最后几层或自动选出的参数) |
Freeze Layers、BitFit、PASTA |
参数少,易实现 |
| 加性微调 |
在模型层之间插入小型适配器 |
Bottleneck Adapter、Adapter Fusion、MAD‑X |
模块化,易组合 |
| 重参数化微调 |
添加低秩旁路,只更新旁路参数 |
LoRA、QLoRA、KronA、MPO |
显存友好,性能优 |
| 提示微调 |
学习软/硬提示向量,无需改变模型权重 |
PET、Prefix Tuning、Prompt Tuning、P‑Tuning v2 |
实现最简单,参数最少 |
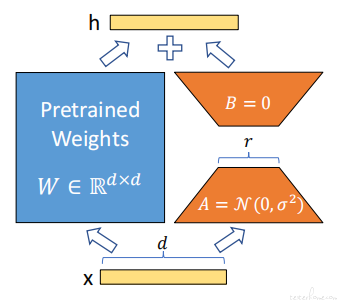
图 1:LoRA 微调示意图(来源 Medium,展示低秩矩阵 A、B 在预训练权重旁路中注入以适配任务)。
检索增强生成(RAG)
1. 为什么需要 RAG
LLM 仅凭参数中的隐含知识往往无法回答领域专有或最新的信息,甚至会产生幻觉。RAG 通过检索外部数据并将相关片段与用户问题组合成新的提示,帮助模型生成更准确、实时的答案。然而随着模型能力提升,传统 RAG 的优势正逐渐减弱,需要深入分析其机制和挑战。
2. RAG 的四大模块
-
索引(Indexing):将外部文档分块并转为稀疏或密集向量表示;
-
检索(Retrieval):包括查询分析、候选检索以及重排序与过滤;
-
生成(Generation):把检索到的内容与用户问题拼接成提示,指导 LLM 输出;
-
编排(Orchestration):协调索引、检索和生成模块的执行顺序与并行化,动态决定是否检索。
3. 目标与挑战
RAG 既要实现 高召回率(找到所有相关文档),又要保持 高精度(避免噪声)。主要挑战包括:
-
知识边界不清:系统难以判断 LLM 是否已有足够知识,导致不必要检索;
-
查询意图分析不足:复杂问题包含多重子任务,需要进行问题分解和改写;
-
外部知识冲突与噪声过滤:来自不同来源的信息可能矛盾,需要过滤不可靠内容;
-
理解 RAG 与 LLM 的交互机制:仍缺乏理论指导,特别是在长文本场景下的设计。
4. RAG 的演进与前沿
为突破传统 RAG 的瓶颈,提出多种改进方向:
-
查询改写与嵌入微调:通过问题重写和嵌入模型微调,提高召回率与精度;
-
知识图增强 RAG:如 GraphRAG、HippoRAG,将文档转为知识图,实现跨文档检索与推理;
-
Agentic RAG:引入自治代理,具备反思、规划和工具使用能力,适应多步推理;
-
长上下文模型:长文本模型可直接载入大型文档,减少检索依赖。
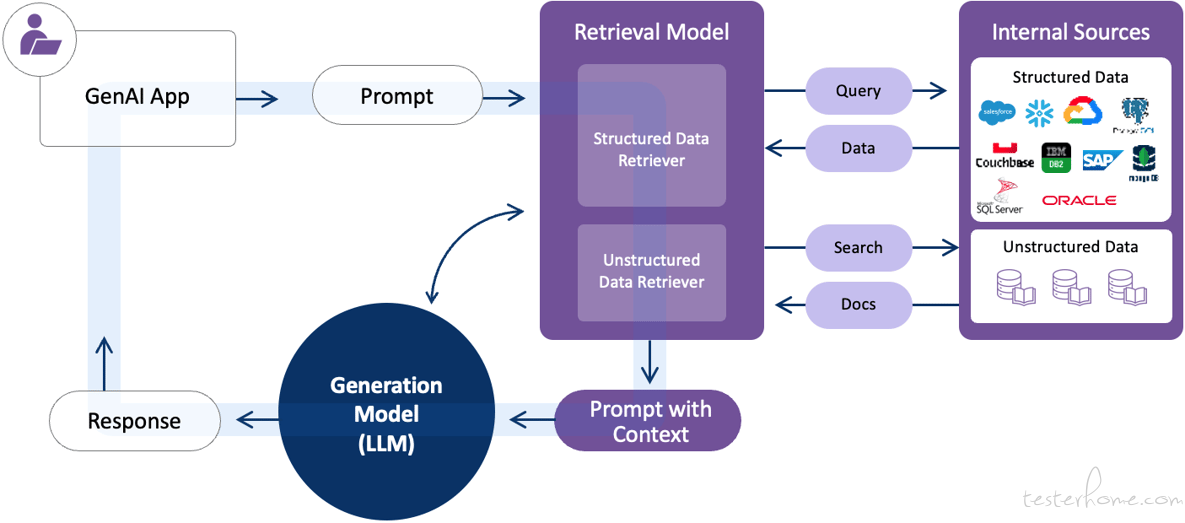
图 2:RAG 架构示意图(来源 K2View,展示用户输入查询、向量检索器、上下文组装和 LLM 生成答案的流程)。
代理(Agent)
1. 基于提示的代理
-
ReAct:交替输出 “思考(Thought)” 和 “动作(Action)”,实现推理与行动的循环;
-
StateAct:在 ReAct 的基础上加入显式状态表示(如目标、库存、位置等);
-
Reflexion / Rewind:模型自我反思并总结经验,从而在后续尝试中改进策略。
2. 经验学习与微调代理
ICLR 2026 论文提出通过 RAG 为代理生成提示并内化到模型中:先运行基础代理收集失败轨迹,再借助强大模型提炼提示,在训练过程中一并融入学生模型,显著提升任务成功率并减少推理开销。
3. Agentic RAG 与智能检索代理
Agentic RAG 将自主代理与 RAG 结合,核心要点包括:
-
反思与规划:代理能自我检查模型输出,根据失败经验调整检索与推理策略;
-
多代理协作与工作流模式:采用提示链、路由、并行化等结构,让多个代理分工协作;
-
智能检索:借助像 Azure AI Search 的 Agentic Retrieval,以代理方式分解复杂查询并并行检索,合并结果。
4. 代理的发展趋势
-
自我反思与改进:代理逐渐具备自我评估并改进策略的能力;
-
多代理协作:评估‑优化器结构和专家‑工作者模式,提升复杂任务的处理能力;
-
融合外部工具:整合搜索引擎、知识图、Web 工具等;
-
安全与伦理:关注错误传播、隐私保护和偏见抑制。
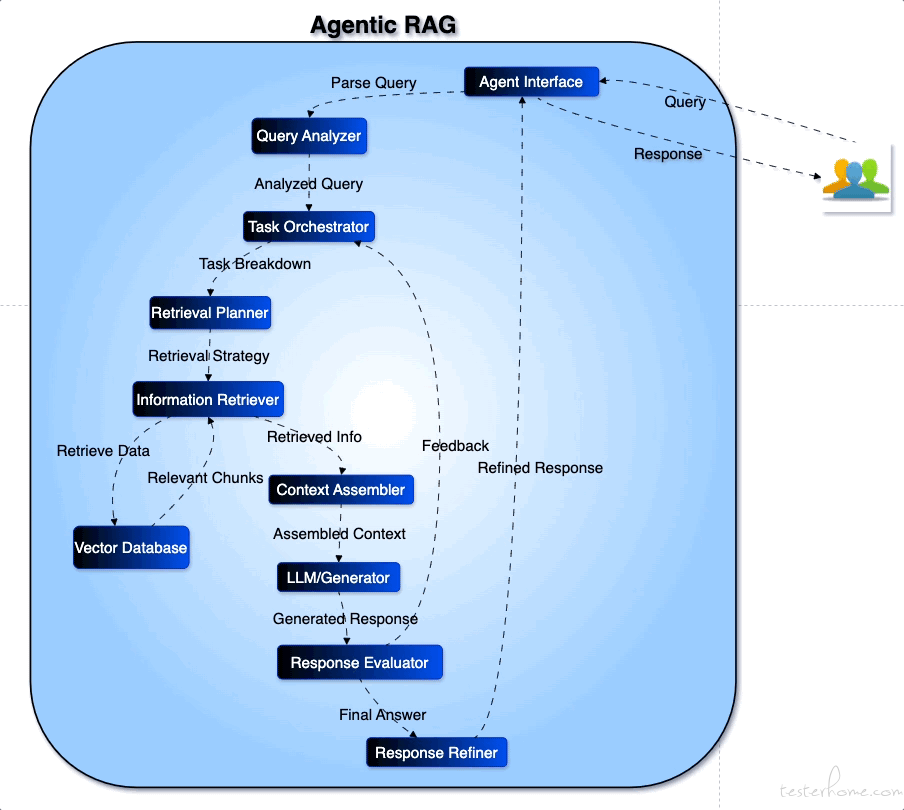
图 3:Agentic RAG 架构示意图(来源 Medium,展示 Query Analyzer、Task Orchestrator、Retrieval Planner、Context Assembler、LLM 生成器等模块协同完成回答流程)。
总结与展望
大模型微调、RAG 与代理是现代 LLM 应用的关键组件:
-
微调:全参数微调结合 SFT 和 RLHF 可在复杂任务上获得最高性能,但资源消耗大。PEFT 利用选择性、适配器、低秩旁路或提示等技术,大幅降低训练成本,适合资源受限或多任务场景。
-
RAG:RAG 通过检索外部知识提高 LLM 处理专业或实时信息的能力。设计索引、检索、生成和编排模块时需平衡召回和精度,并解决噪声、查询分解和知识冲突等挑战。Agentic RAG 通过引入代理改善检索规划,是未来趋势。
-
代理:代理让 LLM 拥有规划、行动和自我反思能力。ReAct、StateAct 等基于提示的方法奠定基础,结合经验学习和 Agentic RAG 的研究,将推动多代理协作与任务自动化。
面向未来,研究者将继续探索如何让大模型在节省资源的同时具备更强的适应性与知识整合能力,并确保模型的安全、可靠与公平。深入理解 RAG 与 LLM 的交互机制、开发稳定的代理算法以及持续优化参数高效微调方法,将是推动通用人工智能落地的关键。

↙↙↙阅读原文可查看相关链接,并与作者交流