我打开了千问
输入【要做语言大模型的 AI 测试,会用到什么工具? 以 deepseek 为例,带我入门】
顺着阿问的回复,我打开了https://agi-eval.cn/
在 AGI-Eval 我找到了一个叫 MULTI-Benchmark 的 AI 评测框架

(一)
那一天在食堂吃午饭
坐我身旁的老领导忽然问我:“黑仔,而家成日讲嗰啲 AI……类似 DeepSeek 呢种问答嘅大模型,系点样测试同评估㗎?”
我随口回了句 “老细犀利!一开口就问倒我测试盲区,我自己都几好奇,等收工之后了解下先”
午睡时,我辗转反侧
脑海里有个声音响了起来:
“富贵之门已经打开,等你走进去”
“难得有刘公公赏识,我们会有很多机会”
起床后,
我打开了千问
输入【要做语言大模型的 AI 测试,会用到什么工具? 以 deepseek 为例,带我入门】
顺着阿问的回复,我打开了https://agi-eval.cn/
在 AGI-Eval 我找到了一个叫 MULTI-Benchmark 的 AI 评测框架
(二)
我以前在内部吹水时说过,
如何短时间熟悉陌生领域业务?
那就要迅速从 上情 下情 内情 外情 四个纬度全面梳理工作内涵和外延,
大集成地动态梳理相关工作的 历史沿革、发展现状、理论前沿、形式问题、对策思路,
确保材料始终 站位高、视角广、思路新、措施实!
但实际操作中呢,我是不会这么干的
我还是喜欢【干中学】
在 git clone https://github.com/OpenDFM/MULTI-Benchmark.git 前
我得先列几个前提,那就是点解我不好回答老领导的问题?
我之前走的测试,大多数问题无非就是 True/False,走自动化能很方便的用 assert 的传统断言
但 AI 的评测带有复杂的需求
带着这些问题,我再去看这个框架咋用和咋实现的
(三)
MULTI-Benchmark框架架构
├── 用户接口层
│ ├── CLI命令行接口
│ ├── Web界面 (deploy.py)
│ └── API接口
├── 业务逻辑层
│ ├── 评测调度器 (eval.py)
│ ├── 数据准备器 (prepare.py)
│ ├── 提示词生成器 (prompts.py)
│ └── 结果分析器 (metrics.py)
├── 模型适配层
│ ├── 本地模型适配器 (models/*)
│ ├── API模型适配器 (models/*_api.py)
│ └── 统一评测接口
├── 数据处理层
│ ├── 题目数据处理
│ ├── 图像数据处理
│ └── 知识库处理
└── 基础设施层
├── 配置管理 (args.py)
├── 工具函数 (utils/)
└── 资源管理
MULTI-Benchmark 框架包含三个核心数据文件,支持选择性使用,不需要每次都全部加载:
| 文件名 | 大小 | 作用 | 使用场景 | 是否必需 |
|---|---|---|---|---|
problem_v1.3.1_20241210_release.json |
~500MB | 题目数据 | 所有测试 | 必需 |
knowledge_v1.2.2_20240212_release.json |
~200MB | 知识库数据 | 需要背景知识的题目 | 条件必需 |
captions_v1.3.1_20241210_blip.csv |
~50MB | 图像描述 |
input_type=1时 |
条件必需 |
graph TD
A[加载配置] --> B[准备数据集]
B --> C[初始化模型]
C --> D[生成提示词]
D --> E[批量推理]
E --> F[结果评分]
F --> G[生成报告]
G --> H[保存结果]
E --> I[检查点保存]
I --> E
F --> J[异常处理]
J --> E
数据流转
原始题目 → 题目解析 → 提示词生成 → 模型推理 → 答案提取 → 评分计算 → 结果汇总
↓ ↓ ↓ ↓ ↓ ↓ ↓
JSON格式 结构化数据 模型输入 模型输出 标准答案 分数矩阵 评测报告
## 二、MULTI 框架的解决方案
专门的评分函数系统:
# MULTI框架的"断言" - 连续评分
score, total_score = evaluation_function(prediction, expected_answer, args)
# 返回:(获得分数, 总分数)
断言函数体系
# eval/metrics.py
EvaluateFuncDict = {
"单选": SingleAnswerChoiceEval, # 单选题断言
"多选": MultipleAnswersChoiceEval, # 多选题断言
"填空": FillInTheBlankEval, # 填空题断言
"解答": OpenendQuestionEval # 开放题断言
}
统一接口设计:
def CustomEvaluationFunction(prediction: str, label: str, args) -> tuple:
"""
自定义评分函数接口
Args:
prediction: 模型预测答案
label: 标准答案
args: 配置参数
Returns:
tuple: (获得分数, 总分数)
"""
# 实现具体的评分逻辑
score = calculate_score(prediction, label)
total_score = get_total_score()
return score, total_score
功能描述:
实现代码:
def SingleAnswerChoiceEval(pred, label, args):
"""
单选题评分函数
断言逻辑:
1. 使用正则表达式提取英文字母
2. 根据配置选择提取位置(开头/结尾)
3. 与标准答案进行精确匹配
"""
# 步骤1:提取所有英文字母
matches = re.findall(r'[a-zA-Z]', pred)
if matches:
# 步骤2:根据配置选择提取位置
if args.answer_position == "start":
answer = matches[0].upper() # 取第一个字母
elif args.answer_position == "end":
answer = matches[-1].upper() # 取最后一个字母
# 步骤3:断言逻辑 - 精确匹配
score = 1 if answer == label else 0
else:
# 没有找到字母,直接0分
score = 0
return score, 1 # (获得分数, 总分数)
断言特点:
功能描述:
实现代码:
def MultipleAnswersChoiceEval(pred, label, args):
"""
多选题评分函数
断言逻辑:
1. 提取并清理答案选项
2. 逐个验证每个选项
3. 严格评分:有错误选项直接0分
"""
# 步骤1:提取答案模式
matches = re.findall(r'[a-zA-Z ,]*[a-zA-Z]+[a-zA-Z ,]*', pred)
score = 0
if matches:
# 选择提取位置
if args.answer_position == "start":
answer = matches[0].upper()
elif args.answer_position == "end":
answer = matches[-1].upper()
# 步骤2:清理答案格式
answer = answer.replace(' ', '').replace(',', '').replace('、', '')
answer = ''.join(sorted(set(answer), key=answer.index)) # 去重并保持顺序
# 步骤3:断言逻辑 - 严格评分
for choice in answer:
if choice in label:
score += 1 # 正确选项+1分
else:
score = 0 # 有错误选项直接0分
break
return score, len(label) # (获得分数, 标准答案选项数)
断言特点:
功能描述:
实现代码:
def FillInTheBlankEval(pred, label, args):
"""
填空题评分函数
断言逻辑:
1. 预处理答案格式
2. 逐个空格进行匹配
3. 支持多个正确答案
"""
score = 0
# 步骤1:预处理答案格式
pred = re.sub(r'\n\n+', '\n', pred) # 合并多个换行
pred = pred.replace("$","").replace(" ","").replace(";","\n").replace(";","\n").split('\n')
label = label.replace("$","").replace(" ","").split('\n')
# 步骤2:逐个填空进行断言
for i in range(min(len(label), len(pred))):
# 主要断言逻辑:精确匹配
if pred[i].strip() == label[i].strip():
score += 1
else:
# 备选断言逻辑:多答案匹配
alternatives = label[i].split('或')
alternatives = [alt.strip() for alt in alternatives]
if len(alternatives) > 1:
if pred[i].strip() in alternatives:
score += 1
return score, len(label) # (获得分数, 填空总数)
断言特点:
功能描述:
实现代码:
def OpenendQuestionEval(pred, label, args):
"""
开放题评分函数
断言逻辑:
1. 中文分词预处理
2. ROUGE相似度计算
3. 连续评分
"""
rouge = Rouge()
# 步骤1:中文分词预处理
pred_ = ' '.join(jieba.cut(pred))
label_ = ' '.join(jieba.cut(label))
# 步骤2:边界情况处理
if label_ == '':
return 0, 0 # 标准答案为空
elif pred_ == '':
return 0, 1 # 预测答案为空
# 步骤3:断言逻辑 - ROUGE相似度评分
rouge_score = rouge.get_scores(pred_, label_, avg=True)
score = rouge_score['rouge-l']['f'] # 使用ROUGE-L的F1分数
return score, 1 # (相似度分数, 总分1)
断言特点:
核心评分函数:
def evaluate_every_problem(args):
"""
主评分流程 - 这是整个断言系统的核心
流程:
1. 加载数据
2. 遍历每道题
3. 选择对应的断言函数
4. 执行断言并记录结果
"""
# 步骤1:加载预测结果和标准答案
with open(args.prediction_file, 'r', encoding="utf-8") as f:
pred_data = json.load(f)
with open(args.label_file, 'r', encoding="utf-8") as f:
label_data = json.load(f)
score_data = {}
# 步骤2:遍历每道题进行断言
for item in pred_data.values():
# 获取题目信息
problem_id = item['question_id'].rsplit('_', 1)[0]
sub_id = item['question_id'].rsplit('_', 1)[1]
# 获取预测答案和标准答案
prediction = item['prediction']
type = label_data[problem_id]["problem_type_list"][int(sub_id)]
label = label_data[problem_id]["problem_answer_list"][int(sub_id)]
# 步骤3:选择并执行对应的断言函数
if type in EvaluateFuncDict:
score, total_score = EvaluateFuncDict[type](prediction, label, args)
else:
score, total_score = 0, 0 # 未知题型默认0分
# 步骤4:记录断言结果
score_data[item['question_id']] = {
"question_id": item['question_id'],
"score": score,
"total_score": total_score
}
动态函数选择:
# 根据题目类型动态选择断言函数
type_to_function_mapping = {
"单选": SingleAnswerChoiceEval,
"多选": MultipleAnswersChoiceEval,
"填空": FillInTheBlankEval,
"解答": OpenendQuestionEval
}
# 执行断言
if question_type in type_to_function_mapping:
assertion_function = type_to_function_mapping[question_type]
score, total = assertion_function(prediction, expected, config)
分数计算:
def calculate_score(args):
"""
汇总所有断言结果
计算:
1. 绝对分数和总分
2. 准确率百分比
3. 改进空间分析
"""
with open(args.score_file, 'r', encoding="utf-8") as f:
target_score = json.load(f)
absolute_score = 0
total_absolute_score = 0
# 汇总所有断言结果
for item in target_score.values():
absolute_score += item['score']
total_absolute_score += item['total_score']
# 计算最终指标
accuracy = absolute_score / total_absolute_score * 100
print(f"Absolute Score: {absolute_score:.2f}/{total_absolute_score}, {accuracy:.2f}%")
return (absolute_score, total_absolute_score, accuracy)
功能描述:
检测模型是否拒绝回答某些问题,并相应调整评分。
实现代码:
def check_rejection(pred):
"""
拒绝回答检测断言
断言逻辑:
- 检测特定的拒绝关键词
- 返回布尔值表示是否拒绝
"""
rejection_keywords = [
"缺少图片信息",
"无法回答",
"信息不足",
"需要更多信息"
]
for keyword in rejection_keywords:
if keyword in pred:
return True
return False
# 在主评分流程中应用
if check_rejection(prediction):
score = 0 # 拒绝回答直接0分
# 统计拒绝次数
image_num = item["question_image_number"]
image_type = "NI" if image_num == 0 else "SI" if image_num == 1 else "MI"
rejection_number[image_type] += total_score
功能描述:
与参考模型的答案进行对比,计算改进空间。
实现代码:
def reference_comparison_assertion(prediction, label, reference_answer, args):
"""
参考答案对比断言
断言逻辑:
1. 评估当前预测
2. 评估参考答案
3. 计算改进空间
"""
# 当前预测的断言结果
current_score, total = EvaluateFuncDict[question_type](prediction, label, args)
# 参考答案的断言结果
ref_score, _ = EvaluateFuncDict[question_type](reference_answer, label, args)
# 计算改进空间
improvement_potential = max(0, ref_score - current_score)
return current_score, total, improvement_potential
功能描述:
根据配置从答案的不同位置提取关键信息。
实现代码:
def position_sensitive_extraction(text, position="end"):
"""
位置敏感的答案提取
支持的位置:
- start: 从开头提取
- end: 从结尾提取
- middle: 从中间提取
- all: 提取所有匹配项
"""
matches = re.findall(r'[a-zA-Z]', text)
if not matches:
return None
if position == "start":
return matches[0].upper()
elif position == "end":
return matches[-1].upper()
elif position == "middle":
mid_index = len(matches) // 2
return matches[mid_index].upper()
elif position == "all":
return [m.upper() for m in matches]
else:
return matches[-1].upper() # 默认取最后一个
功能描述:
处理多轮对话场景的答案验证。
实现代码:
def multi_turn_assertion(conversation_history, expected_responses, args):
"""
多轮对话断言
断言逻辑:
1. 分别评估每轮对话
2. 计算整体对话质量
3. 考虑上下文一致性
"""
total_score = 0
max_score = 0
for i, (response, expected) in enumerate(zip(conversation_history, expected_responses)):
# 单轮断言
turn_score, turn_max = single_turn_assertion(response, expected, args)
# 上下文一致性检查
if i > 0:
consistency_bonus = check_consistency(conversation_history[:i+1])
turn_score += consistency_bonus
total_score += turn_score
max_score += turn_max
return total_score, max_score
步骤 1:定义断言函数
def CustomQuestionTypeEval(pred, label, args):
"""
自定义题型断言函数
Args:
pred: 模型预测答案
label: 标准答案
args: 配置参数
Returns:
tuple: (获得分数, 总分数)
"""
# 实现你的断言逻辑
score = 0
total_score = 1
# 示例:基于关键词匹配的断言
keywords = label.split(',')
matched_keywords = 0
for keyword in keywords:
if keyword.strip().lower() in pred.lower():
matched_keywords += 1
score = matched_keywords / len(keywords)
return score, total_score
步骤 2:注册断言函数
# 在EvaluateFuncDict中注册新函数
EvaluateFuncDict["自定义题型"] = CustomQuestionTypeEval
步骤 3:配置参数支持
def CustomQuestionTypeEval(pred, label, args):
# 支持配置参数
threshold = getattr(args, 'custom_threshold', 0.5)
case_sensitive = getattr(args, 'case_sensitive', False)
# 使用配置参数
if not case_sensitive:
pred = pred.lower()
label = label.lower()
# 实现断言逻辑...
配置文件示例:
# evaluation_config.yaml
evaluation_settings:
answer_position: 'end' # 答案提取位置
case_sensitive: false # 是否区分大小写
fuzzy_threshold: 0.8 # 模糊匹配阈值
partial_credit: true # 是否允许部分分数
single_choice:
strict_mode: true # 严格模式
allow_multiple: false # 是否允许多个答案
multiple_choice:
penalty_wrong: true # 错误选项是否扣分
min_correct_ratio: 0.6 # 最低正确率要求
fill_blank:
alternative_separator: '或' # 备选答案分隔符
ignore_punctuation: true # 是否忽略标点符号
open_ended:
rouge_type: 'rouge-l' # ROUGE评分类型
min_similarity: 0.3 # 最低相似度要求
使用配置的断言函数:
def ConfigurableEval(pred, label, args, config):
"""
可配置的断言函数
"""
# 从配置中读取参数
case_sensitive = config.get('case_sensitive', False)
fuzzy_threshold = config.get('fuzzy_threshold', 0.8)
# 应用配置
if not case_sensitive:
pred = pred.lower()
label = label.lower()
# 实现断言逻辑...
完整的评测脚本:
def batch_evaluation_example():
"""
批量评测示例
"""
# 1. 准备数据
predictions = load_predictions("model_outputs.json")
ground_truth = load_ground_truth("answers.json")
# 2. 初始化评分器
evaluator = MultiAssertionEvaluator()
# 3. 批量执行断言
results = []
for question_id, pred_data in predictions.items():
if question_id in ground_truth:
gt_data = ground_truth[question_id]
# 执行对应的断言函数
score, total = evaluator.evaluate(
prediction=pred_data['answer'],
label=gt_data['correct_answer'],
question_type=gt_data['type'],
config=evaluation_config
)
results.append({
'question_id': question_id,
'score': score,
'total_score': total,
'accuracy': score / total if total > 0 else 0
})
# 4. 生成报告
generate_evaluation_report(results)
调试断言函数:
def debug_assertion(pred, label, question_type, args):
"""
调试断言函数
"""
print(f"调试信息:")
print(f" 题目类型: {question_type}")
print(f" 预测答案: '{pred}'")
print(f" 标准答案: '{label}'")
# 执行断言
if question_type in EvaluateFuncDict:
score, total = EvaluateFuncDict[question_type](pred, label, args)
print(f" 断言结果: {score}/{total} = {score/total:.2%}")
# 详细分析
if score == 0:
print(f" 失败原因分析:")
analyze_failure(pred, label, question_type)
else:
print(f" 错误: 未知题目类型 '{question_type}'")
return score, total
def analyze_failure(pred, label, question_type):
"""
分析断言失败的原因
"""
if question_type == "单选":
matches = re.findall(r'[a-zA-Z]', pred)
if not matches:
print(f" - 预测答案中没有找到英文字母")
else:
print(f" - 找到的字母: {matches}")
print(f" - 期望的字母: {label}")
elif question_type == "填空":
pred_lines = pred.split('\n')
label_lines = label.split('\n')
print(f" - 预测行数: {len(pred_lines)}")
print(f" - 期望行数: {len(label_lines)}")
for i, (p, l) in enumerate(zip(pred_lines, label_lines)):
if p.strip() != l.strip():
print(f" - 第{i+1}行不匹配: '{p.strip()}' vs '{l.strip()}'")
实现新的评分指标:
class CustomMetrics:
"""
自定义评分指标类
"""
@staticmethod
def semantic_similarity(pred, label):
"""
语义相似度评分
"""
# 使用预训练模型计算语义相似度
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
embeddings = model.encode([pred, label])
# 计算余弦相似度
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity([embeddings[0]], [embeddings[1]])[0][0]
return similarity, 1.0
@staticmethod
def factual_accuracy(pred, label):
"""
事实准确性评分
"""
# 提取关键事实
pred_facts = extract_facts(pred)
label_facts = extract_facts(label)
# 计算事实匹配度
matched_facts = len(set(pred_facts) & set(label_facts))
total_facts = len(label_facts)
return matched_facts / total_facts if total_facts > 0 else 0, 1.0
@staticmethod
def logical_consistency(pred, label):
"""
逻辑一致性评分
"""
# 检查逻辑推理的一致性
pred_logic = parse_logical_structure(pred)
label_logic = parse_logical_structure(label)
consistency_score = compare_logical_structures(pred_logic, label_logic)
return consistency_score, 1.0
图像 - 文本断言:
def image_text_assertion(pred_text, image_path, expected_description, args):
"""
图像-文本多模态断言
评估模型对图像的文本描述是否准确
"""
# 1. 图像特征提取
image_features = extract_image_features(image_path)
# 2. 文本特征提取
text_features = extract_text_features(pred_text)
# 3. 多模态匹配评分
multimodal_score = calculate_multimodal_similarity(
image_features,
text_features,
expected_description
)
# 4. 传统文本匹配评分
text_score = calculate_text_similarity(pred_text, expected_description)
# 5. 综合评分
final_score = 0.6 * multimodal_score + 0.4 * text_score
return final_score, 1.0
自适应阈值断言:
class AdaptiveThresholdAssertion:
"""
自适应阈值断言类
"""
def __init__(self):
self.performance_history = []
self.threshold_history = []
def adaptive_threshold_eval(self, pred, label, question_type, args):
"""
自适应阈值评分
"""
# 1. 计算基础相似度
base_similarity = calculate_similarity(pred, label)
# 2. 根据历史表现调整阈值
current_threshold = self.calculate_adaptive_threshold(question_type)
# 3. 应用阈值进行断言
if base_similarity >= current_threshold:
score = base_similarity
else:
score = 0
# 4. 更新历史记录
self.update_performance_history(base_similarity, score > 0)
return score, 1.0
def calculate_adaptive_threshold(self, question_type):
"""
计算自适应阈值
"""
if len(self.performance_history) < 10:
return 0.5 # 默认阈值
# 基于最近的表现调整阈值
recent_performance = self.performance_history[-10:]
avg_performance = sum(recent_performance) / len(recent_performance)
# 如果表现好,提高阈值;如果表现差,降低阈值
if avg_performance > 0.8:
return min(0.9, self.threshold_history[-1] + 0.05)
elif avg_performance < 0.5:
return max(0.3, self.threshold_history[-1] - 0.05)
else:
return self.threshold_history[-1] if self.threshold_history else 0.5
集成第三方评价库:
def integrated_evaluation(pred, label, question_type, args):
"""
集成多种外部评价工具的断言函数
"""
scores = {}
# 1. BLEU评分
if question_type in ["解答", "翻译"]:
from nltk.translate.bleu_score import sentence_bleu
bleu_score = sentence_bleu([label.split()], pred.split())
scores['bleu'] = bleu_score
# 2. ROUGE评分
if question_type in ["解答", "摘要"]:
from rouge import Rouge
rouge = Rouge()
rouge_scores = rouge.get_scores(pred, label, avg=True)
scores['rouge'] = rouge_scores['rouge-l']['f']
# 3. BERTScore评分
if question_type in ["解答", "改写"]:
from bert_score import score
P, R, F1 = score([pred], [label], lang='zh', verbose=False)
scores['bert_score'] = F1.item()
# 4. 综合评分
if scores:
final_score = sum(scores.values()) / len(scores)
else:
# 回退到基础评分
final_score = basic_similarity(pred, label)
return final_score, 1.0
(四)坑
1 运行结果是无法自己评测
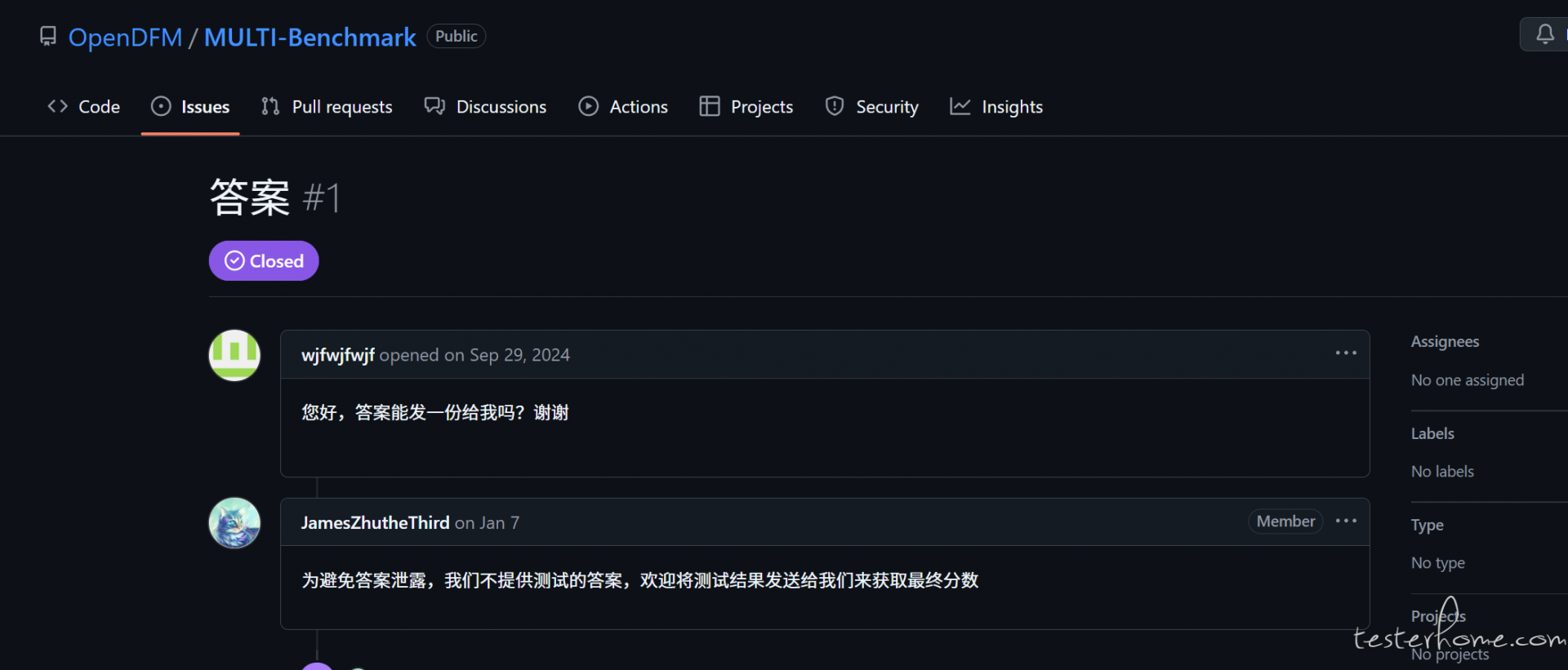
2 MULTI-Benchmark 框架使用了多种数学方法,主要包括:
基础数学:算术运算、布尔逻辑
统计学:描述性统计、频率分析
文本分析:ROUGE 算法、F1 分数、n-gram 分析
数据可视化:坐标系、矩阵运算、颜色映射
集合论:交集、并集操作
概率论:随机化、概率计算
线性代数:矩阵操作
这一行学历要求研究生不是没原因的
(五) 我整理了些资料准备发给老领导,让老领导批改指导下,

领导看后,说我的座位有点低,对颈椎和腰不太好
高度上是时候该往上提一提了

