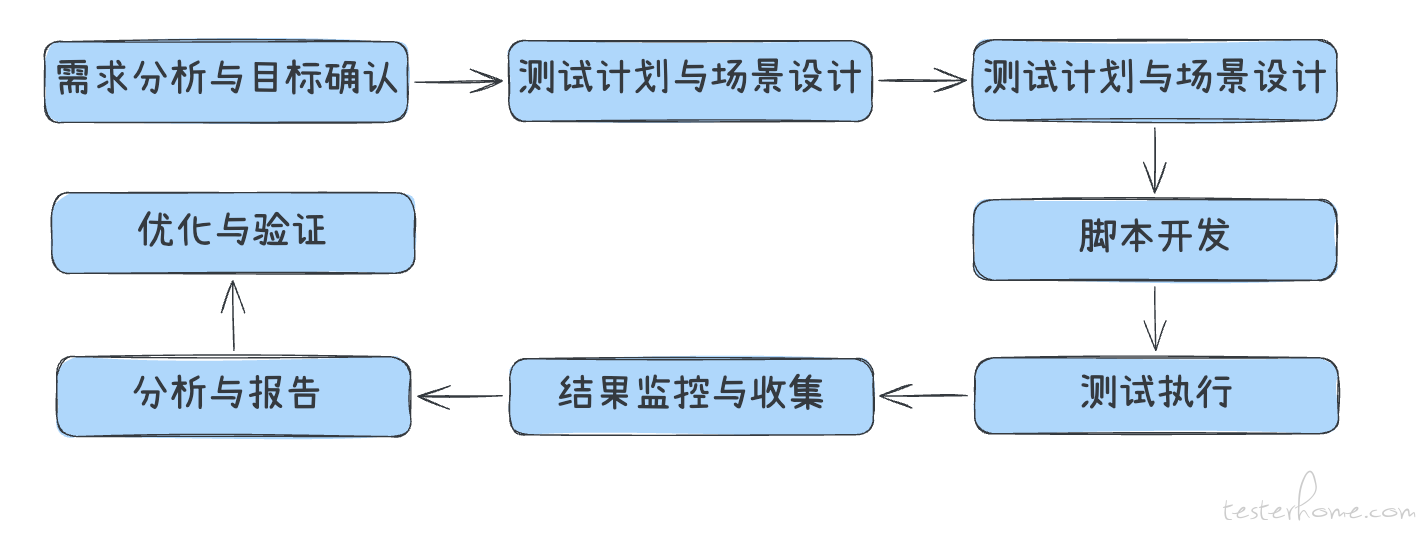
性能测试的目的不是要跑压测工具,而是想通过相应的手段识别系统的瓶颈,保障系统在目标场景下的稳定性和相应能力。如果没有明确的性能目标,测试结果将没有意义,优化方向也会迷失。
常见误区包括:
性能测试的需求并不是测试或者研发拍脑袋决定的,通常来源于以下几个方面:
| 来源 | 内容 |
|---|---|
| 业务需求文档 | 日活量、访问高峰期预测、使用人群 |
| 历史数据 | 上一版本的 TPS/QPS、慢查询数据 |
| 运维指标 | CPU、内存、磁盘、带宽的报警阈值 |
| 架构设计文档 | 分布式部署、限流策略、缓存设计 |
| SLA/SLO 要求 | 如:99% 接口响应时间<200ms, 99.9% 的可用性等 |
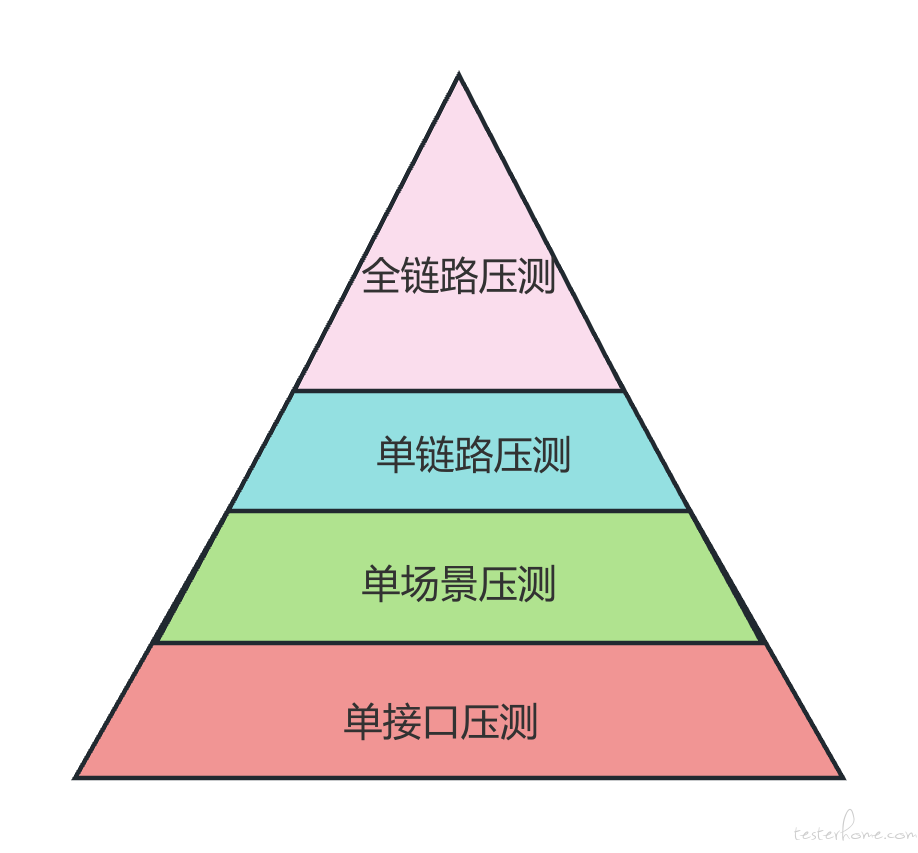
性能问题的暴露往往是一个逐层放大的过程:接口没有问题,链路之间可能有问题;链路没问题,全链路的资源争抢、瓶颈、依赖就可能暴露问题。
因此我们需要从最小颗粒度的接口开始,逐层抽象到整个业务系统,最终设计出覆盖全面、风险可控、逐层定位的性能测试场景。
目的:验证单个接口在不同负载下的性能极限和稳定性
应用场景:
设计要素:
目的:验证某一完整业务流程在负载下的性能表现
链路定义:多个接口组成一个完整用户动作路径(前后端协作逻辑链)
应用场景:
设计要素:
目的:模拟系统在真实运行中多个业务并发执行的场景
应用场景:
设计要素:
目的:模拟生产环境真实高负载下系统全景运行状态,验证系统承压能力、瓶颈位置、异常恢复能力
应用场景:
设计要素:
典型示例:
关键关注点:
环境准备的原则:
| 环境类型 | 特点 | 适用场景 |
|---|---|---|
| 生产环境压测(影子压测) | 数据最真实,但风险高 | 核心系统灰度验证 |
| 准生产环境(beta) | 与生产相似,推荐首选 | 上线前性能验证 |
| 独立压测环境 | 资源可控,安全性高 | 新功能验证、接口 |
性能测试的数据准备,不是随便造几条数据,而是要覆盖真实业务场景 + 满足测试维度多样性 + 可重复使用。
1. 数据维度设计
| 维度 | 说明 | 示例 |
|---|---|---|
| 用户数据 | 有效用户量、登录态 | 生成 x 万用户 |
| 群聊/私聊结构 | 群成员分布、群数量 | x 人大群,x 人小群 |
| ... | 内容敏感 | ... |
2. 数据构造方法
脚本开发是连接 “性能测试需求分析” 与 “压测执行” 的桥梁环节。无论是单接口压测,还是复杂的多链路全链路压测,脚本都是整个过程的执行载体。
| 输入项 | 说明 |
|---|---|
| 接口定义 | 接口 URL、请求方式、Headers、参数结构等 |
| 用例场景 | 关键接口链路、参数组合、依赖顺序 |
| 数据依赖 | 例如接口依赖登录的 token |
| 响应断言 | 是否成功(status code、字段内容等) |
| TPS 目标 | 用于设计线程数、请求频率的依据 |
单接口:
单链路脚本开发:
多链路/业务流程脚本开发:
根据预设场景和目标,稳定、可控地施加压力,并采集关键性能指标,辅助问题定位与性能评估。
| 项目 | 说明 |
|---|---|
| 压测环境准备 | 环境隔离,配置一致,监控联通 |
| 数据初始化 | 测试数据准备好,并且数据状态正常 |
| 服务监控接入 | Prometheus/Grafana/APM 工具等 |
| 日志、链路追踪打开 | 包括 Nginx、应用服务、数据库慢查询 |
| 观察指标定义 | RT、TPS、错误率、CPU、内存、GC 等 |
| 脚本冒烟 | 小流量压测验证逻辑正确性 |
| 依赖方沟通 | 告知被测系统负责人,避免误报警 |
1. 常见压测流量模型
| 模型 | 说明 | 示例 |
|---|---|---|
| 恒定并发 | 模拟固定用户数持续操作 | 50 并发持续 10 分钟 |
| 阶梯增长 | 模拟高峰来临过程 | 每 5 分钟增加 10 并发 |
| 峰值冲击 | 快速打满系统能力 | 高并发短时间强打压 |
| 混合场景 | 多接口/多链路同时发压 | 收发消息,打开文件并行 |
| 波浪式 | 模拟系统高峰低谷流量模式 | 凌晨压测流量 1 倍,工 10 倍 |
2. 发压策略建议
压测过程的核心是采数据、看变化。以下的数据只是一小部分的维度,实际上的问题排查可能会涉及更多性能数据的分析与评估对比。
| 维度 | 指标 | 工具 |
|---|---|---|
| 应用层 | RT、TPS、错误率、接口 P95/P99 | JMeter、Locust |
| 系统层 | CPU、内存、GC、负载、磁盘 IO、网络 IO | Prometheus、Grafana |
| 数据库 | 连接数、慢查询、QPS、锁等待、缓存命中率 | MySQL Dashboard |
| 中间件 | Kafka TPS、Redis QPS、MQ 消息堆积 | 业务自研平台 |
| 链路追踪 | 某一请求经过的服务链路耗时分布 | SkyWalking、Jaeger |
| 问题类型 | 特征 | 定位手段 |
|---|---|---|
| 接口超时 | RT 飙高,JMeter 报超时 | 链路追踪 + 服务日志 |
| 错误率升高 | TPS 下跌,5xx、4xx 增多 | 日志分析 + 接口返回码 |
| CPU 撑满 | TPS 持平但延迟高 | top/Grafana 观测线程 |
| GC 卡顿 | RT 波动大,GC 次数/耗时高 | jstat/GC 日志分析 |
| 数据库瓶颈 | 连接数满、锁等待、慢 SQL | explain+slowlog 分析 |
| 缓存穿透/雪崩 | Redis 请求激增,DB 被打爆 | Redis 监控/fallback |
在这里的核心目标是:
1. 汇总并分析压测期间的关键性能指标
2. 发现性能瓶颈,定位异常
3. 评估系统是否满足业务性能目标
4. 为优化和容量规划提供决策依据
5. 对外形成结构清晰、结论明确的性能测试报告
1. 压测数据指标
| 指标 | 说明 | 分析关注点 |
|---|---|---|
| TPS/QPS | 每秒处理请求数 | 是否达到预期目标 |
| 响应时间(RT) | 平均、P90、P95、P99 | 是否符合 SLA 要求 |
| 成功率 | 有效响应数/总请求数 | 是否出现错误 |
| 错误率 | 5xx/超时/断言失败等 | 哪些类型最多?集中在哪? |
| 并发数 | 实际活跃线程数 | 压力是否真实落到系统 |
2. 系统服务资源
| 指标 | 说明 | 分析关注点 |
|---|---|---|
| 系统资源 | CPU、内存、IO、网络流量、连接数等 | 有无资源瓶颈 |
3. 中间件核心性能指标
Redis(缓存)
| 指标 | 说明 |
|---|---|
| instantaneous_ops_per_sec | 每秒命令执行数(类似 QPS) |
| keyspace_hits/misses | 命中率,命中低代表缓存不生效 |
| latency | 响应时间,高峰期时尤为重要 |
| used_memory_rss, used_memory_peak | 实际占用内存,是否接近上限 |
| connected_clients | 当前连接数,是否稳定,是否打满 |
| evicted_keys, expired_keys | 是否频繁淘汰,是否存在热点键被清除问题 |
MySQL(数据库)
| 类别 | 指标 |
|---|---|
| 性能 | Queries, QPS, Slow_queries |
| 性能 | Threads_running |
| 资源 | CPU, Buffer pool usage, IO wait |
| 连接 | Threads_connected, Max_used_connections |
| 异常 | InnoDB row lock wait, Deadlocks |
“优化与验证”是承上启下的关键模块,目标是根据压测分析结果,驱动系统调优并验证优化是否有效,确保最终上线版本性能稳定、可支撑预期业务量。
以后再细聊吧
性能测试的成败,很大程度上取决于场景设计的科学性与贴合实际业务的能力。设计合理的场景不仅能发现真实瓶颈,还能评估系统是否具备承接未来增长的能力。
常见识别方式:
示例:IM 系统
负载模型决定了压测目标和策略。应根据业务发展阶段、测试目的不同,匹配不同类型的压测模型。
目的:模拟真实业务压力下的系统表现
目的:突破系统瓶颈上限,发现故障点
目的:验证系统在长时间运行下的稳定性
运行 8h~72h 不等,重点关注内存泄漏、连接泄漏、数据积压,其实我们跑的是 7*24 小时。
目的:验证系统对并发突发请求的处理能力
一般用于秒杀、拼团等突发流量场景
要求场景中包含随机性、冲突性(如同一个商品库存扣减)
