作者简介:春亚敏,来自货拉拉/技术中心/质量保障部,资深测试工程师,主要负责地图服务端测试及相关质效能力建设
货拉拉作为领先的同城货运平台,致力于提供高效便捷的运输服务。装卸货推荐点是为了缩短履约过程中的装/卸货时间、帮助货主和司机降低沟通成本,所推出的一个基于大数据和 LBS 的功能。装卸货推荐点的质量直接影响车货碰面效率,是提升用户体验和优化运营效率的关键环节。然而装卸货推荐点的准确性、及时性以及合理性,在质量保障上却面临以下三大难题:
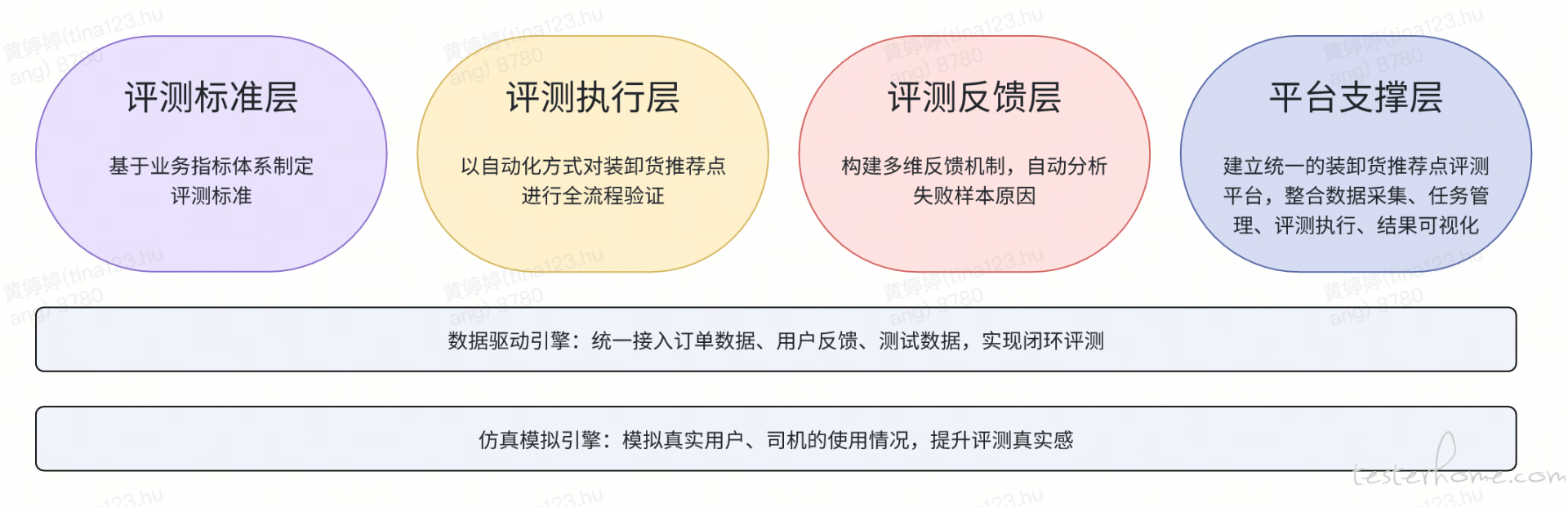
针对装卸货推荐点面临的质量难题,我们深入调研了业内常见的测试方案以及碰面产品的诉求,并结合货拉拉现状,给出了装卸货推荐点的效果评测解决框架及目标:
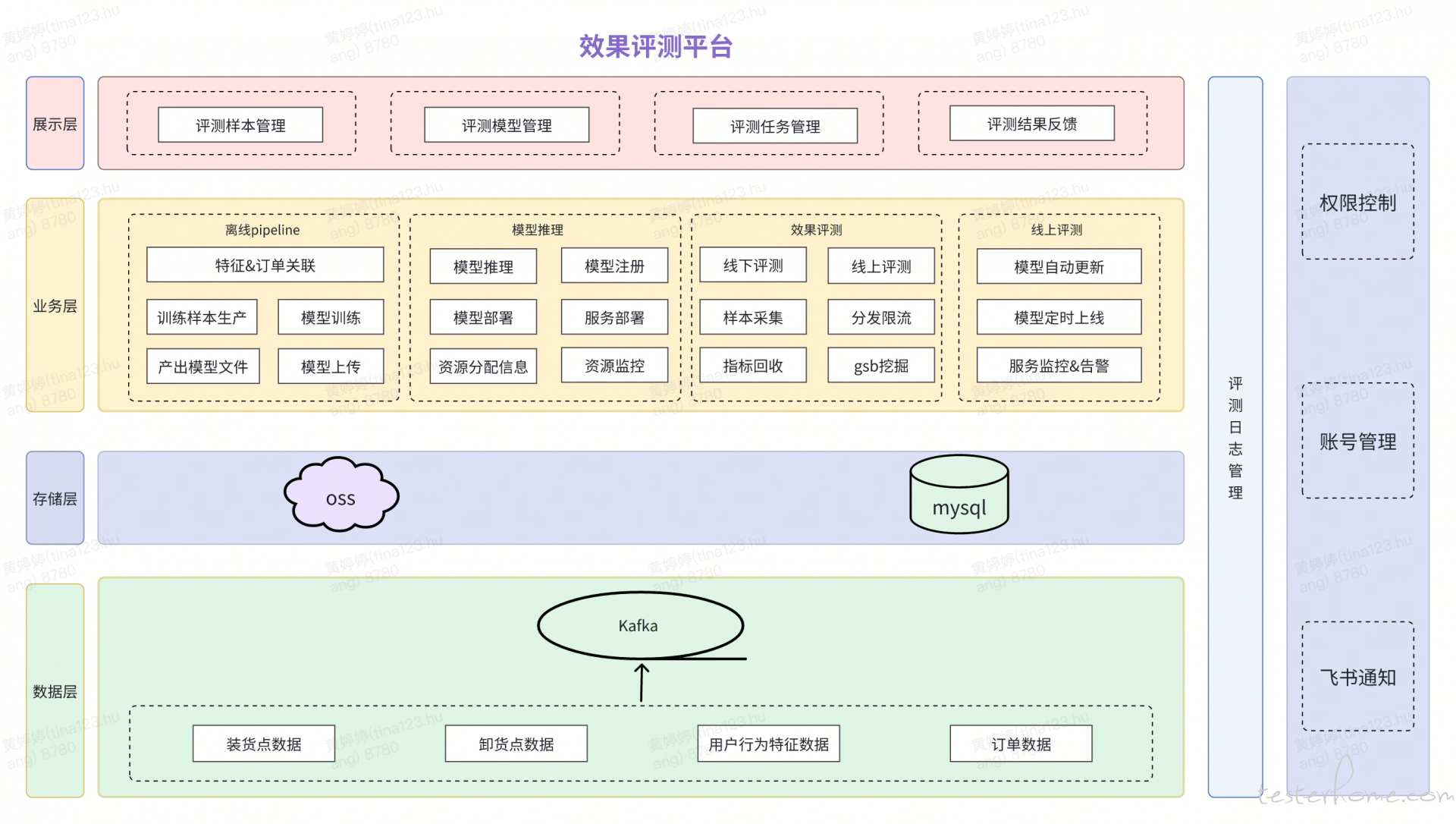
效果评测平台架构由展示层、业务层、存储层和数据层组成。这些模块协同工作,支持装卸货推荐点场景模型自动更新能力。
算法测试相比其他服务端测试的难点:
依赖算法侧自动生成模型的平台,搭建一套完整的在线评测平台,支持模型自动更新。
接下来我们将按照评测指标、样本选取、评测方法、结果分析、反馈预警五个部分进行详细介绍。
传统指标盲区:最初的算法迭代仅关注准确率、精准率、召回率指标,这样很容易掉进 “指标陷阱”!
业务指标设计:本次评测指标体系的设计由产品团队牵头,聚焦于 “用户体验、业务收益、系统性能” 三大核心维度,通过 “两步法” 构建了覆盖重点业务场景的指标体系。
在无推荐点、宽泛/低热区域、推荐过远等推荐效果较差的场景,需提升用户关注度,并转化为有效修改,提升碰面效率。针对典型场景,应适当加强策略与前端引导的联动,减少下单成本。同时监测技术指标和业务指标偏移、验证业务影响,选取合适的业务指标反向驱动产品创新,以达到最优解。
业务衡量指标:可反应真实用户体验的评测指标,指标即体验!
private LalamapMetric calcMetric(List<LalamapCompareResult> compareResults) {
LalamapMetric lalamapMetric = new LalamapMetric();
lalamapMetric.addTotal(compareResults.size());
for (LalamapCompareResult compareResult : compareResults) {
metric(compareResult, lalamapMetric);
}
return lalamapMetric;
}
补充说明:测试团队在此过程中主要负责评测指标在平台侧的落地与实现工作,包括数据采集、指标计算、偏移监控及可视化支持,确保业务视角下的指标体系能够有效转化为评测平台中的可执行能力。
模型效果验证依赖于准确的评测指标计算,而指标本身又高度依赖于客户端的埋点数据(如用户点击行为、下单数据等)。因此,样本选取的合理性直接决定评测结果的代表性与可信度。具体样本选取需满足以下三项原则:
为保障大规模评测效率,采用分布式评测框架设计:
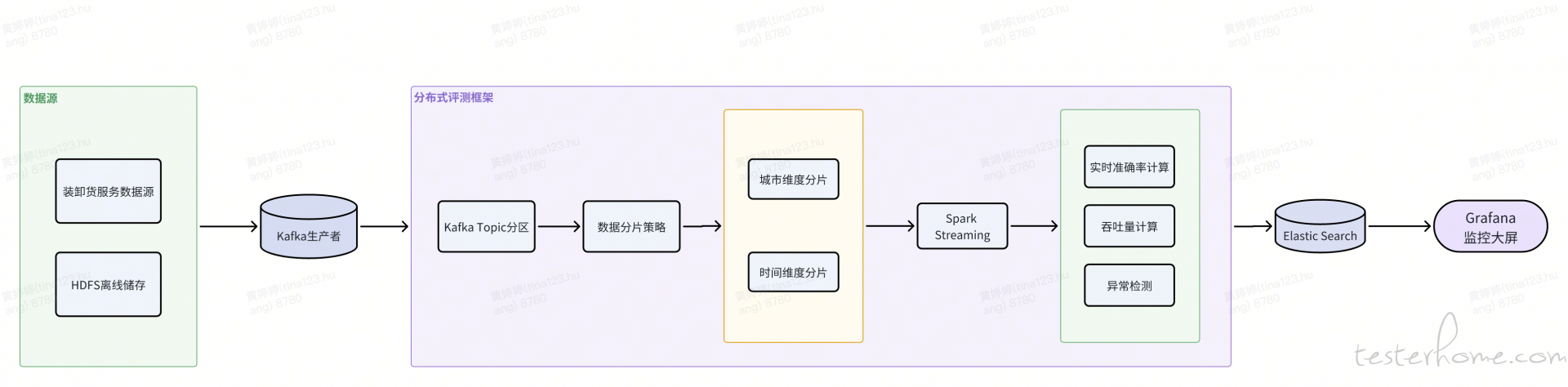
实施该架构后,单次处理能力从 2 万样本提升至百万样本,P99 延迟控制在 300ms 内,且成功缩小了评测指标和线上数据的差距,由原来的 0.38pp 降至 0.12pp。
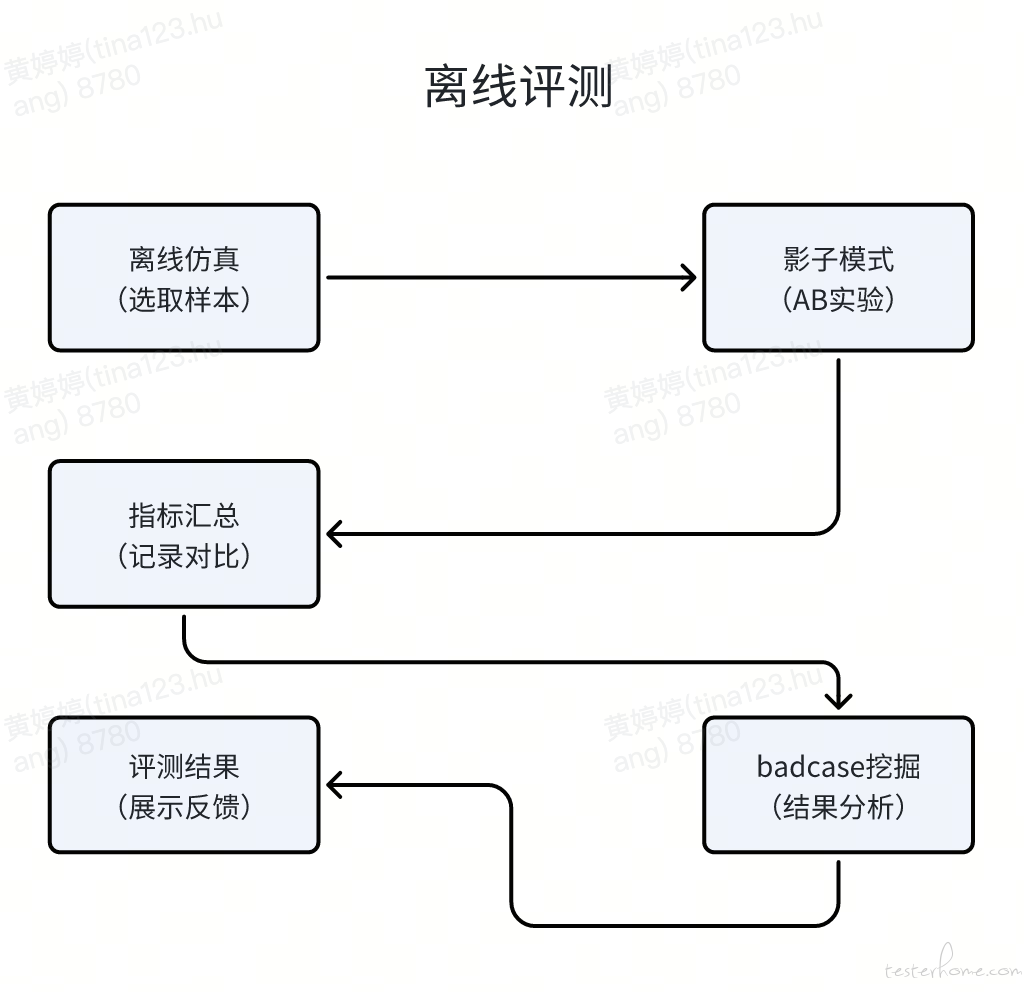
离线效果评测阶段,采用 “二阶段验证法”
如下图所示,人工评测支持自定义选取不同类型的回放数据,用于离线仿真

人工评测的模式强依赖测试人员经验积累,门槛高,且每次只能评测单个用户的推荐效果,效率较低、用户覆盖面有限,因此需要寻求低门槛、更高效、高覆盖的模型线下效果验证能力。通过平台选择批量的用户生成批量的测试结果,自动计算模型评测指标,自动筛选出 badcase,最后再人工确认高风险结果,通过这样的方式提高测试用户覆盖,提高测试效率。
时机:每当上线调整模型、策略,新老数据替换时我们都需要对模型、策略、数据进行一个效果的评测。
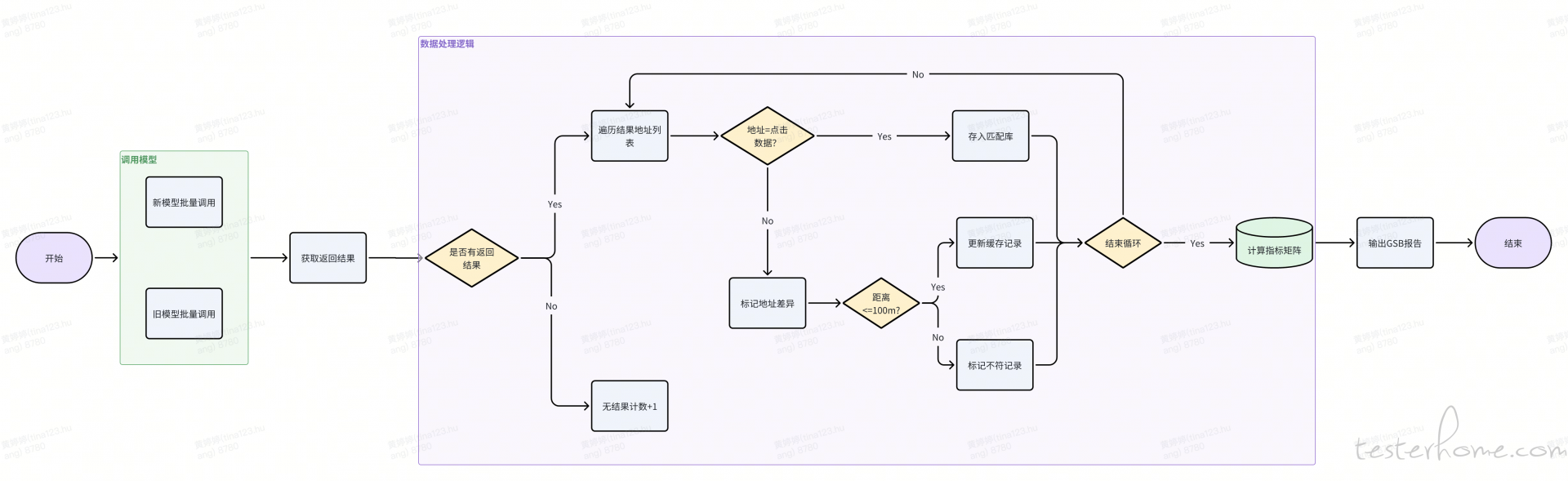
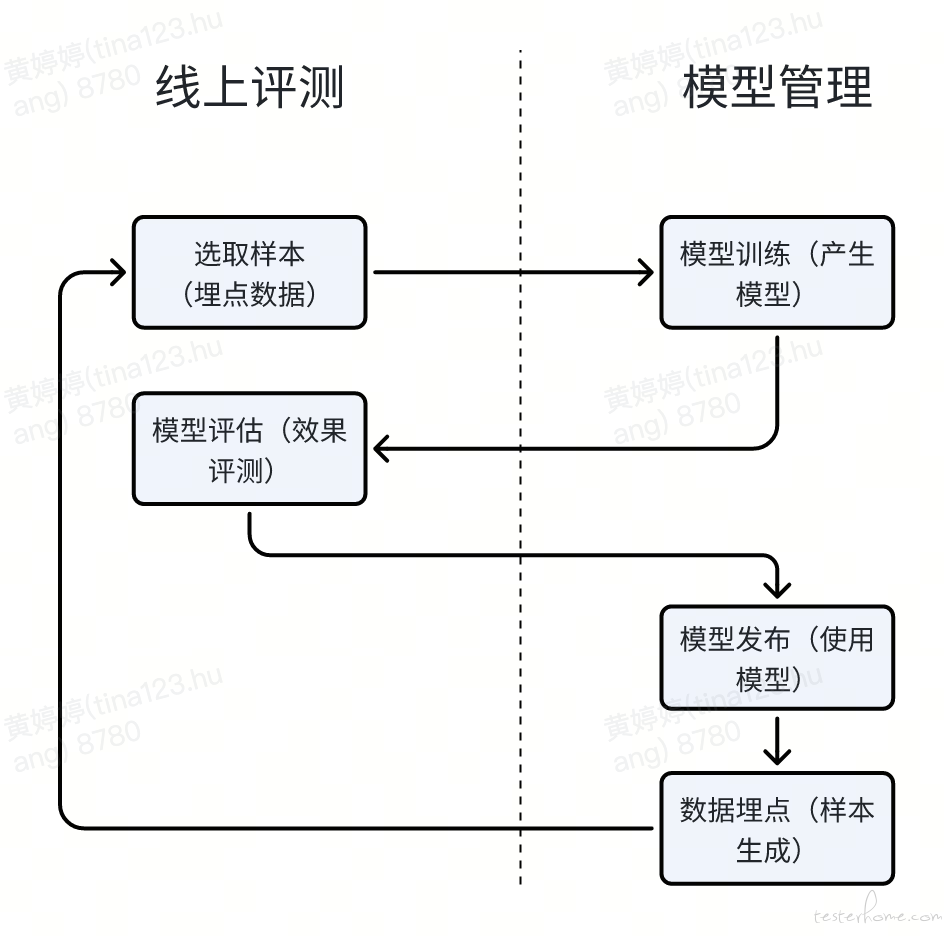
线上效果评测阶段,采用 AB 测试验证法
随着业务体量增长与用户行为变化,模型效果出现退化趋势,对模型进行天级微调以适应最新数据分布的诉求越来越强烈。当前系统已支持新模型的天级自动生成,并在上线前通过自动化质检对新旧模型并进行指标比对,确保效果不回退再执行更新替换,从而保障线上服务效果的稳定性。
public ApiReModule lalamapsuggest(LalamapsuggestDto lalamapsuggestDto) {
final ApiReModule result = new ApiReModule();
final StopWatch stopWatch = new StopWatch();
// 数据准备
final QueryWrapper<OrderRecpointsLog> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("dt", lalamapsuggestDto.getDt());
if (!"all".equalsIgnoreCase(lalamapsuggestDto.getAddrType())) {
queryWrapper.eq("addr_type", lalamapsuggestDto.getAddrType());
}
int total = Math.max(lalamapsuggestDto.getNum(), lalamapsuggestDto.getMaxLine());
int pageSize = Math.min(100, total);
stopWatch.stop();
DataLogRecordDispatch<OrderRecpointsLog> recordDispatch = new DataLogRecordDispatch<>(pageSize, total, queryWrapper, (w, i, s) -> {
Page<OrderRecpointsLog> page = new Page<>(i, s);
return recPointsLogMapper.selectPage(page, w);
});
RemoteServerWrapper remoteServer = new RemoteServerWrapper("map-lalamap-svc", lalamapsuggestDto.getEnv());
RateLimiter rateLimiter = RateLimiter.create(getLimit(lalamapsuggestDto.getEnv()));
List<LalamapCompareRecord> lalaCompareResult = new ArrayList<>(lalamapsuggestDto.getNum());
List<ScheduledFuture<Void>> secondDelay = new ArrayList<>(lalamapsuggestDto.getNum());
while (!recordDispatch.isDone()) {
List<OrderRecpointsLog> records = recordDispatch.records();
List<LalamapCompareRecord> recods = new ArrayList<>(records.size());
for (OrderRecpointsLog record : records) {
if (StringUtils.isEmpty(record.getAnchorLat())) {
continue;
}
LalamapCompareRecord compareRecord = new LalamapCompareRecord();
compareRecord.setOriginRecord(record);
recods.add(compareRecord);
}
lalaCompareResult.addAll(recods);
// 第一次请求
List<CompletableFuture<Void>> firstCollector = new ArrayList<>(recods.size());
for (LalamapCompareRecord recod : recods) {
String host = remoteServer.nextHost();
firstCollector.add(CompletableFuture.runAsync(() -> sendReq(host, recod, lalamapsuggestDto.getControlAbParam(), 0, lalamapsuggestDto.getTriggerId(), rateLimiter, lalamapsuggestDto.getHeader()), REQ_POOL));
}
CompletableFuture[] firstArray = firstCollector.toArray(new CompletableFuture[recods.size()]);
for (LalamapCompareRecord recod : recods) {
// 第二次请求
String host = remoteServer.nextHost();
ScheduledFuture<Void> schedule = REQ_DELAY_POOL.schedule(() -> scheduleSendReq(host, recod, lalamapsuggestDto.getTestAbParam(), 1, lalamapsuggestDto.getTriggerId(), rateLimiter, lalamapsuggestDto.getHeader()), 61L, TimeUnit.SECONDS);
secondDelay.add(schedule);
}
}
}
评测执行后的关键代码如下:
{
List<LalamapCompareResult> compareResults = fireCompare(lalaCompareResult);
LalamapMetric metric = calcMetric(compareResults);
stopWatch.stop();
//获取质检是否通过结果
String prdRes = getPrdRes(metric, diffAbsolute, checkNonZeroDiff, prdDiffThreshold);
String fileUrl = "";
if (lalamapsuggestDto.getNum() <= this.writeLimit) {
String filePath = toExcel(compareResults);
fileUrl = upload(filePath);
}
String sum = recordCompareResult(lalamapsuggestDto, metric, fileUrl, prdRes);
// 发送飞书群通知
sendLark(metric, fileUrl, lalamapsuggestDto.getOptPerson(), feishuUrl, lalamapsuggestDto.getAddrType(), lalamapsuggestDto.getModelKey());
callBack(metric, diffAbsolute, callBackUrl, lalamapsuggestDto.getServiceAppId(), lalamapsuggestDto.getModelKey(), lalamapsuggestDto.getEnv(), checkNonZeroDiff, prdDiffThreshold, lalamapsuggestDto.getModelVersion());
return result;
在 badcase 分析维度,传统方法依赖人工抽样检测效率低下,通过使用规则引擎层,基于业务经验定义硬性违规规则(如推荐点超出服务范围),构建智能化的 badcase 挖掘系统。
badcase 挖掘依据:
private LalamapMetric calcMetric(List<LalamapCompareResult> compareResults) {
LalamapMetric lalamapMetric = new LalamapMetric();
lalamapMetric.addTotal(compareResults.size());
for (LalamapCompareResult compareResult : compareResults) {
metric(compareResult, lalamapMetric);
}
return lalamapMetric;
}
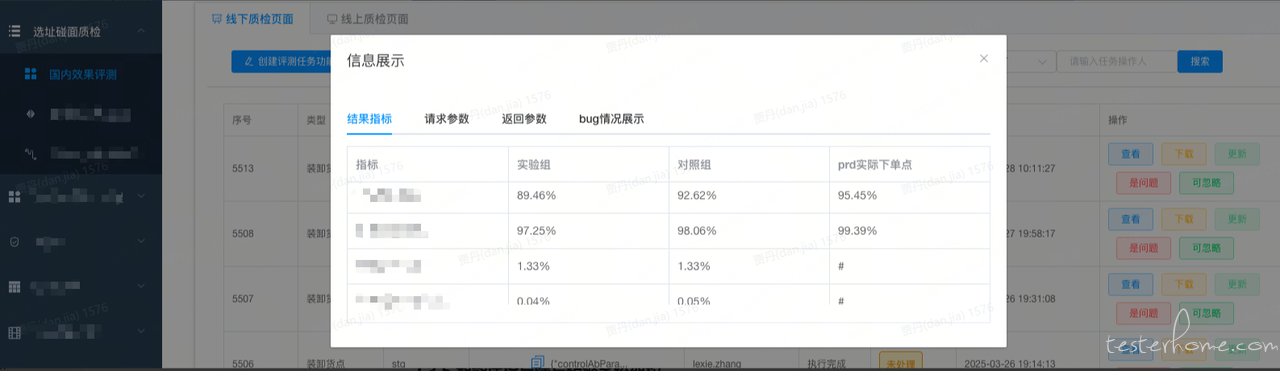
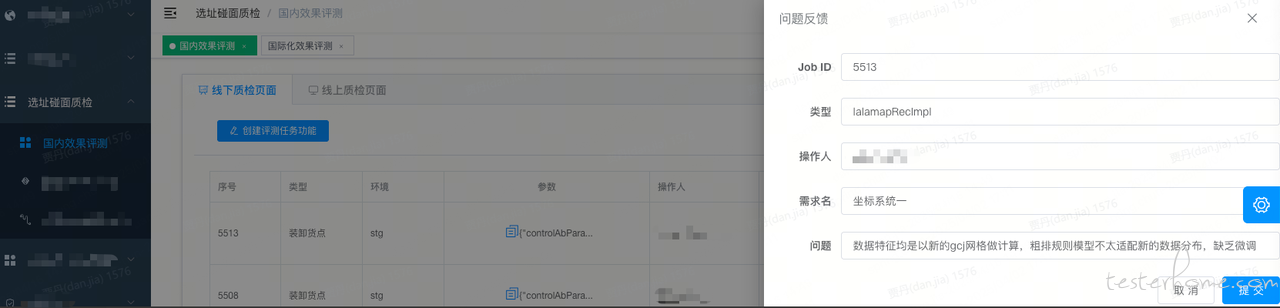


赋能研发自测,提升提测质量,拉高用户满意度;badcase 挖掘提前暴露存在问题,为后续需求迭代指明提升方向 。
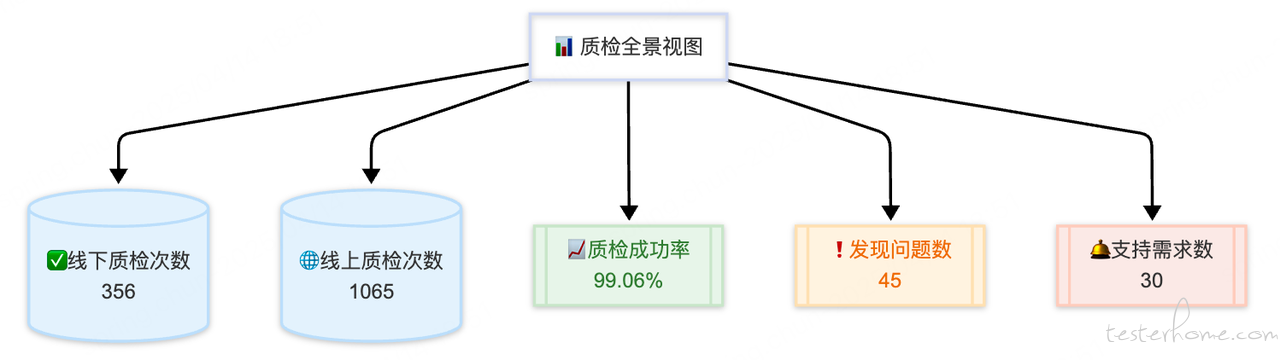
上述业务收益来自产品、研发与测试团队的协同推动。其中,测试团队搭建的装卸货推荐点评测平台在效果验证中发挥了较好的推动作用,是此次收益实现的重要组成力量。
目前,效果评测平台已具备高度自动化、工具化、服务化与可视化等能力,初步形成了装卸货推荐点评测的系统化支撑平台。面向未来,我们希望进一步延伸平台能力,构建覆盖 “模型训练—模型评估—模型预测—模型应用” 的全流程质量保障闭环,持续提升装卸货推荐点的智能化水平。
具体规划包括以下三个方向:
