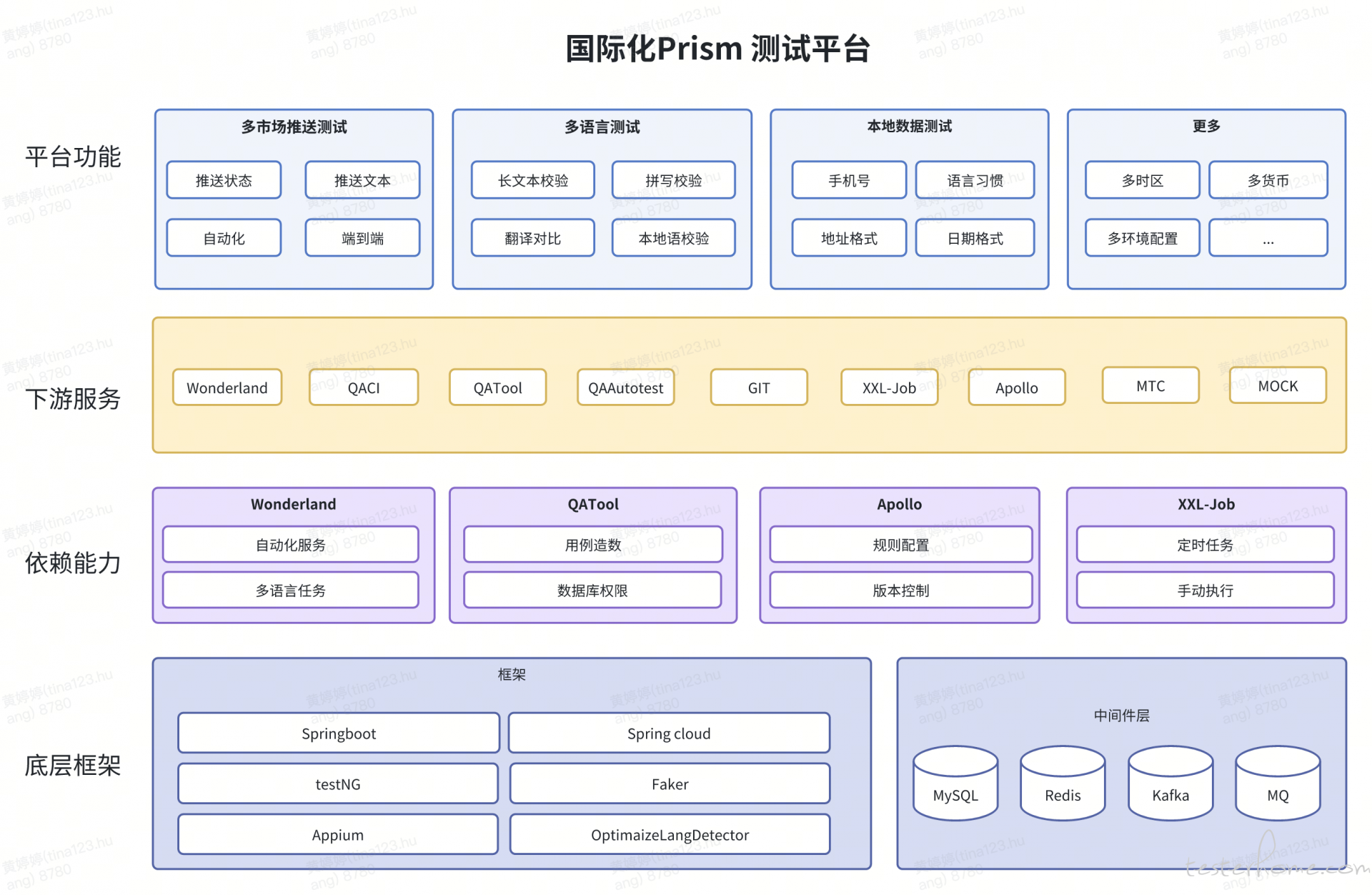
综合考虑现有的测试技术框架和基础能力,我们搭建了 Prism 棱镜测试平台,该平台具备简洁、统一的前端操作页面,提供本地化数据测试、多市场推送测试和多语言翻译测试,以及进行中的多时区功能自动化验收,未来将致力于将其打造成为国际化综合的本地化测试平台。
作者简介:
- 詹柏林,来自货拉拉/技术中心/质量保障部/国际化,资深测试工程师,负责移动端测试工作
- 余晓艳,来自货拉拉/技术中心/质量保障部/国际化,资深测试工程师,负责中台测试工作
- 雷铭峻,来自 Lalamove/Tech/QA Team,高级测试工程师,负责用户端测试工作
在全球化的商业环境中,企业越来越重视产品的本地化适配,确保其产品满足不同地区用户的需求和使用习惯。产品的本地化不仅涉及语言和文化的多样性,还需考虑技术平台的兼容性、法律法规的合规性、用户的偏好习惯、时区、币种管理以及内容的频繁迭代变更等等。作为产品质量保障的测试工程师,如何通过层层的验证测试,给客户提供最卓越的用户体验,我们在执行本地化测试过程中面临着一系列的挑战:
如何减轻测试人员一遍遍的回归负担,提高测试效率变得愈发重要。除了常规的前后端功能自动化测试外,面对本地化测试的诸多痛点,让我们更加坚定了深入剖析并解决问题的决心。
综合考虑现有的测试技术框架和基础能力,我们搭建了 Prism 棱镜测试平台,该平台具备简洁、统一的前端操作页面,提供本地化数据测试、多市场推送测试和多语言翻译测试,以及进行中的多时区功能自动化验收,未来将致力于将其打造成为国际化综合的本地化测试平台。
接下来,我们将逐一介绍本地化测试探索过程中落地的几个工具。
随着 Lalamove 全球化进程的加速,数据文本类的测试也变得越来越多样化,无论是传统的 UI 自动化还是接口自动化测试,在发现未知数据缺陷方面的成本都变得越来越高。如何高效、准确地验证多市场数据的兼容问题成为了一个亟待解决的难题。本节展开介绍一种落地的造数技术方案,借助公司 MTC UI 自动化和 QACI 接口自动化能力,自动检测潜在的多市场数据兼容性缺陷,为自动化测试注入新的活力。
根据产品的功能模块和业务流程,来进一步确定我们需要测试的语言种类和文本类型。首先针对我们现有的海外市场,设计构造出不同语言的文本数据,如英语、繁体中文、泰文、越南文等。同时,我们还要考虑不同风格的文本表达,这些测试数据将用于验证 APP 在不同语言环境下的文本处理能力和用户体验,从而发现潜在的数据处理错误和边界条件问题。
我们选用了目前市面上主流的多语言测试数据工具库 Faker。近期,LOL 英雄联盟著名中单选手 Faker 在 S14 全球总决赛再次带领 SKT 拿到队史第五座总冠军,堪称电竞界的传奇,而作为同名的 Faker 库在 IT 界也同样能力出众。这个工具库可以为我们提供丰富的语言资源和语法规则,帮助我们生成符合要求的测试数据。我们还发现 Faker 库支持全球大部分主流国家地区和语言,且有当地语言风格的字段设计,如街道名,邮编号码等。

除了有丰富的语言资源外,Faker 还有随机生成测试数据的能力,使得我们每次跑自动化流水线的时候,验证的数据场景都是不一样的,保证了测试的多样性,能探索更多潜在缺陷的可能。
在二次开发设计和构造多语言测试数据的过程中,我们首先考虑到了 Lalamove 用户和司机端的基本核心文本输入类型,例如姓、名、全名组合、地址、电子邮箱、电话号码等等。
Faker faker = new Faker(new Locale("zh_TW"));
// 生成随机名字
String firstName = faker.name().firstName();
String lastName = faker.name().lastName();
String fullName = faker.name().fullName();
// 生成随机地址
String streetAddress = faker.address().streetAddress();
String city = faker.address().city();
String state = faker.address().state();
String country = faker.address().country();
String zipCode = faker.address().zipCode();
// 生成随机电子邮件
String email = faker.internet().emailAddress();
其次,我们还考虑到了不同国家的身份证 ID 或护照 ID 的格式不尽相同,对此我们也做了定制化设计。Faker 库对此类字母数字组合提供了三种有用的解决方法分别是 Letterify、Numberify 和 Bothify。首先 Letterify 有助于生成随机的字母序列;而 Numerify 仅生成数字序列;最后,Bothify 是两者的组合,可以创建随机的字母数字序列,可用于模拟 ID 字符串等内容。
FakeValueService 需要有效的 Locale 以及 RandomService:
public void generateIdentifyID {
FakeValuesService fakeValuesService = new FakeValuesService(new Locale("en-GB"), new RandomService());
String identifyID = fakeValuesService.bothify("????####??");
}
在此代码片段中,我们创建一个新的 FakeValueService,其语言环境为 en-GB,并使用 bothify 方法生成唯一的虚假身份证 ID。它的工作原理是将 “?” 替换为随机字母,将 “#” 替换为随机数字。
类似地,regexify 根据所选的正则表达式模式生成随机序列。在这个单元测试代码片段中,我们将使用 FakeValueService 创建一个遵循指定正则表达式的随机序列:
@Test
public void givenValidService_whenRegexifyCalled_checkPattern() throws Exception {
FakeValuesService fakeValuesService = new FakeValuesService(new Locale("en-GB"), new RandomService());
String alphaNumericString = fakeValuesService.regexify("[a-z1-9]{10}");
Matcher alphaNumericMatcher = Pattern.compile("[a-z1-9]{10}").matcher(alphaNumericString);
}
我们的代码创建了一个长度为 10 的小写字母数字字符串,我们的模式根据正则表达式检查生成的字符串。
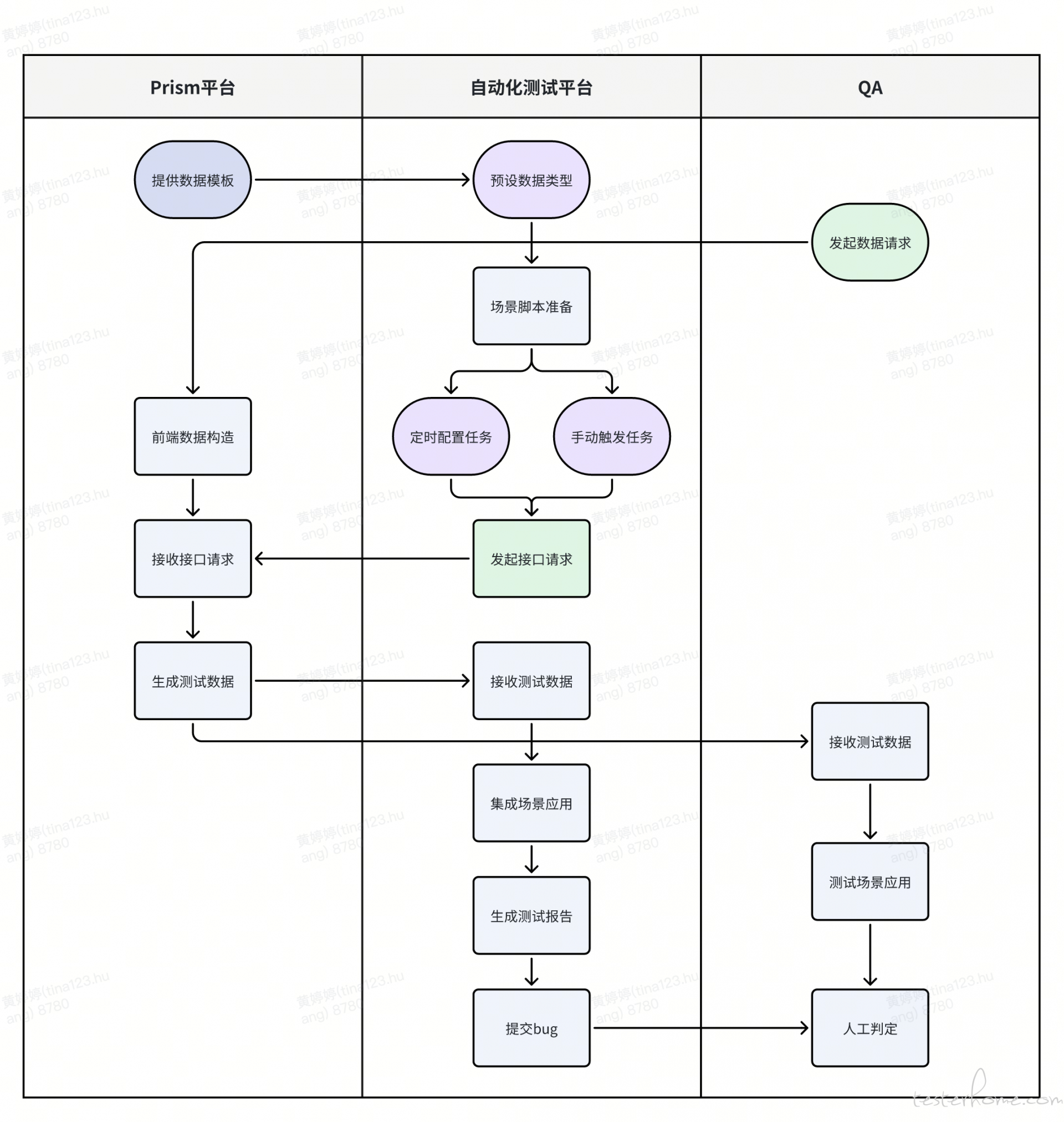
图:数据传输流程图

结果呈现
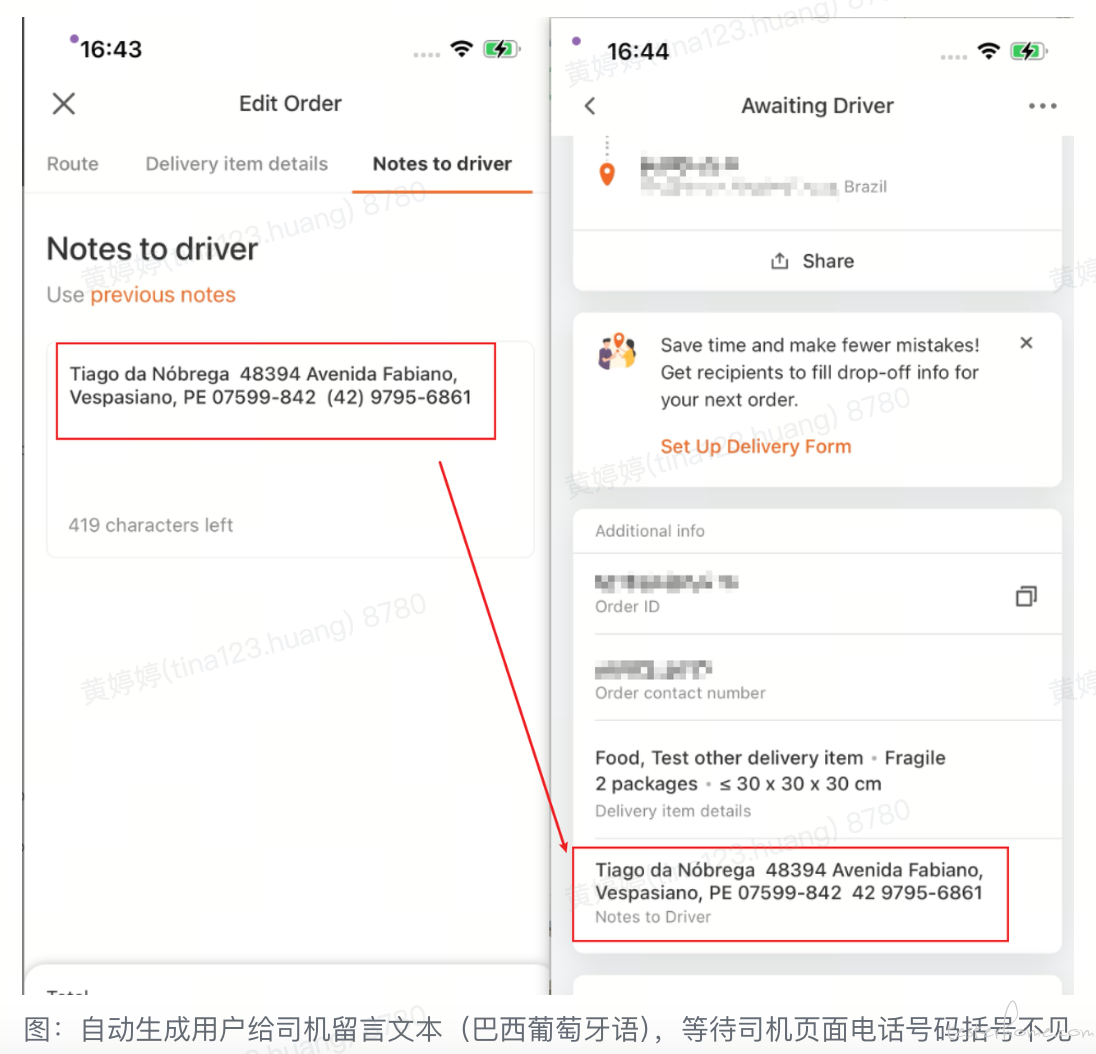

传统的接口自动化测试通常聚焦于特定场景下的接口返回值、数据入库等方面的验证。那么, 对于测试过程中产生的推送消息要如何验证呢?推送消息的发送逻辑涉及多个组件和依赖,通常需要关注消息的生成、发送、接收和处理等环节。为了实现对推送消息的自动化验证,我们首先需要了解推送的发送逻辑及其上下游调用关系。主要包括:
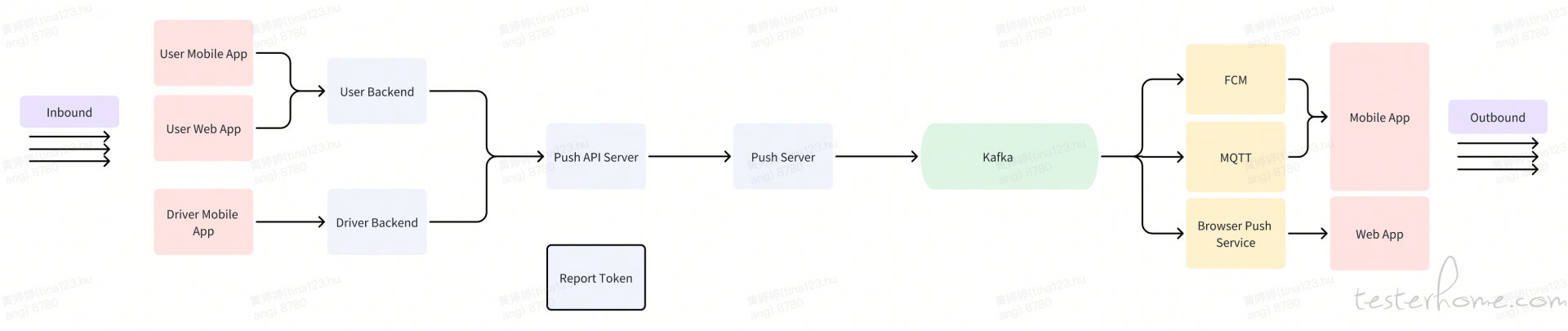
图:Lalamove APP 推送链路 (简化)
如图所示,APP 的推送逻辑由推送中心发起,经过多个下游服务,最终生成 Kafka 消息。根据推送策略,消息分别通过 FCM 或 MQTT 进行推送。需要注意的是,链路中并不涉及数据库写入,因此无法通过读取数据库进行校验;然而,通过消费 Kafka 消息则可以实现。获取推送消息的内容和状态后,我们可以设置不同的校验条件以完成自动验证。接下来,让我们看看平台是如何实现推送的自动化校验的。
平台与自动化交互:
java -jar -Xms512m -Xmx512m -Xmn512m -Xss8m -Dfrom=notification -DcityId=xxxx -DreportId=739 -DdriverAccountInfo='[{"account":"+63xxxxxxxx","password":"000000","account_id":"xxxxx"}]' -Dlanguage=en_ph -DuserAccountInfo='[{"account":"+63xxxxxxx","password":"000000","account_id":"xxxxx"}]' -Denv=pre -Doperator=xxxxx -Dmarket=Philippines -DtaskName="RH Philippines Order Flow" -Did=79 -DuseDefaultAccount=false -DscenarioName=LLM_USER_ORDER_PUSH_RH -Dhcountry=xxxxx -Dstatus=2 -DxmlPath=notificationTool/user/LLM_USER_ORDER_PUSH_RH.xml -Dxml=/home/data/projects/qaautotest_llmove_user/qaautotest/target/classes/cases/notificationTool/user/LLM_USER_ORDER_PUSH_RH.xml /home/data/projects/jars/qaautotest_llmove_user/qaautotest_llmove_user.jar
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = RabbitMQConfig。DIRECT_NOTIFICATION_QUEUE,durable = "true",ignoreDeclarationExceptions = "true"),
exchange = @Exchange(value = RabbitMQConfig。DIRECT_NOTIFICATION_QUEUE + "_exchange"),
ignoreDeclarationExceptions = "true"),concurrency = "10")
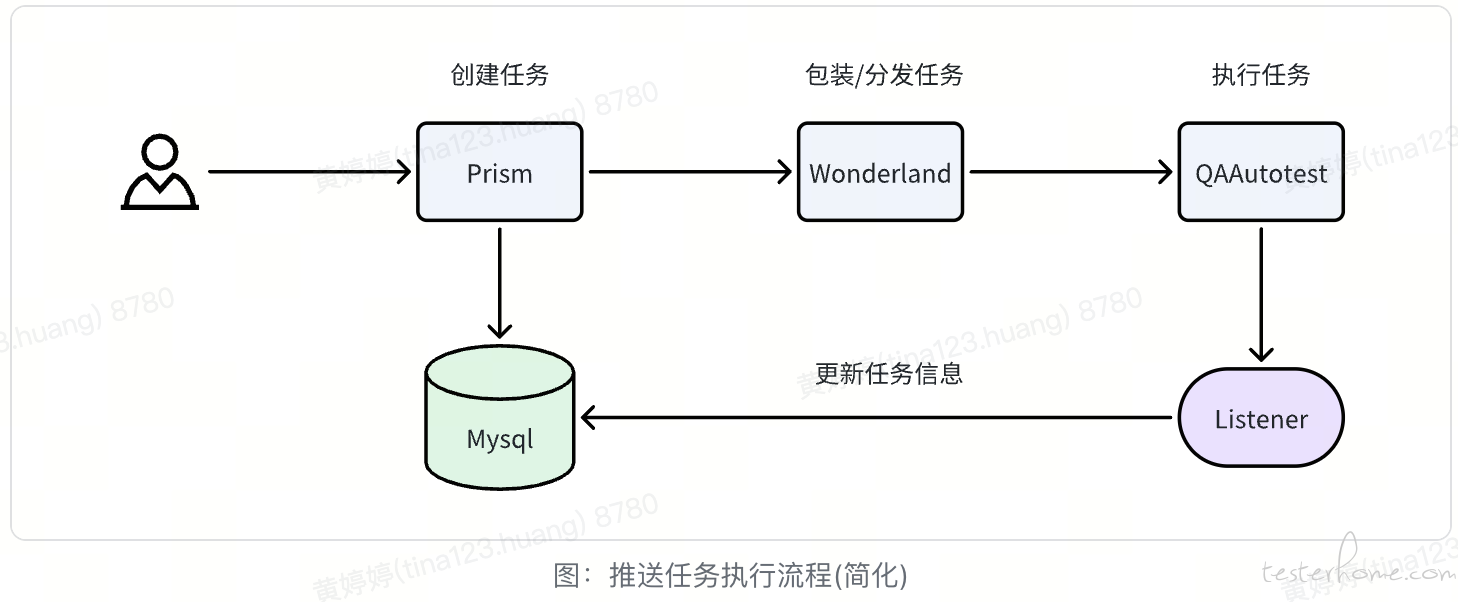
接下来,我们需要把自动化与平台进行关联,使用户不仅能通过平台运行任务,还能自动校验我们需要的内容。这里涉及三个概念:推送断言/测试场景/测试任务

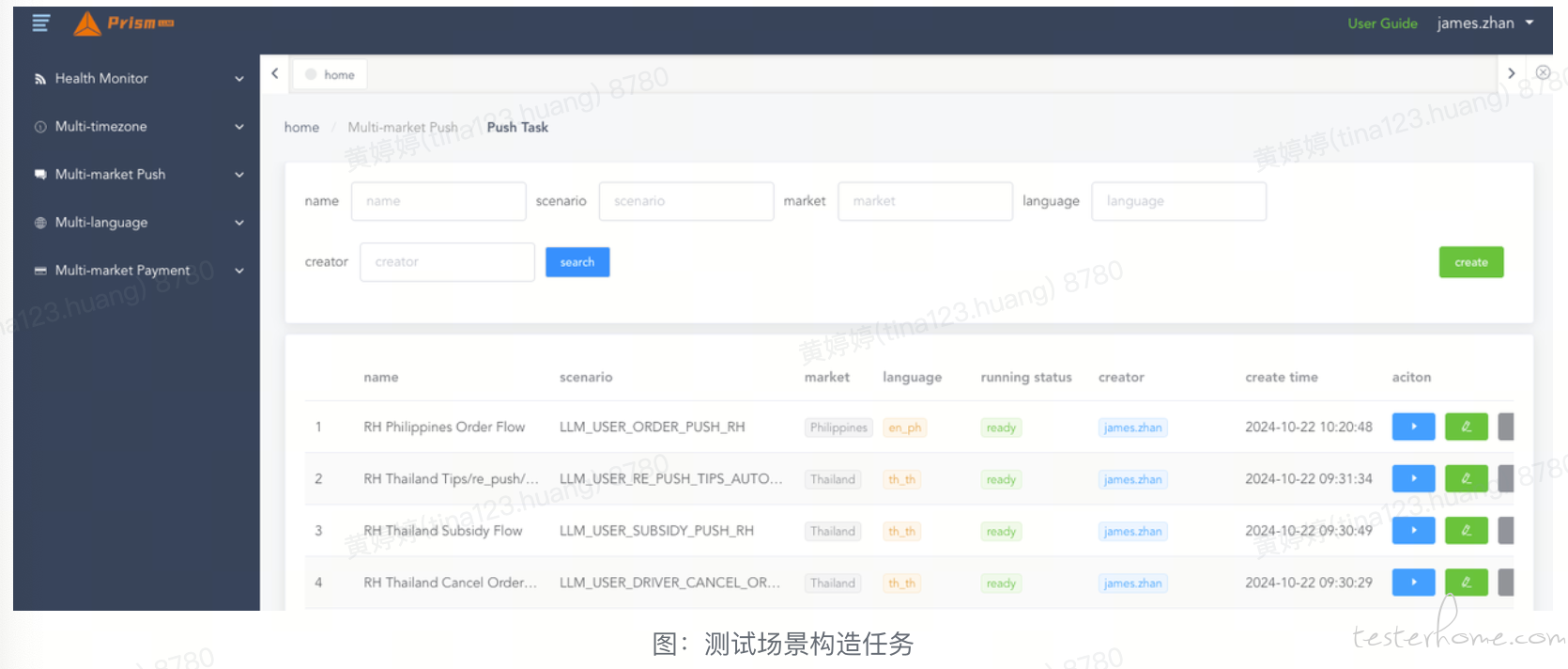
无论是通过手动操作还是平台自动创建,都会生成各种消息。然而,这些消息中包含了不少无效推送,不仅数量庞大,还可能造成干扰。为了应对这一问题,我们制定了相应的存储策略。当平台接收到 Kafka 消息时,将依据既定的策略进行存储。在深入了解存储策略之前,首先让我们来看一下推送事件的不同状态:
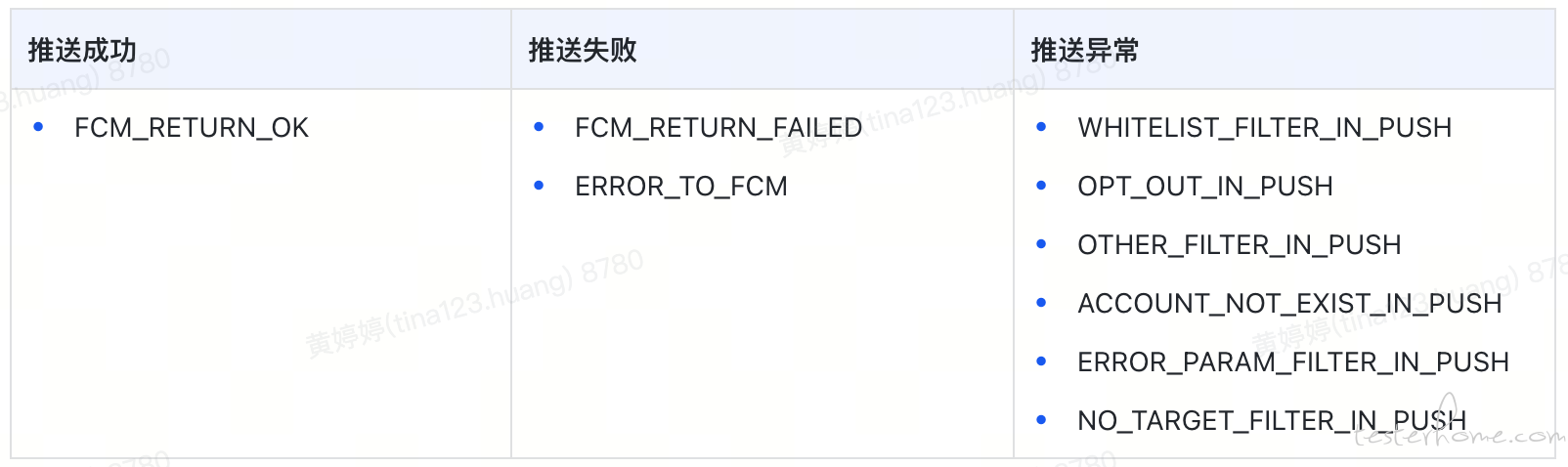
总体而言,推送事件可以分为三种主要状态。其中,与业务相关的推送状态包括 “推送成功” 和 “推送失败”,而 “推送异常” 则主要涉及设备相关问题。因此,我们的入库策略可以划分为 “仅与业务相关的推送” 和 “全部推送”。为了减少干扰,目前主要采用第一个策略。
目前分为 <实时对比> 和 <定时对比> 两种方式,同一条流量在同一时间只能参与其中一项对比。
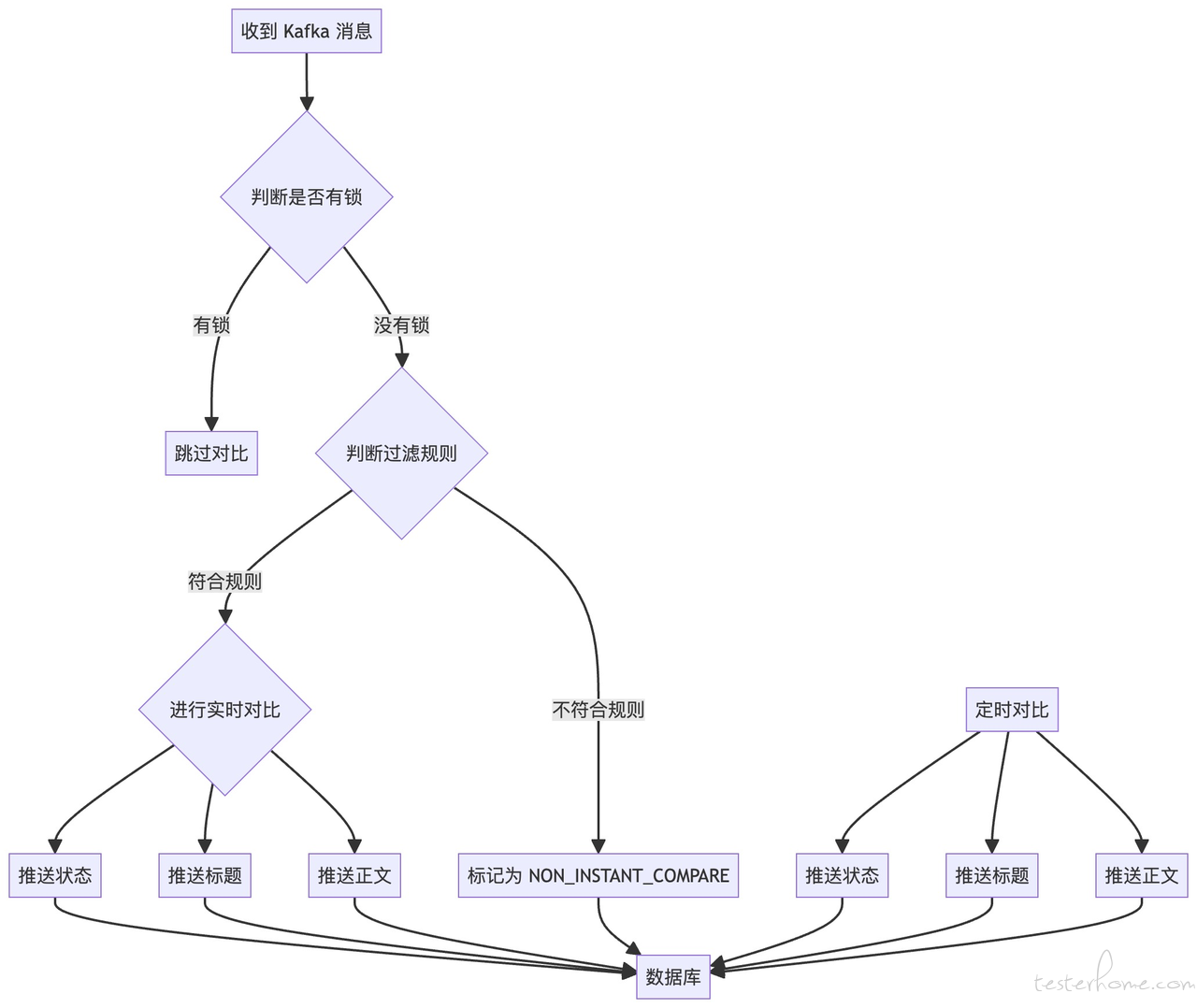
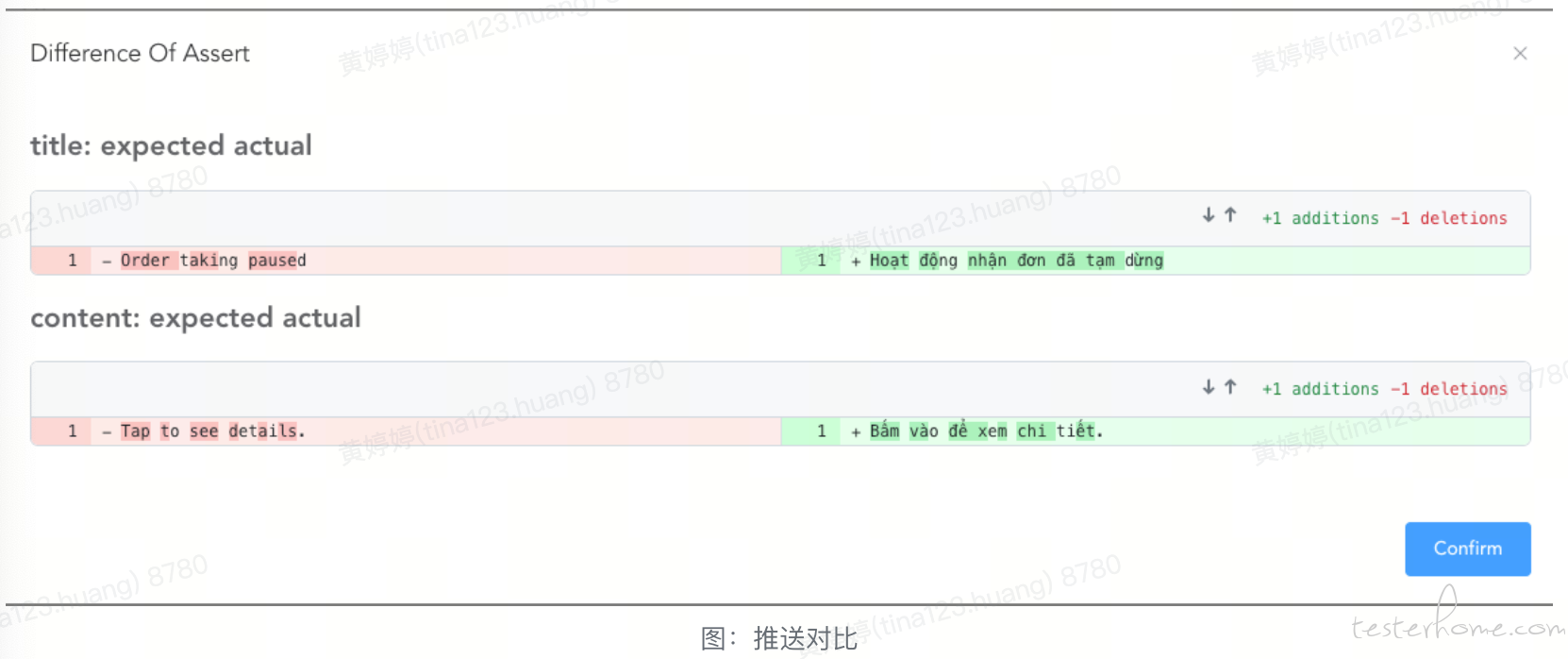
在实际测试场景中,推送消息的触发方式多种多样,除了通过接口同步发送外,还包括异步处理和定时任务。这意味着,在不同的场景下,推送消息的时机可能会有所不同。因此,为了确保每个任务能够在合理的时间内完成,我们需要提前为这些任务配置超时时间。例如,在用户注册成功后,系统会在 3 分钟内发送一条营销消息给用户。因此,为了符合这一逻辑,我们必须配置至少 3 分钟的超时时间。
当定时任务执行时,如果检测到本次测试已经超时,系统将会根据推送的断言情况记录最终的测试结果。
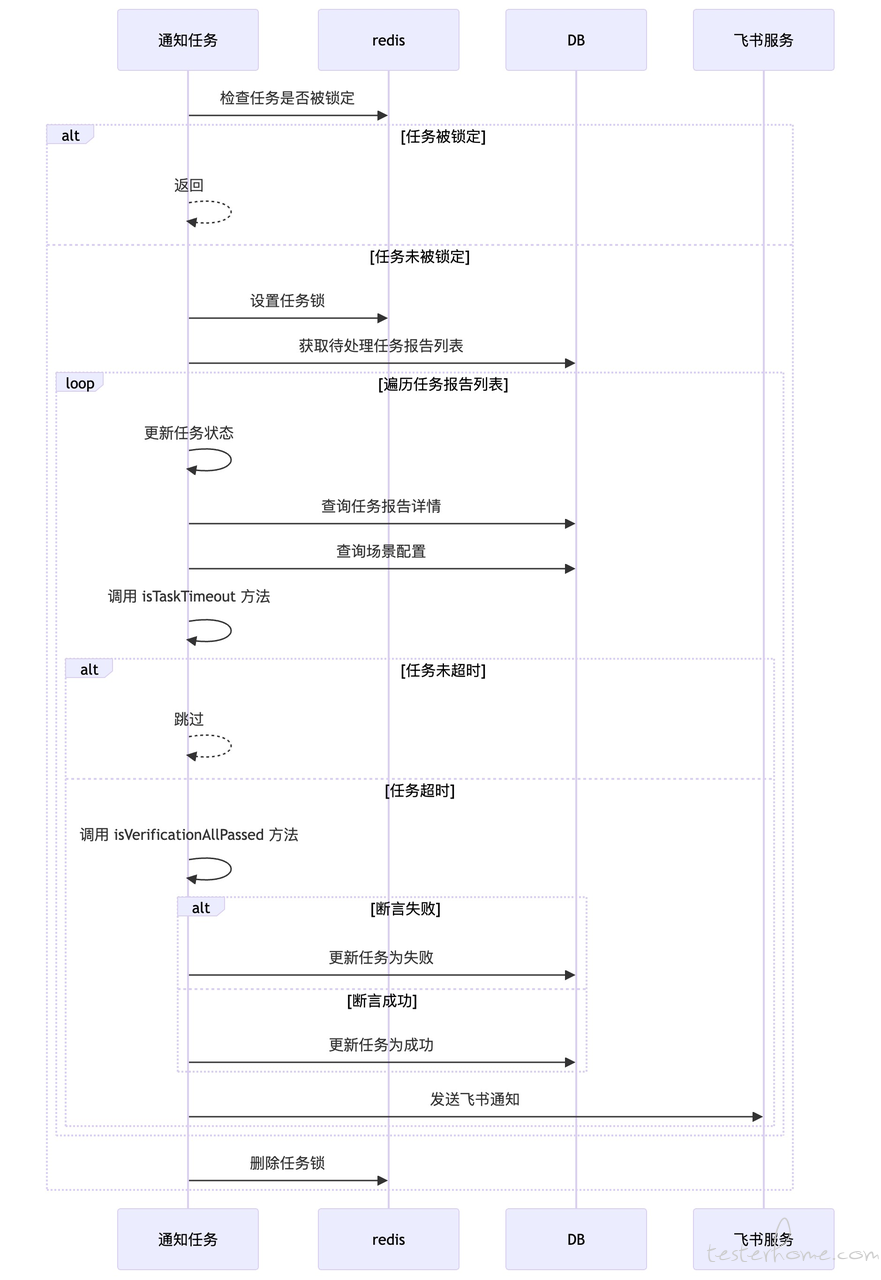
测试完成后,通过飞书机器人推送结果,并附上任务链接,方便查询。
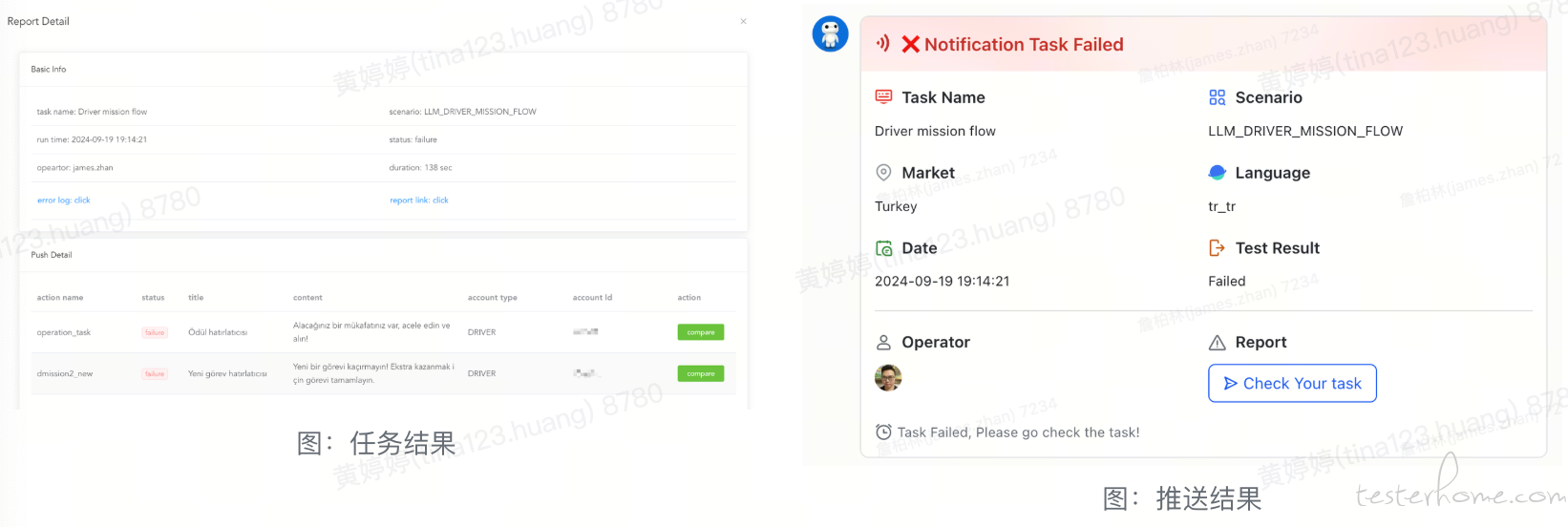
在 Lalamove 的日常功能迭代中,经常涉及到不同市场的翻译验证,相同场景需要切换不用的地区和语种做多次检查。为此,我们开发并不断优化了多语言测试工具,提供不同的自动校验功能,并将其也集成在 Prism 本地化测试平台上,提供最简洁的使用操作。
在翻译文案的测试过程中,我们发现最常见的是未翻译,即某些场景的 key 对应的还是默认语种英文,并未翻译为当地语言,为了花较小的成本批量发现此类问题,在每次提测时,我们都对翻译内容进行一次全量的语种检测。

其翻译原文件如下:
<string name="app_global_log_in">Đăng nhập</string>
<string name="app_global_register">Đăng ký</string>
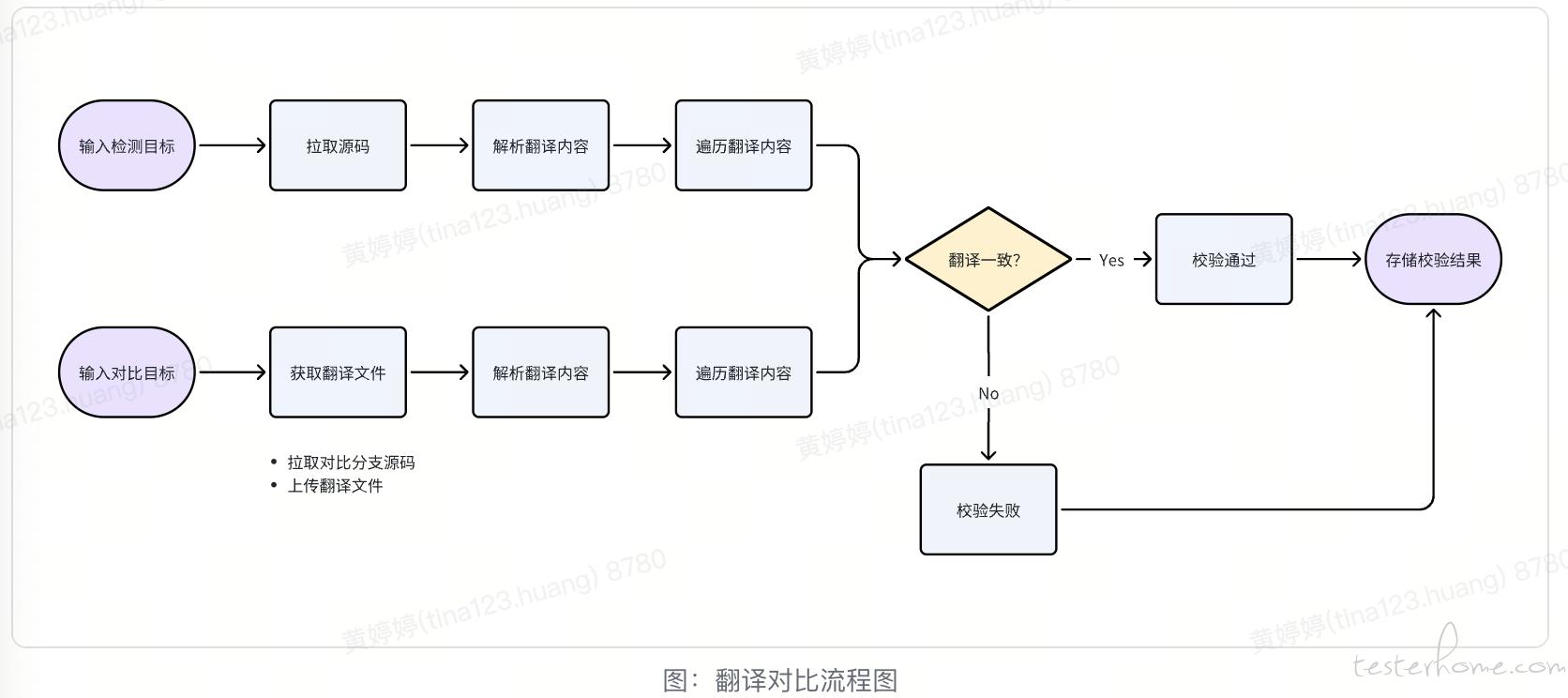
我们的自动化校验工具通过解析翻译原文件,获取翻译文本,然后对翻译文本进行全量校验,检查其语种是否符合预期,如果不匹配,检查是否是因为一些运营原因需要保持非本地语言的翻译,最终输出检查结果,落库存储,经由报告页面解析展示。
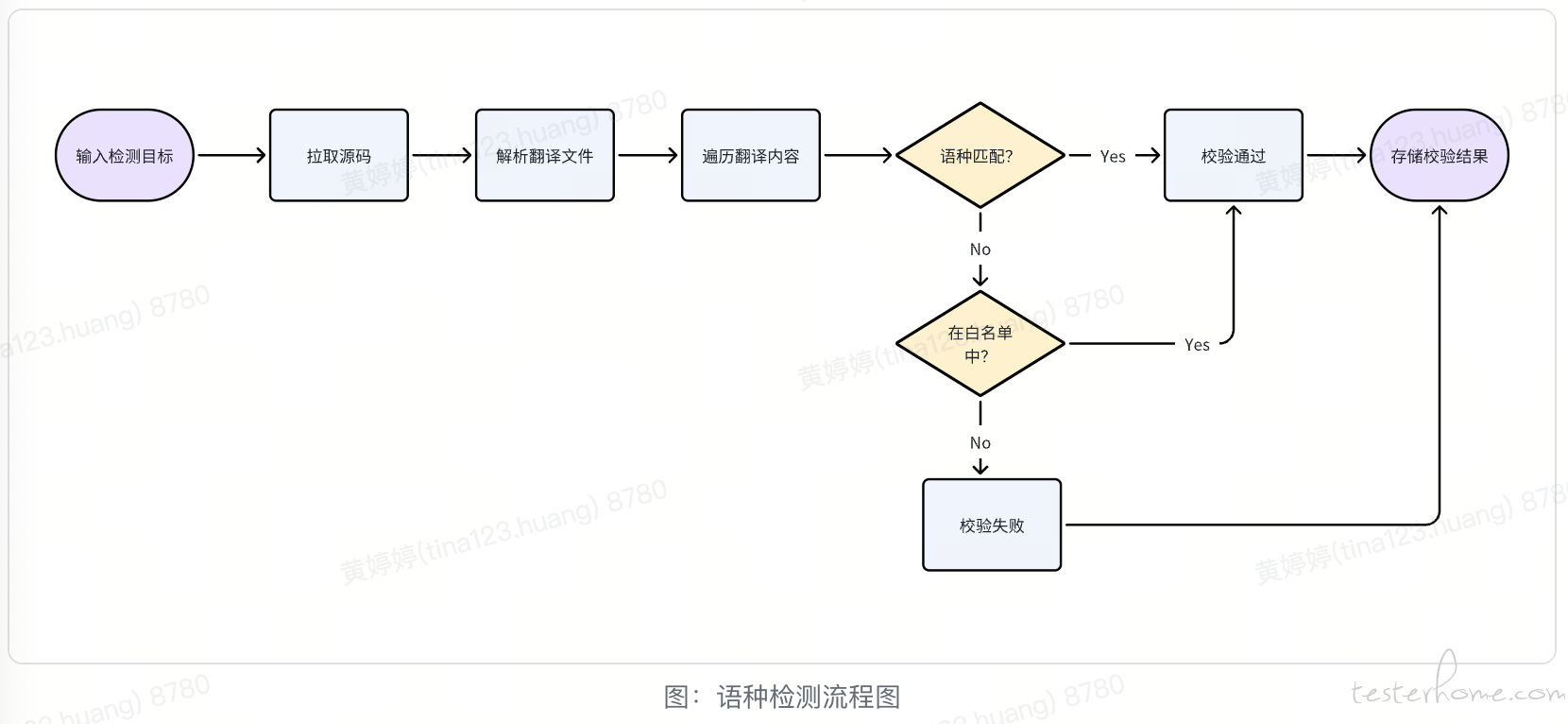
检测原理
判断语种是否匹配时,使用基于 N-Gram 的语种检测模型,其实现原理如下:
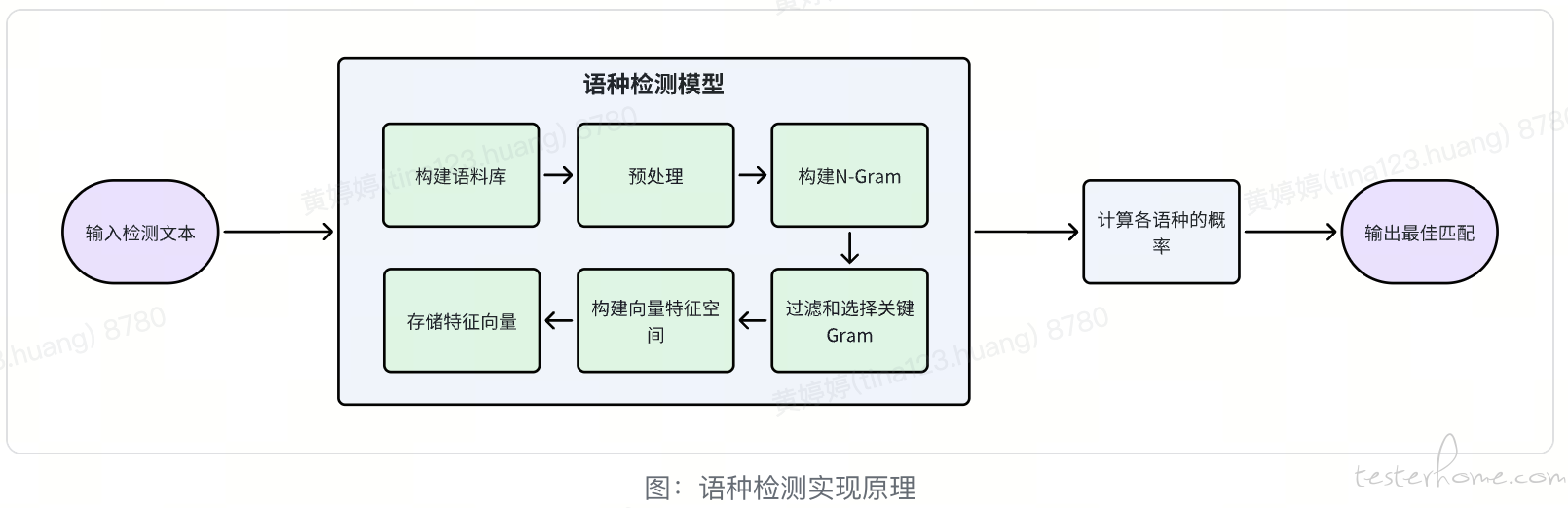
报告展示

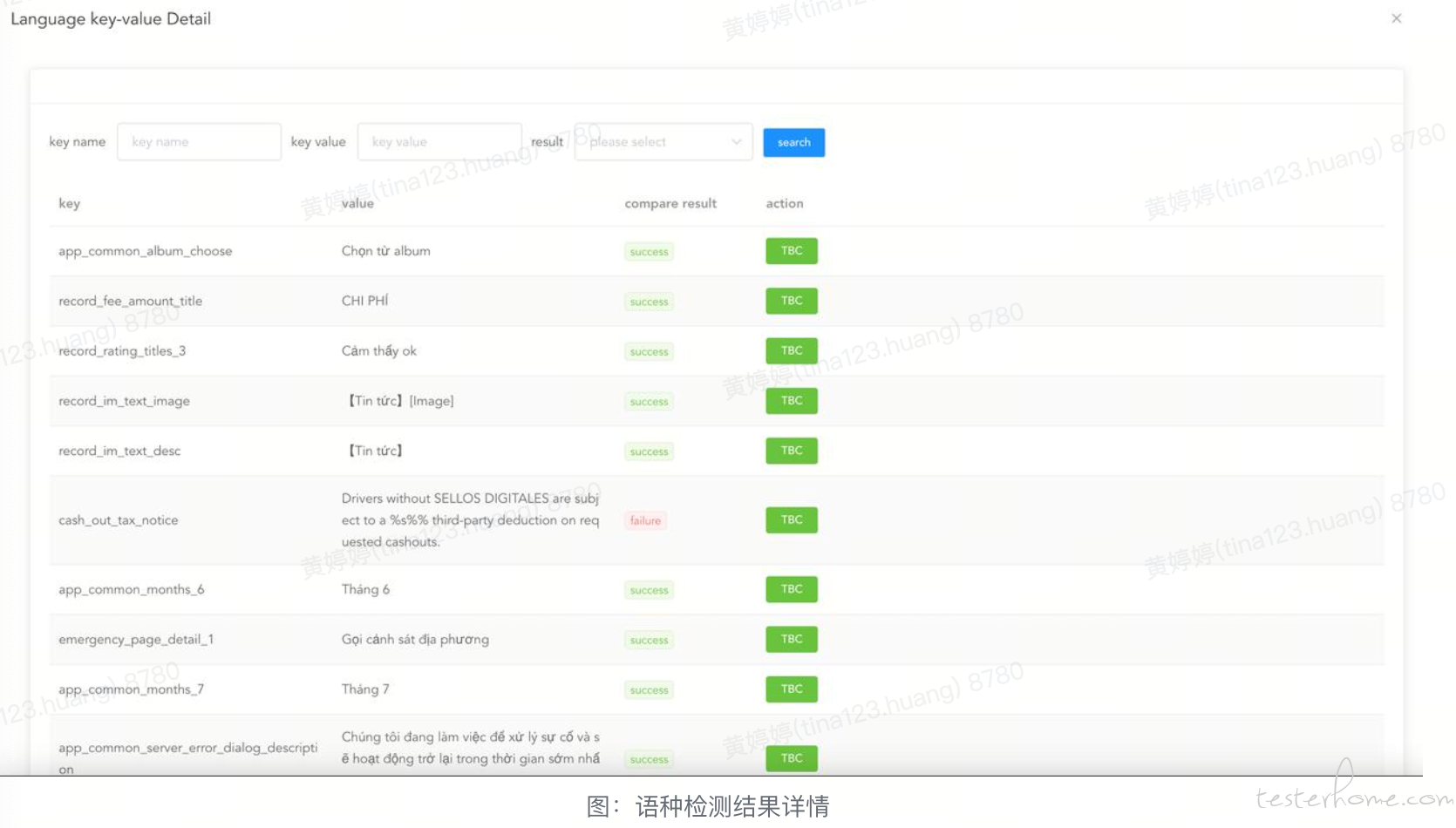
翻译内容对比的数据源同语种检测,区别在于解析完翻译数据后,对格式化后的翻译数据进行对比,如果实际翻译与目标翻译内容匹配,则校验通过。目标翻译内容包括:
翻译内容对比的数据源也与上述两种校验相同,对解析后的翻译内容进行全量的拼写校验并输出校验结果。拼写检查主要检查两部分:

长文本校验,是对翻译解析后的内容根据制定的阈值,检测超过阈值的翻译文本。阈值根据不同的国家和市场,可动态调整,如下面的文本,在语言为英文时只占两行,切换到越南语,需要三行去展示,如果前端的渲染是基于英文去开发调试,那么切换到越南就会有文本展示异常的风险,针对越南语我们设置的阈值要高于英文,去检查同样场景下的长文本。

本地化测试已初见成效,但这条路依然很长很远,未来我们将从以下几个方面继续丰富本地化测试的广度和深度:
