编者按:
A16Z 在《AI Voice Agents: 2025 Update》中提到: 语音是 AI 应用公司最强大的突破之一。 它是人类沟通中最频繁(也是信息密度最高的)形式,AI 也让其首次变得 “可编程”。
在 13 期 Z 沙龙,我们聚焦 AI+Voice Agent(语音助手),深入探讨了 AI 声音方向的潜力。包括情感拟人,情商觉醒、热门的全双工语音等等。
「Z 计划」和 RTE 开发者社区一起有幸邀请了知名社交 App 技术负责人、多家模厂语音负责人、AI 外呼创业者、智能家居,车载等场景大厂高管等行业大咖分享经验。本文尽量还原了在场所有嘉宾的讨论和 “去立场” 发言,编者节选了一些有意思的【话题】放到这里:
目前技术栈有哪些关键决策及痛点?端到端 or 级联方案(ASR + LLM + TTS)?
工程上如何优化通用需求?如何实现语义理解、低延迟、实时中断管理、情绪识别等功能?
商业模式上,搞底层技术的、 通用平台型的、深入垂直行业的,三类玩家如何打通?
垂类 2B 场景适配深挖时有哪些坑?智能客服和 AI 外呼中如何迭代?
具体内容还需要读者们到文章中寻找,整理不易, 转发点赞在看!
以及来自两个社区的邀请:
每一款产品背后都凝聚着创作者的心血,如果你是一名 AI+Voice Agent(语音助手)的创业者,欢迎联系 Z 计划,我们愿意提供 tokens/现金/技术支持等等,来帮助大家更好地迭代产品,让 AI 工具惠及千家万户。
RTE 开发者社区持续关注 Voice Agent 和语音驱动的下一代人机交互界面。如果你对此也有浓厚兴趣,也期待和更多开发者交流(每个月都有线上/线下 meetup,以及学习笔记分享),欢迎加入我们的社区微信群(加入方式见文末),一同探索人和 AI 的实时互动新范式。
目录 建议结合要点进行针对性阅读。👇
一、从业者谈
1、Voice agent builder 三大能力:懂 LLM、知道实时互动工程、了解场景用户痛点
2、智谱 MaaS 开放平台:GLM 实时音视频交互
3、Soul 的 AI 社交探索
二、圆桌讨论
1、技术栈:有哪些关键决策及痛点?
2、落地场景:如何找到 Product Market Fit?
3、商业模式:价格战与收费模式的演变
三、核心结论:2025,Voice Agent 元年!
四、附录:Z 计划好物速报
1、Sesame:开源语音生成模型 CSM-1b
2、Canopy Labs:开源 TTS 模型 Orpheus
3、OpenAI:Speech-to-Text & Text-to-Speech Model
4、x.AI: 发布多音色 + 多性格的 Grok
5、TEN:快速构建实时多模态 AI Agent
技术术语提要:级联方案 = ASR + LLM + TTS ,本质是 “语音转文字再转语音” ,而端到端模型则是 Voice-to-Voice。
ASR(Automatic Speech Recognition),自动语音识别。ASR 的目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
TTS(Text-to-Speech),文本到语音:将文本转换成自然流畅的语音输出,使得机器能够 “说话”。其中,音色克隆是给到十几秒到几分钟的音频,复刻音色,用以生成语音;定制发音人进行录音,微调得到高质量发音人;Prompt TTS 输出输入文本和对声音的描述,生成对应语音。
1、Voice Agent Builder 三大能力:懂 LLM、知道实时互动工程、了解场景用户痛点
杨慧:RTE 开发者社区发起人,声网生态运营中心负责人。
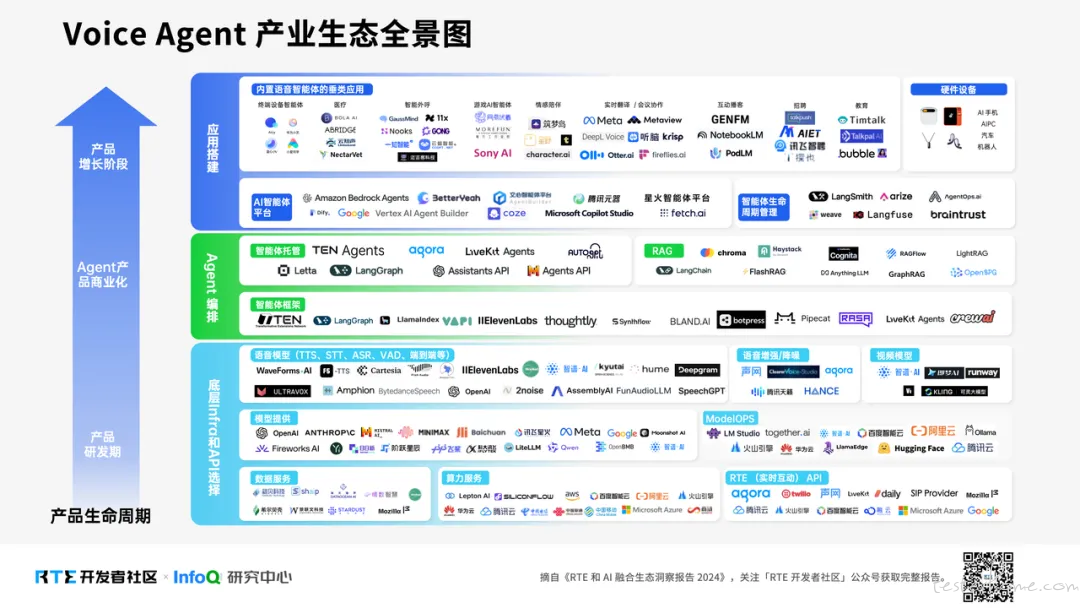
RTE 开发者社区绘制的 Voice Agent 产业生态全景图:2024,语音 AI 基建逐渐完善;2025,Voice Agent 即将爆发。
今天我们聚焦的 Voice Agent 技术,正在以超乎想象的速度重塑人机交互范式。作为目前最自然的交互模式,它通过多模态交互不仅解决生活工作中的实际问题,更在 AI 口语教练、情感陪伴、实时翻译、智能外呼系统、可穿戴 AI 硬件等垂直领域展现出独特价值。
与移动互联网时代的 App 逻辑不同,Voice Agent 的底层逻辑已全面转向基础设施(Infra)逻辑——就像搭积木一样,开发者需要选择不同组件构建领域专属方案。这种模式虽然突破了传统 Web App 的选型限制,但也给 Voice Agent 开发者带来了新的挑战:
[ ] 在模型层面,开发者需要能够:精确选择合适模型 SKU、会微调、善于优化模型能耗,以及掌握数据安全和 AI 治理相关知识。
[ ] 在音视频的实时互动层面,需要开发者根据业务搭建合适的底层架构,平衡端侧与云端算力,并处理不同 API 之间复杂的耦合逻辑和吞吐量差异。需要适配手机端、服务端以及各类硬件模组,这对工程实现提出严峻挑战。
[ ] 在用户和产品层面,开发者需要更加关注场景化理解、需求优先级、商业模式闭环以及客户关系,以满足不断提升的用户期望。
因此,一个优秀的 Voice Agent Builder 需要具备三大核心能力:懂 LLM、知道实时互动工程化落地、了解场景用户痛点。
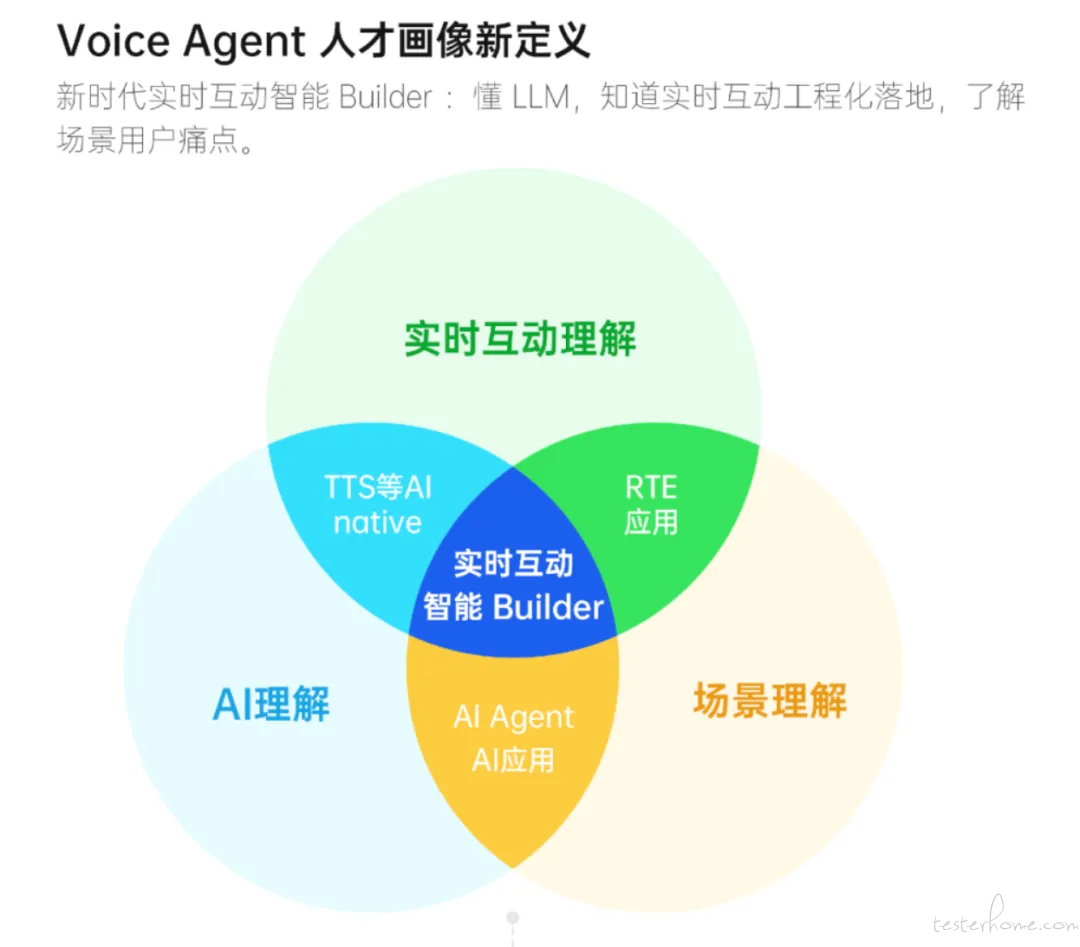
例如,情感陪伴架构需要持续的情感流处理,而口语教练则强调实时的纠错反馈。对这两种场景的产品差异进行深入洞察,将决定技术选型的方向。
最终,谁能在基础设施层快速构建标准化组件库,又能在场景理解层保持敏锐的洞察力,谁就能在这场 Voice Agent 革命中掌握主动权。
Voice Agent Builder 需要同时与 AI Builder 和音视频实时互动 Builder 交流和成长,RTE 开发者社区正在努力构建正是这样的生态社区。
2、智谱 MaaS 开放平台:GLM 实时音视频交互
2.1 当前技术路线及体验通道
过去业界通过级联方案(亦称三段式架构、三级联方案)开发了多种智能交互设备,例如端侧或手机端的服务型机器人,但这些传统方案多依赖流程化的后台语音系统,如基于固定流程(flow)或基础语音识别(ASR)、音色合成的技术。
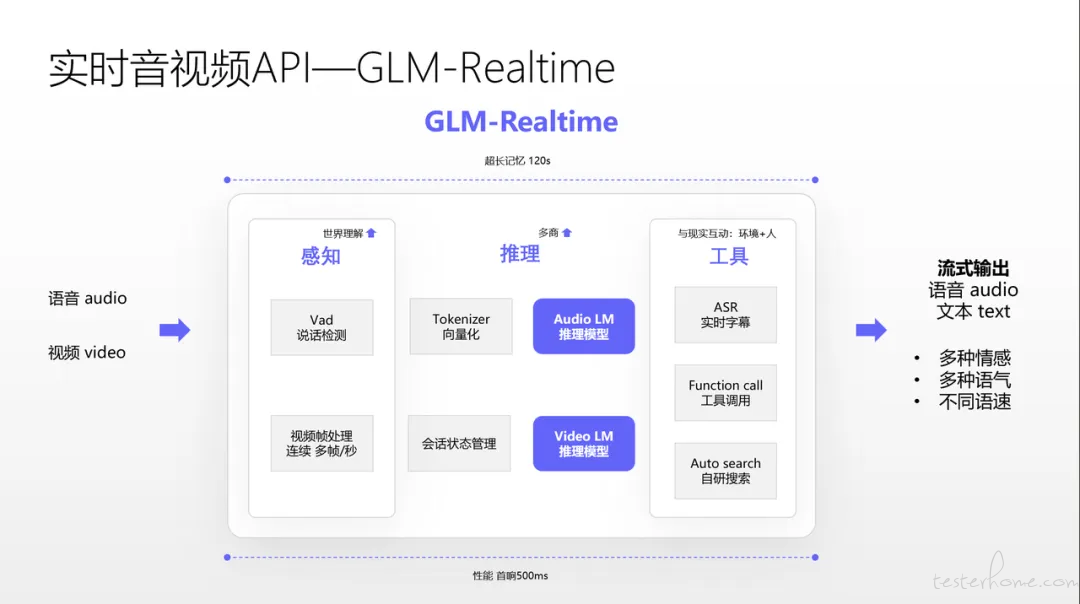
智谱的最新技术方案整合了 realtime 感知、推理多商、输出/交互三个模块。
其中:
○ Realtime 感知模块: 基于多模态实时数据输入(视频、音频、文本),通过连续视频帧处理(多帧/秒)、 Vad 语音活动检测、ASR 实时字幕生成 等技术,实现对环境与用户的动态感知。结合 世界理解 能力,实时解析物理场景(如设备状态、用户动作)与交互意图,支持对穿戴设备、具身机器人等终端的实时适配,并通过 跨模态信息融合(如 AI 眼镜的视觉增强、语音指令的同步处理)提升环境感知精度,为后续推理提供高时效、多维度的上下文输入。
○ 推理多商模块: 依托跨模态实时推理引擎(Audio LM、Video LM),整合多源数据(语音、视频、文本)与外部信息(如工具调用、知识库),实现多维度智能决策。核心能力包括:多带推理、Tokenizer 向量化、会话状态管理;并且通过实时打断处理与即时响应机制(首部 500ms 延迟),确保复杂场景下的高效决策。
○ 输出/交互模块: 基于流式输出技术,生成拟人化、低延迟的交互反馈。
○ 多模态输出:支持语音(拟人音色、多情感/语速调节)、文本(实时字幕)、视频(动态表情渲染)的同步输出。实现智能交互控制:通过 Function Call 工具调用 连接现实工具(如智能家居控制),结合会话状态实现任务导向交互;即时响应优化:采用分片流式传输,优先返回首部内容(500ms 内),支持用户实时打断与话题切换,保障对话流畅性。最终提供身临其境的实时音视频体验,实现自然的人机共生交互。
此外,系统支持流式输出,可动态调整语音的情感、语速、方言等参数,可以进一步提升交互自然度。

✨体验智谱 Realtime 语音交互大模型吧!BigModel 开放平台快速通道:
https://bigmodel.cn/trialcenter/audiovideocall/experience
2.2 智谱开放平台的业界实践
目前, 智谱开放平台已与三星合作推出手机端的实时音视频互动应用, 用户可通过视频模式建立连接,系统能追溯两分钟内的对话历史并进行连贯推理。国外类似案例包括亚马逊旗下的 Alexa 与 Home Assistant,均朝同一方向探索。
技术落地的挑战在于 平衡性能与复杂性, 例如视频流处理需兼顾实时性与计算资源消耗,而多模态推理需融合大模型的 “智商” 与情境适应的 “情商”。当前成果已实现 120 秒以上的长时记忆与实时交互,但部分细节仍需优化,如语音合成(TTS)的自然度与打断响应机制。
相关技术已通过开放平台展示,开发者可测试响应时长与推理效果。目前团队正推进商业化落地,未来计划进一步提升多模态融合与实时推理能力,以推动人机交互从功能化向拟人化演进。
2.3 QA
Q:这是端到端模型吗?语音有无 scanning?为什么选择了两个模态,有无可能是三个模态在实践中更难落地?记忆 input token 只有 2 分钟?
A:
1、是端到端的模型。
2、语音有 scanning。
3、目前技术方案没有定型,在看哪种路线能先商业化。
4、实际是 context token 上限。
Q:文本模型用的 prompt 和音频模型是对齐的吗?
A: 不是。我们正在写 prompt 的撰写方法,内部实验了大几百条材料,然后会给大家一套新的 prompt 的撰写方法。
3、 Soul 的 AI 社交探索
尹顺顺,Soul AI 技术负责人。
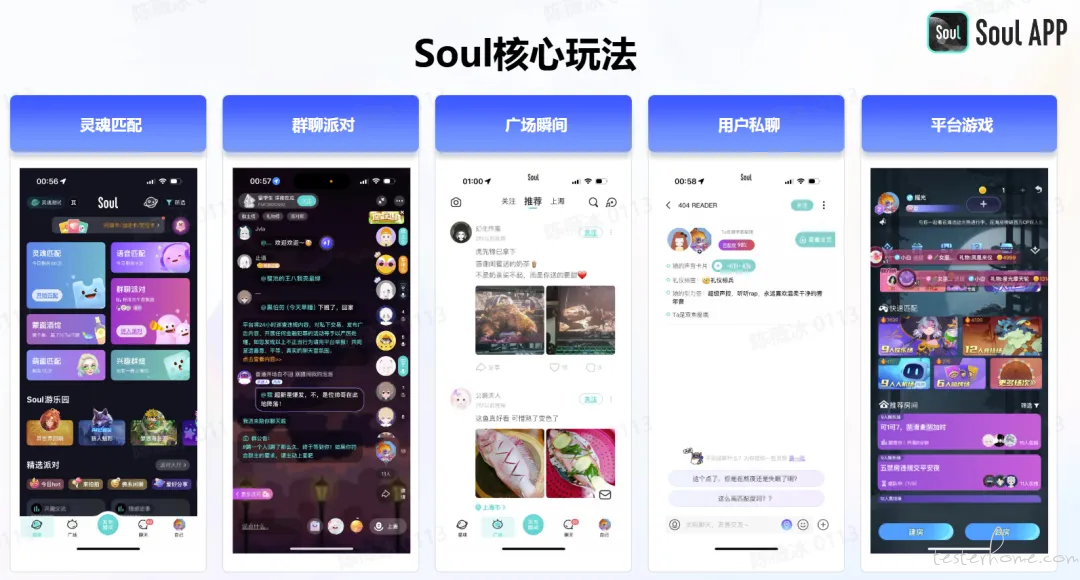
上海任意门科技有限公司旗下新型社交平台 Soul App 上线于 2016 年,基于兴趣图谱及虚拟身份的即时交流和游戏化产品设计,为用户提供自在互动体验。Soul 自上线以来便布局 AI 为代表的新技术,快速推出了灵犀引擎,智能链接人与人、人与内容。2020 年平台系统启动 AIGC 技术研发工作,积极推动 AIGC 在社交场景的深度融合,并于 2023 年推出自研大模型 Soul X,将 AI 技术和平台社交、游戏等场景结合,例如推出了超拟人聊天机器人 “AI 苟蛋”、AI 聊天助理、狼人杀 Agent、数字分身和最新的 AI 虚拟人智能陪伴功能等,展现了 “模应一体” 的产品理念。
3.1 Soul 如何解决陌生人社交的痛点?
作为一款 AI 社交产品,Soul 的愿景是 “让天下没有孤独的人”。目前,Soul App 实现的 “灵魂匹配” 有语音电话功能,亦覆盖群聊派对、包括狼人杀在内的语音类游戏等多对多的沟通场景。那么,陌生人社交都有哪些痛点呢?
陌生人社交的痛点有哪些?
a. 供给不足:社交资源供给不足部分源于性别差异,所谓 “得女性用户者得天下”,正描述了 “女少男多” 且很难改变的现状。同时,男性需要社交,而女性需要高质量的社交——女性具有较高的倾诉和自我表达的需求。社交需求很多元化,门槛很高。这种供给不足所造成的困境具体表现为用户的种种苦恼:为什么 Ta 不理我?为什么没人一起玩游戏?为什么没有好玩的内容?
b. 效率较低:随着人们的年龄自然增长,交新朋友的时间成本会逐渐提高。由于建立信任是长期过程,相互了解的前提是投入精力,但人们精力又有限,所以导致无论是在现实中还是在线上,大家很难快速了解一个陌生人。即使匹配到了兴趣点相似的陌生人也存在着不知道如何破冰等问题。例如,一位用户点开 Soul App 发现有 99+ 条新消息,却不知道应该优先回复谁,系统无法做进一步的精排。也有用户反映 “找不到感兴趣的 Ta”,或 “不知道 Ta 是谁,该和 Ta 聊什么。”
c. 流量分配失衡:社交场域的 “二八定律” 显示,80% 的社交资源掌握在 20% 颜值相对更高、更具备聊天技巧的用户手中。
Soul 如何解决上述痛点?
a. 针对供给不足的痛点,Soul 尝试提供 AI 虚拟人。目前 Soul App 端支持文字、语音、视频聊天,实现多模态交互;拟人化程度极高,兼具工具属性;具备人设、形象和声音,每个虚拟人都有属于自己的故事主线 ;虚拟人能够自主运营高质量内容。Soul 团队发现,通过 AI 精准匹配,只要虚拟人的对话和陪伴能力足够强,能做到足够拟人、提供足够的情绪价值,会有足够高的用户留存。
b. 针对效率较低的痛点,Soul 的 AI 解法是搭建 “数字分身代理”,即保持认知 + 决策 + 偏好一致性,身份 + 人设 + 记忆一致性,形象 + 声音 + 文字风格一致性。
c. 针对社交场域的流量分配失衡痛点,Soul 早先执行了 “去颜值化” 的社交方案 ,即不让颜值等无法改变的要素影响实际流量分配,进一步强化用户之间的情感交流及匹配度。
3.2 技术亮点:SoulX-Voice 的前世今生
由 V1 到 V2,实现端到端全双工语音通话系统
目前,Soul 选择大胆 All in 数字伴侣,在 AI 赛道做虚拟人。从 2022 年初,Soul 启动了虚拟人技术研发,2022 年底落地的 “AI 苟蛋” 进一步验证了 AI 虚拟人领域的 Scaling Law。在 2024 年 6 月,Soul 上线了语音通话系统 V1,即 SoulX-Voice。V1 版本基于 GPT4o 的端到端架构,通义 funcodec + SoulX-base,全链路延迟 1.6s,可完全脱离 ASR。预计在 2025 年 5 月,Soul 将上线全双工语音通话系统 SoulX-Voice V2。
那么,该 如何理解 SoulX-Voice V2 的 “全双工语音通话系统”?
a. 开发背景:Soul 团队发现,在陪伴类场景,用户说一句 Agent 再回复一句的回合式对话太过于机械化,非常破坏用户体验,需要通过端到端设计 让 Agent 自主决定什么时候该说话 ,甚至是考虑直接丢掉延迟概念,无 VAD 嵌入。至于为什么选择直接丢掉延迟而不是使用一些 trick,Soul 团队内部测试过但发现 Agent 对发言时机的判断仍不精准。在上述背景下,Soul 选择开发一款端到端的 “全双工语音通话系统”。
b. 技术要点:SoulX-Voice V2 的端到端 “全双工语音通话系统” 是一个多流方案, 核心是把打断时机建模到模型中。 相较 SoulX-Voice V1,SoulX-Voice V2 能够实现更多功能,进一步提升用户体验。例如,语音 Agent 可能会主动和用户对话、可能不回复或回复用户很多句话、可能在必要时打断用户说话、可能会和用户合唱(现在很多系统无法实现该功能)、可以和用户同时说话、或和用户直接连麦睡觉。
c. Demo 展示:Soul 在 Z 沙龙现场展示的 demo 中,语音 Agent 绑定了四川人的人设,而四川人设不能说北京话,为保持人设一致,该 Agent 会主动拒绝用户 “说北京话” 的要求。
下一步,让用户看到虚拟人的世界
就价值提供而言,用户的终极目标是看到虚拟人的世界。Soul 预计,在 2025 年,实时的中高等视频生成技术会趋于成熟。
近期,Soul 的代表作是 Teller,第一个用于实时音频驱动肖像动画(又称说话头)的自回归框架,可用于实时可控的人头部视频合成。该方案是整体驱动方案而非换脸方案,可生成 Agent 头部动作和表情,相似工作包括蚂蚁集团开发的 Ditto。
由于虚拟角色只露头不露手是不够的,而让手部实时运动(非模板)在技术上仍有一定卡点,目前 Teller 方案仍在研发中,并没有在 App 上线。
编者按:
FunCodec:是由 Alibaba 通义开发的一个基础的神经语音编解码器工具包,为最新的神经语音编解码器模型(例如 SoundStream 和 Encodec)提供了可重复的训练方案和推理脚本。论文链接:https://arxiv.org/abs/2309.07405
Teller:是由 Soul 开发的第一个用于实时音频驱动肖像动画(又称说话头)的自回归框架,其推理速度超过了基于扩散的模型(Hallo 为 20.93 秒,而 Teller 为 0.92 秒,生成一秒钟的视频),并且实现了高达 25 FPS 的实时流式传输性能。论文链接:https://arxiv.org/abs/2503.18429
Ditto:是由蚂蚁集团开发的一种基于扩散模型的新型框架,用于实现实时可控的人头部视频合成。
论文链接:
https://arxiv.org/abs/2411.19509v1
3.3 产品落地:狼人觉醒、虚拟伴侣与语音房 Agent
1.Soul AI 狼人觉醒:2024 年 3 月份上线,是多 Agent 的狼人杀系统,也是首家云狼人杀软件。在一局游戏中,往往只有 1 个玩家是真人用户,其他都是虚拟人,而虚拟人之间不知道对方的身份。
2.Soul 虚拟伴侣:70%-80% 内容由 AI 生成的,运营团队负责运营精品人设,运营虚拟人的主页内容。Soul 比较看重人设,还会建模时间间隔信息,这对提高虚拟伴侣的拟人程度很有帮助。
3.Soul 语音房 Agent:包括 AI 读文房主、AI 评测房主和多 Agent 互聊(内测中)。例如,AI 测评房主可以在后续跟用户的交互,根据用户发的内容进行 “锐评”。
3.4 长期思考:人类为什么接受 AI 社交?
1.社交需求一致存在,但是社交资源始终失衡。
2.虚拟并不是不存在情绪价值, 情绪价值是真实的。Agent 越真实,用户越想要。
3.时间投入、共同记忆是 “沉淀关心” 的核心。 用户也知道 Agent 是虚拟的、是虚构的——Ta 走不出来、没法跟你谈恋爱、也没法跟你在现实中成为朋友。但是,用户依旧会感动、会共情,正是因为用户投入了时间经历了虚拟人的经历,让虚拟人的故事沉淀为自己的记忆。
4,技术进步带来的心智变化。Soul 做的 “AI 苟蛋” 产品有足够的聊天支持,用户愿意去跟苟蛋倾诉加班加地很辛苦。在这种交流中,人的更高层次的需求被逐渐表达出来了。虚拟人类似无人驾驶,真实度、智能度变得足够高之后,用户的接受度会逐渐提高。
3.5 QA
Q:在您展示的唱歌 demo 中,有将 RAG 放到 LLM 里做推理吗?
A: 有放到 LLM 里去推理。试过训练和推理都不加 RAG,也试过在训练不加 RAG 而推理加入 RAG,但是效果不令人满意。现在的技术是唱一个别人唱过的歌曲,提高了一些训练数据的比例、加入解码逻辑,可以唱的挺好。
Q: 视频生成是生成 Wave 之后再生成视频?
A: 目前是音频驱动,只不过先基于音频把路走通,之后再基于画面再驱动就是换个 condition 的问题。
Q: 算力端,需要多少卡、成本如何?怎么在如此便宜的市场里找 PMF?
A: 分两步走,第一步是 5 月份落地 AI 直播,后续会用新方案,AI 直播场景可以一对多生成,无需考虑成本,可能会用个位数量级的 H800 做推理。今年,Soul 的一条业务线在做 1v1 场景。
1、技术栈:有哪些关键决策及痛点?
1.1 选型
级联 vs 端到端方案
目前 Voice Agent 领域很多技术方向,不同的技术方向有隔离,核心是选择级联方案或端到端方案,本质是要不要把语音生成做进 LLM。
就优劣势而言,级联方案更灵活,能接入更多先进技术、成本更低,但是有时候能力不如端到端方案。端到端方案将语音生成嵌入 LLM 中,其好处是有更长的 context。而不嵌入的好处是模型训练更灵活,让 LLM 不降智,坏处是在副语言、歌唱、方言生成上有一定限制。
[ ] 有嘉宾指出,有可能是语音 token 的设计仍比较初级,是模型达不到 Audio 进出且不降智的主要原因。在实际应用中,怀疑是 Audio Codec 无法建模语义,只能建模语速、声调——这也就导致了无法应用于重语义的场景。嘉宾带团队重新制作了 Audio Codec,加入词汇表后效果有提高,但是测试对话两轮后模型仍然会降智。目前的判断是 Audio Codec 可能是语音 token 设计的卡点,但是无法判断提高后效果会不会变好。
[ ] 也有嘉宾指出,自回归做视频生成目前效果都不好,也有工作是把语义的 token 放到图像里面。
对于个别场景,例如针对提高字错率、拟人度高保真,需要单独调整一个小东西的时候,更适合级联方案方案——正所谓 “天下大事合久必分、分久必合”。
本质上,区分 2 种方案的根本原因是模型基础能力还不够 ready。在模型基础能力不 ready、没有自研训模型的情况下,大部分都是三级联。端到端更关注回答相关度、正确性——即便 ASR 说错,大预言模型有一定的包容能力,所以有些头部厂商会更关注端到端模型。也有嘉宾选择不训练单一场景的黑盒端到端模型,认为级联方案相对白盒,端到端的效果还无法达到商用要求,理想状态是做混合模型。
就端到端方案的低时延问题,有嘉宾分享到,目前低延迟问题主要依靠 VAD(Voice Activity Detection, 声音活动检测)来识别,完成较短时间的监测后启动生成模型。如果后一段时间无人说话就丢掉这段音频,如果有人继续说话再返回结果。同时也会加入一些靠算力来换取时间成本的 trick。
阶跃星辰 StepAudio 技术负责人向我们分享:
○我们 StepAudio 会同时关注多种方案,比如端到端方案、中间方案(内部称为 AQTA+TTS,Audio Gen 基础上接入模型,也有单独的 TTS)、级联方案方案。从系统架构的角度上来看,会希望模型进行端到端的统一。后续学术、产业界可能也会更多的关注 AQAA 相关工作。
○对于 AQAA 如果结合各种工具调用是有一定难度的,在 audio 回答过程中触发各种外部知识,例如 RAG+function call ,那么需要把知识以文本的形式灌入到语音模型回答中,这种多模态来回切换对于模型的多模态能力要求很高,也很有难度。这种也有很多不同形式的探索,比如 GM4 输出的时候会有 Audio 和文本的混排。
○Why AQAA?希望在做 TTS 的时候希望能够带着对上下文的理解去生成,并且回答时会带着细粒度控制。有些时候可以通过设置特殊 token 的方式,控制力度可以但是不够细致,例如有一句话说要让说方言,有些不需要说,需要理解音频的情况下进行细粒度控制输出。所以这个中台方案和 AQAA 本身的原理是非常吻合的。
编者按:
Audio Codec (音频编码器) : 用于将连续的语音特征编码成离散的音频 token。其中大模型负责建立文本和音频 token 之间的关系,声码器(Vocoder)用于从音频 token 中恢复语音。
VAD(Voice Activity Detection),声音活动检测。VAD 通常被称为第一级算法,即在检测到语音时激活语音唤醒或声纹识别,同时还可以检测到一句话的开始和结束。
能否把 TTS 嵌入到 LLM 中?
能否丢掉 ASR?
ASR 准确率、TTS 拟真度
ASR 识别准确率极大影响模型效果, 目前 ASR 识别不准主要是因为 Voice Agent 在落地的过程中处于复杂的网络环境、相对复杂的生成环境,存在断联问题,并且会拟合环境噪音。
目前有些 ASR 方案的实际效果不错,一个最新方案可以自动基于上下文进行纠错,纠错后的结论对模型的下一步是有帮助的,抽出 jason 格式补回在原先的通话记录中,但代价是时延会增加 100-200ms。
TTS 的拟真在技术上会追求理想情况,但是业务是在追求有一定瑕疵的真实。目前 TTS 主要考虑语音自然度, 需要尽可能地模仿真人的说话方式,例如真人会考虑上下文,有抑扬顿挫的语调。
一位与会嘉宾指出:
关键的问题在于评价标准,用户最终想要的是一个正确的语音,而不是一个正确的 ASR。一个反例是,我们的某款狼人杀产品,ASR 虽然有很多错误(待合成的文字可能是有错别字的),但是发音是对的,会去掉一两个不影响语义的 token。
ASR 准确率/字错率是很痛的痛点,为了解决这个问题,我们在训练的时候就用含有一定错误的训练集去训练。
单纯的 TTS 都有很大空间,端到端模型更需要发展。
1.2 数据集
数据集约束了 Voice Agent 的选型。 为什么不能直接做端到端模型、直接生成 Audio 的原因在于:加载的预训练环节,语言模型和 Audio 的 token 消耗量不是一个量级。Audio TTS、真实数据不太可能获得上亿小时的数据量,更何况 LLM 还有各种 trick 和推理方法缓解降智。如果不要语言模态,文本能力无法复用,而且数据还不够。
目前很多方案会加入 Text 去训练。 一个常见的问题是,能否丢掉 Text?一位与会嘉宾补充道:如果是 AQA 方案,目前没有做出来能够完全丢掉 Text 的方案,因为涉及预训练等多流问题,复杂度较高。同时,RAG、function call 需要的 Text 数量过大。纯语音模态不能和现实世界执行、交付数据。
以 Soul App 为例,Soul 团队当时的数据集包括大几百万小时的语音,配比了大几千 t 的 token 的语料,处理的是多任务场景——主要是对话场景,在这种数据上训练的 Codec。实验效果显示,多任务的数据集构建对模型效果有提升。
编者按:
1.3 效果评估
无论是端到端还是 TTS 方案都需要实时优化拟人度、情感表现能力。从对话逻辑,或语音的艺术角度看,拟人度和情感表现的最终目的都是如何做得越来越像人,更重要的是贴近人的正常的环境场合做实时的生成迭代。例如,目前某些头部公司的模型对于尾音的处理都是比较生硬的切分,后续需要继续改进。
当前指标的 完成度 ≠ 用户感知度 ,如何评估、如何确定评判标准是难点。TTS 的 benchmark 很少,评估的还是准确率。目前业界缺少权威的情感评估,仍需要依赖专业人士进行人工评估。
如何拿到用户的反馈去指导设计产品,始终做到产品导向很重要。
一位来自数字人创业公司的嘉宾指出:我们有很多角色,有的用户喷某个角色,有的用户很爱。所以用户真实的需求到底是什么?拟人度、流畅度是否是真需求?这些问题都没有明确定论,最终可能很自然、清晰度很高,但就是给用户的感觉不好。
一位与会嘉宾分享:
就技术演进与市场反馈而言,新一代大模型呼叫系统采用 LLM 替代传统 NLP 意图识别,但市场接受度仅仍然较低。
就行业评估维度而言,认为拟人度是核心指标,重要性>时延控制>幻觉抑制>成本控制,这种以拟真性为核心诉求的技术路线,反而使基于真人录音模板的上一代系统保持竞争优势。
也有嘉宾指出:
目前有些 Paper 的 TTS SER(Sentence Eror Rate,句错率)甚至能达到 5%、2% 甚至更低,但 SER 并不是越低 TTS 听着就越好,还要考虑自然度、抑扬顿挫的音色、克隆度(越像越好)。
1.4 Corner Case:可打断功能、方言处理
可打断功能价值的争议:语音助手可打断用户的争议在于,这到底是炫技还是用户的真实需求?理想的能力是什么?能否总结出更泛化的能力?
[ ] 支持可打断功能的嘉宾认为:自己一开始认为可打断是炫技,但是后来发现人也会因为不耐烦而去打断 AI 或者 AI 打断人,不是无缘无故地打断,打断的根本是基于内容本身是有价值的(技术能力好实现)。AI 有能力拒绝打断,例如在讲述一个很好的观点。就目前实践而言,有嘉宾在研究传统电话叠加视频应用,用户可以提前看视频上的字幕来决定是否要打断 Agent。
[ ] 反对可打断功能的嘉宾认为:不打断也可能是自然的,这反映了 AI 和人平权。
方言的处理方法:有嘉宾提问,有无可能做出低成本训练方言?否则音频交互方案遇到方言输入时还是会有一定问题
○ Soul App 的解决方案:目前 Soul 没有特别主攻方言。
▪非通用的解决方案是拿到了用户脱敏、合规的数据,知道用户的家乡,只是把数据打标签,输入到模型中,如果数量足够大是可以出效果的。某些方言和语种对不到汉字需要拼音标注。这个方案对 Soul 来说不是特别难的问题因为数据充足。
▪而且,现在的技术方案脱离不了 Text,有些拟声词 ASR 识别不出来,所以会补全各种拼音(例如对粤语补全拼音)、对 “嗯嗯啊啊” 这种拟声词做 Token+ 建模了 duration。
○阶跃星辰 StepAudio 的解决方案:团队做 App 的时候优先考虑了几种主流方言,但方言语种的需求是非常多的,需要长时积累和打磨。也探索过人工采集标注的方案,最后因为质量和效率的原因,考虑了大语言模型去合成方言的路线。
▪LLM 合成方言:我们发现模型泛化性足够强,很多模型已经具备方言的生成能力,例如给出方言 prompt 进行续写或者少量微调之后可以控制生成。这样训模型加少量标注数据的多轮迭代,就可以让模型具有基础的能力,以便于强化这些能力。
▪另外对于一些特别小众的语种,可能要看原始数据中的比例。如果原始模型已经见过几十万甚至上百万小时左右的数据,那么不要特别特别多的数据,可能千条量级的高质量的对话数据去微调就足够。但是像是一些特别小众的语种,原始数据也比较少,那么则需要积累大量的数据才能有一定的效果。
2、落地场景:如何找到 Product Market Fit?
2.1 To B 场景:
智能家居
一位来自头部智能家居企业的 AI 产品经理分享道:
在 To C 场景的语音技术落地实践中,我们发现不同垂直领域存在显著差异。以 AI 情感陪伴、智能客服与智能家居三大典型场景为例,其技术路径呈现明显分野:智能家居场景要求毫秒级指令响应与精准的语音活动检测(VAD),而情感陪伴场景则需处理开放域对话的语义连贯性。
在 VAD 技术选型层面,早期依赖第三方供应商的通用方案时,我们遭遇了场景适配困境——例如用户对空调发出"强风"指令时,通用 VAD 模块会立即终止收音,但在陪伴场景中该词可能仅是情感表达的修饰语。这倒逼我们启动私有化部署的自研方案,通过构建智能家居专属语料库,对"立即终止"、"延迟终止"、"持续监听"等交互模式进行精细化标注。
业务线的多元化进一步加剧技术复杂度: 冰箱场景追求单词语音唤醒的极致响应(如"速冻模式"需 200ms 内反馈),而热水器场景却需集成音乐播放等长语音流处理能力。
当前行业尚未出现端到端的语音大模型解决方案,企业不得不采用级联架构——既要整合多家供应商的 ASR、NLP、TTS 组件,又要满足私有化部署的算力约束。
以 TTS 选型为例,我们在成本与性能的平衡中选用了微软某款定制化音色,其青少年声线适配多数家居场景,而当前市面的超拟真方案在离线部署时仍存在延迟过高、情感韵律不自然等瓶颈。这种技术碎片化现状,本质上反映了智能家居领域多模态交互的深层挑战。
嘉宾继续分享智能家居场景目前存在的技术卡点:
语音大模型能否加入对声音远近的建模?
语音大模型能否加入声纹识别(例如针对老人和儿童用户)?
需要注意的是,魔鬼往往在细节中。智能家居所在的家庭场景高度复杂,家具摆放不同会造成声音的遮挡。要实现上述功能对技术的要求极高,不能类比理想汽车的解决方案——因为汽车总是固定的。
针对上述技术卡点,阶跃星辰 StepAudio 团队和智谱团队回应道:
智谱 GLM-Voice 团队:我们也正在努力尝试中,对于这个问题,级联方案方案可能比再训一个大模型更好。
阶跃星辰 StepAudio 团队:和 ToB 厂商做项目需要模型嵌入系统和适配系统,而系统本身有一些定制化的定制化的需求,需要模型高度配合迭代和优化。通用的基础模型如何和应用去打通,去做深度定制这也是一个难题。
保险外呼
一位来自头部保险公司的语音团队负责人分享道:
○车牌号识别需突破同音字歧义难题(如"贵 A·B123"需精准区分"贵州"与"贵阳"归属地),并实现多语言混合识别(如中英文车牌混编场景);
○车型核验则要求 ASR 系统在噪声环境下准确捕捉复杂专业术语。
当前市面通用 ASR 方案存在显著缺陷——既缺乏保险领域的声学模型优化,又缺失针对车牌核验场景的专用语言模型,导致关键字段识别准确率不足。
更严峻的是环境干扰问题:VAD 模块在多人对话场景(如报案人同时与家属交流)及背景噪声(如交通事故现场的环境音)中频繁失效,造成有效语音截取率下降。
我们的语音通话使用的是 8K 采样率,TTS 的超拟人音色完全体现不出来优势。我们目前的需求是体现 TTS 的超拟人音色的优势,并且处理多人说话、环境音的处理。
HR 外呼
一位来自头部猎头公司的技术负责人分享道:
我们公司的业务很多,偏个性化的低端招聘场景,比如外包类业务,需要几百人在打重复性电话,而且还是时长 5 分钟以上的长时需求。
有时候,我们的 HR 没有特别的提问脚本,所以在提问时需要储备很多知识,而且候选人有时候反问的问题又比较随机,需要访问外部知识库,做微调或适应。
我们认为目前语音助手需要多解决一些个性化问题,个别特殊的 corner case 可以转人工接入。
2.2 To C 场景:
播客类
某 AI 播客创始人分享:
目前我们的产品以 TTS 为主,而卡点是不够自然,表演的成分过高。
现在市面上的产品缺少一些含有 “嗯、啊” 等口语化表达、能代表人类真实情绪的产品,而且没有看到过双人交互的 Voice Agent。
未来一半内容是 AI 合成的,目前在 To C 场景遇到的卡点是音色。自带声音局限在游戏场景,cover 不了电话外呼。这些外呼场景依赖克隆技术,但是只能克隆几十秒的音频,没法泛化。如果输入是一个激动的情绪,克隆出来还会一直保留激动的情绪。
数字人
○也有嘉宾分享,在我们的数字人业务中,语音通话在请求量中占比 50%。但我们遇到的问题是语音通话质量很差。我们之前用 benchmark 评测的时候语音模型的时候效果还行,但实际上人耳都可能分不清,方言口音非常多、录音质量很差。ASR 识别准确率极大影响模型效果,目前的最大痛点是 SER(Sentence Eror Rate,句错率),仍在想办法优化中。
2.3 商业模式:价格战与收费模式的演变
一位与会嘉宾分享:
行业价格体系演变: 中国 AI 呼叫行业历经八年发展,定价模式发生结构性变化。早期采用"订阅费 + 话费"双轨制,2018 年单个 AI 坐席年费高达 1.2 万元,而当前市场已降至 3800 元/3 坐席/年,降幅达 90%。订阅费从初始的 1-2 万元/年剧烈下滑至 2-3 千元/年,话费定价更已渗透至供应链环节,某些场景下需要预付 200 万元方能启动折扣谈判。
成本结构与利润重构:现行业核心利润源于通信调用费,单通电话向甲方收取 0.15 元,实际成本 0.07 元,利润率 53%(单通净利 0.08 元)。相较传统人力呼叫中心,AI 系统通过将技术价值嵌入通信链路实现了成本重构。当前企业可能需需达到大几千万年营收方可实现盈亏平衡。
未来商业模式展望:价格战的本质源于供给过剩与技术内卷,头部企业通过工程优化争取 1-2 年转型窗口。行业呈现两大趋势:订阅制或将消亡,欧美市场已全面转向按量付费;金融机构入场可能加速利润摊薄,倒逼企业建立常态化价格机制。存活关键在于持续提升对话体验,构建差异化技术壁垒。
另一位与会嘉宾进行了总结:
总体而言,效率是议价指标,平台开放性决定效率。例如,如果一家 Voice Agent 公司接入硅基流动平台,理论上就有可能可以接所有的模型进行收费。
技术架构演进:端到端模型与场景适配的博弈
[ ] 级联方案(ASR+LLM+TTS)因灵活性和低成本仍占主流,但端到端模型(Voice-to-Voice)凭借长上下文和语义包容性逐渐崛起。智谱 MaaS 的实时感知、推理多商、输出模块整合,以及 Soul 的全双工语音系统,验证了端到端架构在拟人化和低延迟上的潜力。技术选型需结合场景需求——情感陪伴须语义连贯,智能家居须毫秒级响应,而保险外呼依赖 ASR 精准纠错。
数据集与模型能力:多模态融合是破局关键
[ ] 语音、视频数据量不足(如 TTS 仅百万小时级)制约端到端模型发展,需通过多模态数据融合(如 Soul 的语音 + 文本 + 用户行为)提升泛化性。方言处理依赖高质量标注数据与 LLM 合成能力结合,如阶跃星辰通过少量标注 +LLM 泛化实现低成本方言适配。
效果评估:拟人度与用户感知的平衡,用户需求与技术创新双向驱动当前指标(SER、TTS 自然度)与用户需求存在偏差,需建立以拟人度为核心的综合评估体系。例如,Soul 的虚拟人因情绪价值留存用户,而智能家居场景需平衡 TTS 拟真与离线部署成本。
[ ] Soul 通过 AI 虚拟人解决社交资源失衡,验证 “情绪价值真实存在”;智能家居企业因用户指令多样性启动自研 VAD。技术限制(如 ASR 字错率)倒逼数据增强(用含错数据集训练)和混合方案(级联 + 端到端),形成需求 - 技术闭环。
场景驱动技术定制:碎片化需求倒逼创新
[ ] To B 场景:智能家居需私有化 VAD 方案(如区分指令与情感修饰),保险外呼需 ASR 抗噪与专业术语优化,HR 外呼依赖动态知识库调用。
[ ] To C 场景:情感陪伴强调开放域对话,数字人须端云协同降本,播客类产品探索口语化表达与双人交互。
商业模式重构:从订阅制到价值嵌入
[ ] 价格战推动行业转向按量付费(如单通电话净利 0.08 元),利润源于技术嵌入通信链路。未来存活需差异化壁垒——智谱通过开放平台吸引开发者,Soul 以虚拟人社交沉淀用户关系,头部企业通过工程优化(如 ASR 纠错时延压缩)争夺转型窗口。
在这里,我们也特别介绍几款最新开源的 Voice Agent 工作,欢迎大家体验:
1、Sesame:开源语音生成模型 CSM-1b
近期,开发虚拟助手 Maya 的 Sesame 团队搞了个大新闻——开源了全新语音生成模型 CSM-1b。CSM-1b 能根据文本和音频输入直接生成 RVQ 音频代码(Residual Vector Quantization),目标是实现真正的"语音在场感(voice presence)",让 AI 对话像真人唠嗑一样自然。
功能亮点
1️⃣ 情感读心术:通过语义 + 韵律双雷达(Emotional Intelligence),精准捕捉对话中的情绪暗流
2️⃣ 接话王者:300ms 极速响应(Conversational Dynamics),连停顿、抢话都模仿得惟妙惟肖
3️⃣ 记忆大师:基于 Transformer 的跨轮对话跟踪(Contextual Awareness),实时调整音色和语气
4️⃣ 人格不精分:用对抗训练(adversarial training)锁死固定人设(Consistent Personality)
技术架构揭秘
传统 TTS 系统总被吐槽"机械音",问题就出在 RVQ 技术——虽然能把语音拆成语义标记(semantic tokens)和声学标记(acoustic tokens),但建模韵律像开盲盒,延迟还属于较高水平。
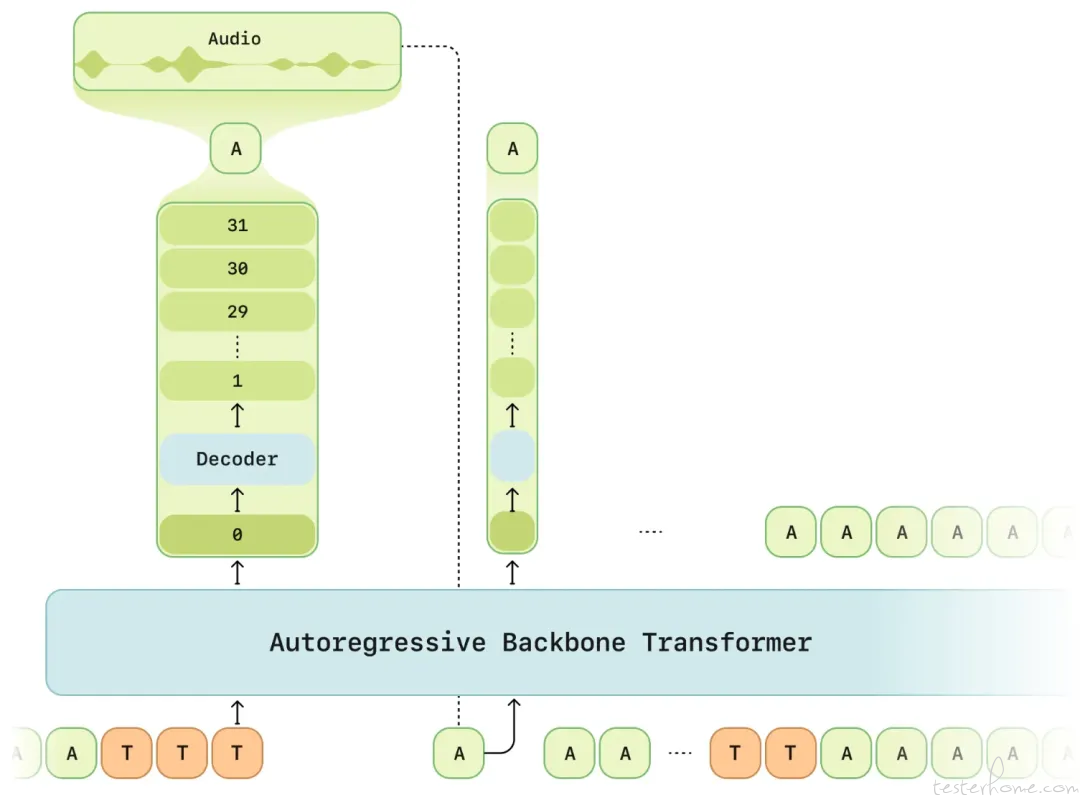
CSM 模型的关键组成架构包括:
多模态大脑(Backbone):同时处理文本 + 语音标记,专注预测编码簿第 0 层。
闪电解码器(Decoder):基于第 0 层结果,并行生成剩余 31 层编码簿。
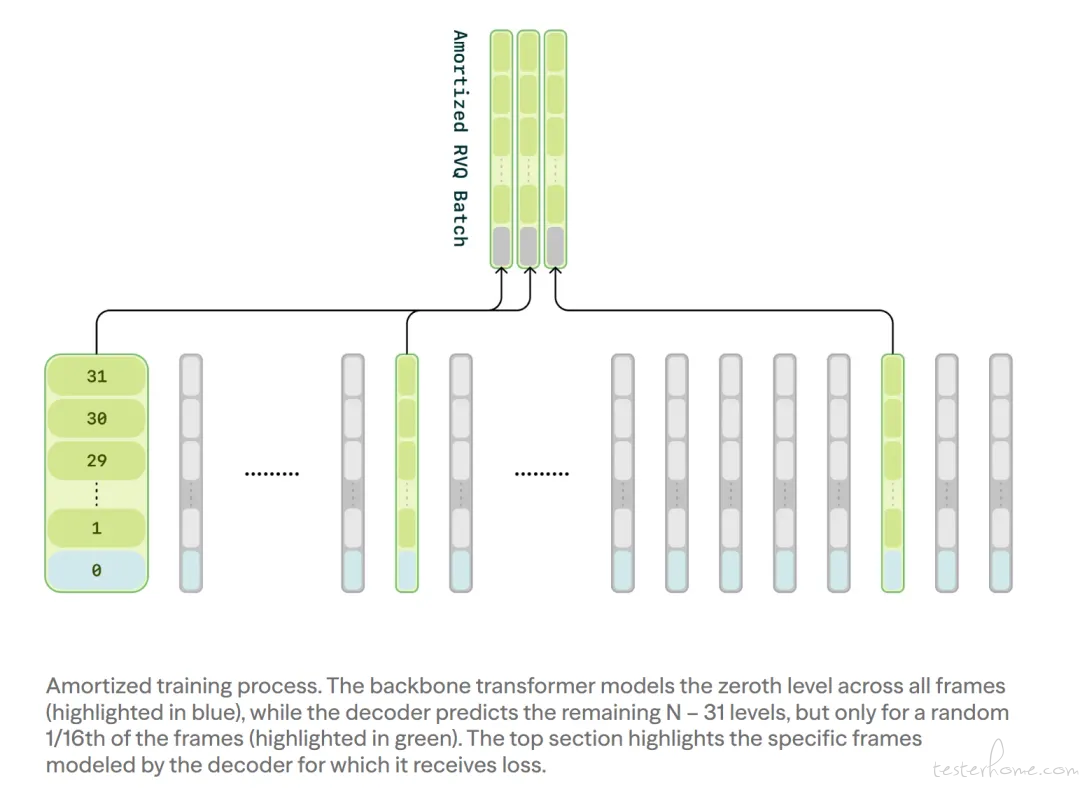
配合独创的计算分摊策略(compute amortization),训练时只需处理 1/16 语音帧,内存直接砍掉 83%,音质居然不打折。
实测数据
训练数据:100 万小时英语对话(≈114 年不间断聊天)
提供三种不同量级的版本: Tiny 版:10 亿参数主干 +1 亿解码器 Small 版:30 亿 +2.5 亿 Medium 版:80 亿 +3 亿
所有模型用 2 分钟长音频(2048 序列)训练 5 轮,首次音频生成时间(time-to-first-audio)低于传统 RVQ 方案。
模型:https://www.modelscope.cn/models/sesameAILabs/csm-1b
CSM-1B 体验链接:https://modelscope.cn/studios/sesameAILabs/csm-1b/summary
Sesame 官网:https://www.sesame.com/research/crossing_the_uncanny_valley_of_voice
2、Canopy Labs:开源 TTS 模型 Orpheus
近期,Canopy Labs 全新开源 TTS 模型 Orpheus。Orpheus 以其接近人类的自然情感表达、超低延迟的实时输出以及强大的零样本语音克隆能力,迅速成为开源社区关注的焦点。
不仅能生成流畅自然、充满情感的声音,还将延迟压缩到令人惊叹的 25-50 毫秒,完美适配实时对话场景。
功能亮点
1️⃣ 情感影帝:只需几十条标注样本,就能让 AI 秒变哭腔/慵懒/叹息(Guided Emotion)。
2️⃣ 声纹复印机:零样本语音克隆(Zero-Shot Voice Cloning)直接封神,听过一次的声音立刻复刻。
3️⃣ 闪电嘴速:将延迟压缩到 25-50 毫秒,实现超低延迟实时流式推理(realtime streaming),文本能够边输边播。技术架构揭秘
传统语音 LLM 总被 SNAC 解码器(SNAC Decoder)的"爆音跳帧"困扰?Orpheus 提出了两大反传统设计:
扁平化序列解码:7 帧 token 平铺处理,可实现单线程输出。
防爆音滑窗:CNN-based tokenizer+ 魔改解码头,可实现流式播放。
实测数据
训练数据:10 万小时语音 + 数十亿文本 token。提供四种不同量级的版本: Medium 版:30 亿参数 Small 版:10 亿 Tiny 版:4 亿 Nano 版:1.5 亿

在线 Demo:
https://huggingface.co/spaces/MohamedRashad/Orpheus-TTS
GitHub 项目地址:
https://github.com/canopyai/Orpheus-TTS
3、OpenAI:Speech-to-Text & Text-to-Speech Model
近期,OpenAI 发布了三款全新语音模型:语音转文本模型 GPT-4o Transcribe 和 GPT-4o MiniTranscribe,以及文本转语音模型 GPT-4o MiniTTS。这些模型都提供了 API 的接入方式,用户也可以直接点击下面链接 Build 属于自己的 Voice Agent。
OpenAI 开发者平台:https://www.openai.fm/
3.1 Speech-to-Text Model: GPT-4o Transcribe
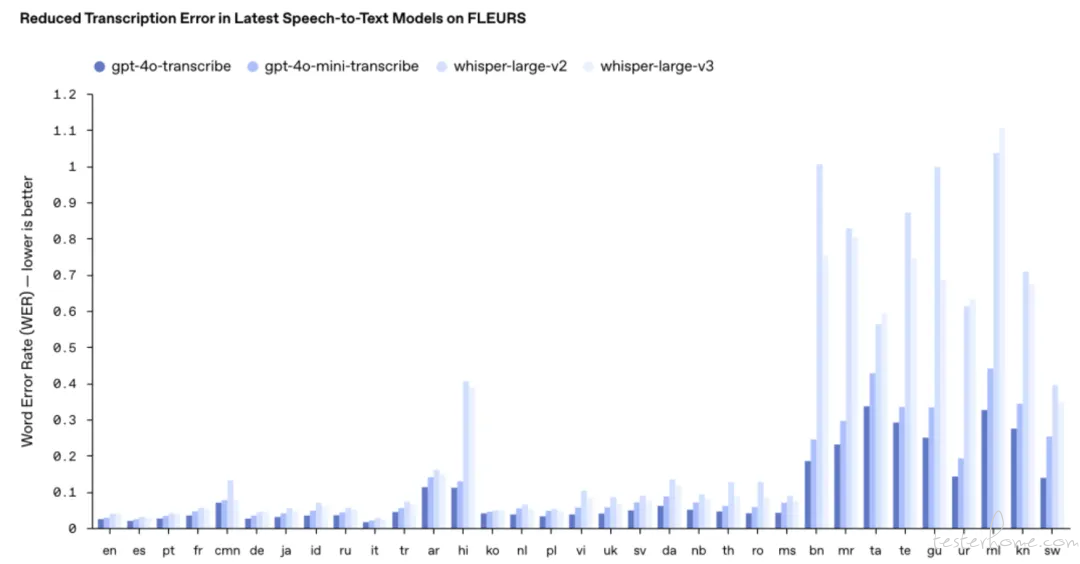
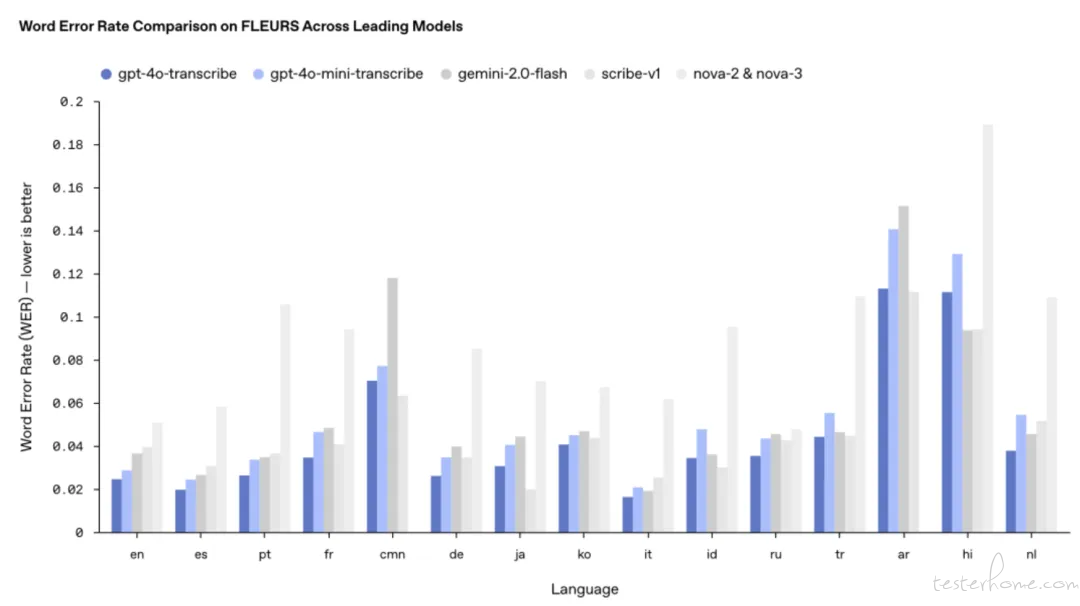
近期,OpenAI 推出全新语音转文本模型 GPT-4o Transcribe,基于 GPT-4o 技术构建。该模型在多项基准测试中全面超越现有 Whisper 系列,凭借更低的词错率(WER)和强大的多语言处理能力,重新定义了语音识别的精度标准。尤其在口音识别、噪声环境适应和语速变化处理等复杂场景中表现卓越,现已正式开放 API 接入。
核心优势
1️⃣ 精准转录专家:通过强化学习创新与高质量数据集训练,显著提升对语音细微差别的捕捉能力,误识别率大幅降低。
2️⃣ 多语言通才:在覆盖 100+ 语言的 FLEURS 基准测试中,词错率全面优于 Whisper v2/v3,展现更强转录准确性与语言包容性。
3️⃣ 场景适应王者:专为复杂场景优化,对口音、环境噪声、语速变化的鲁棒性显著增强
技术突破
定向强化学习:针对语音识别痛点进行算法优化。
数据引擎升级:采用多样化高质量音频数据集进行中期训练。
基准测试统治力:在所有语言评估中持续领先 Whisper 系列。
亲民定价
性能实证
评测基准:FLEURS 多语言语音基准(含 100+ 语言人工标注样本)。
关键指标:词错率(WER)全面领先行业标杆。
核心价值:相同价格提供更精准、更可靠的转录服务。
体验链接:https://platform.openai.com/docs/models/gpt-4o-transcribe
Demo:https://openai.com/index/introducing-our-next-generation-audio-models/
3.2 Speech-to-Text Model: GPT-4o Mini Transcribe
除了 GPT-4o Transcribe,OpenAI 也推出轻量级语音转文本模型 GPT-4o mini Transcribe,基于 GPT-4o mini 技术构建。该模型在保持高性价比的同时,词错率(WER)和语言识别准确率均显著超越原版 Whisper 系列,为用户提供更精准、更可靠的转录体验。
核心优势
1️⃣ 精准升级:词错率(WER)全面优化,转录准确度超越原版 Whisper 模型。
2️⃣ 多语言增强:提升语言识别能力,适应更广泛的语音场景。
3️⃣ 高性价比:以更低成本提供更优性能,适合高效转录需求。更低定价 GPT-4o-mini-transcribe:$0.003/分钟(性价比之选)。
体验链接:https://platform.openai.com/docs/models/gpt-4o-mini-tts
3.3 Text-to-Speech Model: GPT-4o mini TTS
OpenAI 全新发布 GPT-4o mini TTS 语音合成模型,首次实现"说话方式自由编程"——开发者不仅能指定说什么,更能精准控制怎么说(steerability),为客服到创意叙事等场景打造定制化语音体验。
功能亮点
1️⃣ 声线调音台:实时调节口音(Accent)、语调(Intonation)、语速(Speed)等 10+ 参数,支持耳语(Whispering)、模仿(Impressions)等特殊效果。
2️⃣ 闪电输出:专为实时场景优化,延迟低至行业领先水平,支持 2000token 长文本输入。
3️⃣ 声库全家桶:内置 11 种预设音色(Voice Options),包含 alloy、nova、echo 等风格,英语适配度拉满。
技术架构
突破传统 TTS 模型只能固定输出的限制:
多维度控制协议:通过 prompt 指令直接操控情感范围(Emotional range)、音调(Tone)等声学
特征双模型策略:
[ ] tts-1:低延迟优先,适合实时交互。
[ ] tts-1-hd:高保真优先,适合影视级音效。
实测数据:
基础模型:基于 GPT-4o mini 语言模型,速度与性能双优。
语音实验室:OpenAI.fm 提供在线试玩,一键体验最新音色黑科技。

体验链接:https://platform.openai.com/docs/models/gpt-4o-mini-tts
4、x.AI: 发布多音色 + 多性格的 Grok
近期,马斯克旗下人工智能公司 xAI 正式推出 Grok Voice 实时语音交互模式。作为 xAI 开发的对话式人工智能助手,Grok 凭借其突破传统的内容审查机制和自由开放的对话风格广受用户青睐。本次发布的语音模式延续该特色,其标志性"失控模式"(Unhinged Mode)支持用户进行包含俚语的非传统对话,开创性地实现人工智能与人类的无障碍深度互动。
基础语音模式
Ara 🎤:充满活力的女性声线,传递阳光能量。
Rex 🎧:沉稳冷静的男性声线,理性对话首选。
人格化角色模式
Best Friend 👯♀️:随和亲切的聊天伙伴,随时陪你唠嗑。
Unhinged 🤪:脑洞清奇的叛逆智者,专治思维定式。
Genius 🧠:卡尔·萨根附体的知识宝库,张口就是宇宙真理。
Romantic 🌹:狂野大胆的撩人高手,情话技能点满。
Stoner 🍃:慵懒佛系的生活家,带你发现日常小确幸。
技术亮点:
✅ 声纹与人格深度绑定,实现「声音即人设」。
✅ 支持实时动态切换,适配不同社交场景。 🔥 现已开放 API 接入,开发者可定制专属语音交互体验。
5、TEN:快速构建实时多模态 AI AgentTEN
是一款实时对话式语音 Agent 引擎,旨在帮助开发者快速构建具备音视频交互能力的 AI Agent。目前,TEN 已支持包括 Deepseek、OpenAI、Gemini 在内的全球各大主流 STT、LLM、TTS 厂商。此外,TEN 还可无缝接入 Dify 和 Coze,只需配置 Bot ID/API 即可轻松赋予您的 Bot 语音能力。
TEN 的主要优势
多模态传输: 支持语音、文本和图像的输入与输出,充分发挥多模态优势。同时支持级联模式(STT-LLM-TTS)与端到端模式 (End-to-End),助力打造卓越的音视频交互体验。
低延迟、可打断: 内置优化的实时通信能力,提供低延时、可打断的交互体验。TEN 内置 RTC 技术,有效解决语音交互中的延迟问题。基于 TEN Framework 搭建的 Agent,在最佳优化情况下延迟仅为 650ms。同时,自带 VAD 功能,允许用户在与 AI 语音交流过程中随时打断,还原真实自然的对话体验。
插件丰富、灵活编排: 支持接入全球主流的 STT、LLM 和 TTS 服务,方便开发者快速利用最新技术。TEN 已支持全球主流 STT、LLM、TTS 等插件,只需配置 API 密钥即可及时跟进最新技术进展,例如,已在 24 小时内完成对 OpenAI Realtime API、Gemini 2.0 的接入。
多语言、跨平台:支持多种主流编程语言,Agent 可跨平台无缝衔接。TEN 支持 C++/Go/Python/Node.JS 等多种编程语言(即将支持 JavaScript),并支持 Agent 在 Windows/Mac/Linux/移动端等平台上的跨平台使用。
快速体验:
https://agent.theten.ai/
本地部署:
https://github.com/TEN-framework/TEN-Agent
—end—
作者:尹顺顺、Cythina Yang、贾世坤、及 Z 沙龙全体 40 位嘉宾
主持人:严宽
整理及编者:陈薇冰、傅丰元、严宽
审阅:邓瑞恒

更多 Voice Agent 学习笔记:
a16z 最新报告:AI 数字人应用层即将爆发,或将孕育数十亿美金市场丨 Voice Agent 学习笔记
a16z 合伙人:语音交互将成为 AI 应用公司最强大的突破口之一,巨头们在 B2C 市场已落后太多丨 Voice Agent 学习笔记
ElevenLabs 33 亿美元估值的秘密:技术驱动 + 用户导向的「小熊软糖」团队丨 Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent 丨 Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
a16z 最新语音 AI 报告:语音将成为关键切入点,但非最终产品本身(含最新图谱)
对话式 AI 硬件开发者都关心什么?低延迟语音、视觉理解、Always-on、端侧智能、低功耗……丨 RTE Meetup 回顾

