
大家好~这是 Voice Agent 学习笔记系列的第二十五篇。我是课代表十三🧑💻。
过去几年,AI 已经能生成逼真的图片、视频和声音,悄然通过视觉和听觉的图灵测试。但 2025 年最令人激动的突破之一,毫无疑问将是把这些方案集于一体的 AI 数字人(Al Avatar)。
结合 GPT-4o 吉卜力风格生成和 Hedra 制作的主播数字人,在 X 上获得了 231 万次观看。
今年 2 月,字节跳动推出的 OmniHuman-1 模型在全球 AI 圈掀起了巨浪。仅需一张照片和一段音频,即可生成具有动态背景、支持全身动作,且口型同步的逼真 AI 视频。
这些不再令人感到「恐怖」的 AI 角色,正以惊人的速度走出「恐怖谷」,并开始全面渗透到内容创作、广告营销、企业培训等多个领域。这不仅是人工智能技术的一次飞跃,更是内容产业的一次重要转变。
近期,a16z 发布了关于 AI Avatar 数字人的最新报告,详细介绍了数字人的研究进展、构成要素以及未来发展应用。报告中,Agora、ElevenLabs、字节跳动的 OmniHuman 等技术被列为核心要素技术能力。
报告预测:「底层模型的技术水平已经显著提升,AI 数字人应用层将迎来快速发展的机遇,我们预计该领域将孕育出多个价值数十亿美元的公司。」
我们翻译了该报告的全文,希望能为大家带来新的见解。阅读愉快!
AI Avatars Escape the Uncanny Valley

Justine Moore
作者介绍:Justine Moore 是 Andreessen Horowitz 消费者投资团队的合伙人,专注于人工智能公司投资。
当 AI 不仅是内容的制造者,而化身为内容本身,会带来怎样的变革? 人工智能已经掌握了生成逼真照片、视频和声音的能力,通过了视觉和听觉图灵测试。下一个重大飞跃是 AI 数字人:将面部与声音结合,创造出一个会说话的角色。
难道不能直接生成人脸图像、制作动画并添加配音吗?不尽然。挑战不仅在于实现口型同步,更在于确保面部表情和肢体语言的协调一致。 如果嘴巴张大表示惊讶,但脸颊和下巴纹丝不动,就会显得非常不自然。而且,如果一个声音听起来很兴奋,但对应的脸部却没有相应的反应,这种类人幻觉就会立刻破灭。
我们已经在该领域看到了显著进展。AI 数字人正逐步应用于内容创作、广告宣传和企业内部沟通等场景。目前的技术主要表现为「会说话的头像」,虽然具备基本功能,但很有限。不过,近几个月我们观察到一些令人鼓舞的突破,预示着该技术领域将迎来更为实质性的发展。
在本文中,我们将根据 20 多款 AI 数字人产品的实际测试结果,深入分析当前 AI 数字人技术的发展现状,探讨其未来发展趋势,并重点介绍当前市场上备受瞩目的相关产品。
「我测试了超过 20 款用于创建 AI 角色的产品。 作为一个多年来持续体验这些工具的人,我对现在能够实现的效果感到非常震撼。」
AI 数字人是一个极具挑战性的研究课题。为了生成逼真的「会说话的脸」,模型需要学习精确的「音素 - 视素」映射关系,也就是语音中的音素与对应的口型动作(视素)之间的关联。如果这种映射关系出现偏差,就会导致口型与声音不同步,甚至完全分离,影响用户体验。
更复杂的是,说话时不仅仅是嘴部在运动。面部其他肌肉、上半身,甚至有时手部也会协同运动。而且,每个人都有其独特的说话习惯和风格。不妨比较一下你和喜欢的名人说话的方式:即便说着相同的句子,嘴部的动作也会存在差异。如果将你的唇动强行匹配到对方的脸上,效果会显得非常不自然。
近年来,这一领域的研究取得了显著进展。我查阅了自 2017 年以来的 70 余篇关于「会说话的 AI 头像」论文,清晰地观察到模型架构的演变历程:从最初的卷积神经网络(CNN)和生成对抗网络(GANs),发展到基于 3D 技术的方法,例如神经辐射场(NeRFs)和 3D 形变模型,再到 Transformer 和扩散模型,以及最新的基于 Transformer 架构的扩散模型(DiT)。下面的时间轴展示了历年来被引用次数最多的相关研究论文。
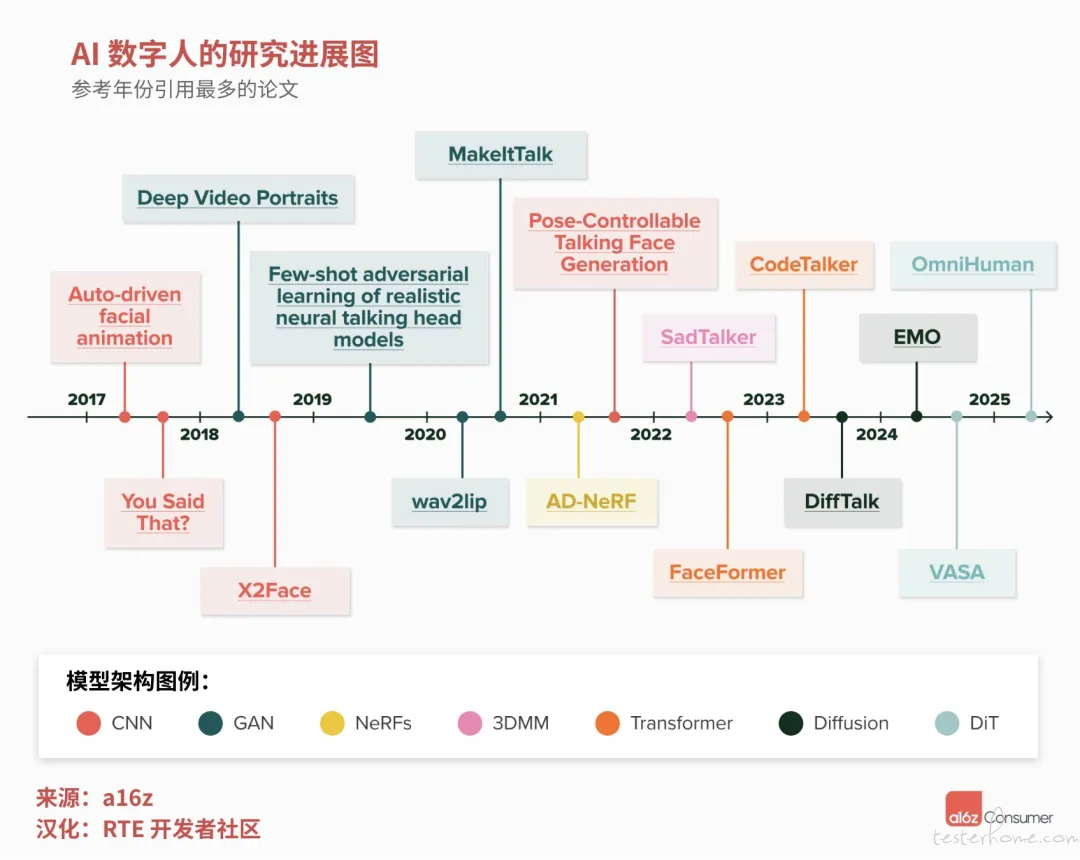
AI 数字人研究进展图
可见,生成的质量和模型性能都得到了显著提升。早期的技术手段较为局限,例如,仅使用单张人物照片,遮盖其面部下半部分,然后根据音频输入中提取的面部特征点来生成新的口型动作。这些模型依赖于数量有限的高质量唇形同步数据进行训练,而这些数据大多是对人脸进行近距离裁剪得到的。为了实现更逼真的效果,比如让奥巴马的头像进行唇形同步,则需要数小时的奥巴马视频素材,并且输出的动作也受到很大限制。
如今的模型在灵活性和功能性上都得到了极大的提升。它们可以在同一视频中生成半身甚至全身运动、逼真的说话表情和动态背景。这些新型模型更像是在更大的数据集上进行训练的、传统的文本到视频模型,采用多种技术手段来确保在复杂的运动场景中唇形同步的精确度。
字节跳动于二月份推出的 OmniHuman-1 模型,首次体现了这种发展趋势(该模型近期已在 Dreamina 平台上线)。该领域的技术迭代速度非常快—— Hedra 公司在三月份发布了 Character-3 模型 ,经过我们的一对一对比测试,该模型在大多数应用场景中都表现出最佳性能。Hedra 模型也适用于非人类角色,例 「会说话的 Waymo」 ,并且允许用户通过文本输入来控制角色的情绪和动作。
一张初始图像帧和一段音轨生成。其中,角色的唇形同步、面部表情以及上半身动作均由 Hedra 模型生成。请注意观察,背景中的角色也能够自然地活动。
AI 数字人的应用案例数不胜数——无论是角色互动,还是讲解视频,都能看到它们的身影。目前,我们已经观察到 AI 数字人在消费者、中小型企业乃至大型企业等多个领域都得到了广泛应用。

AI 数字人市场概览
这是 AI 数字人市场的早期概览图。这一领域发展迅速,各产品之间的界限还比较模糊。理论上,许多产品都具备为上述大部分甚至所有应用场景创建虚拟形象的能力,但我们发现, 在实际应用中,很难构建完善的工作流程并对精细调整模型,使其在所有领域都表现出色。 下面,我们将分别介绍各个细分市场如何利用 AI 数字人的具体案例。
消费者领域:角色创建
现在,任何人都可以仅凭一张图像就能创建出动画角色,这极大地释放了创造力。对于那些希望利用人工智能来讲述故事的普通用户来说,这项技术的重要性无论如何强调都不过分。早期的人工智能视频之所以常被批评为「图片幻灯片」,原因之一就是缺乏会说话的角色,或者仅以旁白形式呈现语音内容。
当内容中的角色能够开口说话时,其趣味性将大幅提升。除了传统的叙事视频外,这项技术还能应用于创作 AI 主播、播客节目,以及音乐视频等多种形式的内容。 Hedra 平台允许用户仅凭借一张初始图片以及一段音频或文字脚本,即可生成生动且能说话的虚拟角色。
如果你的素材是视频而非图片,可以使用 Sync 工具实现唇形同步,使角色面部表情与音频内容精准匹配。 若希望通过捕捉真人表演来驱动虚拟角色的动作,则可以借助 Runway Act-One 和 Viggle 等工具实现。
我很喜欢的一位使用 AI 制作动画角色的创作者是 Neural Viz,他的系列作品 The Monoverse 构想了一个后人类时代,其中居住着名为 Glurons 的生物。 如今,技术门槛已大幅降低,相信在不久的将来,我们将看到大量由 AI 生成的节目,甚至是独立的虚拟网红涌现出来。
随着数字人的实时流式传输变得更加便捷,我们也希望看到面向消费者的公司将它们作为用户界面的核心部分。 试想一下,通过一位实时的 AI「教练」来学习语言,这位「教练」不再仅仅是冰冷的语音,而是一位拥有生动面容和独特个性的完整角色。 像 Praktika 这样的公司已经开始探索这种模式,并且随着技术的不断发展,交互体验将会变得更加自然流畅。
中小企业领域:潜在客户开发
广告已然成为 AI 数字人的首要应用场景之一。 企业现在无需雇佣演员和组建制作团队,即可利用高度逼真的 AI 角色来推广产品。 Creatify 和 Arcad 等公司提供了便捷的解决方案:只需提供产品链接,它们便能自动生成广告,包括撰写脚本、选择辅助素材和图片,以及「启用」一位 AI 虚拟演员。
这为以往无力负担传统广告制作成本的企业提供了广告营销的新途径。 尤其在电商、游戏和消费类应用领域,这种方式广受欢迎。 相信你已经在 YouTube 或 TikTok 等平台上看过由人工智能生成的广告。 目前,B2B 企业也开始探索这项技术,利用 AI 数字人进行内容营销,或借助 Yuzu Labs 和 Vidyard 等工具实现个性化的客户拓展。
许多此类产品将 AI 演员(无论是真人克隆形象还是原创角色)与产品照片、视频片段、音乐等其他素材相结合。 用户既可以自定义这些素材的位置,也可以选择「自动模式」,让系统自动将它们组合成视频。 脚本方面,用户可以选择自行编写,也可以使用 AI 自动生成的版本。
大型企业领域:内容扩展
除了营销领域,企业还在探索 AI 数字人的诸多应用场景。 接下来举几个例子:
员工学习与提升: 大多数大型企业都会为员工制作培训和教育视频,内容涵盖入职引导、合规培训、产品教程和技能提升等多个方面。 Synthesia 等 AI 工具能够自动化这些流程,提高内容制作效率和规模化能力。 某些岗位还需持续进行基于视频的培训。 比如,可以想象一下,销售人员使用 Anam 等产品的 AI 数字人练习谈判技巧的场景。
全球拓展和本地化: 如果企业面向不同国家或地区的客户和员工,可能需要将内容翻译成当地语言,并替换其中的文化元素。 AI 数字人可以快速便捷地实现视频内容的个性化定制。 借助 ElevenLabs 等公司提供的 AI 语音翻译技术,企业能够以数十种语言生成相同的视频,并配以自然流畅的语音。
高管形象塑造: AI 数字人让高管们可以通过克隆自身形象来为员工或客户创建个性化内容,从而提高他们的影响力。企业无需为每次产品发布或感谢致辞都进行拍摄,而是可以生成一位逼真的 CEO 或产品负责人 AI 数字人分身。Delphi 和 Cicero 等公司也在积极探索,让行业领袖能够更便捷地与以往难以直接接触的人群进行 1 对 1 的互动和疑问解答。
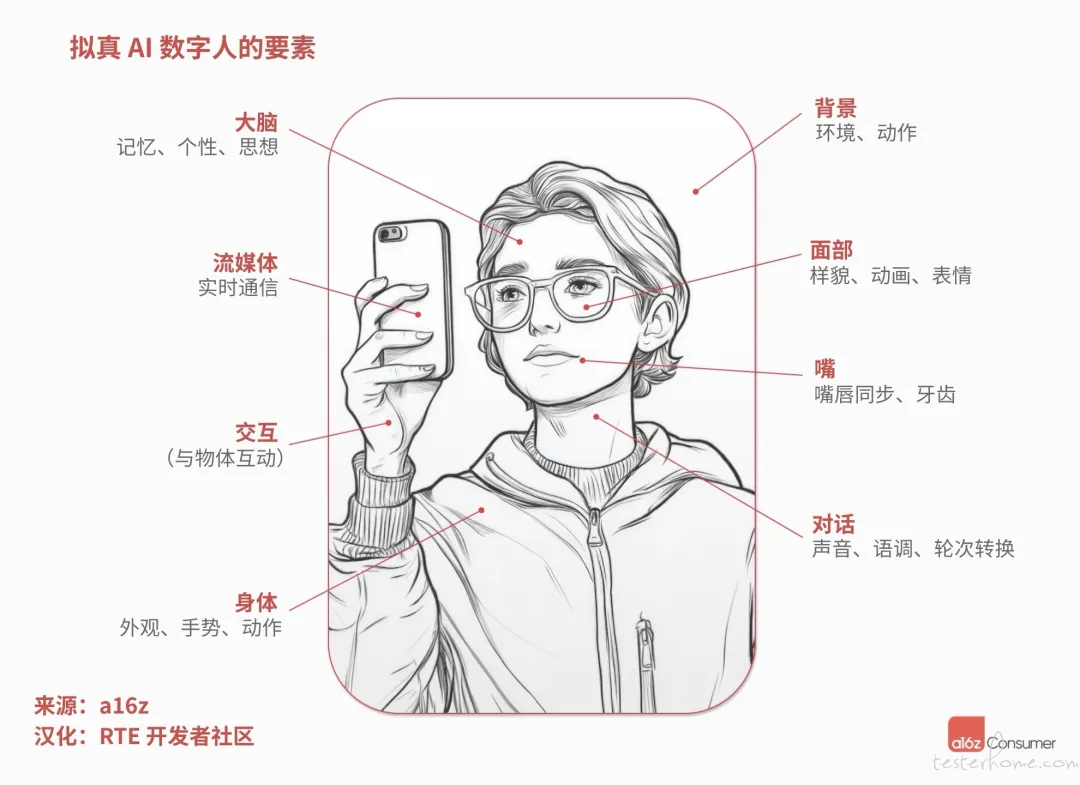
打造一个逼真可信的 AI 数字人极具挑战性,每个细节的真实性都面临着各自的技术难题。 这不仅仅是避免陷入「恐怖谷效应」,更需要解决动画制作、语音合成和实时渲染等领域的基础性问题。 下面我们将详细分析一个逼真 AI 数字人所需的技术要素、其难点所在,以及当前取得的进展:
面部: 无论是克隆现有人物,还是创建全新角色,都需要保证面部在不同帧之间的连贯性,并且在说话时呈现真实的动态。 目前,上下文感知的表情表达仍是一大挑战(例如,当虚拟形象说「我累了」时,能够自然地打哈欠)。
声音: 声音必须听起来真实,并且与人物角色相匹配。例如,一位少女的形象不应配以老年女性的声音。 我们接触过的大部分 AI 数字人公司都在使用 ElevenLabs,该公司拥有庞大的语音库,并支持用户克隆自己的声音。
唇形同步: 实现高质量的唇形同步非常困难。 许多公司,如 Sync 都致力于解决这一问题。 其他模型,例如 Meta 的 MoCha 和字节的 OmniHuman,则基于更庞大的数据集进行训练,并采用多种技术,根据伴随音频精确地控制面部生成过程。 这些模型通过在海量数据上训练,找到了根据音频信息有效控制面部帧生成的方法。
身体: 数字人不能仅仅是漂浮的头部! 新的模型已经能够生成具有完整身体,并能进行动作的数字人。 然而,在规模化应用以及将这些技术交付给用户方面,我们仍处于早期探索阶段。
背景环境: 虚拟形象并非独立存在。 周围环境的光照、景深以及交互效果,都需要与场景相协调。 理想情况下,数字人甚至应该能够与环境中的物体进行互动,例如拿起某个产品。
如果希望数字人能够参与实时对话,例如加入 Zoom 会议,还需要额外考虑以下几点:
大脑(智能): 数字人需要具备「思考」能力。 目前支持对话的产品通常允许用户上传或连接至知识库。 未来,更高级的数字人将有望具备更强的记忆功能和独特的个性特征。 它们应该能够记住与用户的历史对话,并展现出自身的「风格」。
实时流传输: 以尽可能低的延迟传输所有这些数据并非易事。Agora 等产品正在努力解决这个问题,但要让所有这些模型协同工作,同时最大限度地降低延迟,仍然面临挑战。我们已经看到一些产品在这方面表现出色,例如拥有语音和面部的 AI 外星人伙伴 Tolan。 然而,这方面仍有很大的提升空间。
该领域仍有巨大的发展和改进空间。 以下是一些当前最受关注的重点方向:
角色一致性与形态转换
一直以来,AI 数字人通常采用单一、固定的「外观」,包括静态的服装、姿势和环境。 现在,一些产品开始提供更多样的选择。 例如,HeyGen 的角色 Raul 就拥有 20 种不同的外观!(见下方视频)然而,如果能够更轻松地根据用户的意愿自由变换虚拟形象,将会带来更好的体验。
更精细的面部动作与更丰富的表情
长期以来,面部一直是 AI 数字人的短板,往往显得僵硬和缺乏生气。 随着 Captions 推出的 Mirage 等新产品,这一状况正在得到改善,它们能够呈现更自然的外观和更丰富的表情。 我们期待 AI 数字人能够理解脚本的情感内容,并做出恰当的反应。 比如,当角色正从怪物手中逃脱时,能够表现出恐惧的神情。
身体动作
目前,大多数数字人的面部以下动作都非常有限,即使是基本的手势也难以实现。手势控制通常依赖于程序化的设定,例如 Argil 允许用户为视频的每个片段选择不同的肢体语言类型。 我们期待未来能够看到更加自然和智能的动作推断,让数字人的肢体语言更加生动。
与「现实世界 」互动
目前,AI 数字人还无法与周围环境互动。近期一个可行的目标是使它们能够在广告中展示产品。 Topview 在这方面已经取得了一些进展(请参考以下视频,了解他们的实现过程和效果),我们期待着随着模型技术的不断提升,能够实现更多互动功能。
更多实时应用
未来,AI 数字人将在实时互动领域拥有广阔的应用前景。 例如,我们可以与 AI 医生进行视频咨询,在 AI 销售助手的引导下浏览精选商品,或者通过 FaceTime 与我们喜爱的电视剧角色进行实时互动。 虽然目前在延迟和稳定性方面还无法完全达到真人水平,但已经非常接近了。 欢迎观看我与 Tavus 最新模型进行对话的演示。
过去几年,我们同时投资了基础模型公司和人工智能应用,得到的最大体会之一是:几乎不可能准确预测特定领域未来的发展方向。 然而,现在底层模型的技术水平已经显著提升,能够生成质量较高、观看体验较好的 AI 虚拟形象,因此可以肯定地说,应用层面将迎来快速发展的机遇。
我们预计该领域将孕育出多个价值数十亿美元的公司,其产品将根据不同的应用场景和目标客户进行细分。 例如,一位希望利用 AI 数字人来为客户录制视频的企业高管,对于质量和真实性的要求(以及愿意支付的费用)会高于一位制作自己喜爱动漫人物的短视频并分享给朋友的粉丝。
工作流程同样至关重要。 如果您希望利用 AI 形象生成广告,那么理想的平台应该能够自动提取产品详情,编写广告脚本,添加辅助镜头和产品图片,并将视频发布到您的社交媒体渠道,同时还能追踪和衡量广告效果。 另一方面,如果您希望使用 AI 角色来讲述故事,那么您应该优先选择那些能够保存和重复使用角色和场景,并能方便地将不同类型的片段拼接在一起的工具。
课代表留言:那,恐怖角色的数字人要不要跨越「恐怖谷」🤔

更多 Voice Agent 学习笔记:
a16z 合伙人:语音交互将成为 AI 应用公司最强大的突破口之一,巨头们在 B2C 市场已落后太多丨 Voice Agent 学习笔记
ElevenLabs 33 亿美元估值的秘密:技术驱动 + 用户导向的「小熊软糖」团队丨 Voice Agent 学习笔记
端侧 AI 时代,每台家居设备都可以是一个 AI Agent 丨 Voice Agent 学习笔记
世界最炙手可热的语音 AI 公司,举办了一场全球黑客松,冠军作品你可能已经看过
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布

