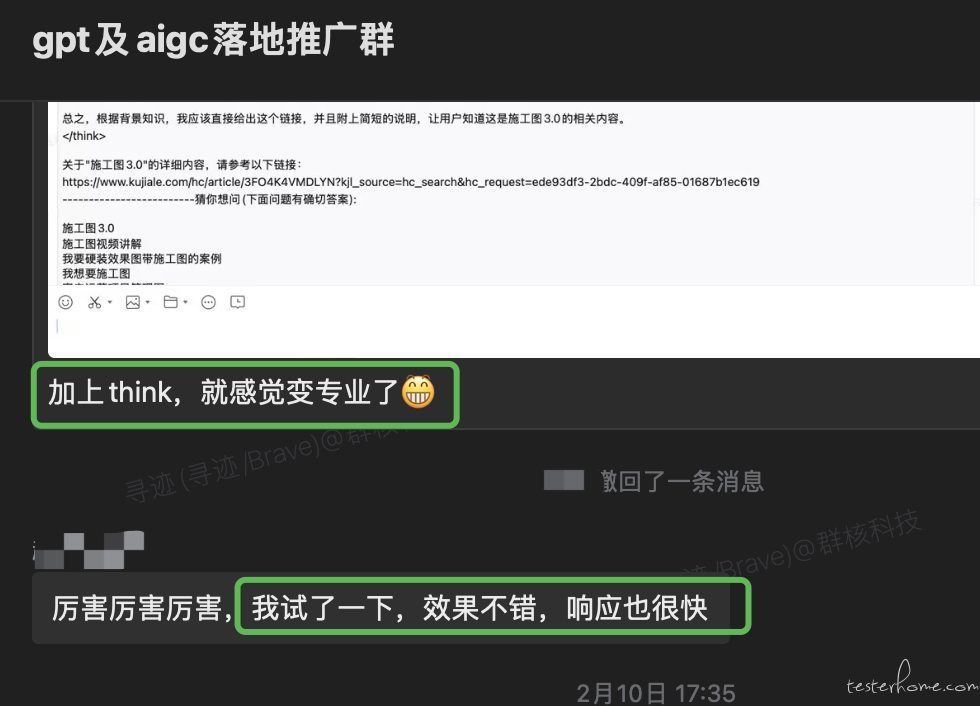
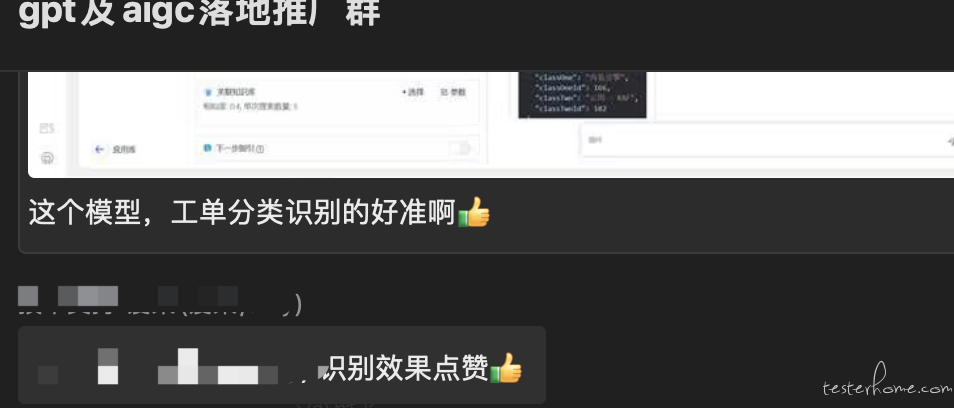

今天看了一篇大模型在测试领域落地的文章,忍不住分享下:
从 2023 年底起,群核科技质量团队便反复强调 AI 可能对测试团队带来的价值,旋即我们组建了专门的 AIGC 虚拟小组,进行了一系列的基建能力搭建和部分领域的探索。从建设进度来看,AI 带来的价值是非常大的。2024 年年底,deepseek 的发布,给业界带来了非常大的震撼,AI 推理能力已经非常强大,行业内纷纷围绕 AI 质量测试和效能领域进行了大量探索。从这些探索、经验和我们取得的结果上看,我们必须紧跟这个潮流,通过运用各种 AI 工具武装我们自己,结合我们的工作流,提升我们的效能。经过一段时间的实践探索,我们 2025 年将重点在以下几个方面进行建设:
2025 年开年至今,我们测试平台已接入如下业界领先的大模型,这些模型也在各个领域得到较好反馈。
| 接入时间 | 模型 | 应用领域 | 接入效果反馈 |
|---|---|---|---|
| 2025 年 1 月 | DeepSeek v3&r1 | 知识库问答 | |
| 2025 年 2 月 | text-embedding-3-small bge-m3-embedding | 向量模型&知识库领域 | |
| 2025 年 2 月 | Claude3.5&Claude 3.7 Sonnet | 自动化测试代码编写 | |
目前已有 20+ 各类应用接入质量部 AI 测试平台 FastQA,平台也在不断优化升级能力中。
| 时间 | 平台优化 | 接入效果反馈 |
|---|---|---|
| 2025 年 2 月 | 模型对接优化 |  |
| 2025 年 2 月 | 平台版本升级 |  |
| 2025 年 1 月 | 企信对接问答优化 | 支持企信群 @ 机器人方式对话,方便对接知识库应用
|
思路:
群聊群内@AI虚拟账户发送创建工单指令,自动创建工单
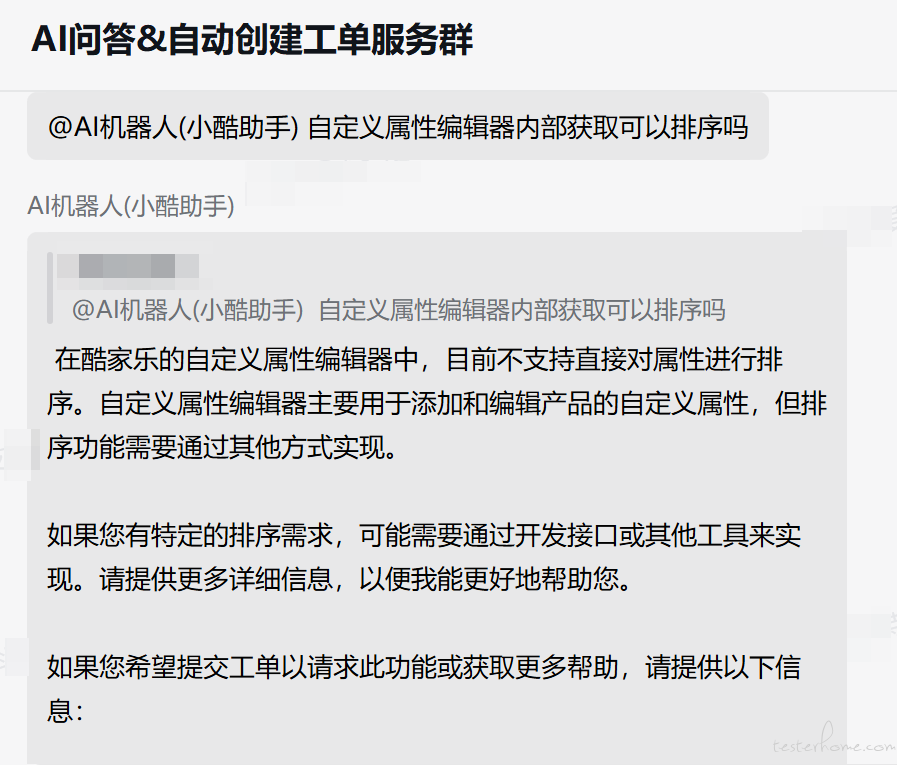
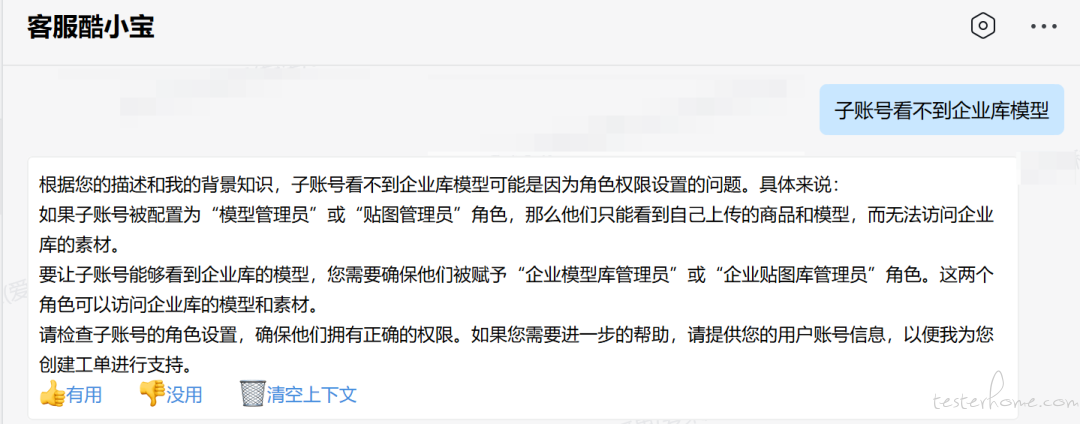
应用内,点击【客服酷小宝】,进行问题咨询,自助解决 FAQ 类问题 ;
应用内,点击【客服酷小宝】,发送创建工单指令,自动创建工单
思路:
 ## 3.3【AI 精选文档分享】
思路:
## 3.3【AI 精选文档分享】
思路: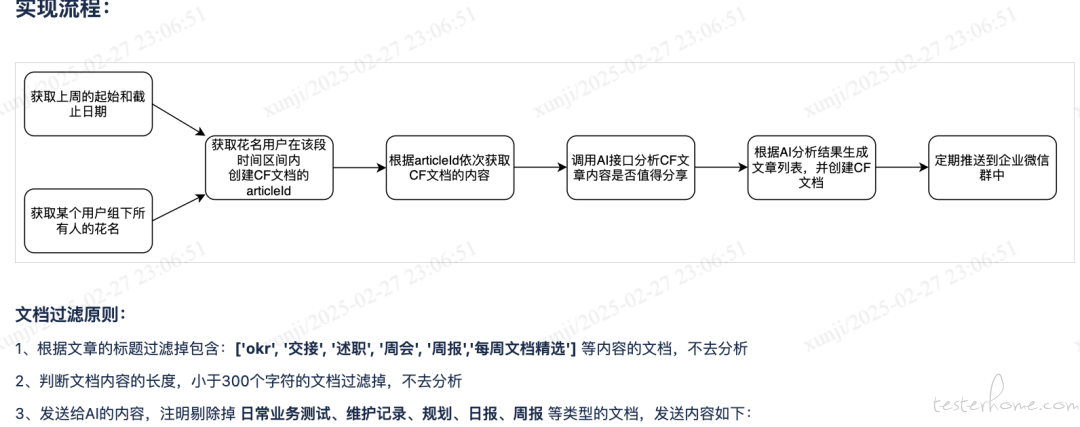 进展:
进展: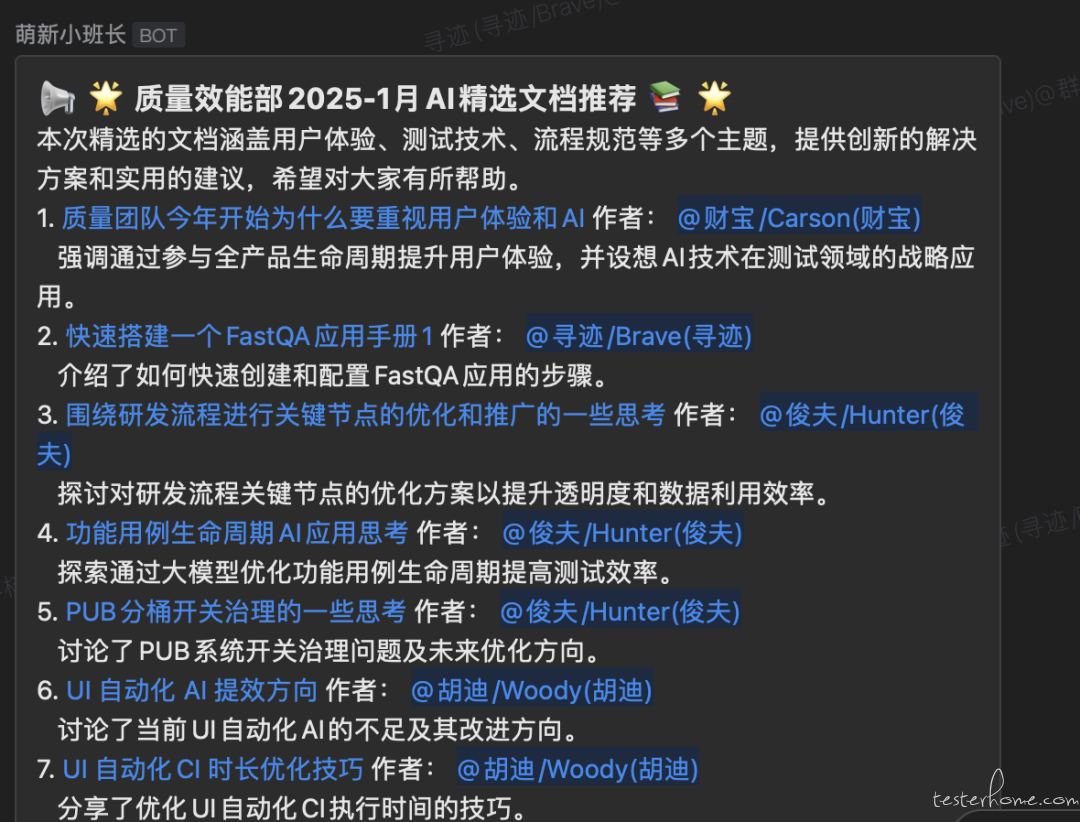
思路:

进展:
思路:
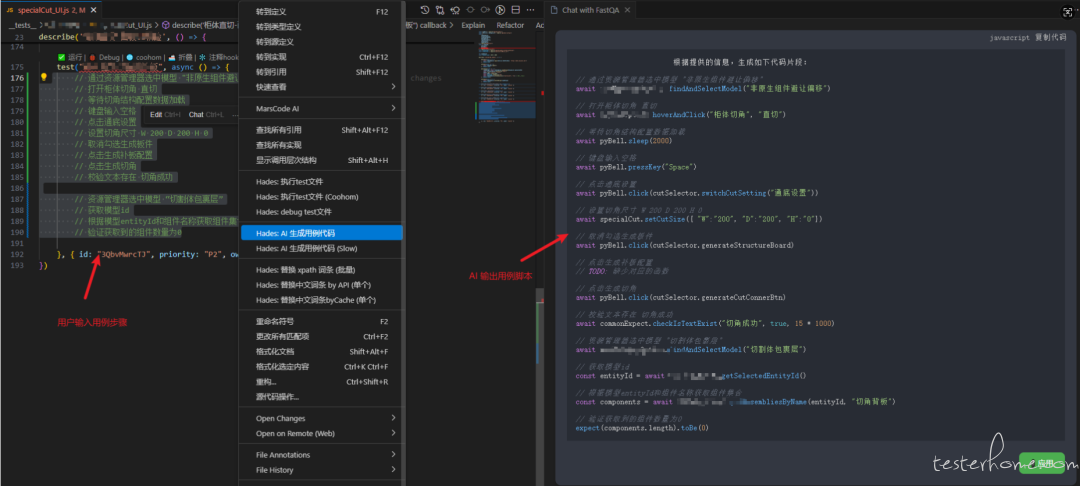
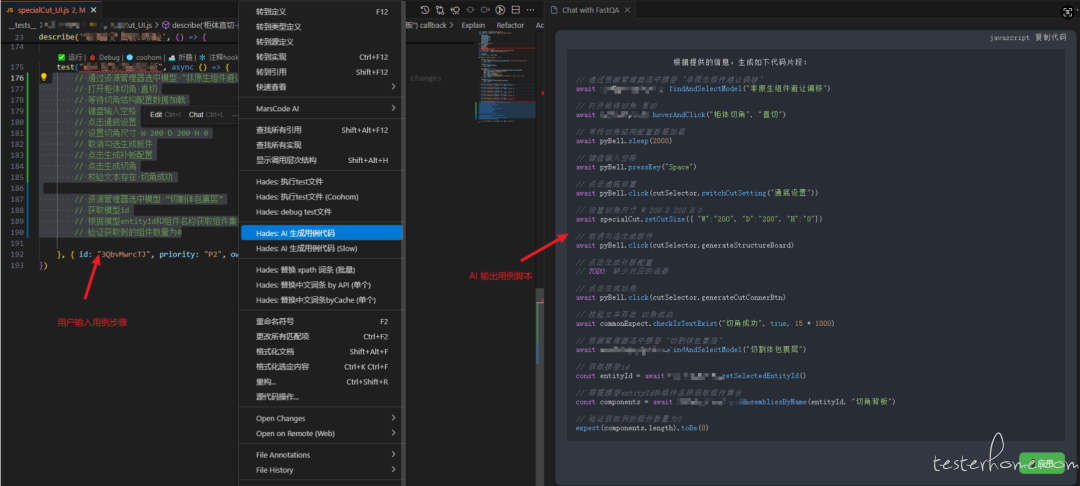
使用 AI Agent 解析文档并生成测试用例,阅读 CF 并解析文档中的图片,拆分功能点,为每个功能点设计测试用例,检查用例的中英文情况
应用:
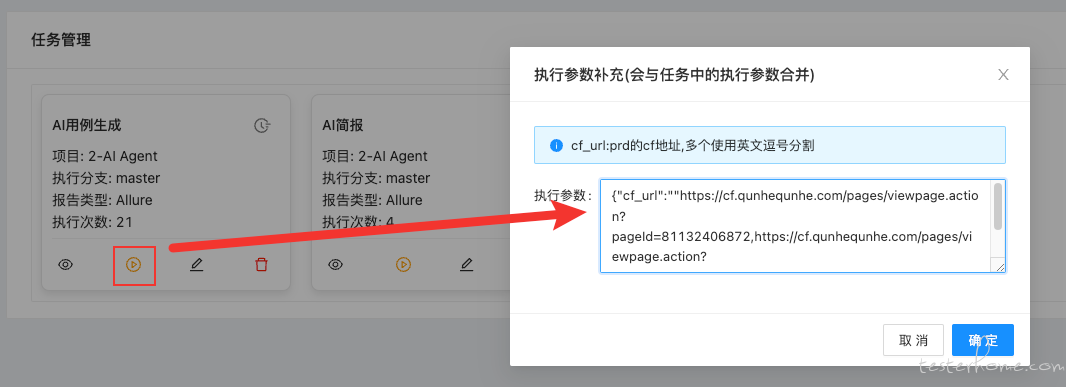
思路:
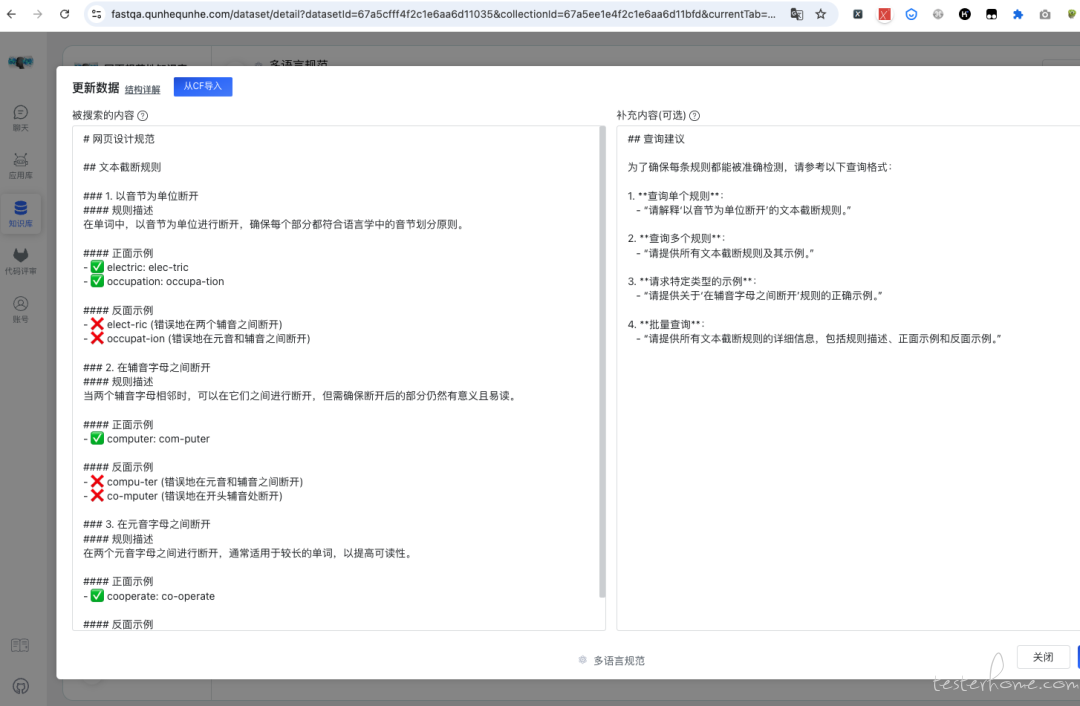
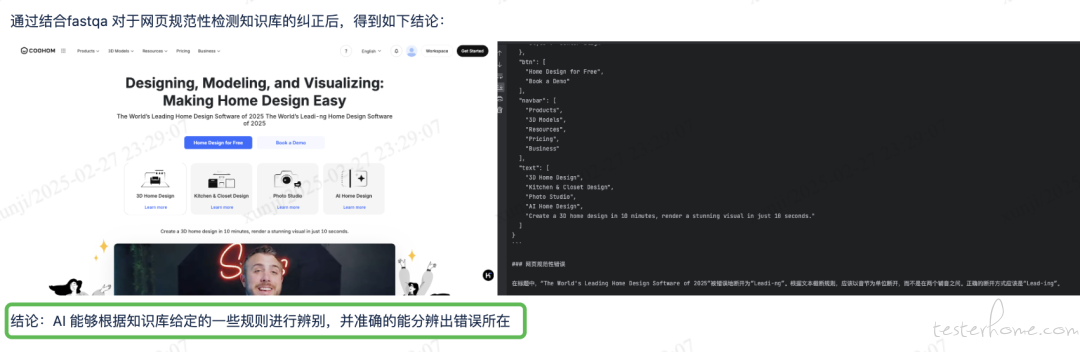
4.1【测试分析报告撰写】
针对大项目编写测试分析报告,引入 LLM 大模型(文本 + 视觉),根据需求文档/CF 文档链接/设计稿,生成初步的测试分析报告。这些报告有助于测试人员拓展思维,为撰写详尽的测试分析报告提供有力的启发与参考。
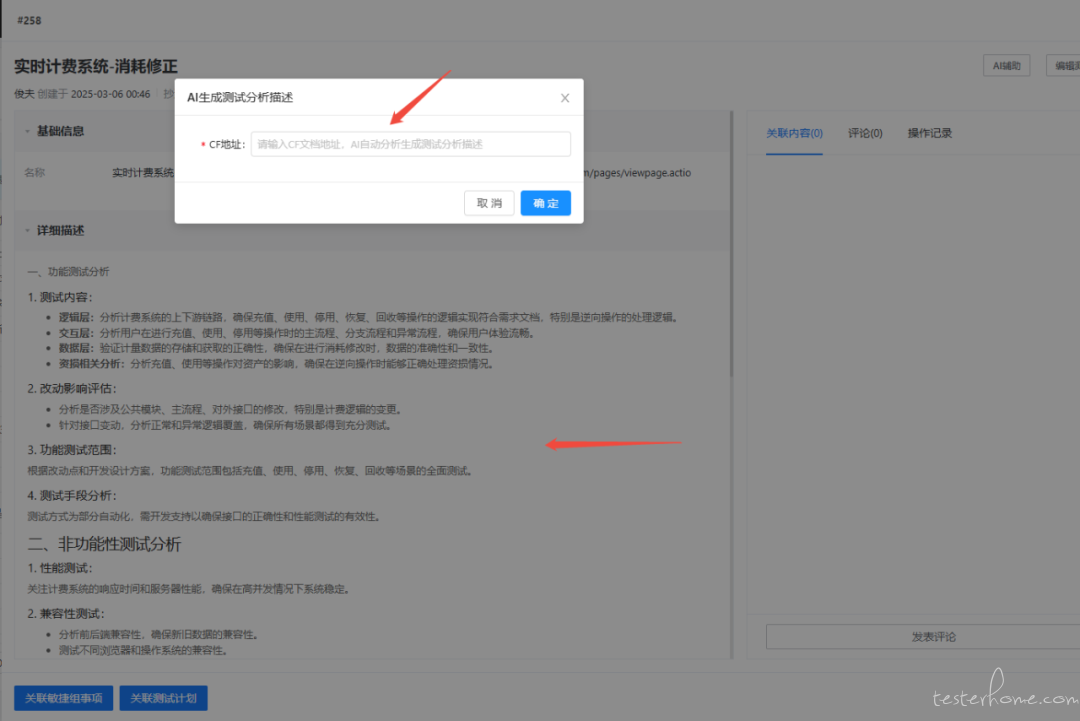
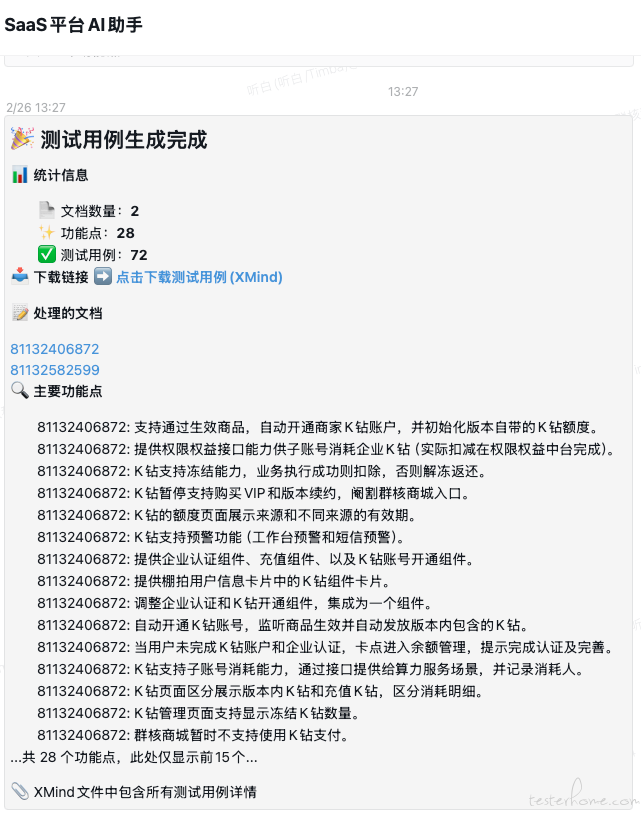
4.2【AI 用例生成】
生成新功能用例时,运用 LLM 大模型依据需求文档,初步生成功能用例,二次确认修改后,一键导入系统。这不仅能为测试人员打开编写思路,还能辅助他们编写更为全面、细致的功能用例。
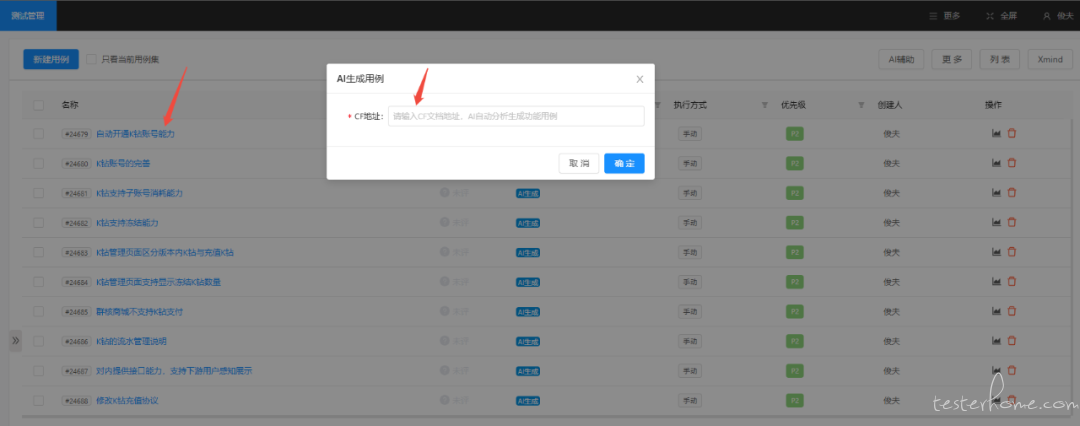
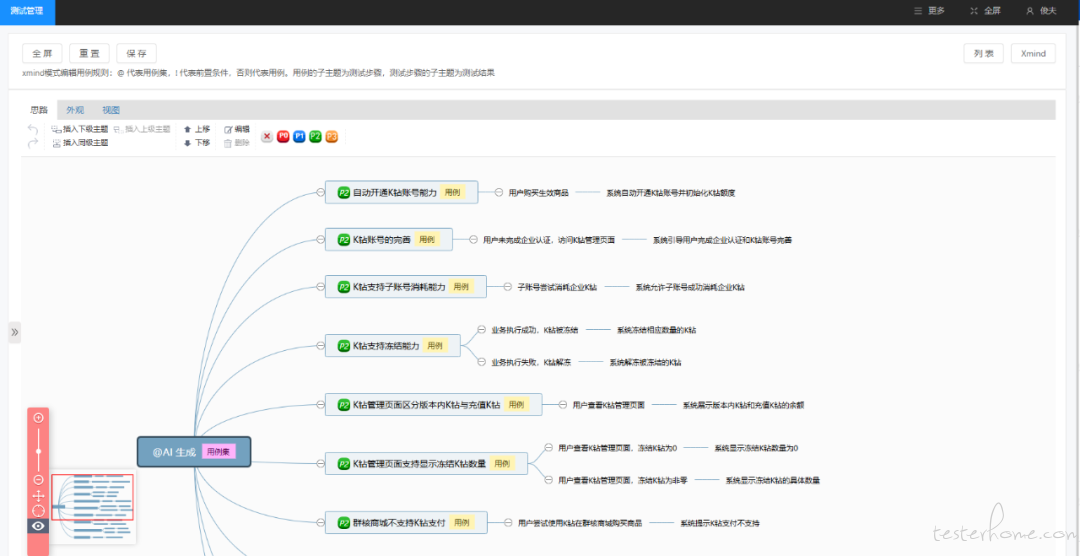
4.3【影响用例自动识别(调研中)】
由于受影响功能在开发阶段已确认,且相关功能用例已存在用例库中,在评估影响范围时,采用 RAG/KAG 模型通过检索增强技术,能够快速从用例库中精准定位相关功能用例,呈现给测试人员。这将极大地节省查找时间,为测试人员编写回归用例提供了重要辅助参考依据。
4.4【AI 用例评审】
用例评审环节也可以用 LLM 大模型。具体方法是制定一系列严谨的评审规则,让大模型在这些严格条件下运行。大模型会给出用例的合格分数,并提供具有针对性的修改意见,助力测试人员对用例进行修改与优化,以保障测试用例达到较高质量标准。
除了上述介绍之外,我们还进行了以下探索的应用建设,值得我们持续期待!
5.1【用户分析-AI 辅助七鱼会话分类打标 】
目标:实现 70% 以上的七鱼分类自动精准打标
思路:七鱼会话结束后,通过输入会话信息及七鱼分类后,让大模型给出一个精准的四级分类再回传给七鱼平台打标,减少客服的工作量
进度:进行中,基础建设完成,提示词待调优
5.2【自动化测试平台接入 AI 能力】
目标:
我们整个部门团队非常重视 AI 领域提效,也希望整个团队同学提升这方面的能力和意识,因此制定了三步走计划:
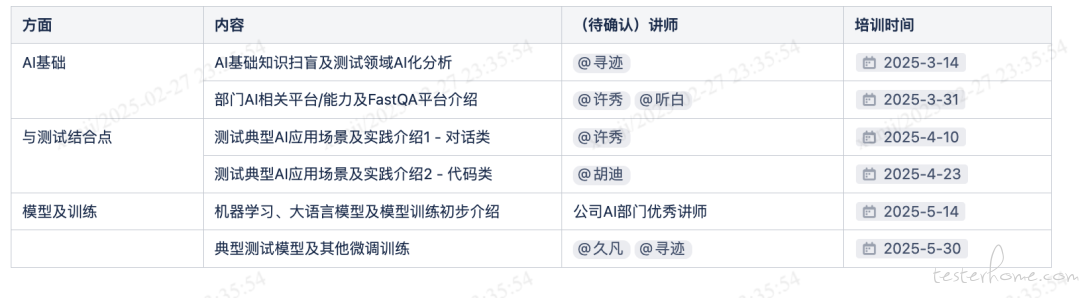
当前培训计划如下:AIGC 知识培训
随着 AI 的持续发展,我们已然看到了它对于互联网及软件工程领域带来的巨大价值,测试领域也是受用方之一。AI 是一个万花筒,对于我们测试同学来说不仅要持续学习 AI、掌握 AI,更要结合我们实际业务场景和诉求,合理利用 AI 能力,与我们现有的系统、流程做深度结合,才能发挥它最大的价值。酷家乐质量效能部门将会持续投入到 AI 学习和基于 AI 落地实践的浪潮中。
原文链接:https://mp.weixin.qq.com/s/zghVVVDIkgy5EDTKv6zLyQ
