
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq、@ 鲍勃
1、Cartesia 发布 Voice Changer:可实现声音转换、克隆和实时语音翻译
Cartesia 是一家专注于开发实时多模态智能技术的初创公司,由斯坦福大学的研究人员创立。今天,他们推出了一个新模型,该模型能够为 Cartesia 的 Voice Changer 提供动力,是实现转换、克隆和本地化语音的终极工具。
模型亮点:
精细调整每一个细节:调整节奏、表现力、语调等,从而获得完美的表达。
利用他们的语音库 :从众多高质量的 AI 语音中选择,适合任何心情或风格,涵盖 15 种语言和多种方言。
自定义声音克隆:创建独特的 AI 声音,并无缝使用我们的声音变换器。
高级本地化:翻译时保持原文语调和情感不变。(@Cartesia@X)
2、xAI 宣布 Grok 3 免费开放使用
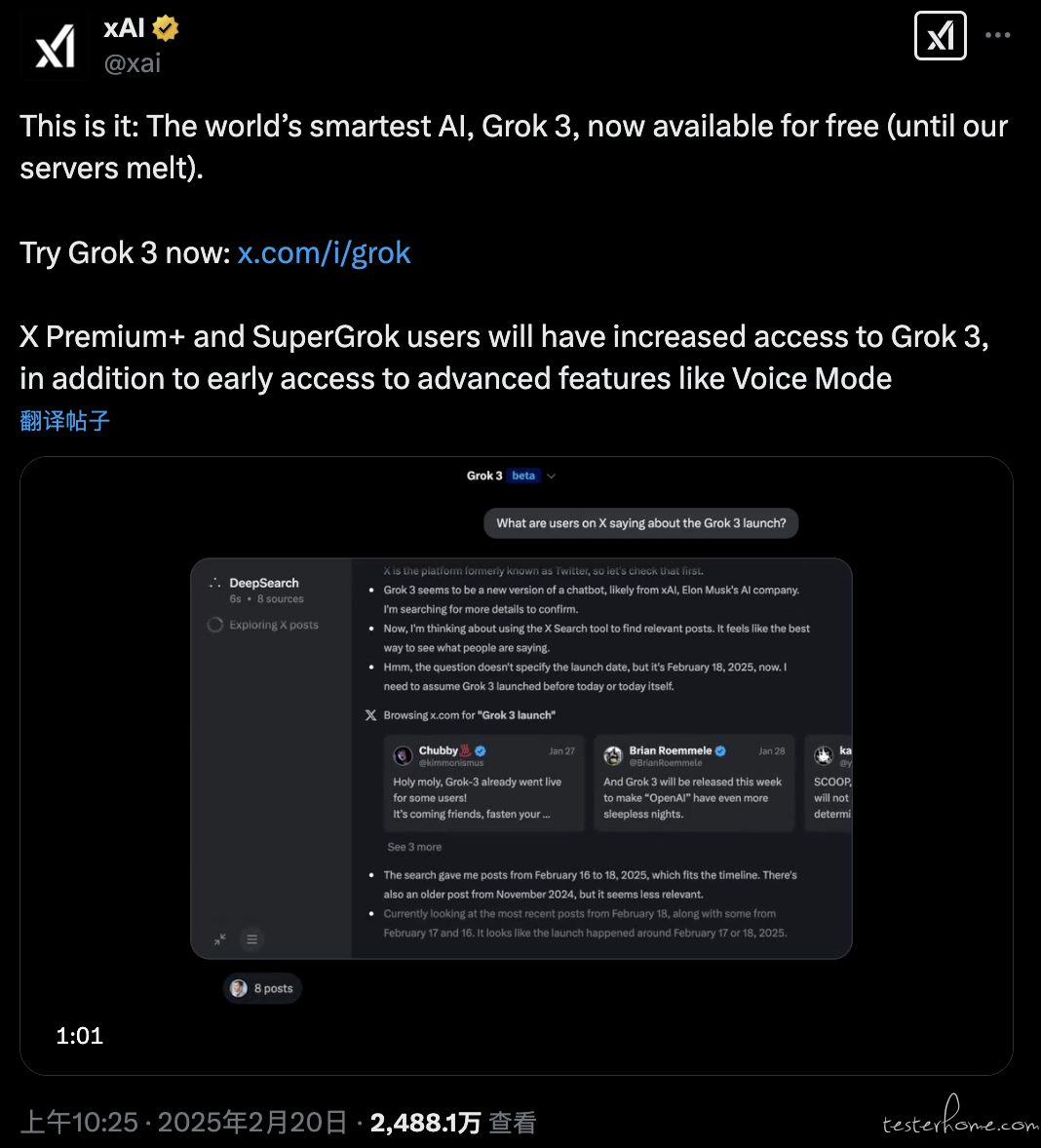
2 月 20 日,马斯克旗下的 xAI 宣布最新推出的 Grok-3 模型免费开放使用。xAI 称,「世界上最聪明」的 AI — Grok-3 模型现已免费提供,并调侃表示除非 xAI 的服务器宕机。同时 xAI 还表示,X Premium+ 和 SuperGrok 用户将能获得对 Grok-3 的更多访问权限,同时还能提前体验语音模式等进阶功能。
同日,Grok App 客户端升至美国区 App Store 免费 App 榜首,超越 OpenAI 的 ChatGPT App。Grok-3 模型于 2 月 18 日发布。据悉,Grok-3 训练累积使用了 20 万张 H100 显卡,其在 Chatbot 竞技场之称的 LMSYS 盲测中,代码、指令响应等各个方面排名第一,超过 Gemini-2 Pro、DeepSeek-V3、GPT-4o 等模型。
此外,xAI 还一同推出由 Grok-3 加持的 DeepSearch,号称是下一代搜索引擎。DeepSearch 功能下,模型将自主像 agent 一样运作,并且理解用户提问背后的意图,能够在互联网以及 X 中进行全面检索。(@APPSO)
3、重磅发现!DeepSeek R1 方法成功迁移到视觉领域,多模态 AI 迎来新突破!
介绍一个全新的开源项目 ——VLM-R1,它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间。这个项目的灵感来自去年 DeepSeek 开源的那个 R1 方法,靠着 GRPO(Group Relative Policy Optimization)强化学习方法,在纯文本大模型上取得了惊人的效果。现在,VLM-R1 团队直接把它应用到了视觉语言模型上,打开了一扇新的大门。

图片里展示了一桌子丰盛的美食,包括各种蔬菜、面饼和点心。针对图片,向模型提出一个问题:「在图片中找出蛋白质含量最高的食物」。
模型不仅回答得准确:
「图片中展示了桌上的各种菜品,包括蔬菜、面饼和点心。从蛋白质含量来看,面饼或面点可能含量最高,因为它们通常由全谷物制成,面粉中含有蛋白质。虽然蔬菜也含有蛋白质,但比起这些主食来说含量较少。」
更厉害的是,它还精准地在图片中框选出了那个蛋白质含量最高的鸡蛋饼。
完美展示了 VLM-R1 在实际应用中的优势:
准确的视觉识别能力专业的知识推理能力清晰的文本表达能力
项目地址:
[VLM-R1](https://github.com/om-ai-lab/VLM-R1@ 机器之心))(
4、阿里宣布将发布深度推理模型!基于全球屠榜的 Qwen2.5-MAX
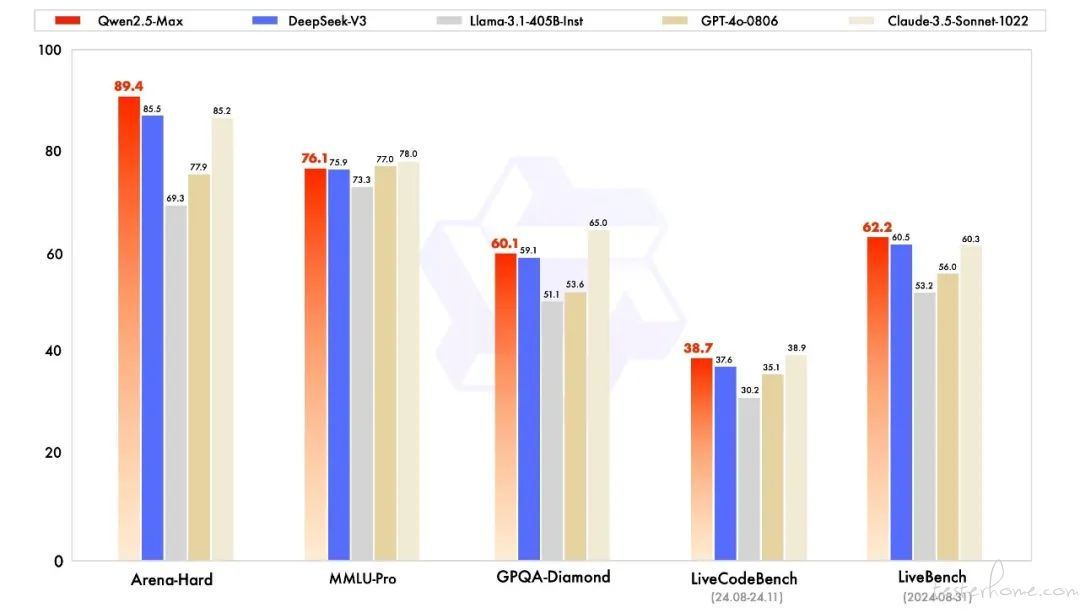
昨天,阿里巴巴集团 CEO 吴泳铭在财报会上表示,阿里将于近期发布基于千问 Qwen2.5-MAX 的深度推理模型。
1 月底,阿里发布了 AI 基础大模型千问旗舰版 Qwen2.5-Max,预训练数据超过 20 万亿 tokens。
公开资料显示,Qwen2.5-Max 在多项公开主流模型评测基准上录得高分,全面超越了全球领先的开源 MoE 模型以及最大的开源稠密模型。
目前,Qwen 的全球衍生模型已突破 9 万个,全球排名第一。(@APPSO)
5、DeepSeek 即将发布 5 个开源项目

DeepSeek 在 X 发布了一个预告说:「我们是 @deepseek_ai,一个探索通用人工智能(AGI)的小团队。从下周开始,我们将开源 5 个代码仓库,以完全透明的方式分享我们虽小但真诚的进展。这些在线服务中不起眼的构建模块,都经过了详细的文档记录、部署以及在生产环境中的实战检验。作为开源社区的一份子,我们坚信每一行分享的代码都能汇聚成共同的动力,加速整个进程。每日解锁即将到来。没有象牙塔,只有纯粹的「车库能量」和社区驱动的创新。」(@ DeepSeek@X)
1、腾讯 ima 安卓端 App 正式上线
腾讯旗下 AI 工作台 ima.copilot(简称 ima)昨日宣布,推出移动端应用程序(App),率先上线安卓端,iOS 将于近期上线,同时将云存储空间免费扩容至 2G。作为以知识库为核心的 AI 工作台产品,ima 自 2024 年 10 月发布以来,已覆盖 Windows、Mac 及微信小程序平台,此次移动端上线标志着用户可随时随地享受「搜、读、写」一体化的智能体验。目前,用户可以通过 ima 官网(ima.qq.com)和腾讯应用宝下载 ima 安卓端 App。(@APPSO)
2、携手舜宇光学旗下公司,中国电信 AI 眼镜最早 5 月发布

在去年举办的 2024 数字科技生态大会上,中国电信就带着自研 AI 眼镜(以下简称电信 AI 眼镜)亮相大会展台,它具有识别物体、人像、拨打电话、编辑短信以及跨语种翻译等功能。
据了解,这款展出的电信 AI 眼镜由中电信人工智能科技有限公司与浙江舜为科技有限公司(注:以下简称舜为)联合研发,后者为舜宇光学科技集团下属控股公司,专注于 XR 智能硬件系统解决方案,研发能力覆盖 XR 整机光学设计、硬件开发、驱动开发、算法集成、ID 设计、结构设计、生产制造等。
配置方面,电信 AI 眼镜采用第一代高通骁龙 AR1 芯片,搭配 1200 万像素 RGB 摄像头,配备 LED 指示灯提示拍摄、语音及配对状态;音频上,支持 3 麦克风阵列和双扬声器开放声场技术,同时集成 AI 降噪,定向增强及空间音频算法,在保护用户隐私的前提下为用户提供良好的音频体验,单次充电续航时间可达 8 小时。
功能方面,电信 AI 眼镜搭载 TeleAI「星辰大模型」,支持语音助手、高清拍照和视频录制、导航与定位、音乐播放、健康数据监测、利用多模态大模型实现 AI 识人识物等,适用于日常生活、工作协作、教育学习和户外活动。
除了具备一般 AI 眼镜的功能之外,电信 AI 眼镜对视障人群也很友好,它能够对使用者面前的图像进行识别,通过语音传递信息,给视障人士带来极大的便利。
中国电信的工作人员透露,这款自研的 AI 眼镜预计最快在今年 5 月份登场。目前,中国电信正在全力进行研发,力争将成本控制在两千元以内。
从电信 AI 眼镜的情况来看,这款产品似乎是一款由舜为负责设计生产,打上中国电信的品牌、内置电信 AI 大模型服务的产品。(@VRAR 星球)
3、AI 宠物企业获近千万融资,算法经济催生养宠新物种
宠物会说(深圳)近日完成近千万元战略融资,其以 AI 为核心的垂直社区平台通过重构「硬件 + 服务」生态,成为这一变革的典型样本——不同于传统宠物企业,它通过数据驱动与场景创新,验证了 AI 技术与宠物产业深度融合的商业潜力。宠会说以 AI 大模型为核心,打造了一个集内容创作、社交互动与智能设备联动于一体的宠物生态社区。其核心技术包括宠物识别、声音分析、行为监测等 AI 模块,为宠主提供更智能化的养宠体验。

宠会说的技术架构呈现出典型的 AI 时代特征:依托大语言模型构建知识图谱,通过图像识别、语音分析等模块形成多维交互网络,最终实现智能硬件与云端服务的无缝对接。这种技术集成不仅体现在社区内容生成层面,更渗透到宠物喂养、健康管理、行为分析等核心场景。在产品层面,宠会说结合 AIGC 技术,围绕以下几大板块展开布局:
短视频社区:用户可通过短视频记录宠物日常生活,分享养宠心得,增强社区互动性。
AI 养宠:结合智能喂食器、摄像头等设备,实现科学喂养和远程监控,缓解宠物因孤独或焦虑带来的行为问题。
AI 健康管理:用户可拍摄宠物的毛发、眼睛等特征,由 AI 分析其健康状态,提供初步诊断建议。
AI 定制周边:上传宠物照片,即可生成专属定制产品,如宠物服饰、周边用品等,满足个性化需求。
AI 视频生成:用户输入关键文字,即可由 AI 自动生成短视频,提高内容生产效率。
这种多元化的产品体系,使宠会说不仅仅是一个社交平台,更是一个集成了内容、智能硬件和个性化服务的养宠生态系统。(@ 中鲸社)
1、Suno CEO:我们想用 AI 拯救音乐

近期,AI 音乐生成产品 Suno CEO Mikey Shulman 接受了播客 20VC 的采访,其中 Mikey Shulman 分享了他对音乐产业的未来一些看法。Mikey Shulman 开篇就表示,Suno 并不是在制作音乐,而是在培养音乐人。其表示,Suno 的目标是让每个人都能体验音乐的所有乐趣。其中 Mikey Shulman 还借此来谈及了公司的转型,他表示生成式内容比自己预测的来得要快,并且比想象中更好。随后主持人提到了 scaling laws「后续是否还会发展」,而 Mikey Shulman 表示,音乐是完全主观的体验,所以单纯扩大规模并不能解决所有问题,并且他认为,规模在音乐领域并不像在文本领域那样是解决一切问题的灵丹妙药。Mikey Shulman 还提及,目前的听众没有意识到流行音乐很大程度上是推荐算法的产物。他解释道,一首歌是否会在互联网流行,其实是算法和人为推广一起作用的结果,不完全取决于音乐本身的质量。最后,Mikey Shulman 提及了自己对 Suno 的未来想法。他引用了「Instagram 如何改变了摄影行业」,并认为,目前 Suno 甚至是音乐行业,需要解决的的问题是不够多的人能靠音乐谋生,因此 Mikey Shulman 想借助 AI,让更多人接触甚至是以音乐谋生。( APPSO)

更多 Voice Agent 学习笔记:
对话 TalktoApps 创始人:Voice AI 提高了我五倍的生产力,语音输入是人机交互的未来
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布
对话谷歌 Project Astra 研究主管:打造通用 AI 助理,主动视频交互和全双工对话是未来重点
这家语音 AI 公司新融资 2700 万美元,并预测了 2025 年语音技术趋势
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
