
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、微软开源超强小模型 Phi-4,超 GPT-4o、可商用
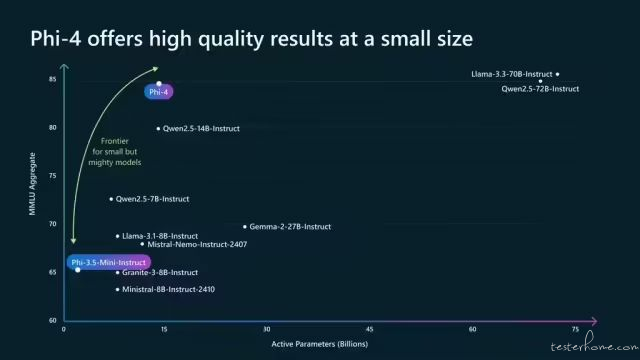
今天凌晨,微软研究院开源了目前最强小参数模型——phi-4。
去年 12 月 12 日,微软首次展示了 phi-4,参数只有 140 亿性能却极强,在 GPQA 研究生水平、MATH 数学基准测试中,超过了 OpenAI 的 GPT-4o,也超过了同类顶级开源模型 Qwen 2.5 -14B 和 Llama-3.3-70B。
在美国数学竞赛 AMC 的测试中 phi-4 更是达到了 91.8 分,超过了 Gemini Pro 1.5、GPT-4o、Claude 3.5 Sonnet、Qwen 2.5 等知名开闭源模型,甚至整体性能可以与 4050 亿参数的 Llama-3.1 媲美。
现在,这款超强的小参数模型终于开源了,并且支持 MIT 许可证下商业用途。(@AIGC开放社区)
2、MediaTek 携手意腾科技,于 CES 2025 展出多元 AI 语音方案
MediaTek 与意腾科技宣布,将协同合作为车用、智慧家庭,以及智慧零售市场打造创新的 AI 语音解决方案,并于 CES 2025 展出。双方合作将致力于提升用户与汽车、智能设备的互动体验,为全球用户带来更智能、安全且直观的生活方式。
此次合作将意腾科技先进的 AI 声学前处理技术和 AI 科技无缝整合到 MediaTek 包括 3nm 制程的天玑汽车座舱平台内,共同推出专为车内智能语音控制而设计的创新解决方案,合作涵盖了声纹消噪(Voice Print Noise Reduction,VPNR)功能、指向性关键字侦测(Directional Keyword Detection,DOK)、唤醒词(Keyword Spotting,KWS)、语音转文字(Speech-to-Text ,STT)、文字转语音(Text-to-Speech,TTS)功能等。
针对智慧家庭市场,双方共同推出创新的「智慧家庭 AI Hub」。在 MediaTek 天玑 9400 旗舰移动平台上,整合意腾科技的 AI 自然语音技术,以及平台上原有生态伙伴的边缘 AI 自动语音辨识模型(ASR)、小型语言模型(SLM)与多模态大语言模型(LMM),并结合可将传统 AI 应用程序重构为具备自主性、推理能力与行动力的 MediaTek 天玑智能体化 AI 引擎(Dimensity Agentic AI Engine),为智慧家庭情境带来更为流畅且个性化的语音操作体验。
双方合作的另一亮点,是针对智慧零售场景打造的生成式 AI 解决方案。该方案将意腾科技的 AI 唤醒词、语音转文字(STT)、文字转语音(TTS)技术与 MediaTek Genio 智能物联网平台、MediaTek DaVinci 生成式 AI 服务平台结合,为智慧零售设备提供生动的虚拟角色界面和自然语言对话功能。(@ 联发科技)
3、HeyGen 推全新数字人技术 集成 Sora,演技超越真人
近日,HeyGen 公司宣布将其数字人模型与 OpenAI 的 Sora 模型实现集成,引发业界广泛关注。这一技术突破意味着,我们即将迎来前所未有的、由人工智能驱动的「会说话的虚拟形象」视频。这些虚拟形象不仅能够无缝地融入 Sora 生成的场景中,更在某些方面超越了真人演员的表现,为视频创作带来了无限的可能性。
长期以来,传统视频拍摄依赖真人演员,不仅拍摄成本高昂,后期调整也十分繁琐。如今,有了 HeyGen 和 Sora 的强强联合,情况将发生巨大改变。新技术的优势在于,用户可以对虚拟形象的动作、表情和姿态进行精确微调,无需像传统拍摄那样反复重拍。这种高度的灵活性,大大缩短了视频制作周期,也降低了成本。更令人兴奋的是,这些视频的长度不再受限,用户可以自由创作长篇作品。
与以往的数字克隆技术不同,HeyGen 推出的虚拟形象并非基于真实人物的模型,而是完全由人工智能生成的全新虚拟人物。这意味着,这些虚拟形象拥有更强的可塑性和创造性,可以满足各种不同类型的视频需求。
例如,在教育领域,可以创建各种不同年龄、背景的虚拟教师;在娱乐领域,可以打造风格各异的虚拟偶像。(@AIbase 基地)
1、3 到 5 秒即可同声传译 40 余种语言,时空壶推出 W4 Pro 实时翻译耳机

AI 通讯科技公司时空壶宣布在 CES 2025 展会期间推出最新的 W4 Pro 耳机,其内置双向通话功能,支持跨语言实时翻译,可让用户在语音、视频通话中实现跨语言沟通能力,且不限通讯平台。
官方表示,该产品可使用户通过任何通讯平台及传统电话完成无缝双向翻译,且不会影响原始语音质量。其搭载 Babel OS,支持 40 余种语言和 93 种口音,翻译结果自然流畅,接近人类翻译水平。
其搭载 HybridComm 技术,可在捕获到原始语音之后的 3 到 5 秒之内完成翻译,翻译语音的音量相比原音稍大,以增强清晰度。此外,其提供多种模式如下:
一对一模式:与他人共享耳机,进行面对面的实时翻译。
听录播放模式:通过应用录制音频并接收翻译,之后可以回放。
语音模式:将耳机中的翻译语音通过手机扬声器播放,适用于会议或演讲。
W4 Pro 还具备 AI 驱动的实时摘要功能。在通话中,它能实时记录并显示所有语音和翻译,并在通话结束后快速生成会议记录。其支持通过浮窗实时显示双语转录结果,还可为特定行业或情景提供专属翻译。
其采用开放式设计,并具备降噪功能,充电 1 小时即可使用 12 小时。据介绍,该产品已于 1 月 7 日上市,售价为 449 美元(当前约 3294 元人民币)。(@IT 之家)
2、新晋 AI 穿戴设备 Omi:用脑机接口提升你的工作效率
CES 2025 上,位于旧金山的初创公司 Based Hardware 宣布推出其最新的 AI 穿戴设备 Omi,旨在通过创新的「脑机接口」技术来提升用户的工作效率。这款设备可佩戴在颈部,用户只需说「嘿,Omi」便可激活其 AI 助手。更有趣的是,Omi 还可以用医用胶带固定在用户的头部侧面,通过脑机接口来判断用户是否在与其交谈。
Omi 的创始人 Nik Shevchenko 最初在 Kickstarter 上以「Friend」命名此款设备,但在另一家旧金山硬件公司推出同名产品并以 180 万美元的价格购买了域名后,决定重新命名为 Omi。近年来,许多 AI 设备纷纷问世,如 Rabbit 和 Humane 等,但这些设备似乎都未能达到最初的市场期待。Shevchenko 此次希望 Omi 能作为手机的补充设备,从而提升用户的生产力。
Omi 的外观设计小巧,呈圆形,价格为 89 美元,预计于 2025 年第二季度开始发货。同时,开发者版本的 Omi 则以约 70 美元的价格即刻发货。Based Hardware 表示,Omi 能够回答问题、总结对话、创建待办事项以及协助安排会议。该设备会不断监听用户的声音,并使用 GPT-4o 进行处理,同时还能根据每位用户的背景信息提供个性化建议。
为了应对用户对隐私的顾虑,Shevchenko 表示,Omi 基于开源平台开发,用户可以清楚地了解他们的数据去向,或选择将数据保存在本地。此外,该开源平台也允许开发者自行构建应用或使用他们选择的 AI 模型。目前,已有超过 250 款应用在 Omi 的应用商店上线。
Shevchenko 透露,Based Hardware 已筹集到约 70 万美元,其中 15 万美元用于制作 Omi 的宣传视频,并表示未来将继续寻找更多投资。他认为,用户基础是产品成功的核心驱动力,越多的人了解 Omi,产品就会越好。(@AIbase 基地)
3、「吹气猫」FuFu 萌化登场,帮你快速吹凉美食

在 CES2025 的舞台上,一款名为「吹气猫」Nékojita FuFu 的创新产品吸引了众多目光。这款由日本 Yukai Engineering 公司推出的可爱装置,专为解决快速冷却热饮与食物而设计,其独特的设计理念让人眼前一亮。
把它挂在杯壁上,它体内的小风扇就会旋转起来,从微微张开的猫猫嘴里吹出,帮你把滚烫的热水吹凉。(@ITBEAR 科技资讯)
1、李开复:只有大公司能继续做超大模型
近日,零一万物 CEO 李开复接受晚点对话的采访,并表示只有大公司能继续做超大模型。
李开复开篇回应了零一万物调整,表示不会停止预训练,但不再追逐超大模型。并且他认为追寻 AGI 需要充足甚至不计代价的弹药储备,而零一万物现阶段的最高优先级是先巩固拿到弹药的实力。
面对行业和认知变化,李开复从商业的角度认为,只有大公司能继续做超大模型。同时他引用前 OpenAI 首席科学家 Ilya 的观点,表示互联网数据资源就像化石燃料般正逐渐枯竭,虽然算力还在提升,但数据增长速度已见顶。同时,李开复提到,从信仰 Scaling Law 到怀疑 Scaling Law 只花了一年时间。他表示,现在一切都加快了。技术迭代加快了。
他还透露,商业化灵魂拷问时刻已经到来。因为要烧 Scaling Law 的创业公司会烧钱更多、更快,所以企业更应该做一个符合商业逻辑、对投资人负责,能确保活下来的商业模式。
此外,李开复还表达了他对「AI Agent」的看法。他表示,只要这个工作还没被 AI 取代,便会一直做他所热爱的工作。并且李开复提到将会花更多时间和他爱的人在一起,因为这一定是 AI 做不到的。(@APPSO)
2、马斯克:现实世界中用于训练 AI 模型的数据已经所剩无几,合成数据是未来的解决方案
在周三晚间与 Stagwell 董事会主席马克・佩恩的直播对话中,马斯克表示:「我们现在基本上已经消耗掉了所有人类知识的积累…… 用于人工智能训练的数据。这个现象基本上是去年发生的。」
马斯克此番言论与前 OpenAI 首席科学家伊利亚・苏茨克弗(Ilya Sutskever)在去年 12 月的 NeurIPS 会议上的观点相似。苏茨克弗曾指出,AI 行业已经达到了所谓的「数据峰值」,并预测未来缺乏足够的训练数据,将迫使 AI 模型的开发方式发生改变。
马斯克认为,合成数据是未来的解决方案。「补充现实世界数据的唯一途径是通过合成数据,也就是让 AI 自己生成训练数据。AI 会进行自我评估,并通过这一自我学习的过程不断优化自己。」
目前,许多科技公司,包括微软、Meta、OpenAI 和 Anthropic 等,已经开始使用合成数据来训练他们的主力 AI 模型。据 Gartner 估计,到 2024 年,用于人工智能和数据分析项目的 60% 数据将是通过合成方式生成的。
使用合成数据的一个显著优势是降低成本。人工智能初创公司 Writer 表示,其 Palmyra X 004 模型几乎完全依赖合成数据进行开发,开发成本仅为 70 万美元,而一个规模相似的 OpenAI 模型的开发成本大约为 460 万美元。
然而,合成数据也存在一定的风险。研究表明,合成数据可能会导致模型性能下降,输出结果不仅缺乏创新性,而且可能变得更加偏颇,最终严重影响其功能性。因为模型是通过自己生成合成数据进行训练的,如果这些数据本身带有偏见或局限性,那么最终模型的输出也会受到这些因素的影响。(@IT 之家)

更多 Voice Agent 学习笔记:
对话谷歌 Project Astra 研究主管:打造通用 AI 助理,主动视频交互和全双工对话是未来重点
这家语音 AI 公司新融资 2700 万美元,并预测了 2025 年语音技术趋势
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨 Voice Agent 学习笔记
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+ 客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
人类级别语音 AI 路线图丨 Voice Agent 学习笔记
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
