
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、Freestyler: 伴奏同步的说唱合成模型
歌唱是人类文化不可或缺的一部分,体现着人类的创造力。说唱(Rap)是歌唱各类流派中最具特色的一种。从本质上讲,说唱的核心特点在于其强烈的节奏和风格,这使其与其他流派有着明显的区别。说唱歌手通常会快速且有力地唱出歌词段落,与伴奏节拍紧密同步,营造出一种充满活力且动感十足的听觉体验。如何生成自然的说唱是一个极具价值的研究方向。
最近,西工大音频语音与语言处理研究组(ASLP@NPU)与微软、CUHK-Shenzhen 合作的论文「Drop the beat!Freestyler for Accompaniment Conditioned Rapping Voice Generation」被人工智能领域顶级会议 AAAI2025 录用,该论文针对上述问题开展了深入研究,提出首个说唱生成模型 Freestyler,以歌词和伴奏输入,生成与伴奏风格节奏匹配的说唱;同时开源了首个说唱数据集 RapBank。
论文原文:https://arxiv.org/abs/2408.15474@ 音频语音与语言处理研究组)(
2、Google 发布了「虚拟现实」版 Android,想让你把熟悉的应用「戴在头上」
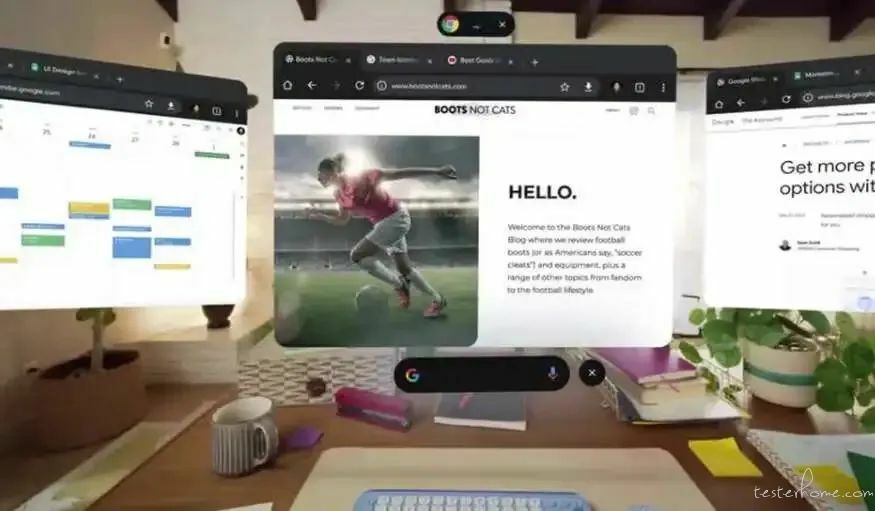
谷歌日前正式发布了用于头显和眼镜设备的操作系统 Android XR。这家公司将其定位为一个全面的空间计算平台,并希望在 XR 领域与 Meta 和苹果展开竞争。
如名字所示,这个基于 Android 的系统主要面向 XR 设备,并支持所有的平面 Android 应用。
谷歌表示,目前 Play Store 的 Android 应用将默认支持 Android XR,除非开发者选择退出。这意味着相关设备从第一天开始就拥有了一个庞大的现有平面应用库,包括谷歌的第一方应用,如 Chrome、Gmail、Calendar 和 Drive 等。实际上,谷歌自家的应用已经更新并实现了所谓的「空间化」。
就功能而言,这与苹果的 visionOS 非常相似,但带有 Android 的味道。
Android XR 的显著区别在于它的人工智能集成。Gemini 内置,但远远超出了聊天代理。Android XR 的 Gemini 可围绕你在现实世界和虚拟世界中看到的一切进行自由形式的语音对话。
苹果为 visionOS 带来了 Siri,但并不能感知头显内外的视图。Meta Horizon 操作系统有一个实验性的 AI,可以支持现实世界视图,但不支持虚拟世界的视图。Gemini 可同时考虑真实和虚拟内容,所以你会感觉体验更加无缝,更为有用。
另外,Android XR 不仅支持头显,同时支持智能眼镜。谷歌预计,Android XR 智能眼镜将很快成为智能手机的外接屏幕工具。
Gemini 是 Android XR 计划的核心,而一个关键载体是紧凑型眼镜。它可以在普通眼镜形态的基础之上提供平视显示和与 AI 对话时的音频反馈。与头显相似,相关的智能眼镜几乎肯定会配备摄像头,它会与十年前的 Google Glass 十分相像,但更时尚、更智能。
尽管目前尚没有针对 Android XR 的具体智能眼镜产品,但谷歌和三星一直在合作开发一款名为「Project Moohan」的 MR 头显,并计划于明年向消费者推出。
在开发方面,谷歌支持广泛的开发途径。对于使用 Android Studio 的开发者来说,新的 Jetpack XR SDK 扩展了相关的工作流程,以帮助开发者创建现有平面应用的空间版本。这包括一个新的 Android XR 模拟器,无需头显即可测试 Android XR 应用程序。Unity 同时提供了一个全新的 Android XR 扩展,以及 WebXR 和 OpenXR 得到支持。
谷歌同时表示,将通过供应商扩展为 OpenXR 带来新的功能,包括:
人工智能驱动的手形网格,从而适应不同手形和大小
详细的深度纹理,允许真实世界的对象遮挡虚拟内容
复杂的光估计,以匹配现实世界的照明条件
新的可追踪设备,可允许你把现实世界的物品,如笔记本电脑、手机、键盘和鼠标带入虚拟环境
值得一提的是,谷歌将在 2025 年举办一个 Android XR 开发者训练营,感兴趣的开发者可以访问页面进行申请。(@ 映维网)
3、Voice Agent 框架 TEN 已经支持 Gemini Multimodal Live API
TEN 是一个开源的 Voice Agent 框架,用于轻松地构建具有语音对话、视觉理解能力、工具调用等能力的对话式 AI。
Gemini Multimodal Live API 发布后 24 小时内,TEN 团队迅速整合了 Live API。Live API 凭借超低延迟、高级多模态功能和卓越的灵活性引领潮流。
此外,通过使用目前免费的 API 密钥,你可以无缝地将其与 TEN 内部提供的 35+ 扩展集成,打造你自己的专属应用场景。
了解 TEN:
https://github.com/TEN-framework/TEN-Agent
1、ChatGPT 推出视频通话和屏幕共享功能
「OpenAI 12 天」活动已进入第六天,OpenAI 公司宣布为 ChatGPT 的高级语音模式带来视频输入和屏幕共享功能,并为迎接圣诞节,限时推出全新的圣诞老人模式。
OpenAI 公司表示未来几天时间内,会向大多数 ChatGPT Plus 和 Pro 用户以及所有 Team 用户,推出视频和屏幕共享。该聊天机器人的企业和教育用户将在 1 月份获得视频和屏幕共享功能。
ChatGPT 的高级语音模式现在可以通过智能手机摄像头支持视频聊天,并通过屏幕共享来识别设备屏幕显示的物体。
用户可以通过以下步骤使用:
在手机上打开 ChatGPT 应用
点击聊天栏附近的语音图标
点击左下角的视频图标即可启用视频输入
或者点击三个点的菜单,选择「共享屏幕」进行屏幕共享(@IT 之家)
2、Midjourney 推出多人协作的世界构建工具「Patchwork」支持 100 人同一画布操作
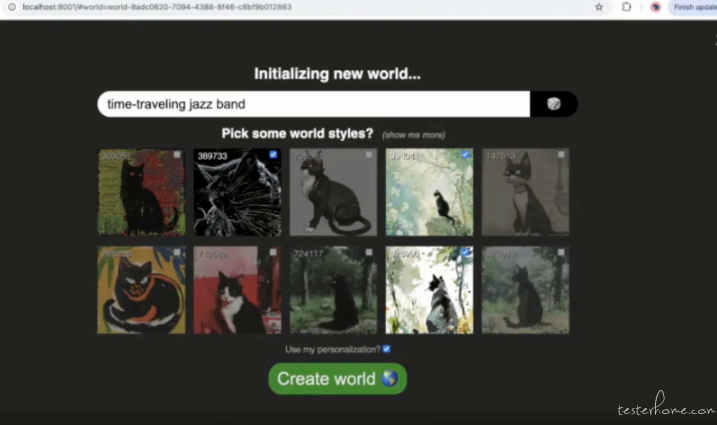
Midjourney 是一家备受欢迎的 AI 图像生成初创公司,拥有超过 2100 万名 Discord 用户。近日,该公司宣布将推出一款新的世界构建工具「Patchwork」,标志着他们从图像创作扩展到更复杂的创意合作领域。
「Patchwork」在 Midjourney 的 Discord 频道通过直播展示,用户需要将他们的 Midjourney Discord 帐户连接到他们的 Google 帐户才能访问 Patchwork 的研究预览。
该工具提供一个白色的无限画布,用户可以使用工具箱中的各种按钮来添加角色、事件、派系、地点、道具等元素。用户可以通过「保存」功能下载 JSON 文件,包含在画布上生成的所有 Midjourney 图像的链接。
要生成新世界,用户需要在「create」屏幕顶部的编辑器栏中输入文本提示,然后从一组 10 种不同的图像样式中选择一种或多种。这会生成一个新的白板,其中包含一堆新的静止图像资产和文本框或实体(称为「碎片」),包括允许用户提示符合初始世界描述的新图像或设置的输入框,甚至是全新的 AI 生成的角色描述。
可以添加新的角色框,然后用户可以提示创建名称和特征。同时,用户可以在角色之间建立连接,并撰写动作序列和场景描述。
共享功能允许多个用户实时协作,一个世界最多可支持 100 名用户在同一画布上操作,不过用户越多,画布上的协作可能会越混乱。
在未来的更新中,Midjourney 计划允许非用户查看这些创作板,以便更多的创意团体能够使用这一工具。Midjourney 的 V7 版本也将推出,支持角色在不同图像中的一致性。此外,Kreminski 提到,Patchwork 的背后有三个大型语言模型在运作,包括一个专为 Midjourney 定制的开源模型。(@AIbase 基地)
3、AI 语音智能体平台 Vapi 完成 2000 万美元 A 轮融资,BVP 和 YC 等投资,估值达 1.3 亿美元
AI 语音智能体初创公司 Vapi(前身为 Superpowered Labs)今日宣布完成 2000 万美元 A 轮融资,由 Bessemer Venture Partners 领投,Abstract Ventures、AI Grant、Y Combinator、Saga Ventures 和 Michael Ovitz 参投。据知情人士透露,本轮融资后公司估值达 1.3 亿美元。
Vapi 成立于 2023 年,专注于为开发者提供 AI 驱动的语音 Agent 部署平台。其核心产品提供灵活的 API 接口,支持定制化对话流程,并可与 CRM 和电子健康记录等现有系统无缝集成。平台采用基于 Kubernetes 的架构和私有互联网骨干网,能够同时处理数百万并发通话,确保实时自然的对话体验。
值得注意的是,Vapi 在成立仅六个月内就实现了数百万美元的营收。目前,Y Combinator、Deepgram、Speaksage、Luma Health 和 Playn Voice 等知名企业已成为其客户。平台支持 iOS、Flutter、React Native 和 Web 应用程序的集成,并提供功能调用能力,使语音 Agent 能够执行预约和实时数据检索等任务。(@Saasverse)
4、Cartesia 融资 2700 万美元,用于构建下一代实时 AI 模型
Cartesia 公司今天宣布获得由 Index Ventures 领投的 2200 万美元新融资,其开创性的状态空间模型(SSM)正在引领生成式人工智能的下一波创新浪潮,总融资额达到 2700 万美元。这笔新资金将使 Cartesia 能够扩展并加速其在任何设备上构建实时、多模态智能的使命。
Cartesia 的创始团队由一群杰出的斯坦福大学研究人员组成,其中包括 Goel、他的前实验室同事 Albert Gu(被《时代》杂志评选为人工智能领域 100 位最具影响力人物之一)、Arjun Desai 和 Brandon Yang,以及他们的前教授 Chris Ré。该团队因其开发的 SSM 而享誉全球,位于一个充满才华的博士和学术合作伙伴的丰富生态系统中心,特别是 Ré 的斯坦福实验室近年来一直是多个数十亿美元创业公司的温床,如 SambaNova、Snorkel AI 和 Together AI。他们还汇聚了一支多元化且经验丰富的产品团队,成员来自 DoorDash、Salesforce、Meta、Scale AI、Microsoft、Google Brain 和 Zoom 等知名公司,确保 Cartesia 能为各行业的企业带来实实在在的价值。
Cartesia 的 SSM 架构在性能上明显优于传统的 Transformer 模型,因为它能够与序列长度线性扩展,实现高效、低成本的推理。尽管 Transformer 模型彻底改变了人工智能的格局,并支持了我们今天所见的众多应用,但它们在上下文长度上的二次方扩展限制了推理速度。相较之下,Cartesia 的模型高效且具备更好的长期记忆和更低的延迟,同时能够在任何设备上本地运行。与 Transformer 需要关注每一个过去的标记不同,SSM 在标记流入时会动态更新模型状态并丢弃之前的标记,这使其成为实时推理的理想选择。Cartesia 创始团队广为引用的 Mamba 架构证明,SSM 已能以更少的资源匹配 Transformer 的性能,为开发人员提供了一种更高效、经济的实时人工智能应用开发方案。
2024 年 5 月,Cartesia 发布了 Sonic,这是一款低延迟语音模型,能够生成富有表现力、逼真的语音,展示了其 SSM 架构在实时 AI 应用中的强大功能。除了是速度最快的文本转语音模型(首个音频延迟<90 毫秒)之外,在第三方评估机构(如 Labelbox)进行的盲测中,Sonic 在语音质量、稳定性和准确性方面均优于市场上现有的最佳模型。
Cartesia 计划在其 Sonic 成功的基础上,制定一项长期路线图,其中包括开发能够摄取和处理不同输入(例如文本、音频、视频、图像和时间序列数据)的多模态 AI 模型,目标是创建能够在广泛应用中跨越海量上下文进行推理的实时智能。通过构建具有长期记忆和低延迟的下一代基础模型,Cartesia 旨在改变从医疗保健到机器人技术再到游戏的各个行业,为任何人在任何设备上都能使用的无处不在的、交互式的和实时的 AI 铺平道路。(@PRWEB)
1、Discord 创始人:AI 会大大降低创作出好内容的成本
近期,Discord 创始人&CEO Jason Citron ,接受了著名播客 20VC 的访谈。在访谈中,Jason Citron 表示,Discord 的故事说明了「打造好产品,用户就会来」并不总是奏效。而 Discord 用户增长的突破点在于,邀请人们对应用提出反馈,而不是像在推销产品一样让他们尝试。
当时,Discord 的工作人员在 Reddit 的一篇贴子里,发了一个 Discord 服务器的链接。用户在看到帖子后,点进了 Discord ,然后和工作人员交流,适用产品。Jason Citron 说,「那天我们通过这个帖子获得了 50 个用户,第二天,这 50 个用户变成了 100 个,然后开始滚雪球式增长。」
当被问到「AI 如何改变游戏创意」时,Jason Citron 表示,「我认为 AI 会大大降低创作出好内容的成本」。
他认为,以后像《艾尔登法环》这样的游戏,可能只需要 20 人,而不是 300 人来完成。AI 还会使得一些个人开发者或独立创作者能够制作出今天他们无法做到的游戏,因为现在他们会面临制作周期太长和技术限制的问题。总之,「以后我们会看到更多更小型、更高质量的游戏。」(@APPSO)

更多 Voice Agent 学习笔记:
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+ 客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
人类级别语音 AI 路线图丨 Voice Agent 学习笔记
语音 AI 革命:未来,消费者更可能倾向于与 AI 沟通,而非人工客服
语音 AI 迎来爆发期,也仍然隐藏着被低估的机会丨 RTE2024 音频技术和 Voice AI 专场
下一代 AI 陪伴 | 平等关系、长久记忆与情境共享 | 播客《编码人声》
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
