
例如:AI 生成的电子商务系统可能会创建一个复杂的折扣计算算法。手动测试人员可能会发现某些折扣和用户角色的组合会导致负价格,这是 AI 没有预料到的情况
人工智能辅助手动测试、人类引导的人工智能学习、人工专注于高价值活动、持续学习和适应、道德监督
围绕软件开发的讨论很多,但是同样重要的软件改进关注很少,如今几乎任何人都可以涉足软件开发
测试远不止简单的检查或寻找错误。它涉及收集产品各个方面的尽可能多的信息。这就是测试的美妙之处:它让您真正了解一个系统,发现它的弱点,并观察它在不同条件下的表现。
这是常见的误解,自动化永远是一种方法,不能替代其他类型,人工智能也是如此
从开发人员到利益相关者,质量应该是每个人的责任,以确保产品真正强大
尽早发现问题可以避免以后昂贵而复杂的维修。虽然测试不是免费的,但它是一项投资,通过确保更顺畅的开发过程和更可靠的最终产品,最终可以节省资金
当测试有效进行并遵循敏捷原则时,它会与开发同步进行
故意的(如:优先考虑速度)、无意的(如:糟糕的编程能力)、环境和流程(如:跳过了代码审查)
缺陷越来越多、维护成本越高、开发及测试周期变换、未检测到的风险增加、用户体验下降
识别和记录重复问题、优先考虑技术债务测试、与开发人员合作、使用回归测试、建议主动重构
定期重构、对债务密集型代码进行自动化测试、设定代码质量标准、监控和报告技术债务相关的缺陷
随着人工智能不断革新行业,确保这些系统不仅具有创新性,符合道德规范更加重要。需要从功能准确性转向公平性、偏向检测负责人的人工智能
查询是否存在隐藏的偏见,确定 AI 系统是否平等对待所有群体。
确保 AI 模型可以为其决策提供清晰的解释,尤其是在金融或医疗保健等敏感领域使用时
如何做?
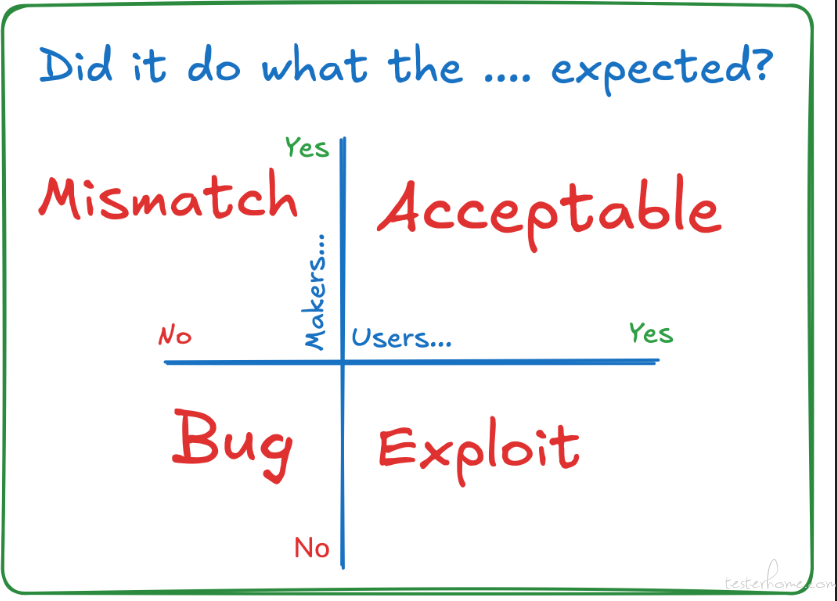
讨论错误报告和功能请求之间的区别,揭露极端情况,存在的灰色地带,从一本书《Mismatch》中获取的灵感,从 “期待” 角度去思考
B-BUG(缺陷):
E-Exploit(漏洞): 该功能满足了用户预期,但不符合产品制造商的预期(一些小群体确实是恶意的,需要被阻止,但有些人只是想出一种我们意想不到的方式来使用我们的产品)
A-Acceptable(可接受):
M-Mismatch(不匹配): 设计和用户能力之间存在不匹配(将其视为不匹配就无需讨论设计是否太聪明或用户是否太愚蠢。存在不匹配,我们可能需要处理)
作者粗略列举了 管理者 对测试人员的 指导工具(指示、证明、观察、分析、干预、称赞、保持沉默、问题、反馈),并推课和卖书
讨论作者对六层测试看法、好处及弊端,这里只记录一下摘抄一下弊端
第一层:生产测试(方法:探索性测试、监控、观察工具实时查看存在的问题,但这可能会损害您的声誉和品牌形象)
第二层:手动回归测试(在这里发现问题意味着要再次回到开发周期,这可能会进一步推迟发布,或者有些团队选择先发布,然后看看会发生什么。)
第三层:自动化端到端 UI 测试 (编写和维护这些测试可能非常耗时,而且一旦测试超过 50 个,就很难理解测试涵盖了哪些内容,哪些内容没有涵盖)
第四层:探索性测试(要做好这项工作需要技能和经验,而测试人员往往是这方面的佼佼者,但往往供不应求。这项工作也很耗时,而且很难重复)
第五层:自动化代码测试(缺点是它只测试工程团队编写的代码,即使测试是按照高标准编写的,也很难看出哪些内容被覆盖了,哪些内容没有被覆盖)
第六层:需求测试(一开始什么都还不存在,所以任何未知的未知,都要等到开发生命周期的后期才会被发现)
为什么 DRY 很重要:
通过最小化冗余来增强可维护性。
简化未来的更新。一个地方的变更会反映在所有实例中。
通过减少代码混乱来提高可读性。
WET 何时有益:
对于小型、直接的测试,重复代码可能会使测试更具可读性。
快速变化的灵活性:在快速变化的环境中,复制代码可以提供灵活性,而无需过早地抽象功能。
为什么 DAMP 很重要:
可读性:使其他开发人员和测试人员更容易遵循和理解测试。
可维护性:描述性名称有助于调试或维护测试。
协作:让其他人更容易掌握测试意图,从而提高团队协作。
一套在语言模型的帮助下 “自我修复” 的测试,这样您就不必在每次代码更改和相关测试失败时手动干预。 这就是所谓的 “自我修复”
主要是对 Given、When 或 Then 步骤,书写可读性、简化的经验分享
结合上面的对比,最后引出 JGiven 工具,不用写 Gherkin 文件,将 DSL(领域特定语言)直接引入到代码中,可以结合 Junit、TestNG、Spock 使用,给出了一些诱人的操作例子

实际就是使用 LangChain 的 Gen AI 能力,来做了一个测试自动化,但实际 WorkFlow 设置很复杂,作者没有进行深入研究
作者使用过 Playwright 进行 API 测试、数据库测试、移动应用测试、浏览器多选项卡交互、等等,部分内容会员才可见。
检查特定元素是否包含
const text = await page.locator('.user-greeting').textContent();
expect(text?.toLowerCase()).toContain('welcome back');
await expect(page.locator('.user-greeting')).toHaveTextContent('Welcome back', { caseSensitive: false });
import { expect, Locator } from '@playwright/test';
const customMatchers = {
async toHaveTextContent(locator: Locator, expectedText: string, options = { caseSensitive: true }) {
const actualText = await locator.textContent();
let pass: boolean;
if (options.caseSensitive) {
pass = actualText?.includes(expectedText) ?? false;
} else {
pass = actualText?.toLowerCase().includes(expectedText.toLowerCase()) ?? false;
}
return {
pass,
message: () => pass
? `Expected element not to have text content "${expectedText}"`
: `Expected element to have text content "${expectedText}", but found "${actualText}"`,
};
},
};
expect.extend(customMatchers);
declare global {
namespace PlaywrightTest {
interface Matchers<R> {
toHaveTextContent(expectedText: string, options?: { caseSensitive?: boolean }): Promise<R>;
}
}
}
这里只是定义了一种 toHaveTextContent 匹配器函数,还有很多例子,可以去原文进行查看
最近 Selenium 名声不佳,速度慢,有人说:“Playwright 和 Cypress 才是未来”
作者数十个企业实践测试,后发现
由于后续内容需要充值会员,有兴趣的朋友可以付费阅读
欢迎各位参与投稿或修正,提交 PR
##
以下所有数据具有时效性,排序不分先后
Star:439,Open Issues:51,Contributors:50


Star:376, Open Issues:111,Contributors:55

Star:8.2K, Open Issues: 46,Contributors:104

有趣的观点:
有趣的提问:
有趣的现象:
有趣的观点:
作者通过提问的方式,建议测试人员进行反思。
