
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、新 Chrome 插件可有效检测 AI 生成的声音

为了应对即将到来的 2024 年美国总统选举,电话筛选和欺诈检测公司 Hiya 推出了一款免费的 Chrome 插件——Hiya Deepfake Voice Detector,该插件能够可靠地检测出 AI 生成的声音。这款插件通过分析视频或音频流中的声音,给出一个真实性评分,帮助用户判断声音是否为真实的或伪造的。
Hiya 表示,第三方测试者验证了该插件的准确性超过 99%,即使是对未训练过的 AI 生成声音也能有效检测。此外,Hiya 声称该插件能够识别新合成模型生成的声音,即使这些模型刚刚发布。在插件正式上线前,Engadget 进行了测试,发现其表现良好。例如,当播放一段疑似使用 AI 配音的关于布鲁斯音乐家 Howlin’ Wolf 的 YouTube 视频时,插件给出了 1/100 的真实性评分,确认该视频为深度伪造。
Hiya 总裁 Kush Parikh 在一份新闻稿中批评了社交媒体公司在防止深度伪造内容传播方面的不足:「显然,社交媒体网站有责任提醒用户他们消费的内容有很大可能是 AI 深度伪造。目前,这一责任落在了个人身上,要求他们保持警惕并使用像我们的 Deepfake Voice Detector 这样的工具来检查可疑内容。这是一个很高的要求,因此我们很高兴能够提供一种解决方案,帮助用户夺回一些主动权。」
该插件只需几秒钟即可完成声音检测,并采用信用系统来防止服务器过载。用户每天将获得 20 个信用点,这可能不足以覆盖社交媒体上大量存在的操纵性 AI 内容。尽管如此,这款插件仍为用户提供了一个有效的工具,帮助他们在信息泛滥的时代辨别真伪。(@ 龙剑秀南)
2、Canary Speech 推出用于临床对话的 Canary Ambient 真实语音分析技术
Canary Speech 是语音生物标记技术领域的领先企业,该公司宣布推出专为医疗保健和联络中心设计的 API 优先解决方案 Canary Ambient,该解决方案可在临床对话中提供实时语音分析,公司称这是「同类产品中的首创」。
Canary Ambient 是一款临床决策支持软件,能够深入了解患者与医生的对话,跟踪语言模式,并对认知和行为健康状况进行实时评估。
凭借其先进的语音处理能力,Canary Ambient 可提供不显眼且有影响力的见解,帮助组织识别潜在的高危人群,使其受益于进一步评估,改善整体沟通,提高患者护理效率 -- 所有这一切都在后台监听时完成。
Canary Speech 首席技术官 Nate Blaylock 表示:「Canary Speech 的临床环境监听技术可实现无缝声乐生物标记分析,捕捉临床医生与患者之间的自然互动,无需额外提示。」这项技术有助于临床医生识别可能受益于额外筛查的患者。
Canary Speech 首席执行官 Henry O'Connell 表示:「我们很高兴能够提供 Canary Ambient,这将使更多机构能够将声乐生物标记分析无缝集成到现有工作流程中,从而改善患者护理和客户服务。
Canary Ambient 的主要功能包括
3、智源发布原生多模态世界模型 Emu3,宣称实现图像、文本、视频大一统
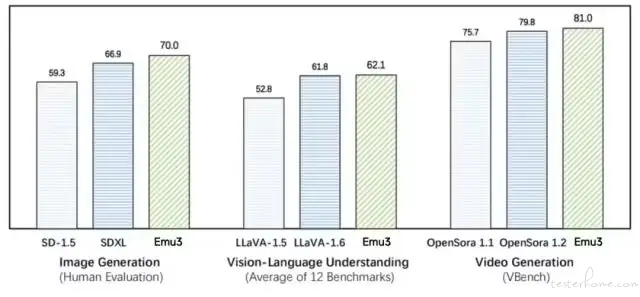
智源研究院于昨日(10 月 22 日)发布原生多模态世界模型 Emu3。该模型只基于下一个 token 预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。官方宣称实现图像、文本、视频大一统。
在图像生成任务中,基于人类偏好评测,Emu3 优于 SD-1.5 与 SDXL 模型。在视觉语言理解任务中,对于 12 项基准测试的平均得分,Emu3 优于 LlaVA-1.6。在视频生成任务中,对于 VBench 基准测试得分,Emu3 优于 OpenSora 1.2。
据介绍,Emu3 提供了一个强大的视觉 tokenizer,能够将视频和图像转换为离散 token。这些视觉离散 token 可以与文本 tokenizer 输出的离散 token 一起送入模型中。与此同时,该模型输出的离散 token 可以被转换为文本、图像和视频,为 Any-to-Any 的任务提供了更加统一的研究范式。
Emu3 研究结果证明,下一个 token 预测可以作为多模态模型的一个强大范式,实现超越语言本身的大规模多模态学习,并在多模态任务中实现先进的性能。通过将复杂的多模态设计收敛到 token 本身,能在大规模训练和推理中释放巨大的潜力。(@ IT 之家)
4、马斯克的 xAI 正式发布 API,开发者可将 Grok 集成到其他应用
埃隆・马斯克的人工智能公司 xAI 正式发布了其应用程序编程接口(API),允许开发者将 Grok 集成到其他应用程序中。
马斯克在周一宣布了这一消息,并同时在 xAI 网站上发布了该接口的链接。此前,马斯克曾在 8 月份确认将为 Grok 提供 API 的计划,并在 3 月份开源了该软件的权重。
要查看和使用 API,用户必须登录他们的 xAI 账户,并在个人资料设置中选择「Request Access」来申请访问 PromptIDE 和 API。目前,API 只有一个模型,名为「grok-beta」,其价格为每百万输入 token 为 5 美元,每百万输出 token 为 15 美元。
API 还允许用户执行函数调用,以便 Grok 可以与数据库、搜索引擎和其他外部软件工具集成。
马斯克和 xAI 于去年 11 月推出了 Grok,这是该公司的第一个产品,并在今年 4 月推出了 Grok 1.5V 视觉处理模型。
今年 5 月,一份文件显示,xAI 在 B 轮融资中筹集了 60 亿美元,此前马斯克在 1 月否认了有关该公司计划筹集资金的报道。马斯克还在 7 月谈到了特斯拉可能投资 xAI,但他同时指出,这样的投资需要获得股东的批准。(@ IT 之家)
5、Meta 重启面部识别技术,打击「假名人」诈骗
据路透社报道,当地时间 22 日,在因隐私和监管压力于三年前关闭 Facebook 的面部识别功能后,Meta 目前宣布正在重新测试该服务,以打击「名人诱饵」诈骗。
Meta 表示,将在试验中招募约 50000 名公众人物,自动将他们的 Facebook 头像与疑似诈骗广告中的图像进行比较。如果图像一致且 Meta 判断该广告是诈骗,将会阻止这些广告。参与的名人将会收到通知,并且如果不愿参与,可以选择退出。
该试验计划从 12 月开始在全球范围内推出,部分未获得监管批准的地区如英国、欧盟、韩国以及美国得克萨斯州和伊利诺伊州将不包括在内。
Meta 内容政策副总裁 Monika Bickert 表示:「我们的目标是尽可能多地为这些公众人物提供保护。他们可以选择退出,但我们希望提供这样一种保护,并使参与变得简单。」(@ IT 之家)
1、小鹏自动驾驶负责人:端到端很容易方向错了
10 月 21 日,晚点 LatePost 发布了与小鹏自动驾驶负责人李力耘的访谈内容。
在访谈中,李力耘提到,端到端其实很容易走错方向。他表示,小鹏和华为的方向大致一致的,是正确的。然而有的厂商会有一些混淆,把一些小模型通过规则的连接看成是端到端,或者直接做一个车上的端到端模型,其实这些都会有问题。
例如,借助规则堆砌小模型来做端到端,会导致厂商仍然需要大量优秀的规则工程师;如果是在车上部署一个端到端模型,短期内可能见效很快,但是它长期的能力会受限于模型本身的大小。
随后,李力耘也在微博转发了该篇访谈内容,并表示「小鹏更着重长远的发展,目前选择的路线与 Open AI 是一致的,我们认为,未来的自动驾驶竞争在云端,小鹏已经开始布局云端大模型。在云端实现强化训练后蒸馏到车上,极大提高了端到端的上限。不久后小鹏端到端表现将会有极大的提升,欢迎各位持续关注小鹏的 AI 智驾。」(@ APPSO)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
