
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的新闻」、「有态度的观点」、「有意思的数据」、「有思考的文章」、「有看点的会议」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、猫眼娱乐发布动态故事板 AI 生成工具「神笔马良」:视听化呈现剧本内容
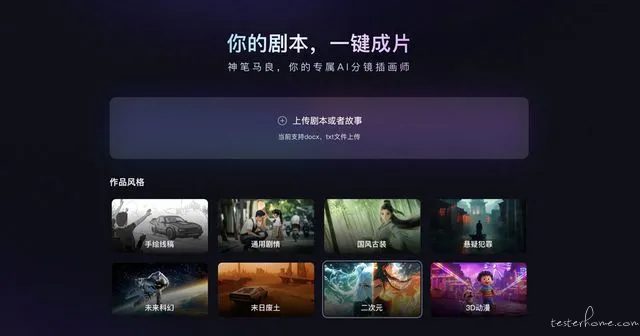
猫眼娱乐发布了首个面向长剧本解析的动态故事板 AI 生成工具「神笔马良」,该产品可对用户上传的剧本进行一键智能分析、智能角色创作、智能分镜创作、智能台词朗读,实现剧本内容的视听化呈现。
「神笔马良」有严格的产品使用规范和内部管理举措,作为对剧本原创性的保护。其对剧本访问实施严格的控制措施,配备风险阻断机制、落实访问机制和操作留痕等方式,实现权限最小化管控。应用场景方面,该产品可应用于项目提报、创投路演、创意阐释、剧本会议、分镜设计等多个阶段。
从官方获悉,「神笔马良」能够对剧本内容进行 AI 智能分析。根据用户上传的内容,「神笔马良」可以进行「专家级」的剧情提炼,深度理解故事内核,通过 AI 生成的动态故事板,提升影视创意的评估效率与准确性,大大降低在项目前期因各方理解差异导致的沟通效率低下的情况。
该产品还可生成 AI 智能角色,可以快速撰写人物小传、生成 AI 画像,还原创作者脑海中的人物音容,使角色形象立体丰满、一目了然。(@IT 之家)
2、OpenAI:计划五年内将 ChatGPT 每月订阅费用提高到最高 44 美元
据 Engadget 报道,OpenAI 告诉投资者,该公司计划在今年年底前收取 ChatGPT 每月 22 美元的费用,并计划在未来五年内积极提高月费,最高将提升至 44 美元。
报道提到,OpenAI 正在从非营利公司向盈利公司的转变迈步,这种商业模式可取消对投资者回报的任何上限,因此公司将有更大的空间以潜在的更高价格与新投资者谈判。文件显示,OpenAI 今年 8 月的营收为 3 亿美元,自 2023 年初以来增长了 1700%,预计 2029 全年营收将达到 1000 亿美元,约相当于目前雀巢或 Target 的年销售额。不过 OpenAI 今年仍预计将亏损 50 亿美元。
为了解决资金短缺问题,OpenAI 正在寻求新投资者,并以 1500 亿美元的估值进行新一轮融资,预计能筹集高达 70 亿美元的资金。(@ APPSO)
3、美图公司旗下 AI 短片创作工具 MOKI 开放:覆盖动画短片、网文短剧、故事绘本等
美图公司旗下 AI 短片创作工具 MOKI 于 9 月 26 日面向全部用户开放。
官方介绍称,与市面上流行的文生视频产品、图生视频产品不同,MOKI 专注于 AI 短片创作这一场景,覆盖动画短片、网文短剧、故事绘本、MV 等多个类型的视频内容生产。
使用 MOKI 的流程如下:
在前期设定阶段,输入故事梗概或导入现有脚本,MOKI 生成分镜脚本并提供多种设定选项在内容生成阶段,MOKI 生成分镜画面并允许细节修改在后期制作阶段,MOKI 生成带有配乐的视频内容,允许用户对视频生成效果持续优化(@IT 之家)
4、苏黎世联邦理工学院研究:AI 可 100% 绕过谷歌 reCAPTCHA V2 验证
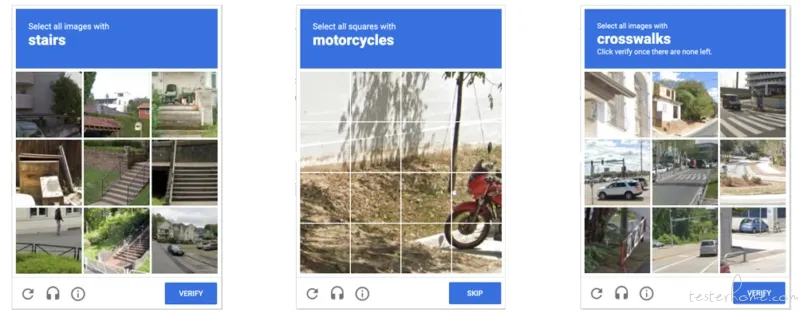
据 Ars Technica 报道,苏黎世联邦理工学院博士生 Andreas Plesner 及其同事发表了一项新研究,研究重点放在了谷歌的验证码系统 reCAPTCHA V2 上。该研究声称,使用经过专门训练的图像识别模型运行的本地机器人在应对这类图片验证码时的表现,可以与人类相媲美,成功率达到了 100%。
谷歌 reCAPTCHA V2 验证码通常会向用户提供一组图片,要求识别出图中的哪些部分包含自行车、巴士、人行道、楼梯或红绿灯等项目。根据谷歌的说法,该系统已在几年前逐步进入淘汰阶段,新的 reCAPTCHA v3 可以分析用户的交互。但即便如此,世界各地仍有数百万个网站使用上文提到的 reCAPTCHA V2 系统。
研究人员使用了经过微调的开源 YOLO(You Only Look Once)对象识别模型,该模型以其实时检测对象的能力而闻名,并且可在计算能力有限的设备上运行。在对 14000 张标记的交通图像进行模型训练后,研究人员的系统可以识别出任何提供的验证码网格图像属于 reCAPTCHA v2 的 13 个候选类别之一的概率。
研究人员还使用了一个单独的、预先训练好的 YOLO 模型来应对他们称之为「类型 2」的挑战,即验证码要求用户识别单张分割图像的哪些部分包含特定类型的对象。除了图像识别模型,研究人员还需要采取其他措施来欺骗 ReCAPTCHA 系统,例如采取措施避免来自同一 IP 地址的重复尝试被检测到。
根据被识别对象的类型,YOLO 模型能够准确识别单个验证码图像的概率从 69%(摩托车)到 100%(消防栓)。这种性能加上其他预防措施,足以让机器人每次都能顺利「冲破」验证码。
在此之前曾有类似用来「对付」验证码的研究,但成功率大多在 68% 到 71% 之间。这篇论文的作者表示,成功率提升至 100% 表明「超越验证码」的时代已正式来临。(@IT 之家)
5、show-me,提供传统大型语言模型(LLM)交互的可视化和透明替代方案
Show-Me 是一个开源应用程序,旨在提供传统大型语言模型(LLM)交互的可视化和透明替代方案。它将复杂问题分解为一系列有理有据的子任务,使用户能够理解 LLM 的逐步思考过程。该应用程序使用 LangChain 与 LLM 交互,并通过动态图形界面可视化推理过程。(@ 机器之心 SOTA 模型)
1、沈向洋在青年科学家 50²论坛的演讲:关于大模型的 10 个思考
9 月 28 日,第四届「青年科学家 50²论坛」在南方科技大学举行,美国国家工程院外籍院士沈向洋做了《通用人工智能时代,我们应该怎样思考大模型》的主题演讲,并给出了他对大模型的 10 个思考。
1、算力是门槛:大模型对算力的要求,过去 10 年非常巨大。今天要做人工智能大模型,讲卡伤感情、没卡没感情。
2、关于数据的数据:如果有 GPT-5 出来,可能会上到 200T 的数据量。但互联网上没有那么多好的数据,清洗完以后,可能 20T 就差不多到顶了,所以未来要做 GPT-5,除了现有的数据,还要更多的多模态数据,甚至人工合成的数据。
3、大模型的下一章:有很多多模态的科研工作要做,我相信一个非常重要的方向是多模态的理解和生成的统一。
4、人工智能的范式转移:o1 出来后,从原来的 GPT 的预训练思路,变成了今天的自主学习的道路,就是在推理这一步强化学习,不断地自我学习的过程。整个过程非常像人类思考问题、分析问题,也需要非常多的算力才行。
5、大模型横扫千行百业:在中国的大模型建设浪潮当中,越来越多的是行业大模型。这个趋势肯定是这样的,未来通用大模型的占比会越来越低。
6、AI Agent,从愿景到落地:超级应用一开始就在那里,这个超级应用就是一个超级助理,就是一个超级 Agent。
7、开源 vs 闭源:我认为 Meta 的 Llama 并不是传统的开源,它只是开源了一个模型,并没有给你原代码和数据,所以我们在用开源系统的时候,也要下定决心真正理解大模型的系统闭源的工作。
8、重视 AI 的治理:人工智能对千行百业、对整个社会的冲击非常大,要大家共同来面对。
9、重新思考人机关系:真正把人机交互搞清楚,才能成为每一代高科技企业真正有商业价值的领导者。现在讲 OpenAI 加上微软就代表这个时代还太早,他们是领先了,但是未来还有很多想象的空间。
10、智能的本质:虽然大模型已经给大家带来很多的震惊,但是我们对大模型、深度学习是没有理论的。关于人工智能的涌现,大家只是讲讲,并没有讲清楚。(@ 腾讯科技)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
