
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的新闻」、「有态度的观点」、「有意思的数据」、「有思考的文章」、「有看点的会议」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、Reflection 70B AI 模型「塌房」:第三方基准测试结果不佳,不如 LLaMA-3.1-70B
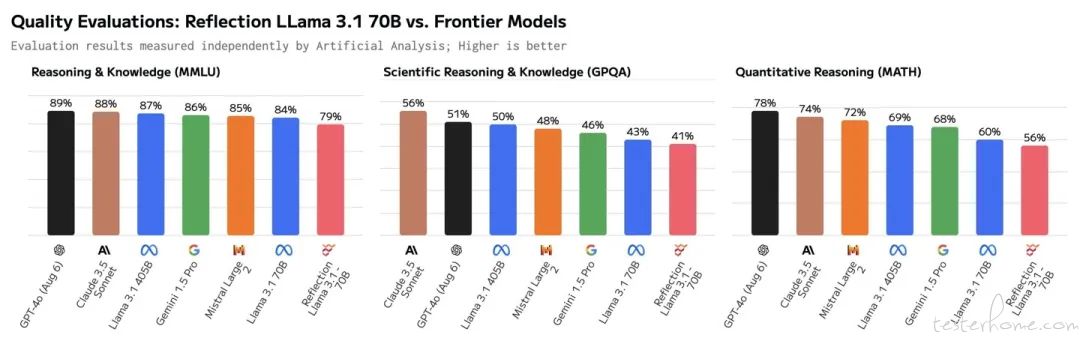
根据科技媒体 The Decoder 昨日(9 月 10 日)报道,对比平台 Artificial Analysis 相关数据表明,Reflection 70B AI 模型在基准测试中的表现,实际上不及 Meta 的 LLaMA-3.1-70B。
针对 AI 模型基准测试结果不佳,Reflection 公司首席执行官马特・舒默(Matt Shumer)表示,上传模型权重至 Hugging Face 时遇到问题,所使用的权重是多个不同模型的混合体,而他们内部托管的模型则显示出更佳的结果。
舒默随后向部分用户提供了独家访问内部模型的权限,Artificial Analysis 重做了测试,并报告结果优于公开 API,只是他们无法确认所访问的具体是哪个模型。
Reflection 在 Hugging Face 已上传了新的模型,不过这些模型在测试中的表现明显逊于之前通过私有 API 提供的模型。有用户还发现了证据,表明 Reflection API 有时会调用 Anthropic Claude 3.5 Sonnet 以及 OpenAI。(@IT 之家)
2、Vidu 全球首发 AI 视频生成「主体参照」新功能,一键同步角色特征
7 月份正式上线的国产视频大模型 Vidu,于昨日(9 月 11 日)的生树科技媒体开放日上发布了「主体参照」(Subject Consistency)功能,该功能能够实现对任意主体的一致性生成,让视频生成更加稳定、可控。
Vidu 主体参照功能是 Vidu AI 全球首发的参考一致性新功能,能够实现用户上传单一主体的图片,如真人、2D 或 3D 角色,在生成的视频中保持这些主体角色的一致性。Vidu 主体参照功能不仅支持对角色的面容、半身、全身特征进行精确控制,还涵盖了多种角色类型和画风,包括写实风格和各种艺术风格。
目前该功能面向用户免费开放,注册即可体验!体验地址:www.vidu.studio(@Founder Park)
3、GPT-4o 实时音频项目负责人离职创业,曾在 OpenAI 最早提出构建「Her」
今年 5 月份,OpenAI 发布了震惊世界的 GPT-4o。这个模型可以跨越文本、视觉和音频,以一种非常自然的形式和人类语音对话,延迟低到与人类在对话中的响应时间相似。而且,它允许用户随时打断,并能感知和回应用户的情绪。因此,该模型发布后,很多人说科幻电影《Her》中的场景照进了现实。
此次离职的 Alexis Conneau 就是 GPT-4o 项目的关键人物之一。离职前,他是 OpenAI 音频 AGI 研究负责人,也是 OpenAI 最早提出 Her 愿景的人。他在领英的个人简介中写道,他是「专注于多模态和音频 AGI 的人工智能研究员,在 OpenAI 领导了『Her』的研究(GPT4-o 和 GPT-5),这是首个原生集成音频的 GPT 模型。」
关于离职后的创业方向,Conneau 还没有透露详细信息。但在被问及「AGI 时间表」时,他回答说自己更想追求「通用情感智能(General Emotional Intelligence,AGEI)」。(@ 机器之心)
4、小模型越级挑战 14 倍参数大模型,谷歌开启 Test-Time 端新的 Scaling Law
谷歌 DeepMind 的最新研究引发了广泛讨论,甚至有人猜测这可能是 OpenAI 即将发布的新模型「草莓」所采用的方法。研究的核心是通过根据 prompt 的难度,在推理阶段动态分配计算资源,从而优化大模型的推理效率。该方法在某些情况下比简单扩展模型参数更为经济有效。具体而言,研究团队探讨了如何在一定计算预算内,使用不同的计算策略解决问题,并评估这些策略的有效性。
他们研究了两种主要的测试时计算扩展机制:一是使用过程密集验证器奖励模型(PRM)来指导搜索算法,动态调整计算策略,以减少不必要的计算;二是根据 prompt 自适应地修订模型的响应,通过逐步修改先前生成的答案来提高精度。研究发现,不同计算策略的效果依赖于 prompt 的难度,他们提出了「计算最优」的扩展策略,能够以更少的计算资源超越传统的 best-of-N 方法。
研究还比较了增加预训练与测试时计算的效果,结论显示,简单和中等难度问题上,测试时计算更有效,而对于更复杂的问题,增加预训练的计算量可能更为有效。这项研究表明,尽管测试时的计算优化无法完全替代大规模预训练,但在某些场景中有显著优势。
有网友将此研究与 OpenAI「草莓」模型联系起来,猜测草莓模型可能使用类似的计算优化策略,通过在回答前「思考」来优化推理过程。这一猜测引发了广泛讨论和推测。( @LLM Space)
5、Pixtral 12B 发布:Mistral 首款多模态 AI 模型,120 亿参数、24GB 大小
法国 AI 初创公司 Mistral 于昨日(9 月 11 日)发布 Pixtral 12B,这是该公司首款能够同时处理图像和文本的多模态 AI 大语音模型。
Pixtral 12B 模型拥有 120 亿参数,大小约为 24GB,参数大致对应于模型的解题能力,拥有更多参数的模型通常比参数较少的模型表现更优。Pixtral 12B 模型基于文本模型 Nemo 12B 构建,能够回答关于任意数量、任意尺寸图像的问题。
与 Anthropic 的 Claude 系列和 OpenAI 的 GPT-4o 等其他多模态模型类似,Pixtral 12B 理论上应能执行诸如为图像添加描述和统计照片中物体数量等任务。用户可以下载、微调 Pixtral 12B 模型,并能依据 Apache 2.0 许可证使用。
Mistral 开发者关系负责人 Sophia Yang 在 X 平台的一篇帖子中表示,Pixtral 12B 很快将在 Mistral 的聊天机器人和 API 服务平台 Le Chat 及 Le Plateforme 上开放测试。(@IT 之家)
1、百度李彦宏:未来大模型之间的差距将拉大
百度 CEO 李彦宏的一次内部讲话内容曝光,谈到了业界对于大模型的认识误区,涵盖大模型竞争、开源模型效率、智能体趋势等。
李彦宏认为,未来大模型之间的差距可能会越来越大,模型的天花板很高,现在距离理想情况还相差非常远,所以模型要不断快速迭代、更新和升级;需要能几年、十几年如一日地投入,需要不断满足用户需求,关注大模型成本的降低和效率的提升。大模型应用落地也将经历从辅助工具、到智能体、再到 Al Worker 的三个阶段。
李彦宏指出,模型之间的差距是多维度的,一个维度是「能力」方面:理解能力、生成能力、逻辑推理能力、记忆能力等;另一个维度是「成本」方面:想具备这个能力或者想回答这些问题,付出的成本是多少。(@ 爱范儿)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
