响应时间一般会随着并发用户数(负载)上升不断升高。
最近正在做压测工作,之前线上环境出现了一些性能问题。起因是由于业务特性在某个时间节点流量激增,造成线上出现了非常严重的服务可用性下降,部分接口可用性下降到了 60%,某些接口平均响应时间从 500ms(毫秒)飙升到 6 s。
经过分析,得出可用性下降以及接口平均响应时间飙升的原因为数据库服务挂掉。
出现线上数据库服务挂掉这样的异常事件,可以看出我们对整个系统的架构并没有认识到性能瓶颈,主要的盲点如下:
解决这些盲点的方法就是进行容量压测,现在重新梳理一下容量压测:
容量压测(Capacity Testing)是一种软件性能测试方法,主要用于评估系统在特定负载下的容量。其目的是确定系统可以处理的最大工作负载,以及在达到容量极限时,系统是否能够保持其性能和稳定性。
容量压测和一般的接口压测都会模拟实际生产环境下的负载情况,通过不断增加并发用户数来逐渐加大负载,两者的区别在于容量压测需要压到系统开始出现性能问题或崩溃,而一般的接口压测只需要满足在性能测试方案当中指定的并发用户数即可,不需要压到服务有损。
在容量压测试过程中需要监控系统的各项性能指标,如响应时间、吞吐量(QPS)、资源使用率(CPU、内存和网络)、服务可用性、错误码等,并记录压测结果。
QPS(Queries Per Second):表示每秒查询率,用来衡量系统每秒能够处理的请求数量。
日常接口压测中,通过制定压测方案,先确定要压到的 QPS 数量,压测执行完毕后若没有性能问题,则表明该接口能扛住对应的 QPS,用来衡量对应系统的吞吐量好坏。
TPS(Transactions Per Second):表示每秒事务处理量,即系统每秒能够处理的事务数量。一个事务可能包含多个请求,因此完成一个事务所需的时间往往比处理一个请求的时间更长,这就导致了 TPS 通常比 QPS 更低。
系统的复杂性和实现方式不同,可能会影响到每个事务或查询的处理时间,实际情况下大多数场景 QPS 和 TPS 两者近似相等。
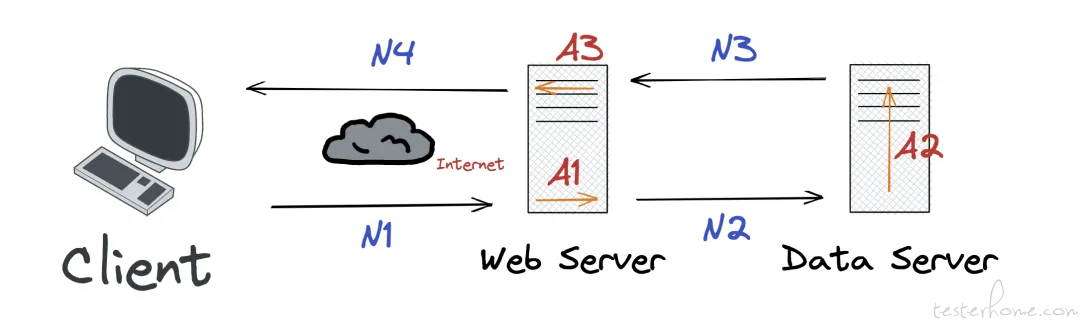
响应时间是指从客户端发一个请求开始计时,到客户端接收到从服务器端返回的响应结果结束所经历的时间。
响应时间由请求发送时间、网络传输时间和服务器处理时间三部分组成,一般取平均响应时间。
计算方式:响应时间=发送时间(约等于 0)+ 网络传输时间(N1+N2+N3+N4)+ 服务器处理时间(A1+A2+A3)
响应时间一般会随着并发用户数(负载)上升不断升高。
吞吐量指的是单位时间内系统处理的请求数量,系统吞吐量由 QPS(TPS)、并发用户数、平均响应时间共同决定。

多数情况下 QPS 和 TPS 近似相等,而 QPS 由并发用户数和平均响应时间决定。
所以对于服务端来说,系统吞吐量一般直接用 QPS 来作为量化指标,换句话说别人问起某系统的吞吐量有多高,就是指这个系统能抗的 QPS 有多大。
利用计算并发用户数的经验公式来验证 QPS 的计算方法的正确性。
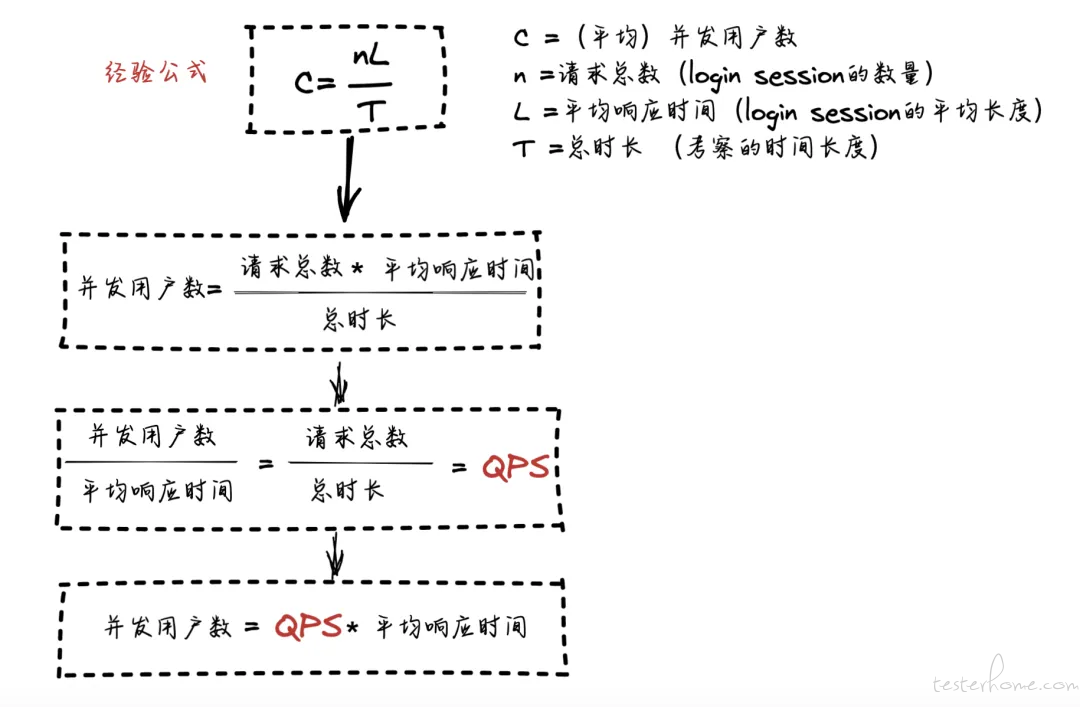
通过查看上图论证过程,可以得知计算 并发用户数,计算 QPS 的正确性。
不同系统资源的使用程度,通常用占用最大值的百分比或均值的百分比来衡量,通常需要关注的资源有 CPU,内存,磁盘,线程数等。
压测中需要关注 Web 服务实例,数据库实例,缓存实例的资源利用率,CPU 利用率是重点指标。
服务可用性为异常请求数量占请求总数的占比,在性能测试中,根据实际情况,需要关注对应压测服务接口以及接口下游服务的可用性,数据库服务,缓存服务可用性等。
计算方式:服务可用性 = 100 - 请求异常数量 / 请求总数 * 100
看完这些概念,是不是还是感觉一脸懵逼,用一个实际的场景来 1 秒内并发地来了 160 个请求,那么此时 QPS 和并发用户数都怎么计算呢?
从上面计算公式可以得知,QPS 为 160,但无法计算并发数,前面我们知道了,并发数=QPS* 平均响应时间。但这里缺少了响应时间,假设响应时间为 100 ms(0.1s),并发用户数为 160*0.1=16
系统同时(1s 内)在处理 16 个用户的请求,这就是系统支持的并发用户数。
并发用户数与资源利用率/吞吐量/响应时间这 3 个指标之间关系密切。随着并发用户数增大,资源利用率,吞吐量,响应时间都会发生不同的变化。
引用一张非常经典的性能指标图片来说明它们之间的关系,该图来自 2005 年 Quest Software 的白皮书《Performance Testing Methodology》
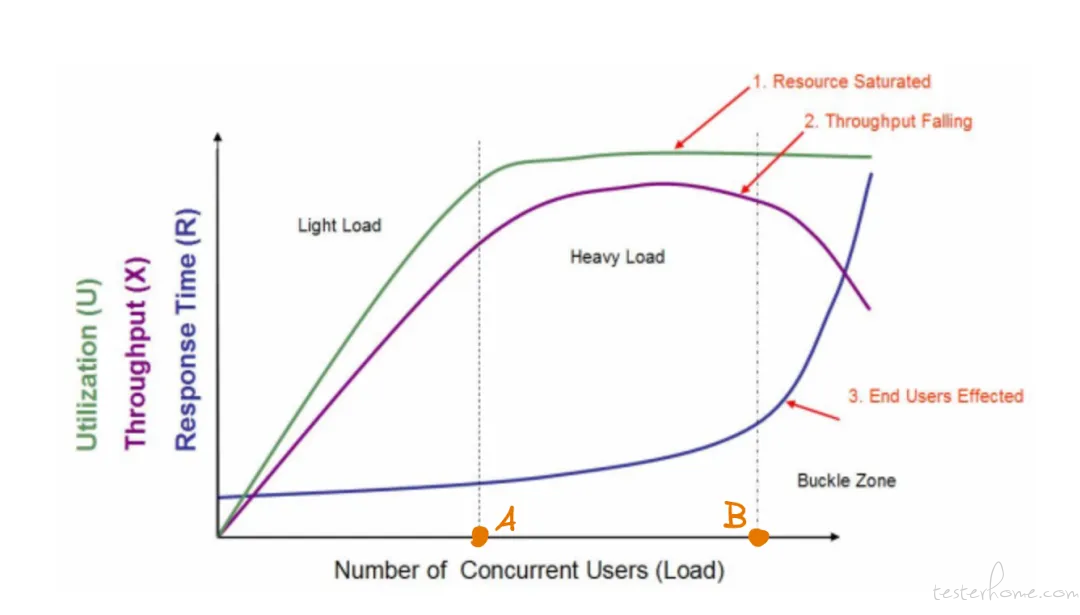
在这个图中,横坐标为并发用户数(衡量系统负载的重要指标),纵坐标有 3 层含义:分别是资源利用率(CPU/内存,下面统称为 CPU),吞吐量(对于衡量服务端吞吐量,一般用 QPS 代替,下面统称为 QPS),响应时间。
通过此图,可以看到三条曲线、三个区域、两个点以及三个状态描述。
三条曲线:QPS(紫色)、CPU(绿色)、响应时间(深蓝色)
三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)
两个点:A 点为最优并发用户数(The Optimum Number of Concurrent Users)、B 点为最大并发用户数(The Maximum Number of Concurrent Users)
三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)
用大白话解读一下这张图:
假设刚开始系统只有一个用户,CPU 工作处于不饱合状态。一方面该服务器可能有多个 CPU,但是只处理单个进程;另一方面,在处理一个进程中,可能 IO 等待阶段,因为没有其他用户,所以没有其他请求进程可以被处理,这个时候会造成 CPU 等待。
随着并发用户数的增加(未超过 A 点),CPU 利用率逐步上升,平均响应时间也在增加,QPS 相应也增加。
而当并发数增加到很大时(超过 B 点),每秒钟都会有很多请求需要处理,会造成进程(线程)频繁切换,真正用于处理请求的时间变少,每秒能够处理完的请求数反而变少(即 QPS 开始下降),但用户的请求等待时间(响应时间)也会持续变大,最后超过用户的心理底线。
综上所述:
在最小并发数和最大并发数之间,一定有一个最合适的并发数值,在最佳并发数下,QPS 能够达到最大。但是,最佳并发并非是一个最大的并发,到达最大时的并发,可能已经造成用户的等待时间变得超过了其最优值。
对于一个系统来说,最佳的并发数需要结合 QPS 以及用户的等待时间来综合确定。
有小伙伴就有疑问了,QPS 怎么还会下降呢,从数学的角度来解释一下原理,见下图:
表示并发用户数和响应时间关系的深蓝色曲线,以 B 点为分界点,在横坐标 [1,B] 以及 [B,正无穷] 区间内,增长速率有所不同。
当并发用户数没有到达点 B 时,曲线的斜率小于 1,所以在初期由于并发用户数的增速比平均响应时间更快,分子比分母涨得快,所以 QPS 不断上升。
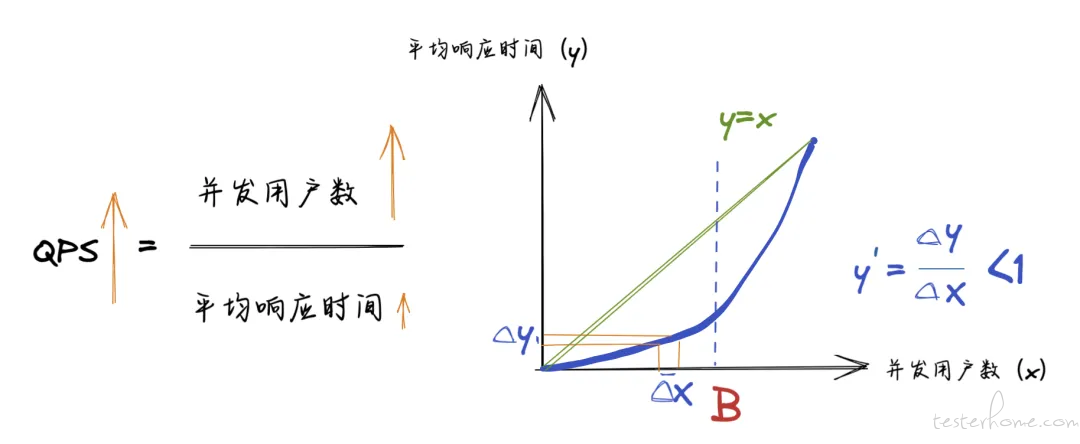
并发用户数超过点 B 后,曲线呈现出指数增长,并发用户数和响应时间的曲线的斜率大于 1,并发用户数的增速比平均响应时间还慢,分母比分子涨得快,所以 QPS 下降。
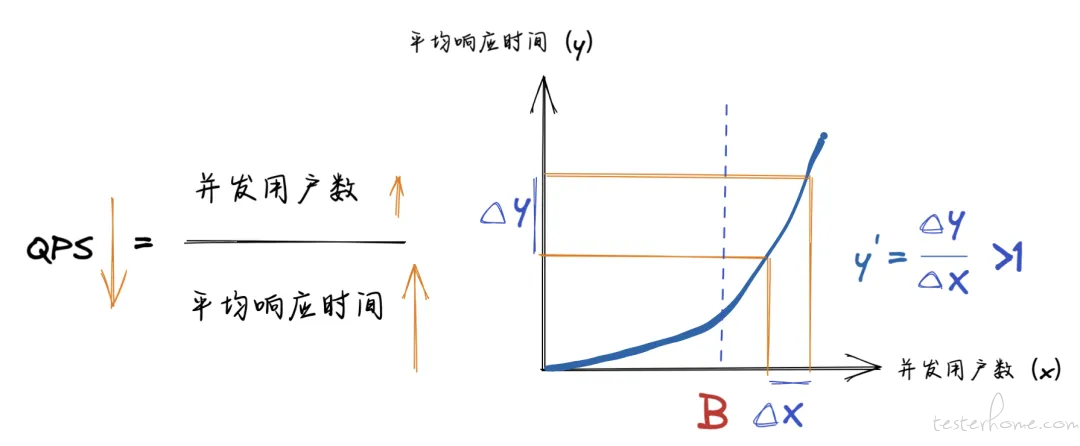
从 QPS 的计算公式可以得出,QPS 是由并发用户数,平均响应时间两者共同决定。
谈到 QPS 时,一定需要指明是多少并发用户数下的 QPS,否则毫无意义,因为单用户的 40QPS 和 20 个 并发用户下的 40QPS 是两个不同的概念。
前者说明该应用可以在一秒内串行执行 40 个请求,而后者说明在并发 20 个请求的情况下,一秒内该应用能处理 40 个请求,当 QPS 相同时,越大的并发用户数,代表了服务的并发处理能力越好。
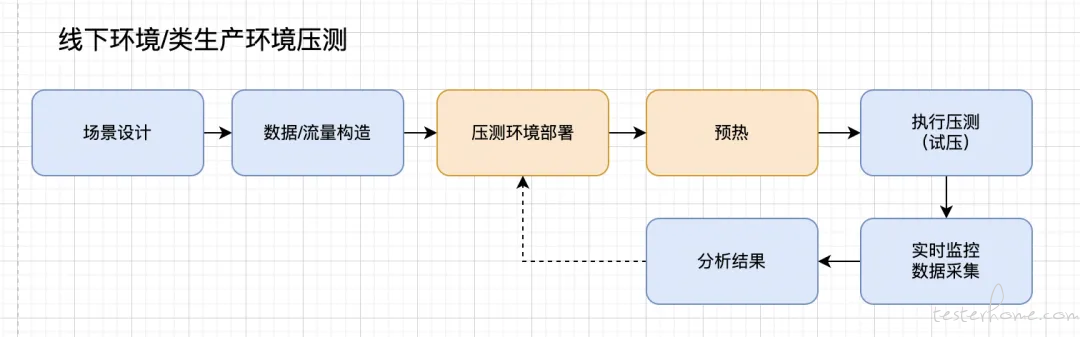
容量压测也是属于性能测试,和一般的性能测试流程相同,需要值得注意的是,如果是使用线下环境压测,压测流程如下:
而对于直接使用线上环境(生产环境)压测,则无需进行流量构造,压测环境部署,预热这 3 个环节。
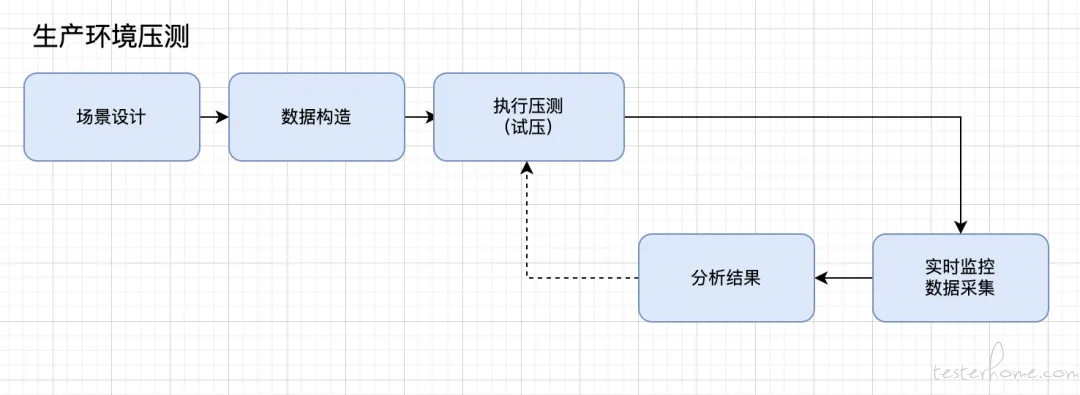
在进行性能测试之前,第一步是进行压测的场景设计,是指针对单接口还是多个接口有关联,需要组合起来同时压测。
由于本次容量压测只针对高并发的单接口,通过查看监控平台某时间段的接口请求流量情况,以及查看代码得知代码架构和调用时机,我就确定好了高并发接口的范围,并没有花时间在场景设计上。
高并发是指在同一时间内,系统或应用程序所处理的并发请求量非常高。在一个系统或应用程序中,如果同时有大量的用户或进程访问同一个资源或进行相同的操作,就会出现高并发的情况。这种情况下,系统或应用程序需要同时处理大量的请求,如果处理不当,可能会导致系统响应变慢、延迟或崩溃等问题
高并发处理能力是一个系统或应用程序的重要指标之一。为了提高高并发处理能力,通常需要采用分布式、缓存、负载均衡、异步处理等技术来优化系统的性能
在本次压测的接口当中,有部分接口的参数需要动态获取,不能写死,否则会命中缓存,起不到压测的效果。如下方接口参数,param2 参数的值,为从文件当中读取一批提前生成好的数据。平时在进行压测时,通常我们可以通过用 Python 写一些造数脚本,满足性能测试数据构造的需求。
另外接口信息,如 URL 和请求参数也需要提前配置好,发压工具可以使用 Jmeter、Loucst、Loadrunner 等。
{"param1": 123456,
"param2":${id},
"param3":10000006,
"param4":"6.7.5"
}
压测前若使用线下环境压测需要提前进行流量构造,对于流量的构造也有下面几种不同的策略:
为了避免对生产环境影响,也可以使用线下环境进行压测,如果使用线下环境,需要提前部署好压测环境。
对于线下环境,部署好压测环境,一般不能马上进行压测,需要进行预热,也就是等机器空跑 5-10 分钟,这是因为在环境刚启动的时候,系统的响应时间,CPU,内存环境刚启动的时候均处于不稳定的状态。
前面的准备工作都做完成了,就可以开始压测,在进行压测过程中,注意通知开发一起关注监控。常见的监控指标:机器内存使用率(机器包括部署程序实例,数据库服务,缓存服务)、CPU 利用率和代理层服务以及下游可用性,响应时间,错误码等。
性能测试后,发现的问题多种多样,我总结了一些常见的调优方法:
以上是一些常见的性能调优案例,具体情况需要根据应用程序的特点和性能瓶颈来确定。同时,在执行性能调优时,需要谨慎考虑对应用程序的影响,并进行充分测试,以确保解决方案是可行和有效的。
在本次压测当中,也出现了很有意思的问题,在这里分享一下:
