首先读取 Redis 开始出现失败,读 Redis 失败必然会进行访问数据库,并写入 Redis,但写 Redis 又是写大 Key,写入超时失败,再次影响 Redis 读请求,越来越多的 Redis 读请求失败,最终造成 Redis 的实例都不可用。

今天分享一下在做压测时遇到的很有意思的性能问题以及对应的排查解决方案,这个性能问题的现象为:Redis 线上实例不可用,Redis 读写均超时。
先来看一下问题代码(Go 语言实现),这段代码的含义为先从 Redis 当中读取数据,如果 Redis 里没有数据,则访问 DB 获取数据,获取到数据后再 Set Redis 缓存,便于下次访问直接从 Redis 获取数据,减轻数据库压力。
func GetInfoByCache(key string, expired int) interface{} {
strData, errCache := GetCacheData(ctx, key, expired)
if errCache == nil {
return strData
}
ret := GetInfoFromOther(params) //访问数据库
strJson, errJson := jsoniter.MarshalToString(ret[0].Interface())
if errJson == nil {
errSet := SetCacheData(ctx, key, strJson)
if errSet != nil {
ctx.Warning(errSet)
}
}
return ret
}
//调用该方法,传参当中的Redis Key只有一个,为固定值
res:=GetInfoByCache("Redis_Key_Name",60)
如果是熟悉编程的小伙伴,应该知道上述业务逻辑是运用 Redis 缓存很基本的操作,即使是在高并发情况下,Redis 实例一般也能扛住,那问题到底出在哪里呢?
第一个前置条件,调用 GetInfoByCache 方法时,使用到的 Redis Key 是一个大 Key。
另外一个前置条件是,这个 Redis 的 Key 为固定值,在高并发条件下会成为一个热 Key。
热 Key 可能对 Redis 的性能和稳定性产生负面影响,因为它们引起了数据库中的高并发访问。当某个 Key 变得热门时,可能会导致以下一些问题:
在进行压测时,在 Redis 大 Key 和热 Key 的加持下,压测到达指定的 QPS 就会发生下面的性能问题:
首先读取 Redis 开始出现失败,读 Redis 失败必然会进行访问数据库,并写入 Redis,但写 Redis 又是写大 Key,写入超时失败,再次影响 Redis 读请求,越来越多的 Redis 读请求失败,最终造成 Redis 的实例都不可用。
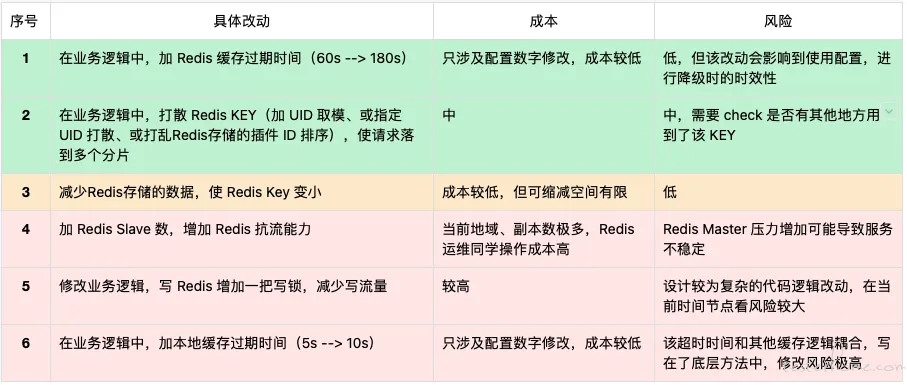
跟开发讨论后,制定了以下 6 种问题的解决方案,权衡成本和风险,最终采用了第 2 种方案:
将 Redis 的 Key 进行打散,这样就能解决 Redis 热 Key 的问题,Redis 读写请求可以落到不同的 Redis 分片上,进而解决了 Redis 实例不可用的性能问题。