
开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement)领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@SSN,@ 鲍勃
1、谷歌发布 3 款 Gemini 实验 AI 模型:1.5 Pro 冲榜第二、1.5 Flash 从第 23 蹿升至第 6
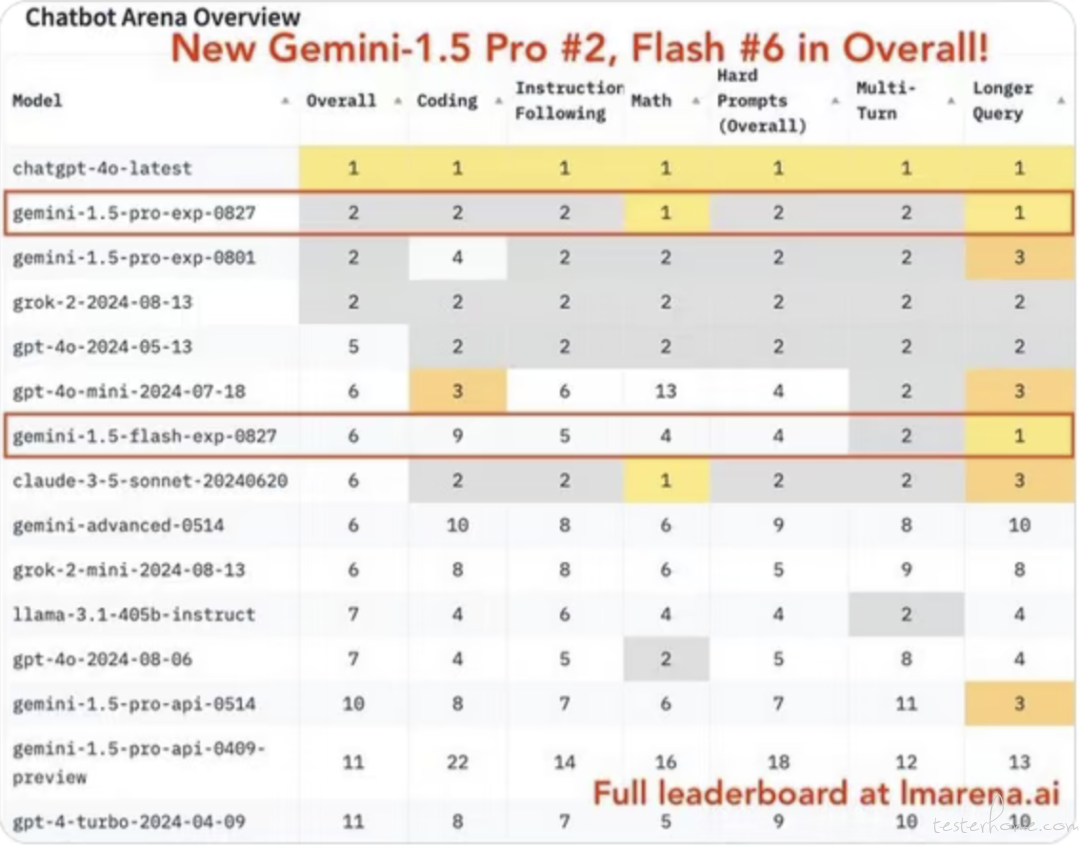
昨日,谷歌 AI Studio 产品总监洛根・基尔帕特里克(Logan Kilpatrick)在 X 平台发布推文,宣布推出 3 款 Gemini 实验性模型。3 款实验性 Gemini AI 模型如下:
Gemini 1.5 Flash-8B
Gemini 1.5 Pro Exp-0827
主要增强编程、复杂提示词,现已通过 Google AI Studio 和 Gemini API 免费提供,名称为「gemini-1.5-pro-exp-0827」。
Kilpatrick 表示,新的 Gemini 1.5 ProExp 0827 型号在各方面都优于 8 月初发布的实验型号,目前在 LMSYS 上的排名为第 2 位,仅次于 OpenAI 的 GPT-4o-latest 模型。
谷歌将于 9 月 3 日起,将 gemini-1.5-pro-exp-0801 模型的请求,自动重定向到新的 gemini-1.5-pro-exp-0827 模型上。gemini-1.5-pro-exp-0801 模型将从 Google AI Studio 和 API 中删除。
Gemini 1.5 Flash Exp-0827
用户可以通过 Gemini API 和 Google AI Studio 访问上述两个模型,名称分别为 gemini-1.5-pro-exp-0827 和 gemini-1.5-flash-exp-0827。(@IT 之家)
2、Freepik Mystic 发布,号称是目前最先进的 AI 图像生成器
Magnific AI 和 Freepik 联合推出了 Freepik Mystic,宣称是目前最先进的 AI 图像生成器,也是唯一可以直接生成全高清图像的 AI 图像生成器。
与 Midjourney 和 OpenAI 的 Dall-E 不同,Mystic 并非基础模型,而是一个结合 Flux 基础模型、微调、高分辨率图像生成技术和参数调整的流程。
Mystic 能够生成高质量的图像,包括写实肖像、动物、风景、奇幻场景、室内设计和建筑概念、像素艺术、游戏元素、表情包等多种类型的图像。这些图像由顶尖摄影师、数字艺术家、VFX 专家和设计师精心策划,并由 Magnific AI 和 Freepik 的内部专家进行微调。Mystic 可以生成分辨率高达 1,664 x 2,432 的 AI 图像,并能够很好地遵循所给定的提示词生成符合要求的图像。
目前,Freepik Mystic 可以通过 Freepik Premium 订阅使用。此外,Mystic 也将登陆 Magnific AI 平台。(@AI 未来)
3、字节开源 FLUX Dev 的 Hyper SD Lora,8 步生图

字节跳动开源了 FLUX Dev 的 Haper SD Lora,大幅度缩短了 FLUX 图片生成的时间。Hyper-SD 提供了一系列基于不同基础模型的 LoRA 检查点,支持 1 到 8 步的推理过程,并且提供了与 ComfyUI 集成的工作流程,以及相关的技术报告和演示。尽管 8 步模型相较于原始版本效果有所下降,但是效果是可接受的。
项目还包括了如何使用这些模型进行文本到图像的生成,以及如何与 ControlNet 结合使用,以实现更精细的图像控制。用户可以通过 Hugging Face 的演示来体验 Hyper-SD 的性能,并且可以通过 ComfyUI 使用 Hyper-SD 的工作流程。(@ 雷锋网)
4、SlowFast-LLaVA:苹果推出的无需训练多模态模型
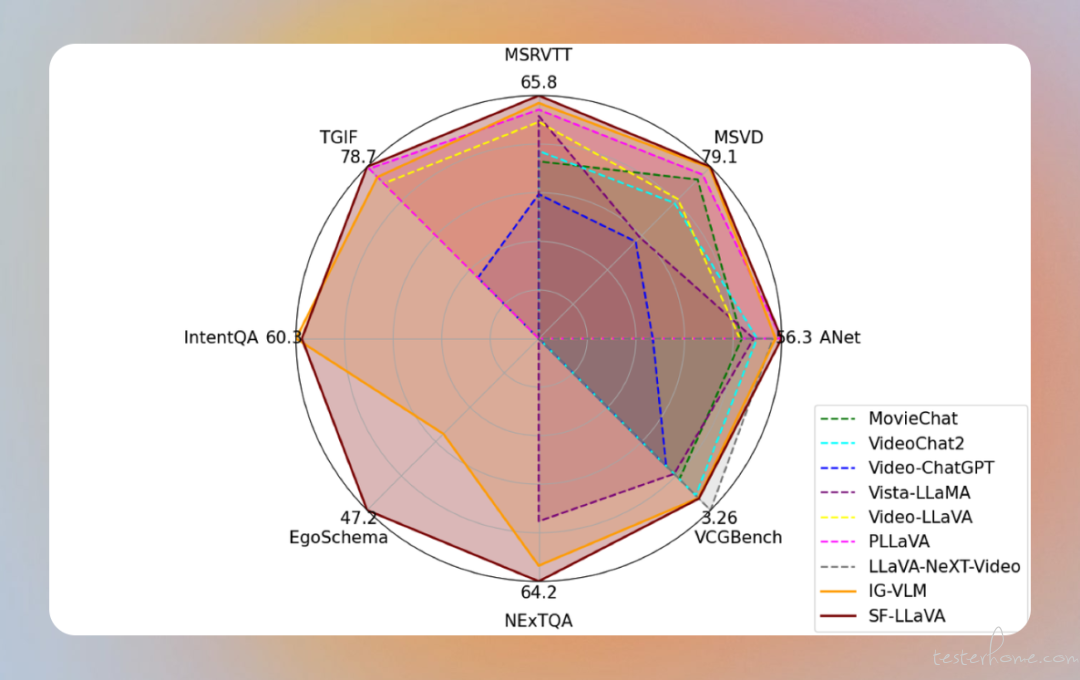
SlowFast-LLaVA 是苹果推出的无需训练多模态大语言模型,专注于视频理解和推理。该模型旨在在不超出常用 LLM 的 token 预算情况下,同时捕捉详细的空间语义和长距离的时间上下文。该项目无需对任何数据进行微调,在广泛的视频问答任务和基准测试中,其性能与最先进的视频 LLM 相当甚至更好。(@ 机器之心 SOTA 模型)
5、安卓 / macOS 版 ChatGPT AI 应用现支持「@」,可无缝切换不同 GPT 模型
科技媒体 testingcatalog 昨日发布博文,报道称安卓版和 macOS 版 ChatGPT 现支持 Mentions 功能,用户在聊天对话中使用「@」字符来调用不同的定制 GPT 模型。
Mentions 是 ChatGPT 的一个重要工具,让用户在一次对话中与多个专门的人工智能模型互动,每个模型都能提供独特的功能来丰富对话内容。
在安卓版 ChatGPT 应用中,用户输入「@」符号之后,会弹出一个窗口,让用户选择不同的 GPT,在保持聊天上下文的时候方便用户无缝切换。
苹果 macOS 平台最新版 ChatGPT 也已上线该功能,但目前 iOS 平台 ChatGPT 仍未上线。(@IT 之家)
1、宇树创始人王兴兴:做机器人,中国缺乏 AI 人才
2024 年不少厂商开始将人形机器人搬到工厂「打工」,比如马斯克让擎天柱在特斯拉工厂「自己造自己」。但从世界机器人大会中会发现,人形机器人距离成为真正的「打工人」还有不小的一段距离。它们并没有展现出能够替代人类劳动力的能力,有的人形机器人连行走都比较困难,需要在吊杆辅助下才能顺利挪步,而有的人形机器人虽然能够演示其检修作业能力——例如对轮胎进行质检,但实际汽车工厂的场景更复杂、工序流程更多。就单纯的轮胎质检环节而言,有一个成本更低的、有视觉感知功能的设备就能完成,而不需要一个成本更高的人形机器人。而在诸如车辆内外饰装饰、道路测试等更复杂并且更耗人力的场景里,机器人的泛化能力不够,尚无法代替人类。
与其说机器人们「进厂打工」,不如说他们是「进厂学习」。目前,机器人企业们还需要进入工厂不断完善数据采集工作,来帮助提升产品的泛化能力。
在世界机器人大会之前,王兴兴分享了他对人形机器人产业现状的观点,他认为,AI 能力不够是机器人行业发展最大的瓶颈。「只有机器人 AI 的能力能突破一个临界点,工厂里的一些工序才能跑起来,机器人才能比人效率更高」,但是「中国的 AI 人才欠缺,对 AI 的人才培养力度不太够」,并且王兴兴认为「跟通用 AI 的发展相比,机器人 AI 的整个行业,落后了 10 年左右。」
虽然硬件层面也会对机器人发展形成桎梏,但王兴兴认为「硬件没有理论上的门槛,它是工程上的问题,在工程上把成本做得更低,做得更好,外观也做得更加极致,硬件功能也更加丰富。」
虽然机器人行业存在软硬件困境,但王兴兴表示行业会越来越好,因为「这个行业越来越热了,有更多的聪明人,更多的钱,更多的关注参与进来。(@ 腾讯科技)
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
