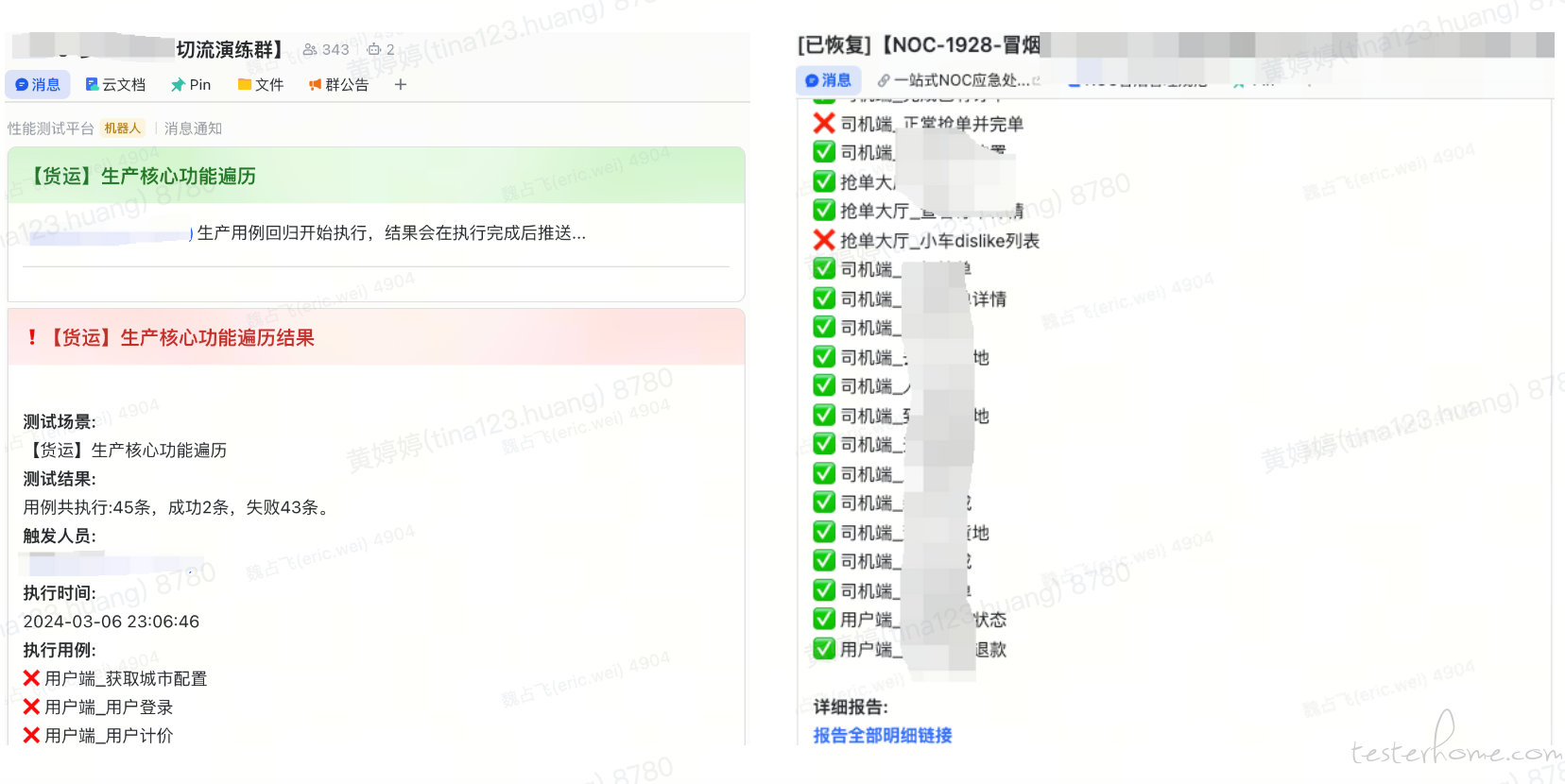
为实现全链路压测的自动化,主要目标是把人工操作的重复工作自动化。在确定整体方案后,我们详细梳理了全链路压测前、中、后的常见工作场景,并确认了对应的需求以及平台服务支撑。以下是我们的整体改造思路图。
作者简介:
魏占飞,来自货拉拉/技术中心/质量保障部,测试专家,负责货拉拉性能测试领域的质量保障和效能建设工作。
陈婷婷,来自货拉拉/技术中心/质量保障部,资深测试工程师,负责货拉拉货运性能压测保障和效能建设工作。
在过去的几年里,货拉拉的用户和货运订单数量都实现了快速增长,现已发展成为全球最大的闭环物流交易平台。随着订单业务的飞速发展,系统稳定性的保障变得越来越重要,全链路压测在保证系统稳定性的过程中发挥了关键的验证作用,其目标是检验系统的稳定性和容量。然而,在业务快速迭代和高速增长的背景下,全链路压测也面临着更高的需求和挑战。
及时验证峰值容量: 随着业务的高速发展,订单量常常会突破历史峰值,甚至曾在半个月内多次打破记录。因此,我们必须确保压测能够及时验证服务的总体容量以及单个服务扩容后相关链路的稳定性。
提升压测效率: 传统的全链路压测是一项较为繁重的测试活动,它不仅涉及多个部门和人员,还需要核心服务的开发人员进行值班。此外,还包含了较多的脚本维护,复杂的造数,以及较长的压测流程。若要求能够实现及时、高效的全链路压测,我们必须提升测试工作的效率,同时减少对值守人员的依赖。
保障压测安全性: 全链路压测通常是在生产环境中进行,压测所产生的大流量可能导致某些服务的响应变得不稳定,甚至可能引发连锁反应,影响到更多服务并导致线上真实故障的发生。因此,在压测过程中要具备熔断机制,在服务被压崩溃前及时停止压测流量,保障系统稳定运行。
在构思初始方案时,我们在行业内寻找并比对类似的解决方案,但是发现相关资料较少。由于全链路压测和压测自动化都需要与公司业务和内部平台频繁交互,我们在考虑改造全链路压测自动化时,决定结合公司业务特点和现有全链路压测流程以及内部平台特性进行改造。
为实现全链路压测的自动化,主要目标是把人工操作的重复工作自动化。在确定整体方案后,我们详细梳理了全链路压测前、中、后的常见工作场景,并确认了对应的需求以及平台服务支撑。以下是我们的整体改造思路图。
梳理出改造场景中的重点和难点问题,我们需要着重完成以下功能:
模型建模与模型效果对比: 无论是在压测场景和流量的配比,还是在压测后的效果对比中,都需要我们找到一个适合的模型算法,以确认压测场景的模型以及对比压测效果。
压测任务编排: 在压测任务中,一些任务有固定的时间顺序或因果关系顺序。这就要求我们需要有一个灵活的任务编排系统,方便自由地编排相关压测任务。
压测任务调度: 以货拉拉货运全链路压测为例,每次涉及到超 70 个脚本,300 余台压测机,以及数百万订单的压测目标流量。因此,如何对测试场景、脚本和测试数据以及压测流量进行有效的管理、分发和收集显得尤为重要。
健全的熔断机制: 既要检测出系统瓶颈,又要在出现异常时及时停止压测流量,以避免引发更大的生产问题,因此需要一个健全的熔断机制。
全链路压测自动化的整体能力建设内容繁多,我们将以重点改造为例,列出相关的思考和部分实现原理。
压测模型,简而言之,就是设定被压测的各个服务及其相关接口的具体目标 QPS 比例,压测流量模型应尽可能接近线上真实流量。模型自动化在全链路压测的整个过程中有各种应用场景,其中包括在压测前建立压测模型,在压测过程中调整压测场景,以及在压测后对比流量模型。
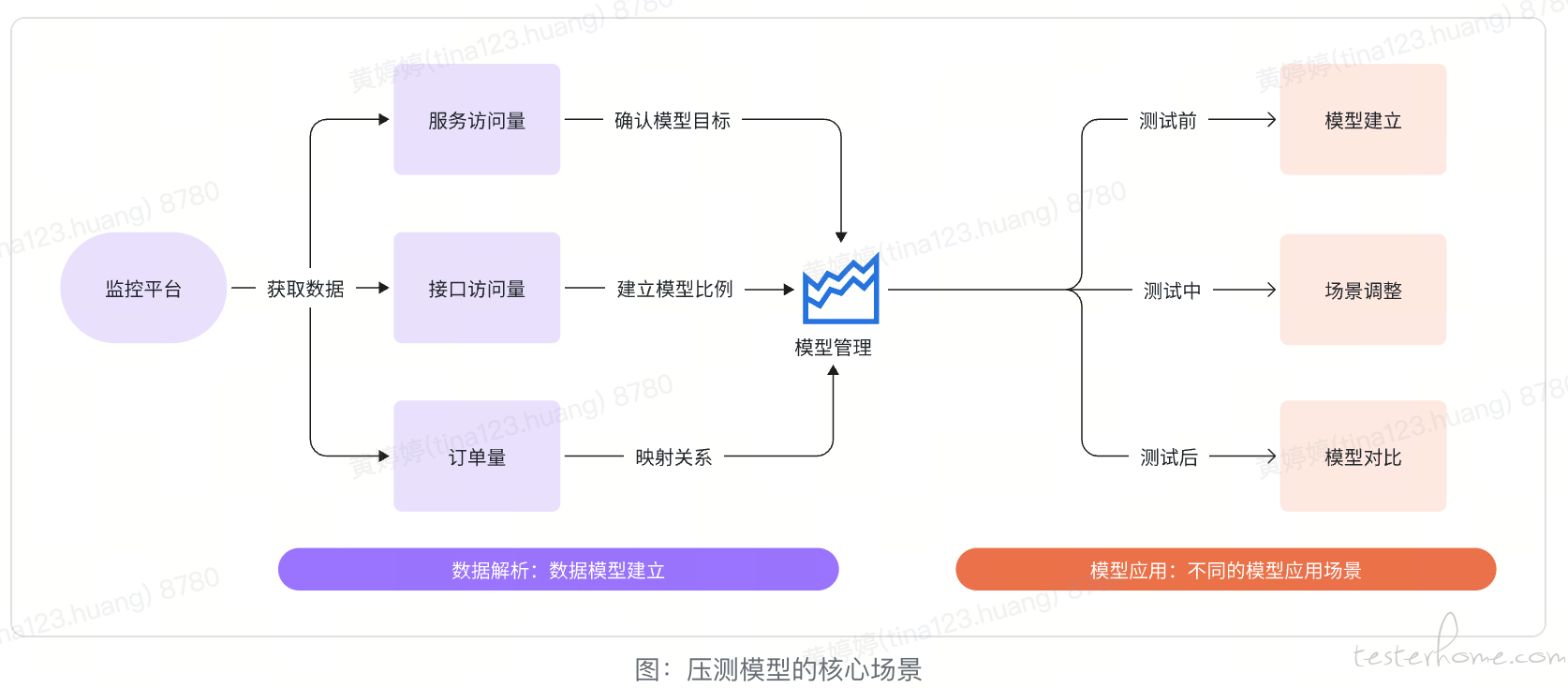
当服务数量有限时,通常可人工处理各服务接口的请求量并配置对应压测流量比例来建立模型。但在大型项目全链路压测中,接口数量和脚本量的增长使这成为了压测人员最繁重的任务之一。且在人工配置过程中可能出现疏忽,导致流量比例失真。
对于压测模型的构建,我们首先从公司监控平台获取主要相关数据,然后进行关联和模型转换,最终定时生成各服务不同指标的峰值流量模型。
/**简化代码,只保留主要流程信息,
*从监控平台获取相关服务数据,并转化为压测模型保存在压测平台
*/
public PressureModel getAndSaveOneDayMonitorData(String appId, String env, String name, String batchId, long start, long end, long step, MonitorData orderMonitorData) {
PressureModel model = new PressureModel();
String timeScope = StrUtil.isEmpty(orderMonitorData.getTimeScope()) ? MonitorData.TIME_ALL_DAY : MonitorData.TIME_CUSTOM;
//soa监控数据获取并转换模型
HashMap<String, MetricIntegratorData> monitorQpsSoaData = getMonitorQpsSoaData(env, appId, false, start, end, step);
List<MonitorData> monitorQpsSoaDataFromMetricDates = getMonitorDataFromMetricDates(appId, env, name, batchId, MonitorData.TYPE_QPS_SOA, MonitorData.TYPE_QPS_SOA, timeScope, monitorQpsSoaData);
if (!monitorQpsSoaDataFromMetricDates.isEmpty()) {
monitorDataRepository.saveAll(monitorQpsSoaDataFromMetricDates);
model = MonitorDataUtil.transitionPressureModel(model, monitorQpsSoaDataFromMetricDates, orderMonitorData);
}
//获取其它关键信息如SOA,CPU,Mysql,Redis等,均保存到模型model中。
pressureModelRepository.save(model);
}
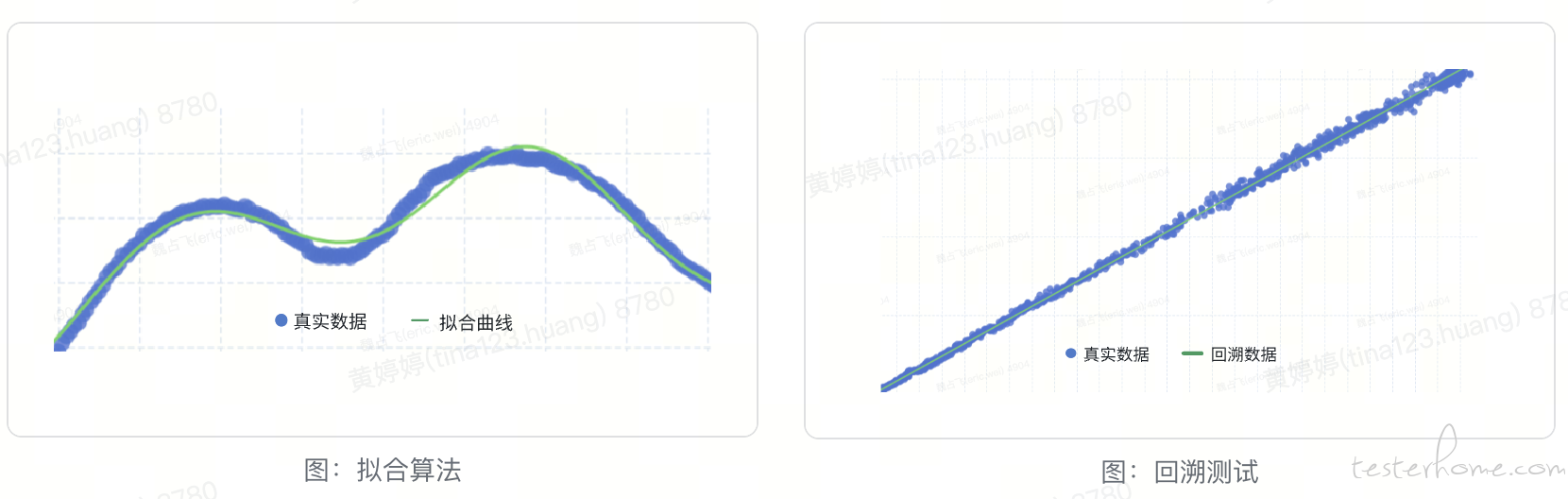
在模型算法方面,我们在压测初期采用了业务峰值时间段峰值算法,随后发现各个服务和预测订单量的比例关系并不固定。为了细化不同级别预测订单和各服务的目标流量的系数关系,我们结合公司的订单量和业务特点,采用了以下的拟合算法:
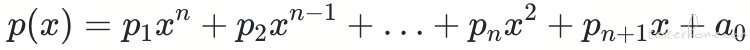
通过这样的模型,可以方便地计算不同订单级别对应的模型缩放系数,在各个订单级别的压测任务中,可以快速得到相应服务的模型数据。通过对模型数据和真实数据的回溯对比,我们发现模型和真实数据的贴合度相当高(已对相关数据进行脱敏处理)。
为了更精确地进行压测,除了获取整体服务的压测模型外,我们还需要获取各个服务的接口流量模型,即确定压测模型所在时间段内的接口使用比例。根据这些信息,系统会自动调整压测脚本的接口比例并自动上传脚本,从而使每次压测更接近最新的业务模型。
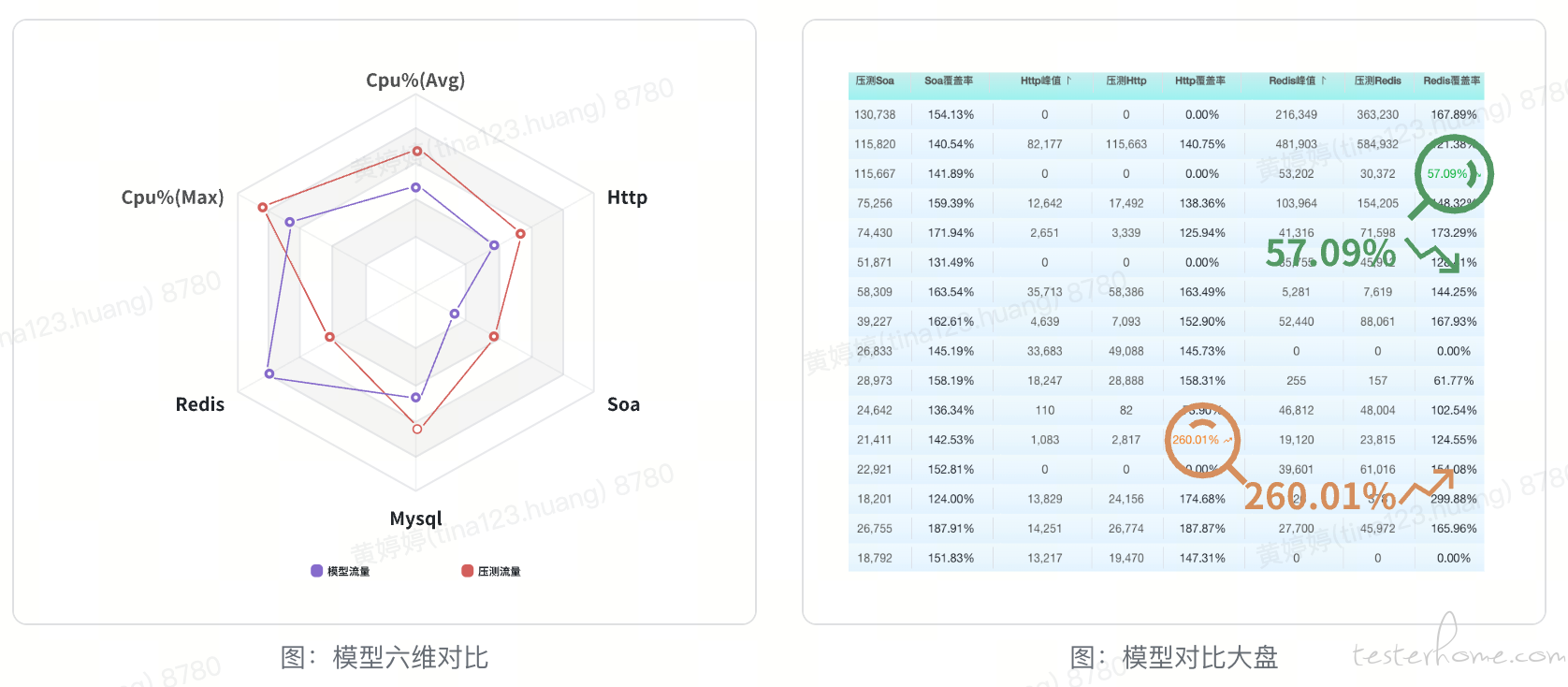
由于压测服务中存在业务分支处理和缓存关系,实际的压测过程中常会发现压测流量覆盖不全。为全面评估压测效果,在每次压测后,对压测时间段内的压测流量单独建模,并通过 Cpu%(Avg)、Cpu%(Max)、Http、Soa、Redis、Mysql 六个维度的峰值模型与压测模型进行对比,以便及时发现异常流量,并针对性优化,使全链路压测的流量更接近真实业务。
在没有模型效果对比之前,主要是关注入口服务及被动等待开发反馈异常流量,常常会遗漏部分压测流量异常的服务,影响压测效果。通过模型效果对比,可在每次压测后快速发现压测过程中的异常流量服务,以便及时针对性优化,使全链路压测的流量更接近真实业务。
在全链路压测过程中,我们常会遇到一些前置条件,如数据初始化,压测信息通知等。我们通过梳理将压测活动分为五大类:运行脚本、运行场景、申请压测机、释放压测机、消息通知。我们抽象出任务的共同行为,并将任务执行前、执行中、执行后的相关操作集中处理或单独定制,这大大减少了前后端的代码量,并增强了后续扩展性。
public abstract class AbstractTaskNodeService implements TaskNodeService {
protected TaskNode taskNode;
public AbstractTaskNodeService(TaskNode taskNode) {
//代码已简化
this.taskNode = taskNode;
init();
preExecute();
execute();
postProcessor();
}
@Override
public void init() {
//解析出对应的上下文,及数据处理工作
}
@Override
public void preExecute() {
//执行预处理动作,包括获取兄弟节点任务
}
@Override
public void execute() {
//执行任务,每一种任务类重写
}
@Override
public void postProcessor() {
//保存状态,生成下一节点任务
}
@Override
public TaskNode getTaskNode() {
return this.taskNode;
}
}
在不同的压测场景下,我们可以根据特定需求,对压测任务进行流程编排和组合,来实现压测流程的个性化定制。
以货拉拉的下单运货业务场景为例,需要预先设定用户和司机的位置,确保在特定范围内,用户能看到足够的司机,司机也能看到足够的订单。因此,压测前需要通过打点脚本将相应的用户和司机部署到不同的位置,这样不仅能更符合线上真实情况,同时也避免了数据热点问题。

在此类场景下,需要将位置打点脚本放置在压测场景之前,以便提前更新司机位置信息。在其他不同的压测场景下,可能存在不同的要求。人工处理不仅时间紧张,而且易出错,因此,通过编排对应的任务流,我们可以灵活地实现不同压测场景的组合。
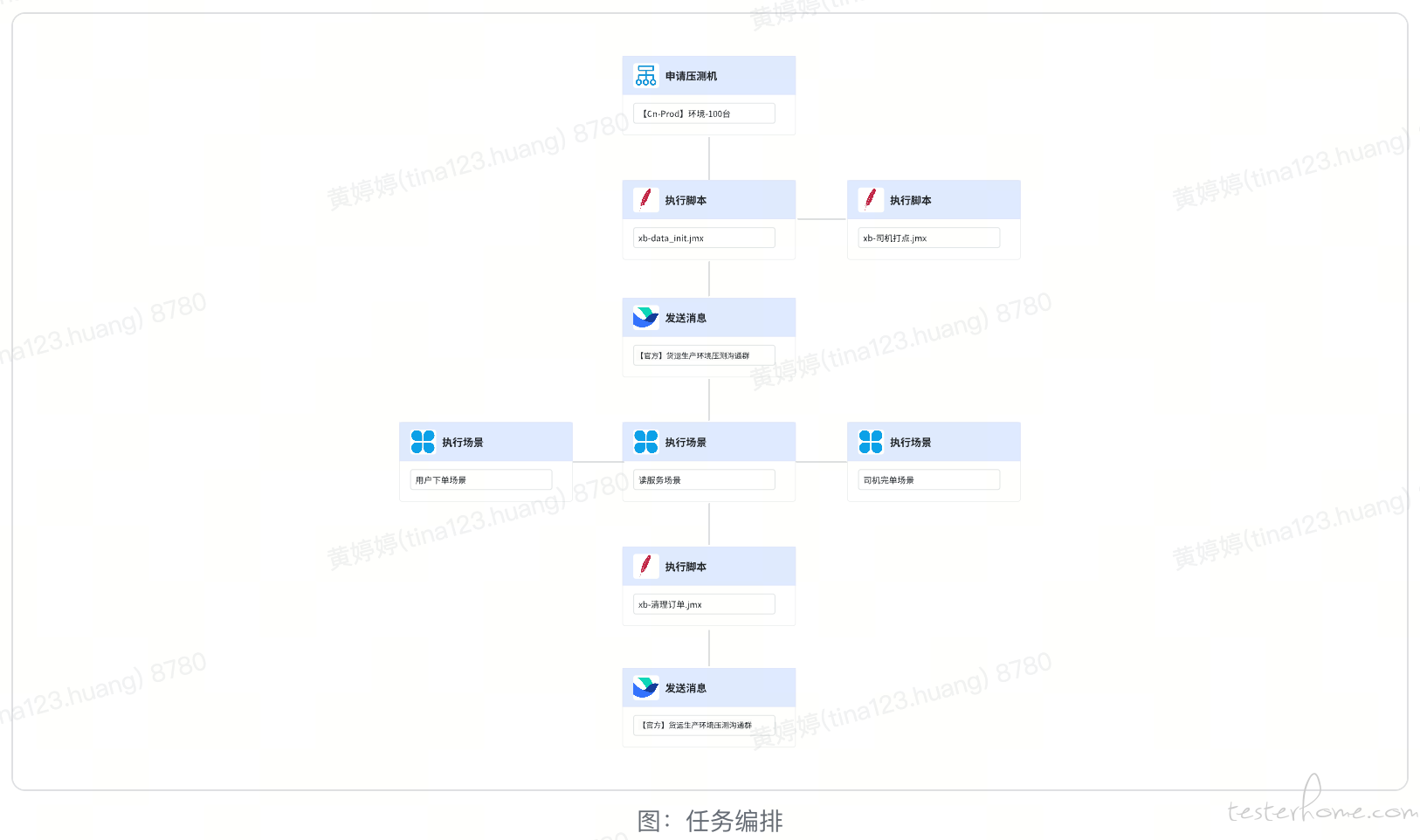
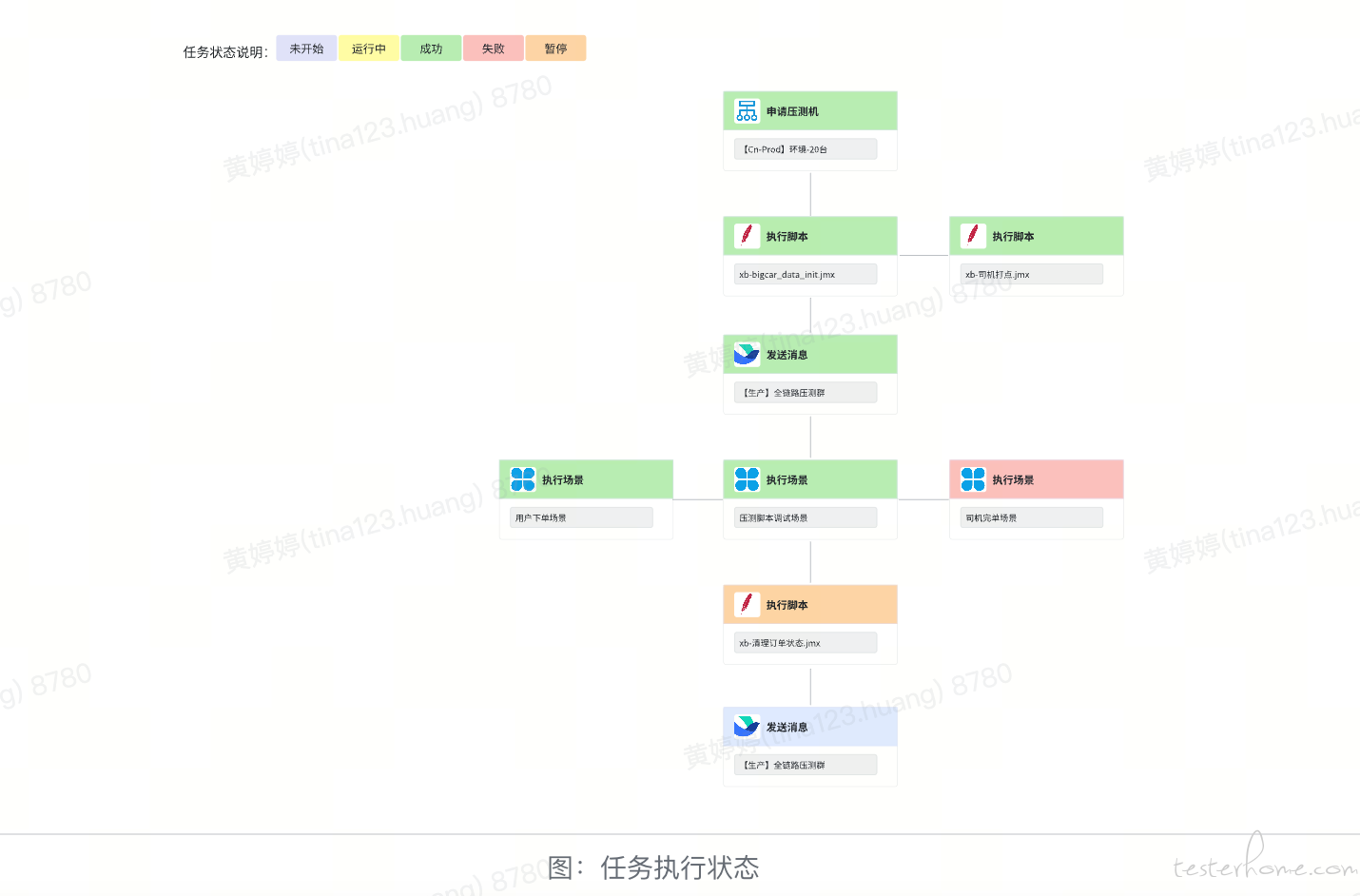
如果在压测过程中遇到需暂停压测的紧急情况,我们可以暂停或结束当前正在执行的任务。在问题得到处理之后,可以继续执行当前任务节点,或者执行下一个任务节点。
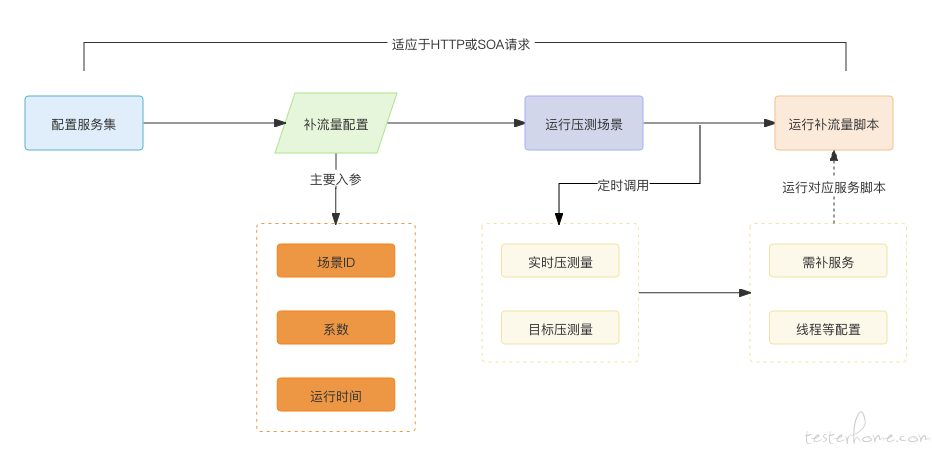
压测任务调度是把各种需求的压测脚本、压测文件、压测数据,根据需要分配到不同的压测机上,压测启动后对压测流量进行实时监控和补充,并收集汇总相关压测指标的过程。在小规模的压测任务中,可以通过手动部署原生 Jmeter 压测集群,然而,在大规模压测中,原生集群的性能瓶颈非常明显。因此,如何高效地分配任务和收集压测数据是压测平台需要解决的问题。
不同规模的压测需要不同数量的压测机,以货运全链路压测为例,每次压测需要约 300 台压测机,加上日常的其它的压测任务,需要的压测机数量会更多。货拉拉的最初采用 ECS 集群部署,在达到约 200 台时压测机规模时,其硬件成本已经比较高了,后把压测机改造采用 Serverless Container 弹性容器实例,通过 ASK 竞价申请 POD 资源,1 分钟内可完成 500 台压测机的申请与部署,在申请后,及时进行压测任务后自动或手工释放,使压测机的硬件成本得到了大幅降低。
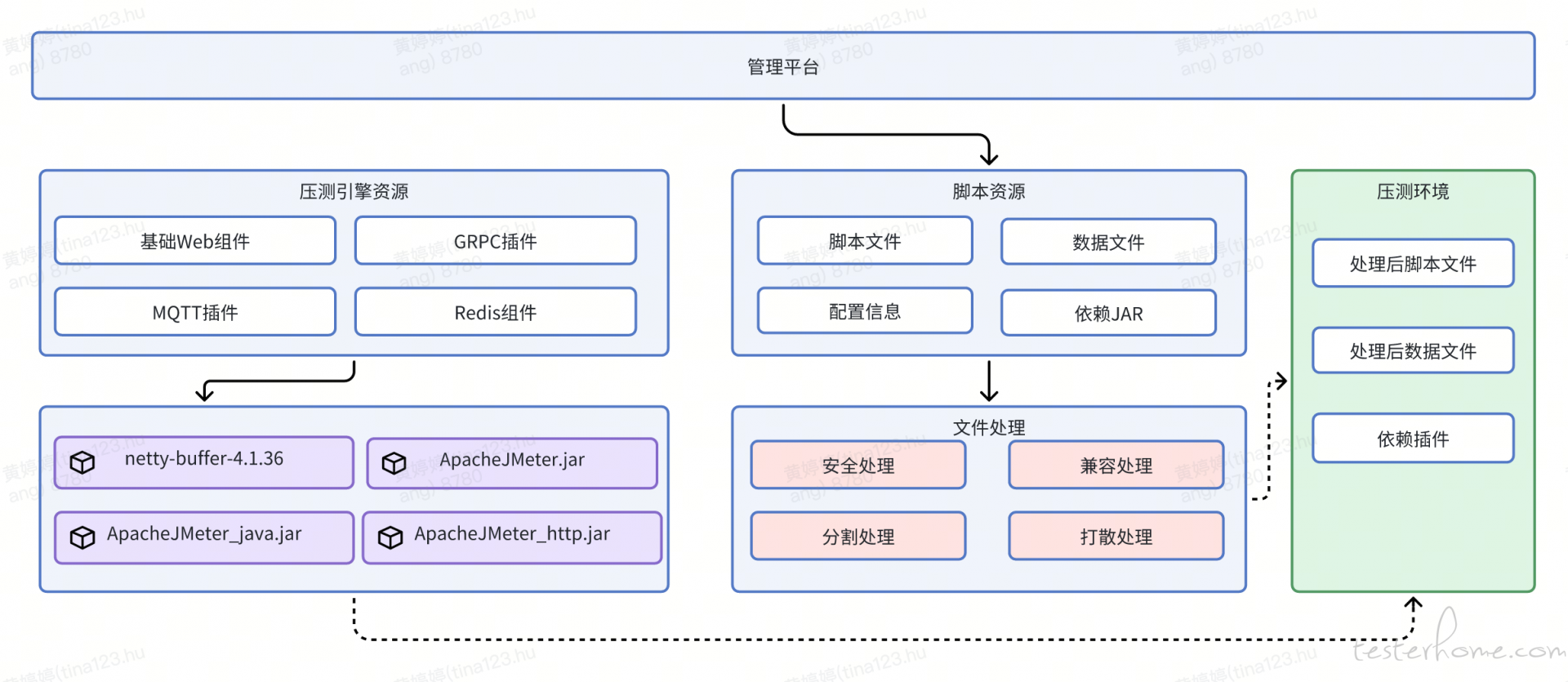
同时,压测机资源还会根据不同项目、不同申请人、公用、私用等维度进行管理,普通用户可使用自已申请的、当前项目拥有的及公用的压测机进行压测,使压测机资源的综合利用率更高,压测启动后会先把压测任务所需要的压测资源分发到对应权限的空闲压测机中。

平台在执行具体的压测任务后,会拆分压测任务的场景、脚本、数据文件及依赖 JAR 包,并按照一定要求把对应的脚本和数据文件分发到对应的目标压测机,这中间涉及到任务的分发,文件的下载与预处理,同时为了避免压测机在各项目之间的文件冲突、数据冲突或 JAR 包冲突,还需要对相关文件做对应处理后放入纯净的压测空间。
压测启动后,对于压测流量经常会遇到两种场景,一种是配置了流量目标,但通常因为服务响应或线程配置没有达到预期流量;另一种因业务缓存或业务分支处理问题,流量无法传递到下游服务。针对这两种情况,我们采用自动加压和自动补流量来解决。
自动加压:在压测过程如果开始设置的线程数和机器数无法达到预期流量,平台能够提供自动加压功能,自动增加线程数或者压力机来达到测试目标,在有限的压测窗口期,自动追加压力,减少了测试人员时间以及资源成本。 当压测过程中发现 QPS(每秒接口请求数)未达到预期时,无需停止本轮压测,系统可以自动探索出需要的线程数,并自动增加线程,以及用户可以手动增加压测机,以追加压测,节约了时间、人力、硬件成本。
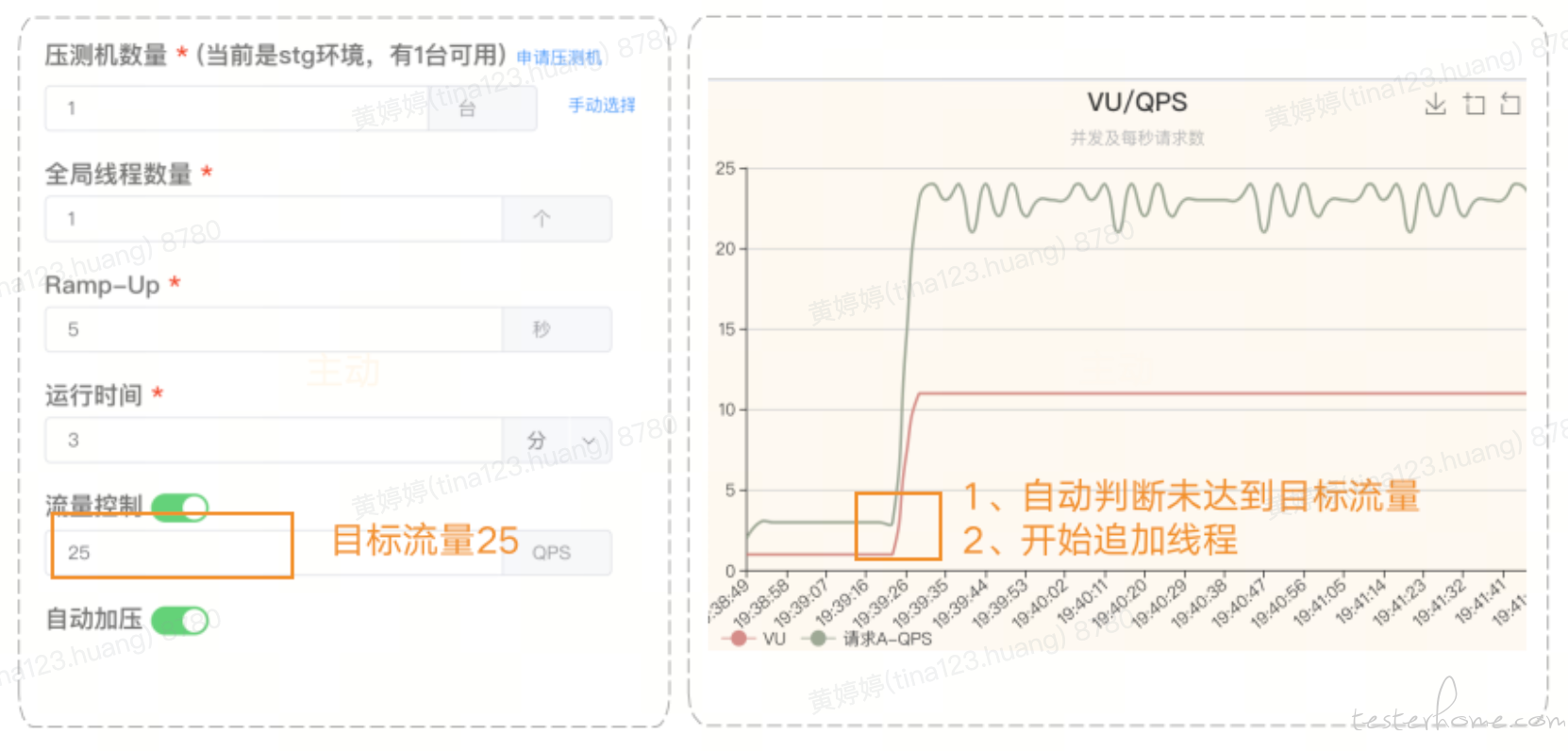
自动补流量: 全链路压测中由于缓存和业务分支处理等因素的影响,部分流量无法有效传递到下游服务,在这种情况下,我们需要人工启动下游服务的相关脚本,以补充缺失的流量。然而,由于涉及到的下游链路高达数百个,在一次压测周期内,很难及时通过手工补全缺失服务的流量。结合压测模型对比,提前准备补流量的脚本,在压测时压测平台计算压测流量是否满足要求,以及需要补充的流量多少,自动启动相应的脚本,进行流量补充。
在全链路压测进行过程中,需要实时关注压测相关指标,及时进行收集和汇总,给压测任务提供数据指标及风险参考,各压测机把自身的压测数据通过监听器实时发送到 Kafka,再由收集服务进行统一汇总,在汇总数据后进行展示或结合其它策略进一步利用。压测机的数据采用每秒收集汇总并发送一次,收集服务的收集器采用每 3 秒收集汇总一次,尽可能保证的数据实时性并减少指标图表的曲率的变化频率。
//压测机初步收集汇总本机数据,并发送到kafka
@Slf4j
public class HllBackendListenerClient extends AbstractBackendListenerClient {
@Override
public void setupTest(BackendListenerContext backendListenerContext) throws Exception {
//压测设置项
}
@Override
public void handleSampleResults(List<SampleResult> list, BackendListenerContext backendListenerContext) {
//压测数据处理并发送
}
@Override
public void teardownTest(BackendListenerContext backendListenerContext) throws Exception {
analysis();
schedule.shutdown();
}
private void analysis() {
//压测机初步数据统计
Collector<YiSample, SampleState, SampleState> c = Collector.of(
SampleState::new,
SampleState::accumulator,
SampleState::combiner,
SampleState::finisher
);
Map<String, SampleState> sampleStateMap = temp.stream()
.collect(Collectors.groupingBy(YiSample::getLabel, c));
}
}
//收集服务消费KAFKA并统一汇总数据
@Slf4j
public class AnalysisProcessor implements Processor<String, String> {
private ProcessorContext context;
private AtomicInteger processorNumber = new AtomicInteger();
PerformanceRecordRepository performanceRecordRepository = SpringContextUtils.getBean(PerformanceRecordRepository.class);
ReportRepository reportRepository = SpringContextUtils.getBean(ReportRepository.class);
private ConcurrentHashMap<String, List<SampleState>> sampleMap = new ConcurrentHashMap<>();
@Override
public void init(ProcessorContext context) {
//1.初始化
this.context = context;
processorNumber.getAndIncrement();
if (processorNumber.get() <= 1) {
this.context.schedule(Report.REPORT_INTERVAL, PunctuationType.WALL_CLOCK_TIME, (timeStamp) -> analysis());
log.info("init AnalysisProcessor");
}
}
@Override
public void process(String key, String message) {
//2.压测数据处理
SampleState sampleState = JSON.parseObject(message, SampleState.class);
if (!sampleMap.containsKey(key)) {
List<SampleState> list = new ArrayList<>();
sampleMap.put(key, list);
}
sampleMap.get(key).add(sampleState);
}
@Override
public void close() {
}
private void analysis() {
sampleMap.forEach((reportId, sampleStates) -> {
if (sampleStates.size() == 0) {
sampleMap.remove(reportId);
}
long start = System.currentTimeMillis();
Collector<SampleState, PerformanceRecordState, PerformanceRecord> c = Collector.of(
PerformanceRecordState::new,
PerformanceRecordState::accumulator,
PerformanceRecordState::combiner,
PerformanceRecordState::finisher
);
//汇总性能数据
Map<String, PerformanceRecord> reportRecord = sampleStates.stream()
.collect(Collectors.groupingBy(SampleState::getLabel, c));
AtomicInteger i = new AtomicInteger();
reportRecord.forEach((label, record) -> {
PerformanceRecord saveRecord = performanceRecordRepository.save(record);
i.getAndAdd((int) saveRecord.getN());
});
log.info("analysis report:{} once,it has {} record ,and {} samples ,used:{}ms ", reportId, sampleStates.size(), i.get(), (System.currentTimeMillis() - start));
//清空此批数据
if (sampleMap.containsKey(reportId)) {
sampleMap.get(reportId).clear();
}
});
}
}
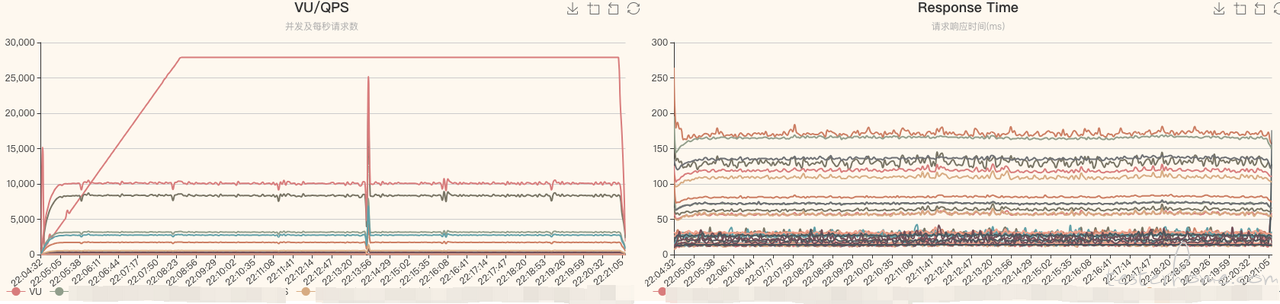
最终对汇总的数据通过不同维度进行展示,达到实时观察需要或做为熔断条件的前置数据。
报告汇总:

接口数据:

性能曲线:
压测的熔断机制是压测活动的一道保险,全链路压测因为是在线上真实进行操作的,在服务有资源风险、性能问题或是压力过大时会引起服务响应异常,需要及时停止压测,避免造成连锁反应造成生产故障。
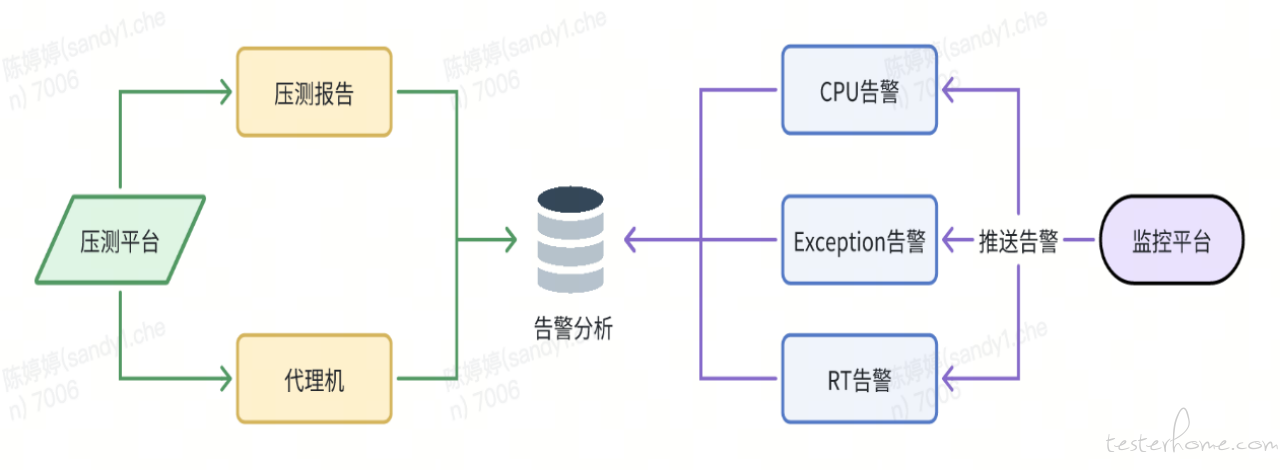
根据压测流量发起方的相关指标如接口错误率、响应时间做为判断指标,由压测平台根据压测数据,主动判断当前压测是否需要发起熔断,从而停止压测。
主动熔断相关指标通过压测脚本的相关配置不同的阈值,在启动压测并收集压测结果时加入熔断规则的判断,触发阈值或达到指定规则后进行熔断。
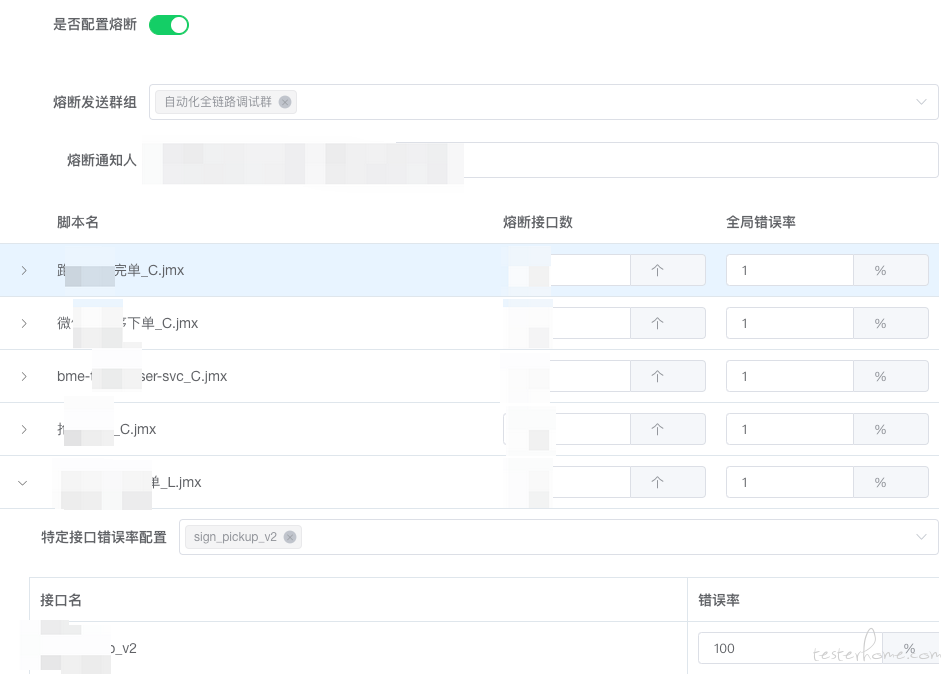
由货拉拉其它如监控平台、数据库管理平台等公司内部系统平台的相关数据指标或报警为触发条件,并调用压测平台的报警信息接口,压测平台接受报警信息后进一步处理和判断,如果符合条件则会停止压测。
全链路压测自动化在上线的一年时间内,在效率、成本、压测效果上都取得了显著的成果。
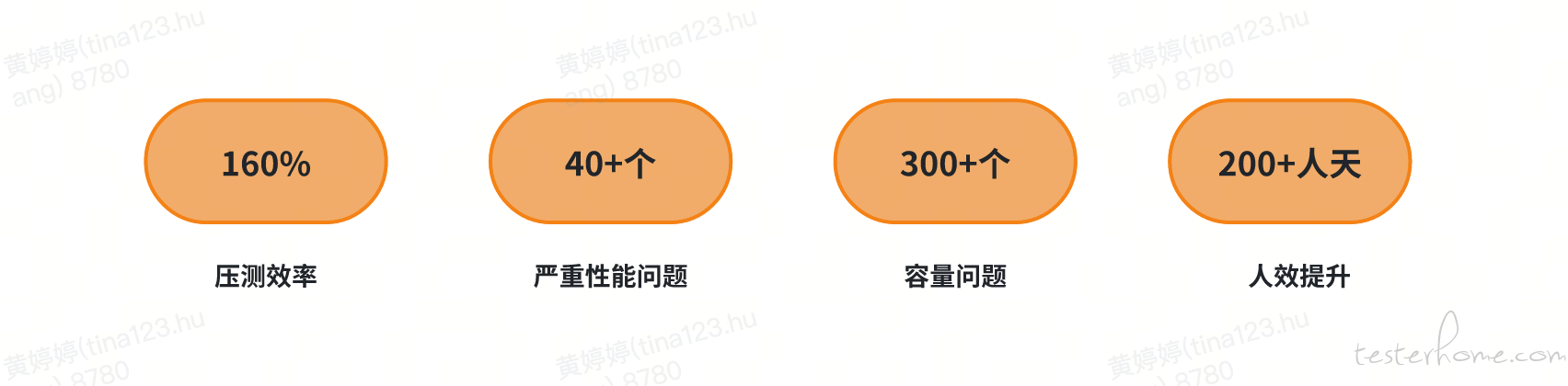
压测效率:对比 22 年的全链路压测,最直观的改变为压测频率的提升,从双周一次提升到每周一次。并具备当天实时发起全链路压测能力,能够对新的峰值做出更迅速的验证。
成本优化:相较于以往全链路压测需 30 多名开发值班和测试人员一起参加压测,如今自动化压测只需压测同学进行压测即可,人力成本节省 80%+。同时随着压测机采用容器化改造,硬件成本节省了 90+% 以上。
压测效果:通过模型优化和压测模型效果对比,可及时优化压测流量偏差较大的场景,服务的压测覆盖度和压测流量的合理性都得到了显著提升。经过对每个服务的压测流量和峰值流量的合理区间进行统计,发现有效覆盖率已从最初的 43% 提高到了 90%。
从过去一年压测自动化实践来看,在压测成本、压测效率及压测效果来看都有了较高的水准,在今年主要在以下方面进行探索尝试。
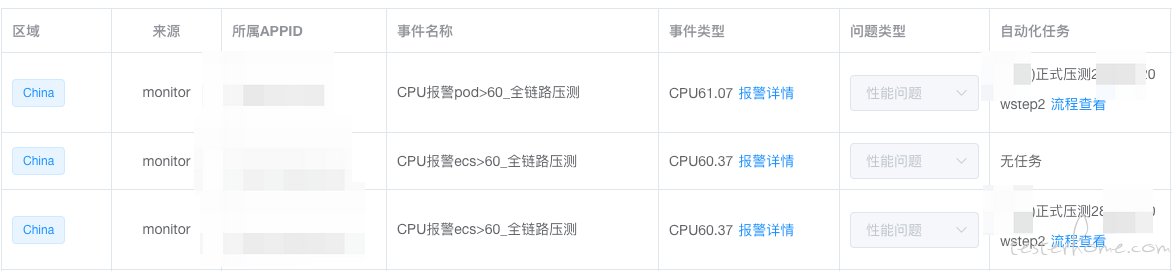
性能测试大模型:目前我们对压测的数据只是简单的通过 CPU 使用率和各种 QPS 来提醒开发是否进行扩容(如下图),在大模型愈发成熟的趋势下,我们希望对压测数据方面通过 AI 分析进一步发掘,提高发现性能隐患及性能隐患分析能力。

压测服务化提高: 在过去压测平台了提供了一些在特定场景的服务化能力,如与故障演练平台打通直接发起压测流量、与 NOC 打通提供线上的核心功能遍历能力(如下图)。大部分压测仍需要通过脚本编写&调试、数据准备、压测各种环节,在未来会进一步结合流量回放平台、精确测试平台等平台的服务能力,通过自动生成压测场景,逐步提供更多的服务化能力,进一步提升工作中性能测试的效率。