打开浏览器,输入网站之后,进行一个屏幕截图(用于获取你电脑屏幕的分辨率)
然后在截图中标记出来你的操作(即点击的位置,类似于这种),该标记可以通过调用大模型 OCR 识别,先找出执行顺序,然后找到对应顺序(红色数字)(的可点击区域(红色方框)
大模型识别出来之后,可以在页面上面进行显示。然后可以对这一步骤 做前置和后置的操作
个人做软件测试也有三四年的时间了,对于 UI 自动化这一块的工具想说一下自己的看法。
我这几天在网上搜了一下 AI 在 UI 自动化方面中的文章,发现都还是之前的样子。基本上都是使用 AI 和机器学习技术来增强元素定位的可靠性。传统的元素定位方法(如 XPath 或 CSS 选择器)在页面结构变化时容易失效。然后最近由于个人也学习了一些大模型方面的知识。于是有了下面的一个想法:
打开浏览器,输入网站之后,进行一个屏幕截图(用于获取你电脑屏幕的分辨率)
然后在截图中标记出来你的操作(即点击的位置,类似于这种),该标记可以通过调用大模型 OCR 识别,先找出执行顺序,然后找到对应顺序(红色数字)(的可点击区域(红色方框)
大模型识别出来之后,可以在页面上面进行显示。然后可以对这一步骤 做前置和后置的操作
4.这里说一下跳转(其实跳转在截屏这一步骤就包含了,我们可以这样做)
然后就是上传文件(这个其实我个人不太懂,我预期是 还是调用截屏。毕竟你做自动化的时候,你的鼠标和眼睛是当前页面,因此我通过点击屏幕也可以实现的)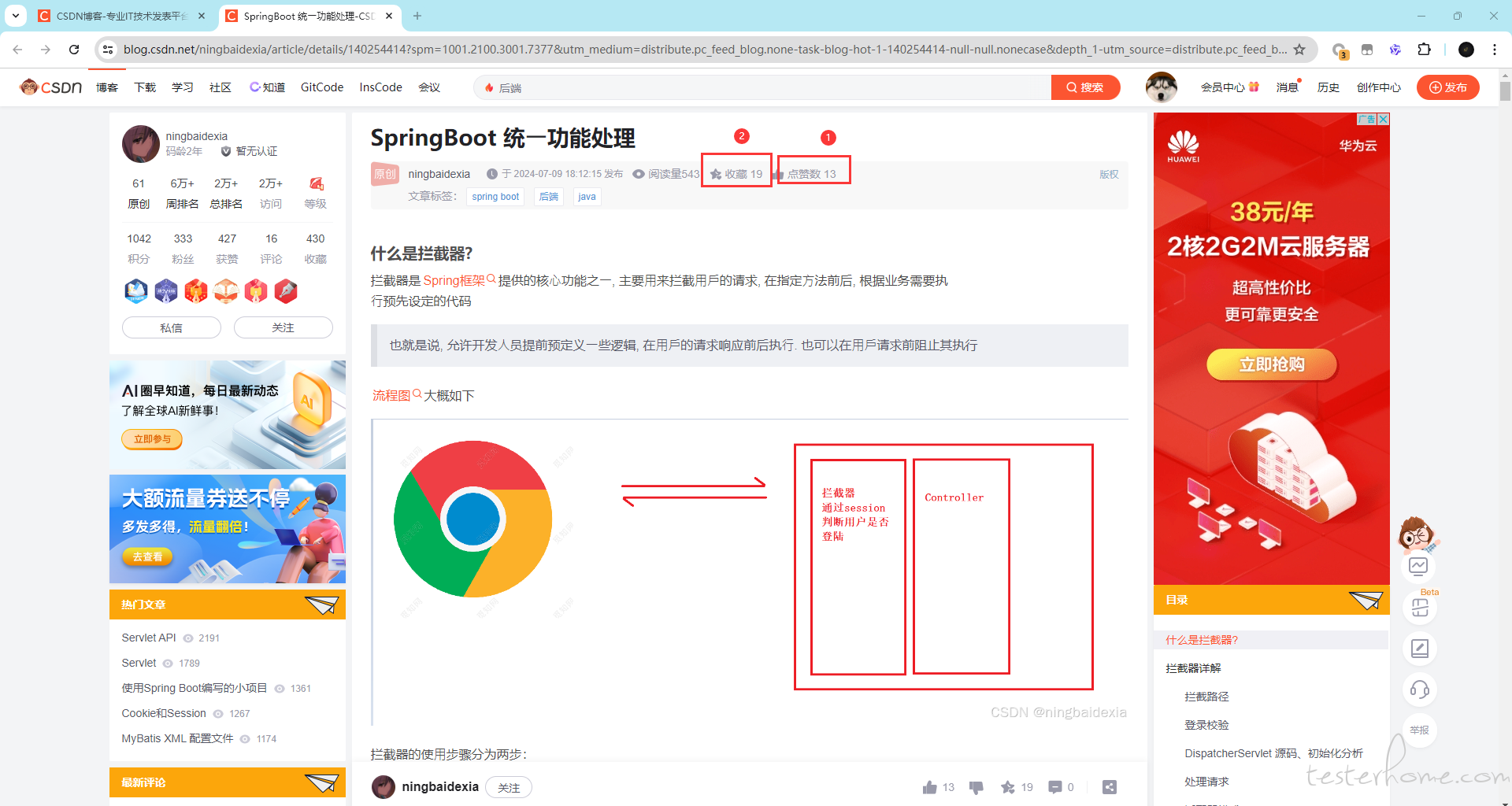
然后是最重要的 确认数据正确性(比如我在这个页面添加一个文章,我需要看下列表是否会展示,或者我提交了一个数据,看一下另一个页面的数据是否 +1 等等)这一步我们也可以通过 OCR 实现,就是在前置或者后置中加一个区域识别,比如下面这张图,(我们默认测试数据是固定死的,即每次测试完,数据清理。回到初始状态,比如这里的收藏和点赞数,初始为 0,我预期是 2,如果识别出来不是 2,则用例失败,并截图这样子)
