tips:llama.cpp 可以量化模型解决模型在电脑上跑不动的问题,而 ollama 则是解决量化后的模型怎么更方便的跑起来的问题
一:hugface(需要一些科技狠活)
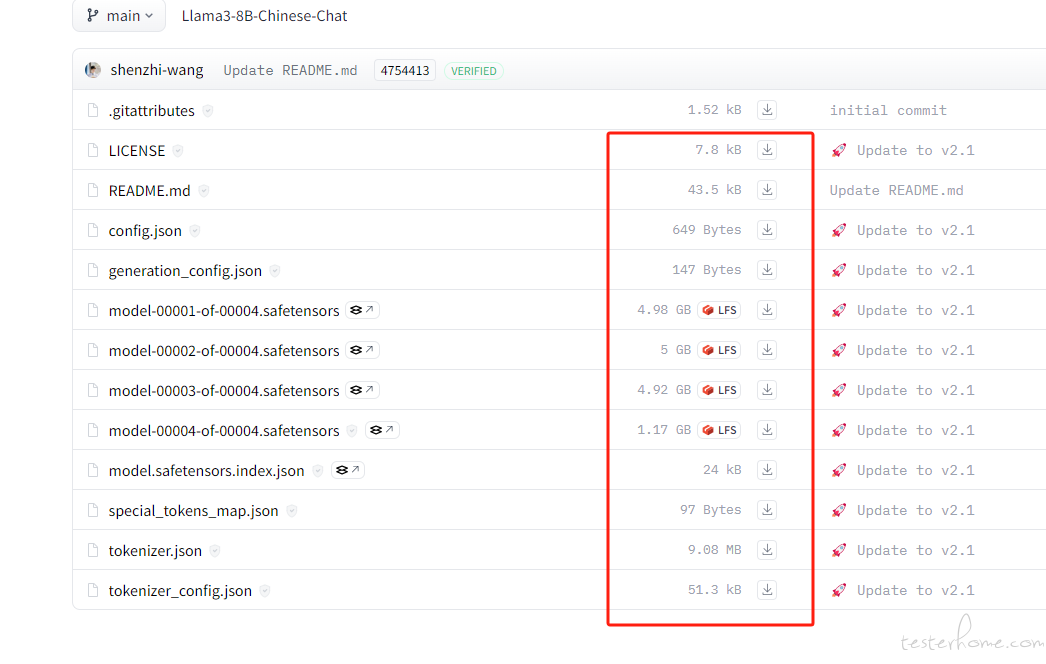
1)、找一个适合自己的https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat/tree/main2B/7B/8B 即可。,新手自己玩建议
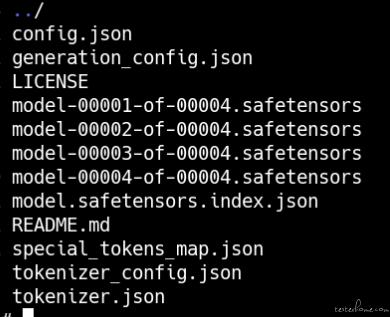
2)、下载模型,这些都需要下载,下载后形成本地目录
二、利用 llama.cpp 进行量化
1)、git clone https://gitee.com/tan_fu_xiang/llama.cpp.gitgit( clone https://github.com/ggerganov/llama.cppmake 后有文件丢失,待分析)官网这个
2)、cd 到 llama.cpp 目录,执行 make 命令

3)、进行格式转换,从 hf 格式转换为 gguf 格式
python convert-hf-to-gguf.py models/safe/ --outfile models/Llama3-8B-Chinese-chat-ff16.gguf
(如果没有 numpy\torch\sentencepiece\transformers,需要提前安装 pip install numpy\pip install torch\pip install sentencepiece\pip install transformers)

4)、进行量化 (HF 格式直接转 gguf 没有办法直接使用,一般电脑带不起来)
./quantize /data2/other/llamacpp/llama.cpp/models/Llama3-8B-Chinese-chat-ff16.gguf /data2/other/llamacpp/llama.cpp/models/Llama3-8B-Chinese-chat-4-bit.gguf Q4_K_M


量化后直接 4g,太清爽了。
三、利用 ollama 进行本地部署
1)、ollama create llama38b -f model.txt

成功了!!!
四、使用 open-webui
参考我们https://testerhome.com/topics/39986这篇文章讲的内容
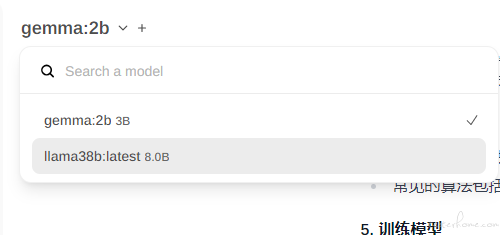
选择下面 8B 的模型看下效果

