在过去几年零零散散的学了一些 Cypress 的知识,也尝试写了一些 demo 代码。但是真正开始在项目上使用 Cypress 还是在 2023 年。实现了从 0 搭建 Cypress 自动化测试并持续稳定运行超过一年,该博客结合我在项目上使用 cypress 的一些实践,与大家分享探讨。 在公司的博客大赛中有很多伙伴发布关于 Cypress 的博客。所以 Cypress 的介绍这里我就不再赘述了。
为客户提供一款 To-B 的财务管理相关系统并为客户做数据迁移。该系统主要包含了一个很长很长很长的注册审批流程(这里称其为注册审批流好像不太确切,但是为了便于理解我们就把它当作是一个注册流程)项目初期选定了使用 Cypress 作为自动化工具。框架使用 Cypress + TS。项目总共有 4 个环境, DEV, SIT, UAT 和 Production 环境,前期我们只配置了 DEV 和 SIT 环境。所以我们的自动化也主要运行在这 2 个环境上。(文中提到的自动化测试多指项目 UI 自动化测试)
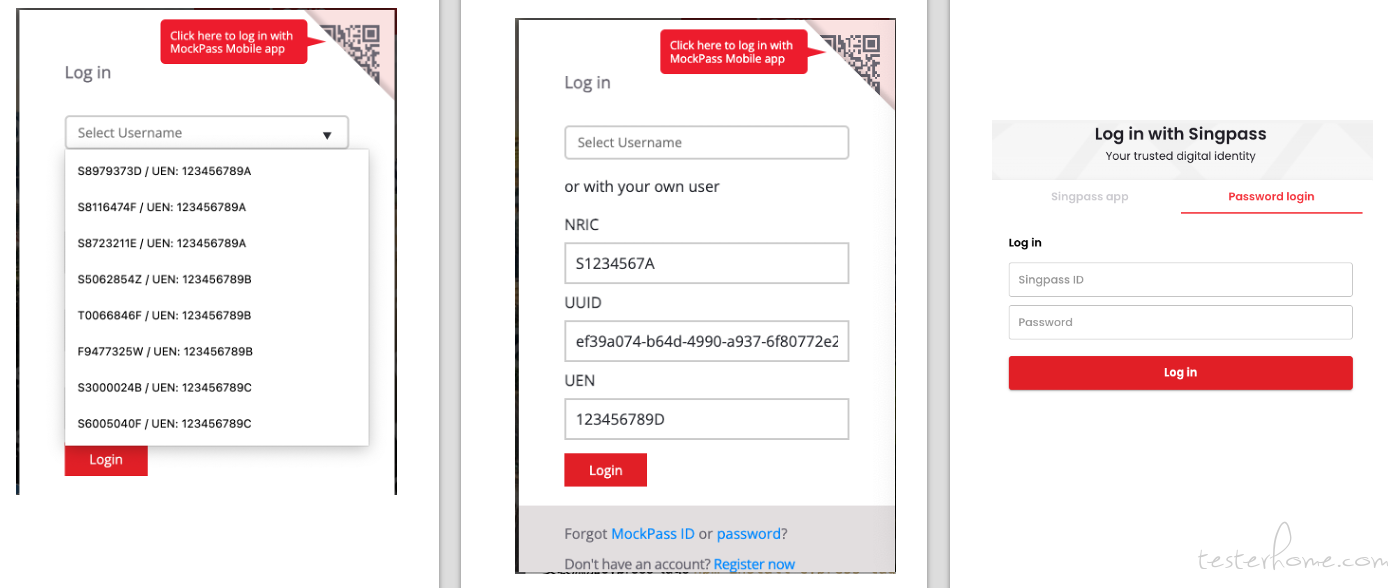
该系统的登陆模块用户将来会使用自己的 SingPass 或者 CorpPass 账户登陆,所以测试环境集成了 mockpass 用于模拟用户登录。众所周知 Cypress 是运行在浏览器内的自动化框架。初期考虑可能会有跨域请求问题,后来调研发现我们可以自己部署 mockpass 服务,所以也就没有这个跨域的问题了。但其实跨域在 Cypress 9.6 开始已经很好的支持了。Cypress 12 引入了 cy.session(),用户可以保存 session,不需要反复的登录。
SingPass:是新加坡居民数字身份,可以安全便捷的访问政府部门或企业的在线服务系统。 CorpPass: CorpPass 是新加坡政府推出的一种企业电子身份账号。该登录程序要求用户首先通过 SingPass 验证身份,然后才可使用政府数字服务进行交易。 Mockpass:是一种用于模拟用户身份验证和授权的系统。它可以帮助开发人员在开发和测试阶段模拟不同的用户身份,以验证不同用户角色的权限和功能。
由于是模拟系统,如图所示,用户可以在页面选择登陆账户也可以输入,如果选择的账户是合法的且校验通过就可以直接登陆系统。虽然是测试环境但是安全性还是得考虑进去。所以从系统登陆页面到 mockpass 页面之间,加入了 basic auth 的校验,针对 UI 自动化测试我们在 hook 加入 basic auth 登录就可以了。这里顺便说下安全,整个系统使用到的账户信息我们都存入了 pipeline 的 variables,使用时可根据运行的环境获取 (该项目我们使用的 gitlab CI)。但是 API 测试就比较麻烦了,因为 mockpass 是第三方服务,我们无法直接生成并获取 token,所以 token 只能通过 UI 登录的方式获取。就 Cypress 本身,它是可以支持多种 auth 的生成,例如 auth0, google auth, okta 等。
官方文档: https://docs.cypress.io/guides/end-to-end-testing/amazon-cognito-authentication
左边 2 个是 mockpass 登陆界面,右边是 singpass 登陆界面
在开始做测试策略的时候就考虑了后期项目越来越复杂,服务越来越多后我们的自动化该如何运行,怎么让自动化测试运行的更加有效? 虽说 cypress 的执行速度很快,但是再快的自动化测试也是一步步执行的。在定义完测试策略后,我们为自动化测试配置了单独的 pipeline,与其他服务的 pipeline 采用 parent-child 的协作模式。提高了自动化整体运行的灵活性。这里我们引入了 cypress-tags 来为不同的测试用例加 tag 以保证测试的执行效率。
安装添加 cypress-tags
npm install cypress-tags
在 cypress config 文件加入配置
import { tagify } from 'cypress-tags';
export default defineConfig({
e2e: {
setupNodeEvents(on, config) {
on('file:preprocessor', tagify(config));
},
},
});
在测试用例加入你所定义的 tag,tag 可自己根据需要进行命名
describe('my-feature', () => {
it(['smoke'], 'one case can add one or multiple tags', function () {
cy.visit('/');
//...
})
})
可根据具体的 tag 运行不同的测试用例
CYPRESS_INCLUDE_TAGS=smoke npx cypress run
官方参考文档:https://www.npmjs.com/package/cypress-tags
前端流水线 sample

后端流水线 sample

除此之外我们还设置了定时任务,在每个工作日早 8:00AM 自动触发回归测试,保证上班后第一时间查看系统是否稳定。 下午 4 点半左右触发第二次回归测试,开发 4 点 code diff,这时候一般会有大量的提交,在提交完成后运行自动化测试确保系统的稳定性。
不同项目的策略会不同,也会有人质疑我们这样是不是执行过度了或者说有漏洞(其实我自己也反思过很多次),但是结合项目具体的运行情况来看,自动化测试帮助我们提前发现了不少的问题。大幅减轻了测试的压力,尤其是在项目后期做 UAT 阶段。欢迎大家分享探讨项目上的优秀实践。
过去参与过的很多项目都会采用 api 来协助准备自动化测试数,从而简化测试运行时长以及稳定性,之前的项目相对来说复杂度都不是很高,可能两三个 API 就搞定了。但是该项目流程较长且包含了大量的信息填写生成,每一步都会有大量文档的填写,上传, 审批。手动快速填写一些基础信息走完流程最少也需要几分钟的时间。过去跟很多小伙伴也聊过项目自动化的痛点,大家都很认可使用 API 准备提高效率,但是现实是残酷的,大型系统理清业务流程,数据创建都比较费劲,更别说把整个系统的 API 调用流程完全自动化。具体能做到什么程度大家需要根据自己的项目情况分析。那我们这个系统的好处在于我们是从 0 开始的,我们对自己的系统非常熟悉,虽然 API 很复杂,但是我们对于接口的调用,接口之间的依赖关系,数据的关联性,计算的逻辑等都有清晰的认知。
虽然流程很清晰,但是难点也是非常明确的,动则几百行的请求体,动态的数据变化,复杂的计算逻辑,服务间数据的依赖与更新。我们将 API 的请求体参数化,解决了大多数问题。对于复杂的计算自动化没有做过多的测试测试。开发在前后端 UT 都加入了大量的测试来保证计算的正确性,除此之外呢前后端还加入了对比校验(这里为了前后端 0.01 的不同,开发真可谓是呕心沥血,向他们致敬。)自动化测试主要选取了客户提供的一套模版数据。综合评估如果这里逻辑出问题了,固定的计算请求体发送后也是会失败。
这里我想到一个类似的例子来解释这个复杂的计算:我们去银行申请房贷,银行会根据我们购买房屋的首付比例,年龄,职业,收入,已有住宅等情况审批,具体审批的贷款额度,年限可能会根据每个人的情况不同。同时每月还贷款的数额还会根据每年的利率,选择的还贷方式有差异。那么这里提到的计算可能也是类似的复杂度。
引入一个博客系统新建文章的 API 举例使用 Mustache.render 来解决请求参数化的问题:
安装
npm install mustache --save
生成 article 数据
const article = {
title: "title test" + faker.random.words(10),
body: "body test" + faker.random.words(15),
description: "title test" + faker.random.words(20),
}
可将请求模版单独存储为一个文件, 例如 article_template.ts
const article_template = () => ({
article: {
title: "test title '{{title}}'",
body: "test body '{{body}}'",
description: "test description '{{description}}'"
}
});
export default article_template;
API 调用:
import article from '../fixtures/article'
import Mustache from 'mustache'
import article_template from '../{path}';
Cypress.Commands.add('add_articles', (token: string) => {
const data = Mustache.render(JSON.stringify(article_template()), article)
request(${url}/articles, data, token).then((response: any) => {
return response.boby;
})
});
由于大多数测试用例都可以用 API 准备数据,所以我们想写一个大而全的方法涵盖整个数据准备流程,实际上也实现了并且运行良好。很多人可能会质疑这不是一个好的实践,基于项目的真实情况,大多数的测试用例都依赖我说的这个长长的注册流程,且小一半的用例测试的是注册成功之后的业务。唯一的缺点是异步调用问题,我们不得不在有依赖关系的 API 之间加上.then() 来保证执行的顺序。
实际的项目上的数据准备方法会有参数化的设计,根据参数决定数据准备的类型以及步骤。这里我列举了一个类似的代码例子:
Cypress.Commands.add('data_preparation', (article, query = false, edit = false) => {
return createarticle(article).then((createResponse) => {
const createdArticleId = createResponse.body.id;
if (query) {
return get_article(createdArticleId).then((getResponse) => {
const titleToEdit = getResponse.body.title;
if (edit) {
const updatedArticle = {
id: createdArticleId,
title: titleToEdit + ' - Updated', // 假设您想要在原标题后添加 '- Updated'
content: 'Updated article content.'
};
// 调用 edit_article 命令来更新文章内容
return edit_article(updatedArticle);
}
return { title: titleToEdit };
});
} else {
return null;
}
}).then((articleAfterOperations) => {
return articleAfterOperations;
});
})
在前面的例子里大家可能注意到我自动生成了部分数据, 这里我用的是 faker 工具。faker 生成数据简单易用接近真实数据. 不知道有多少伙伴跟我一样测试的时候都会随意输入很长的字符,系统上有很多看不懂的文字,看不懂的描述。但是 faker 可以帮助我们生成大量多样化的数据,还可以根据具体需求定制化数据格式,简单易用,节约了不少时间。
以下是几个关于 faker 生成数据的例子:
1.生成随机姓名:
import { faker } from "@faker-js/faker";
const firstName = faker.name.firstName(); // "Alice"
const fullName = faker.name.fullName(); // "Marcos Kuphal"
2.生成随机电子邮件地址:
const email = faker.internet.email(); // "john.doe@example.com"
说明:faker.internet.email 生成一个包含随机用户名、域名和顶级域名的电子邮件地址。
3.生成随机电话号码:
const phoneNumbner = faker.phone.number('+86 137 ### #####') //"+86 137 810 94249"
const phoneNumbner = faker.phone.number('8###-####')// "8632-9325"
const phoneNumbner = faker.phone.number()// "(824) 202-9912 x5553"
说明:faker.phone.number 生成电话号码,可指定一个格式化的随机电话号码,可能包括国家代码、区号和号码。
4.生成随机金融信息:
const creditCardNumber = faker.finance.creditCardNumber(); // "3016-598542-7652"
const creditCardNumber = faker.finance.creditCardNumber('#### #### #### ####') //“7882 1291 3314 0469”
说明:faker.finance.creditCardNumber 生成一个随机的信用卡号码,可指定生成需要的格式
详情可参考官方文档:https://fakerjs.dev/api/
NRIC: 术业有专攻,faker 生成 NRIC 就没那么厉害了,是有唯一性的,在项目初期开发自己写了一段生成 NRIC 的 js 脚本,刚开始挺好用的,但是随着系统越来越大,唯一性校验导致失败的几率也高了,所以我们引入了第三方的库生成 NRIC,很大程度上解决了稳定性问题。
参考:https://github.com/danielkhoo/nric
NRIC (National Registration Identity Card) is the identity document in use in Singapore. The NRIC number is a unique alpha-numeric serial
日常流水线失败检查 cypress 的截图和视频回放其实足够详细了,但是我们项目最终交付物是要包含自动化报告的,所以我们集成了 mochawesome-report.但是后来发现 gitlab 自带的 report 就很香了,而且可以直接发送地址给客户,他们可以自行查阅,缺点是考虑到自动化运行的频率,同时也为了节约资源所以 artitfact 过期设置了 1 天,其实可以更长点。但是好像不需要就一直没有修改。所以最终给客户发送报告的时候带上了链接,但是确实也遇到了客户没有及时查看,让我们发送了第二次的情况。
当我们的测试用例达到 90 条以后,regression 的时间大概需要 30 分钟以上,耗时主要集中在登陆模块以及复杂数据的准备。所以我们调研了并行的策略且在 CI 尝试运行了,效果比较理想。但是客户提供的机器有限,无法支持官方提供的并行策略。回归测试相对来说跑的没有那么频繁,所以后来也就没有使用并行策略。算是下项目前的一点遗憾吧。听项目伙伴说最近引入了一个新的包,希望并行可以大幅运行效率。
系统有很多日期相关的功能,且输入框有多种自动格式匹配加校验。所以开始的时候几位 QA(每个人测试的模块不同)各自写了不同的方法输入/选择日期。直到有一天一条测试由于选择不到想要的那天而失败了。才发现原来我们用了好几种方法且日期选择不是很灵活。所以我们写了几个方法根据需要生成不同日期以及日期格式。在使用日期控件选择的时候,日和年的选择相对简单点,但是月份只能在 UI 上左右滑动选择,所以增加了根据当前月份计算差值进行左右滑动选择。项目伙伴调查对于日期控件编辑的时候无法 clear 的情况其实可以使用类似这种方法解决:
cy.get(div.MuiInputBase-root input)
.clear()
.type('{leftArrow}').clear()
.type('{leftArrow}').clear()
.type('08052005', { force: true })
动态元素是自动化测试不可避免的,项目上能加上 data-testid 的都喊开发加上了,但是该系统表格较多,所以我们也会采取一些迂回的方式查找,比如利用父子节点,相邻节点,表格的行,列号等。另外我们还有一个典型的是项目使用的 select 多选组件。该组件在系统里大多都不支持 dropdown 的 select 方法,项目一些选项名称较长但是命名比较规则,所以会将选项存成 enum,封装方法,根据输入的参数选择对应的选项。
页面不稳定:页面明明 save 成功了,但是没有跳转出来。导致后续校验失败。手动尝试了无数次都无法重现。仔细慢放 cypress 录屏后发现是因为自动化运行过快导致 save 被判断为 leave 触发了 unsave 的 pop up,这种情况太过于边界,但是这种逻辑自动化测试又很难绕过的,只能在前端修改判断逻辑执行,但是前端加多了会影响前端的性能,加少了可能自动化又不稳定。所以反复调试了好多次。
我常听到伙伴们说这个工具没有那个工具好。 我理解工具是为我们服务的,所以并没有好坏之分,只有适合之分。好的工具匹配合适的项目才能达到事倍功半的效果。所以根据项目的实际情况来权衡。在工具选型时尽可能的考虑工具是否可以匹配未来项目发展。另外在用例的选择的粒度上先粗再细。优先考虑 smoke,再考虑 regression。最后 case 也是需要不断的维护与更新来保持它的有效性。期待小伙伴们可以分享更多的项目实践,大家共同学习总结。
