往期文章
专栏文章 质量保障系统的落地实践 (一) 概览篇
专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 基础信息与缺陷信息设计
效能度量 专栏文章 质量保障系统的落地实践 (二) 项目管理设计 - 代码信息设计
前言
往期文章中已经介绍了关于项目管理的主要设计内容,围绕项目管理还有一些小工具的开发,暂且按下不表。后续有机会的话,以工具角度单独聊聊。
本篇文章主要介绍 CI 管理,也是整个质量保障体系中比较重要的一环,值得 QA 人员探索。
CI 与自动化
首先我们要知道,CI 与自动化的关系。一般来说,测试行业内讲自动化,大部分是指接口自动化,当然也不排除 UI 自动化,狭义上指的是测试人员需要有编写、调试、运行自动化脚本的能力。广义上指测试具备使用代码解决一些问题的能力,用机器替代人力。
CI 的含义是持续集成,顾名思义,两个要素:1、集成;2、持续。需要将一些能力 (包括但不限于代码) 组合在一起,完成某项或多项诉求,并且可以继续往后迭代,不断丰富能力。
所以综上来说,CI 的语境范围是大于自动化的。那么投射到测试行业内,CI 可具象化成:
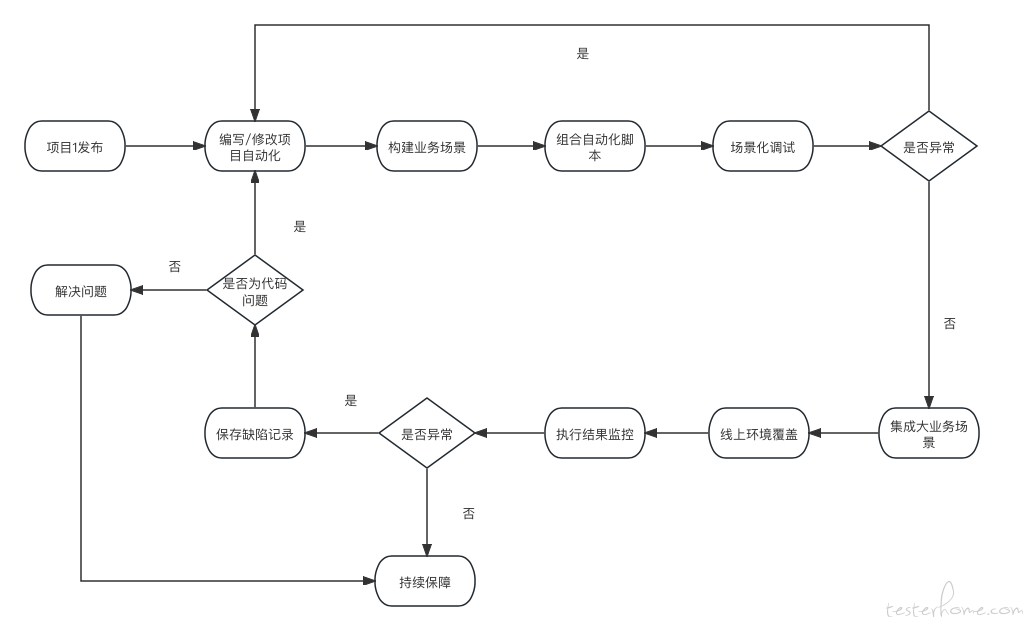
随着项目不断地迭代,业务场景会逐渐增多,当然业务场景也有优先级的差别。资源有限的情况下优先保证主流程的畅通与稳定,项目需求的更新必将不断增加业务场景的复杂程度,也将增加业务代码处理的复杂程度,特别伴随在项目中还存在着的人员迭代 (离职 or 新加入),后续进入项目的人,对于需求的熟悉程度有限。这种情况下纯依赖某位或多位测试人员对于项目以往需求的熟悉程度来把控项目质量是有风险的,需要有自动化的辅助。
直接参与项目的测试人员在项目发布后,迅速梳理出核心场景,并完成高质量的自动化脚本,于测试环境进行核心场景调试。调试通过后,集成到现有的业务自动化体系中调试,若导致上下游的脚本出现了异常,则需要排查原因,解决问题后重新调试,直至集成测试通过。
测试环境通过后,相同的方式依次在预发环境及线上环境重复,保证新增项目的自动化脚本与现有业务自动化体系完美契合。
由上面的论述可知,高质量的自动化脚本是释放测试人力,替代人力监控系统核心业务的重要帮手,那么对于自动化脚本的编写自然有了要求,期望越细致越好。那么针对这个要求,我们该怎么来设计?
案例选型
自动化可总体分为接口自动化和 UI 自动化,本篇文章以接口自动化为例,一来是我司更偏重于接口自动化;二来是在我司接口自动化的实践已有一定成果,适合作为案例分析。若是阅读本篇文章的同学采用的是 UI 自动化或其他自动化,我想也可当做休闲文章阅读。
接口信息设计
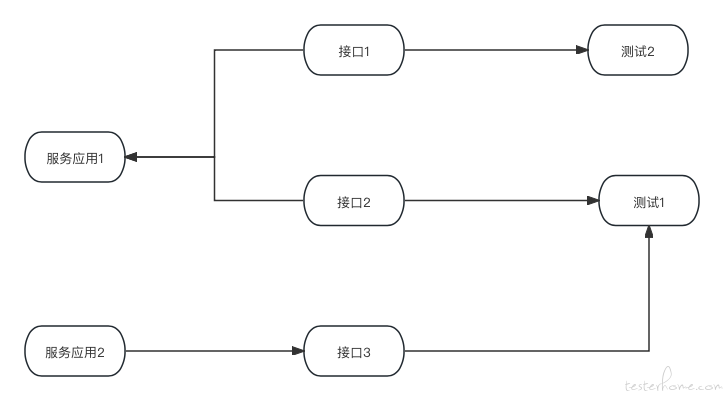
既然本篇文章的切入点在接口自动化上,那么首先映入眼帘的就是接口信息的设计。由于我们的需求是要管理团队的自动化脚本质量,团队由测试成员组成,那么很自然的,这个数据也是需要落到具体某位测试身上的,聚合而得团队的数据。
业务核心场景由接口串联而成,接口是承载业务场景的底座,结合人员数据的需求,很自然的我们就会考虑将接口信息与测试关联起来:
# CI管理-接口管理-服务接口信息表
class CIInterfaceInfo(BaseModel):
department_id = models.IntegerField(verbose_name=u"归属组织节点")
app_code = models.CharField(max_length=50, verbose_name=u"服务code")
domain = models.CharField(max_length=150, verbose_name=u"域名")
path = models.CharField(max_length=255, verbose_name=u"接口路径")
description = models.CharField(max_length=40, verbose_name=u"接口描述")
is_core = models.BooleanField(default=False, verbose_name=u"是否为核心接口")
priority = models.IntegerField(verbose_name=u"接口优先级")
owner_name = models.CharField(max_length=11, verbose_name=u"负责人姓名")
owner_phone = models.CharField(max_length=11, verbose_name=u"负责人手机号")
is_available = models.BooleanField(default=True, verbose_name=u"是否有效")
env = models.IntegerField(verbose_name=u"归属环境(测试/预发/生产)")
class Meta:
db_table = 'CI_Interface_Info'
verbose_name = "CI管理-CI接口信息"
verbose_name_plural = verbose_name
通过上面的数据表设计,我们得到的接口与测试人员的关系图如下:
校验粒度设计
前文中一直在强调高质量自动化脚本,那么怎么样去界定这个高质量,或者说该设计一种怎样的机制去促使测试写出高质量的自动化脚本?若是应付交差而已,测试人员在编写自动化脚本的时候,完全可以不做任何校验或仅仅保证接口能够访问成功,这在实际工作中是完全有可能出现的,那么该怎么做?
首先想要改善某个指标,往往是先发现这个指标不令人满意,随后需要查出有多少这类情况数据,然后想办法去提高,总结来说以数据驱动管理,这也是我设计质量保障平台的一个核心观点。
以我所在公司的情况为例,由于我负责自动化的集成,所以会时常 review 自动化代码。在此过程中发现了很多接口很少甚至没有任何必要字段校验,但是存量数据又太多,不可能一一去翻阅然后统计。那么该怎么做?必然是要使用代码的,问题又来了,代码怎么知道一个接口的校验是不是足够呢?答案是不能的,对于一个接口的校验是否到位除了参与该接口所属业务的测试外,其他人都很难评估,这时候怎么办?
回头想想自己是怎么判断某个接口的校验是否完善,直观感受是校验语句的多少,若是校验的细致,那么校验语句一定使用得多,那么这个指标可以作为一项判断依据。有了这一项是不是就足够了呢?实际情况中确实有的接口只是很简略的处理逻辑,那是不是意味着这样的接口就是校验不到位的呢?解决这个问题的方案是看实际的传参情况,例如一个提交表单接口,提交 10 个字段,接口校验部分少于这个数量甚至没有,那么程序可以判定校验数据不够。
那么我们就抽离出了两个关键要素:1、传参数量;2、校验语句数量,这就是本小节所述的校验粒度。
而这两个参数恰恰又是关联在接口上的:
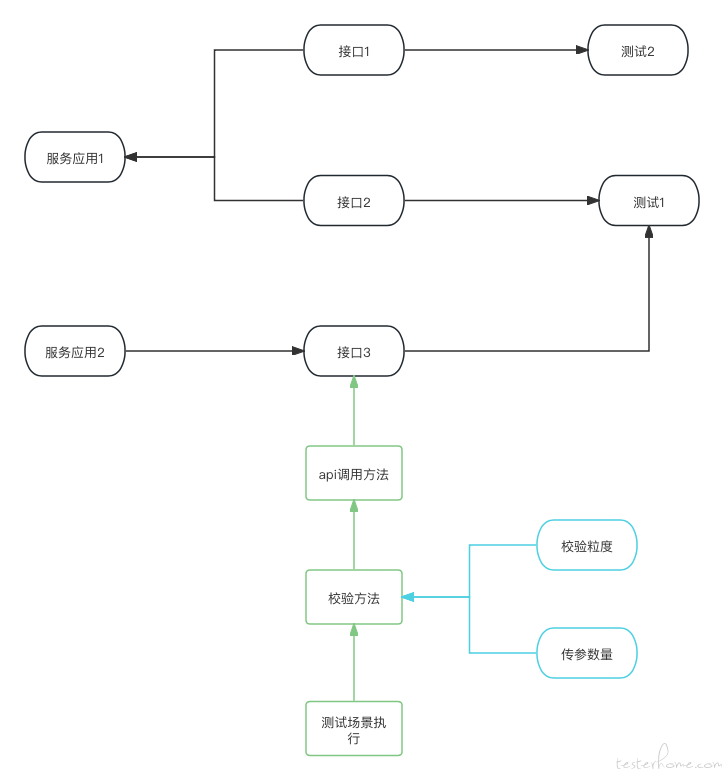
以上图为例,实际的自动化执行过程中,最小单元是测试套件->校验套件->api 触发套件。从校验套件中可以提取出传参数量以及校验语句数量,而这两个数据又与接口进行关联,通过接口信息表的设计,接口与测试人员已经建立了联系,那么就可以将这两个关键数据与对应测试关联起来。
分析到这,基本可以满足我们的诉求,下面再来谈谈校验粒度的设计。首先传参数量是无法维护的,因为每个接口的情况都不同,很难维护;其次校验语句是可以维护的,因为不管使用哪一类的自动化框架,自研的也好,市面上成熟的体系也好,一定有对应的完整的校验语句维护,那么这些信息我们就可以维护下来,而后可统计接口的校验套件中包含了多少条校验语句:
# CI管理-校验语句管理-校验语句配置信息表
class CIVerificationSentenceConfigInfo(BaseModel):
department_id = models.IntegerField(verbose_name=u"归属组织节点")
sentence = models.CharField(max_length=200, verbose_name=u"校验语句")
is_available = models.BooleanField(default=True, verbose_name=u"是否有效")
class Meta:
db_table = 'CI_Verification_Sentence_Config_Info'
verbose_name = "CI管理-CI校验语句配置信息"
verbose_name_plural = verbose_name
粒度数据获取
这一小节我们来谈谈怎么获取校验粒度的数据,在这之前我们先谈谈自动化框架的分层设计。前文也提到了,一般来说分为配置文件、底层能力、测试套件、校验套件、api 套件。触发自动化脚本之后,由测试套件触发校验套件,校验套件调用 api 套件完成接口请求,其中会有调用底层能力,读取配置文件等等步骤。那么在执行过程中是很容易拿到包括 api、校验传参、校验语句等关键数据的,非常满足我们的需求,但这个方案却不一定能落地。这是为什么?
因为在执行过程中获取我们期望的参数,这就要求我们的期望逻辑需要侵入到自动化框架执行过程中,需要框架研发者为我们定制逻辑,而通常情况下这种要求是很难满足的。那么还有没有别的办法?
是有的,既然无法侵入执行步骤,那就暴力解析:无论什么自动化框架,校验套件和 api 套件都是文件,那么我们直接解析文件提取我们想要参数即可,这种解析方式就要求了在编写校验套件和 api 套件时需要按照一定的规则进行,便于解析匹配:
api_analysis_prefix = models.CharField(max_length=50, verbose_name=u"平台api解析前缀")
api_analysis_postfix = models.CharField(max_length=50, verbose_name=u"平台api解析后缀")
keyword_analysis_prefix = models.CharField(max_length=50, verbose_name=u"平台keyword解析前缀")
keyword_analysis_postfix = models.CharField(max_length=50, verbose_name=u"平台keyword解析后缀")
依据于配置的前后缀进行匹配,提取出 api 数据、校验套件内的传参数量、校验语句数量并不难。
以下代码以 RF 为例,解析前已经完成了团队内部代码编写规范要求,api 套件均以 Http-开头,-api 结尾,所以解析过程比较清晰:
# api.robot文件范例
Http-XX业务:获取登录用户信息-api
[Arguments] ${SH_TOKEN} ${data}=&{EMPTY}
${headers} Create Dictionary Token=${SH_TOKEN}
Create-Session-XXXX
${result} HTTP Post session_name /xxx/xxx/xxx headers=${headers} data=${data}
[Return] ${result}
# CI管理-api.robot文件解析
def api_robot_analysis(file_path, prefix="Http-", postfix="-api"):
# 维护Http-类型keyword内容映射关系
api_map = defaultdict(list)
key = None
with open(file_path) as f:
content = f.readlines()
# 将keyword及keyword内容包装
for line in content:
line = line.strip()
if line.startswith(prefix) and line.endswith(postfix):
key = line
continue
if key is not None:
if line and "HTTP" in line.upper():
split_res = re.split('\s+', line.upper())
try:
http_index = split_res.index("HTTP")
except ValueError:
continue
path_index = http_index + 3
try:
path = split_res[path_index]
except IndexError:
continue
# 避免注释接口也被计算在内,仅处理第一条
if len(api_map[key]) == 0:
api_map[key].append(path.lower())
校验套件也是类似的,提前约定以 Http-开头,-keyword 结尾:
# keyword.robot文件
Http-XXX业务:XXX统一拦截器-keyword
${userInfo} Http-XXX业务:获取登录用户基础信息-api
### 参数提取 ###
${shopCode} Set Variable ${userInfo}[shopCode]
### 数据查询 ###
${querySql} Set Variable select xxx from xxxx where xxxx
${shop_record} remote query database by env ${querySql} &{DB}
Should Not Be Empty ${shop_record}[0]
### 参数提取 ###
${shop_info} Set Variable ${shop_record}[0]
${whether_test} Set Variable ${shop_info}[whether_test]
# 测试标识拦截
Should Be Equal ${whether_test} ${1}
# CI管理-keyword文件内容分离器
def keyword_content_split(file_path, keyword_prefix, keyword_postfix, inner_keyword_prefix):
# 以keyword名称为key,聚合keyword主体
keyword_line_map = defaultdict(list)
keyword_key = inner_keyword_key = None
with open(file_path) as f:
content = f.readlines()
for line in content:
# 移除换行符等干扰字符串
line = line.strip()
# 过滤无效行
if not line:
continue
# 判断是否符合待采集的keyword名称,符合则将keyword名称设置为key
if line.startswith(keyword_prefix) and line.endswith(keyword_postfix):
keyword_key = line
continue
if keyword_key is not None:
# keyword校验语句去重-预防复制粘贴
if line not in keyword_line_map[keyword_key]:
keyword_line_map[keyword_key].append(line)
return keyword_line_map
分别得到 api.robot 与 keyword.robot 内的数据,只需要做一定的数据分离,如按空格分隔字符串等手段,就可以解析出代码主体里的各条语句,与我们自己定义的校验粒度进行匹配,就可以得到每一个校验套件 (keyword) 的校验粒度数据。
小结
本篇文章对于 CI 管理的设计开了一个头,考虑到结构完整性,下一篇文章再来讨论如何将这些逻辑进行集成。感谢大家阅读。
如果对你有所帮助,请一键三连。

↙↙↙阅读原文可查看相关链接,并与作者交流