智能座舱 自动化测试浅谈之用户场景下的语音交互系统测试
随着 w 界/x 米汽车入市,2024 年的汽车市场已开始进入了白热化的竞争阶段,智能汽车销量及占比持续增长。
智能座舱及智能驾驶作为软件部分的 2 大核心竞争力深刻的影响着用户的购车决策,其中受限于技术、成本、道路条件、安全等因素,智能驾驶方面发展相对缓慢,而智能座舱做为各大厂商最容易发力,也是在购车前最容易被用户感知的领域,未来很长一段时间将是汽车,尤其新能源汽车重要竞争与发展方向。
语音交互系统作为用户使用场景中比重最高的主动触发类功能,已深度融合到驾舱的各个模块,包括软件 app 交互、车内/外硬件交互、家庭 IOT 场景交互、垂域/开放域大模型交互等。
在历经智能手机、智能家居到如今的智能驾舱,为了实现测试结果与用户体验之间的一致性,语音交互系统的自动化方案也在不断迭代:
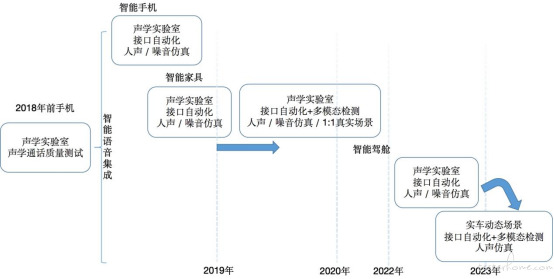
智能驾舱自动化方案迭代说明:
当前车机的降噪方案均基于麦克风/麦克风阵列 + 声源定位技术通过相应的增益与抑制技术等提高高噪场景下的语音识别效果。
主机厂(尤其是新势力厂商)在结合用户数据与实验室数据对比并分析后,发现直接移植传统电声领域的声场仿真方案无法完全满足以声源定位技术为核心的驾舱算法(驾驶过程中车辆交汇,噪音快速的进入、消退与移动),造成实验室数据在唤醒、误唤醒、识别、连续对话等多领域的结果差异。
随着实车动态场景下的自动化方案被更多的主机厂发现与认可,如何更好的实现自动化测试结果与用户体验的一致性?针对核心技术部分,以下思路与建议供行业同时参考:
1、人声还原不等于播放人声。
因噪音采用实际用户场景的动态测试,自动化测试结果是否和用户结果趋于一致,人声还原至关重要,需考虑高中低不同频率下的还原度,自动化需结合硬件与软件,考虑到还原性能的差异(尤其是中高频)硬件仿真嘴建议采用 BK/Grass 等头部产品,每台设备需配备不同的 EQ 校准文件,这部分软件实现需要自研,各频率还原度差异可通过 soundcheck 等软件进行测试。
2、单一测试流程不等于用户使用场景
产品业务流程设计上需要高度考虑用户的实际使用场景,在音乐播放时进行唤醒、识别交互、在 TTS 播报进行时进行唤醒、识别交互、多个位置间的交互与互动等,不能用单一位置的重复测试去评估用户的实际体验效果。
3、其他需要考虑的点,包括连续、非连续识别、免唤醒、功能自动化实现、算法效果快速验证、误唤醒方案、响应时间、LOG 获取、语音交互系统的稳定性等。
4、如何自动化实现竞品的对比测试
因无法获取竞品车辆的接口权限,可以通过多模态的方式(单一方式或结合应用)实现自动化,如通过摄像头图像识别、mic 识音、传感器 Sensor 等。
5、语言大模型和文生图的主客观测试是否能够实现自动化
对于客观测试(有预期或参考答案)的实现相对简单,这里不展开,但问题的多样性和迭代周期需要深入考虑,主观 MOS 测试实现同样不难,自动化系统重点解决效率提升问题,可以参考众测行业的方案。
德风运科技自动化产品:
产品服务于蔚来汽车、小米汽车、天津汽研等,详细自动化产品能力,请联系北京德风运团队。
语音交互系统:

大模型测试系统:

↙↙↙阅读原文可查看相关链接,并与作者交流