如何使用大模型解决日常工作中难以解决的问题?
大模型在自动化测试领域可以发挥什么作用?
如何利用大模型提前发现故障,并提升产品质量?
如何发现日常工作中难以察觉的故障?
团队现状:
A. 经常性的泄露一些修改 java 依赖引发的故障,在 maven 的 pom.xml 文件中修改一个依赖的版本号都可能引出故障,见下图例子
此类型的问题难以发现的原因:
B. 没办法对所有的新增代码进行 CodeReview,Review 的效果一般,容易泄露在功能测试阶段无法发现的问题。
因此,针对上述原因,将大模型与当前自动化测试相结合,通过大模型自动化来防护此类问题就是本实践的目标。
虽然该类问题难以发现,但也并不是毫无办法。
该类问题有个共同点:在 JVM 运行时,找不到某个依赖,会抛出:ClassNotFoundException,NoClassDefFoundError,IllegalAccessException,InstantiationException,NoSuchMethodError 等异常。
那我们收集到组件日志后是否就能规避这种问题呢?
答案肯定是不行的。举个例子:
例如团队内组件热部署探针运行在框架中,在热部署探针启停阶段,因探针在框架中提交的线程还在轮询,探针实例已经被销毁后,依旧会出现很多上面的异常来干扰判断,无法得出精确的结果,所以需要从提升精度的方向去优化。以下是思考方向:
如何去解决呢,想了以下几点:
然后还有最重要的一点,收集的异常信息和热点代码的映射如何建立呢?如果手动去建立 异常->依赖 的映射始终会滞后,出一次问题加一次不利于可持续发展,而且只有当在出问题时才能知道抛出的异常长什么样,难以完成该项目。
所以引入了大模型去帮我完成 异常->依赖 的建立。
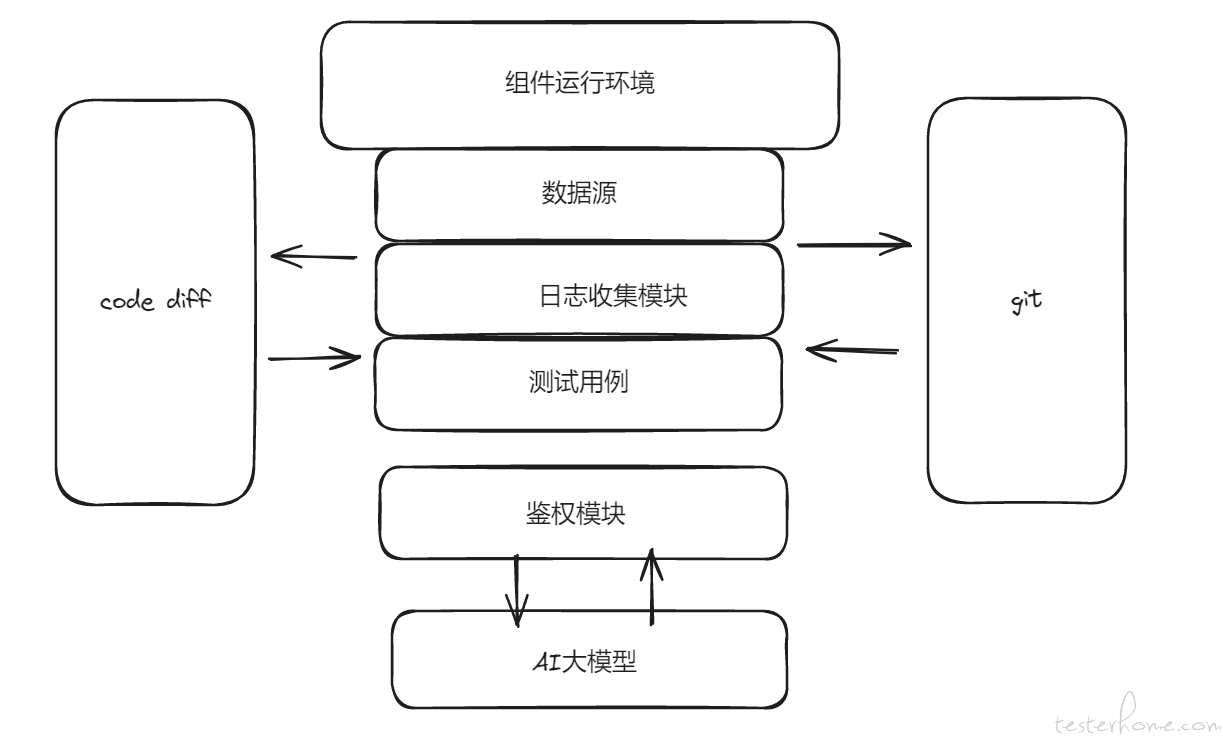
实践过程采用了以下架构:
获取大环境数据源:项目组件运行在大环境下,利用大环境提供的数据源进行后续操作。
获取代码变更:
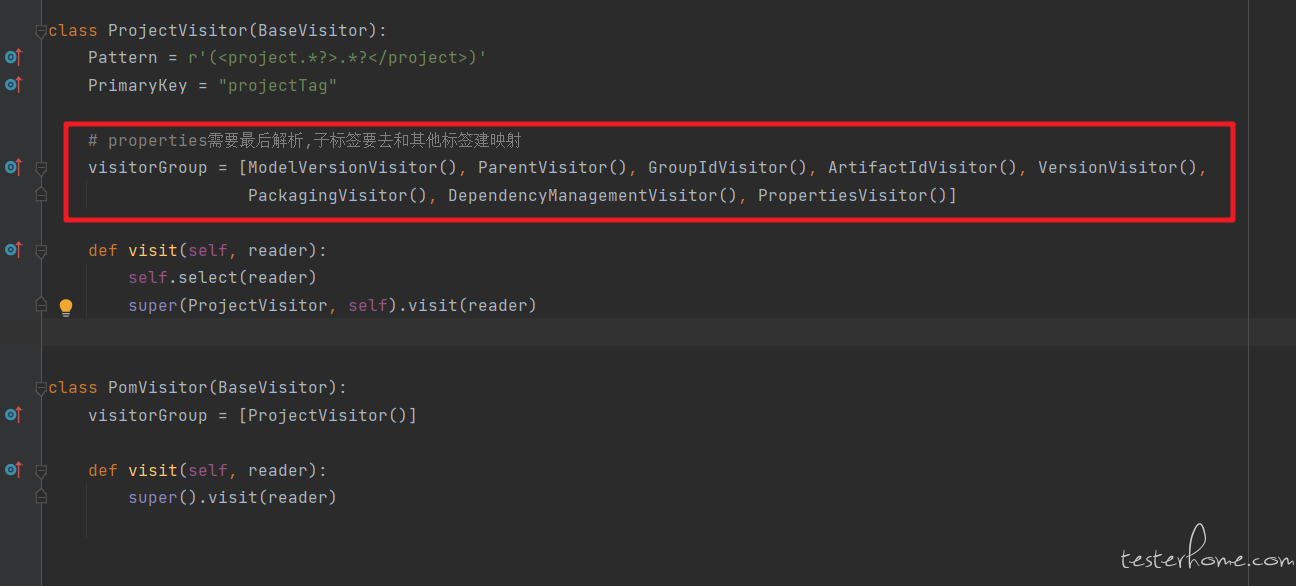
解析修改文件:
日志处理:
与 AI 大模型交互:
热点代码匹配与记录:
发送邮件通知:
获取大环境数据源:同样利用大环境提供的数据源。
获取指定需求编号的代码变更:
解析修改文件:
与 AI 大模型交互:
结果输出:
通过上述实践过程,可以有效结合 AI 大模型与自动化测试技术,提升故障发现和产品质量的能力。同时,减少了人工审查和测试的工作量,提高了工作效率和准确性。
针对 pom.xml 如下:
运行自动化测试用例,测试用例会从 git 库中获取指定项目指定分支的代码提交记录,进行解析和缓存。
收集环境上日志,拿到原始日志后进行分类
通过一些对字符串的算法,把 java 异常堆栈进行去重,同种类型的异常只保留一个,方便人工查看和邮件推送
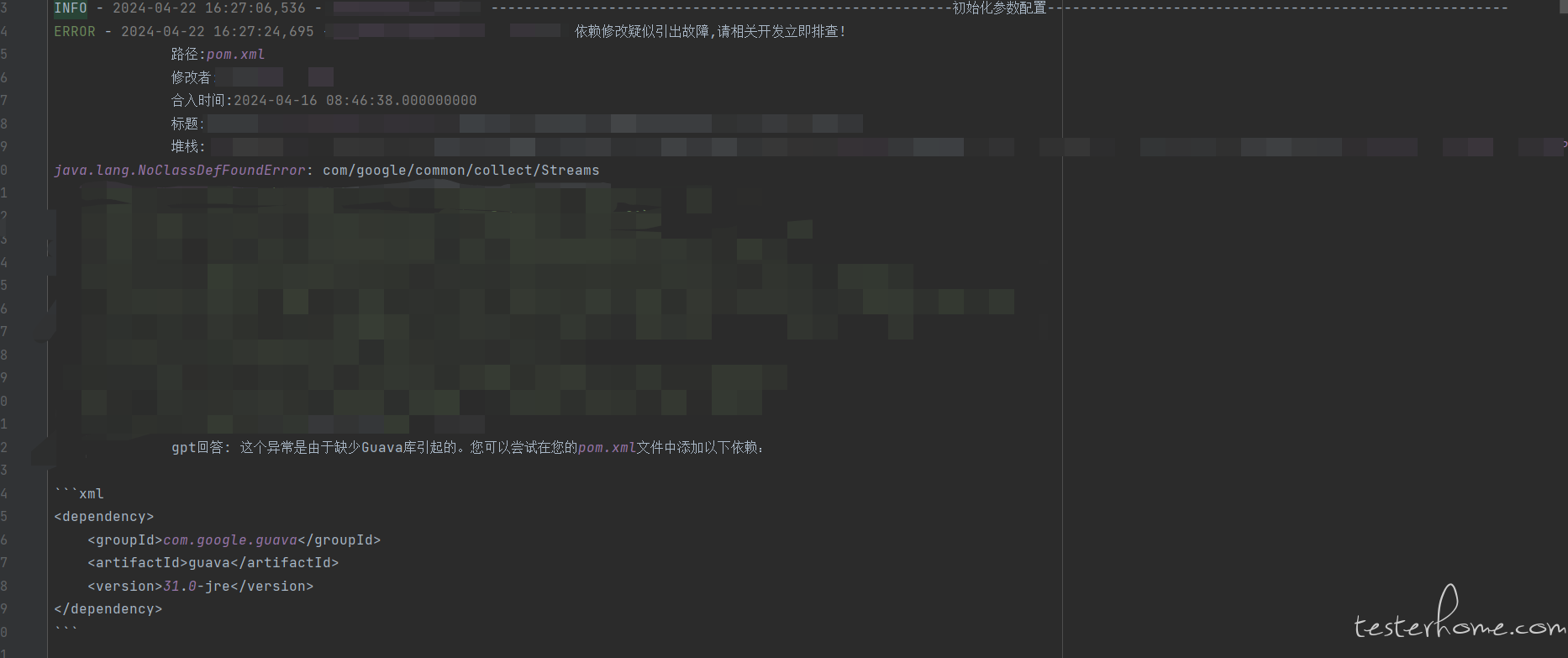
把解析好异常堆栈向大模型提问,自定义模板的大模型提问见下:
出现以下异常是缺少什么 maven 依赖: java.lang.ClassCastException: XXXXXX
大模型回答:
这个问题可能是由于你的项目缺少了 CGLIB 库引起的。你可以尝试在你的 pom.xml 文件中添加以下依赖:
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version> <!-- 你可以选择需要的版本号 -->
</dependency>
然后运行 mvn clean install 以重新构建你的项目并下载所需的依赖
测试用例会从 git 库中获取指定项目指定需求编号的代码提交记录,进行解析和缓存。
获取需要使用的 Method 信息,以最大并发 20 的限制去请求 AI 大模型。以下是 prompt 模版的示例:
## 角色: 代码评审专家
## 背景: 你是一位java语言专家级工程师,具备出色的代码审查能力,能够从多个方面评审代码。
## 任务: - 对指定代码进行系统化地审查。
## 任务细节: 对代码能够从以下方面进行逐一审查:
- 逻辑漏洞:评审代码逻辑是否有缺陷。遵守要求:排除因为没有判空而导致的空指针异常等,不评审因没有判空等而导致的漏洞,不进行入参为空的校验。
- 代码结构:评审代码结构是否清晰、易于理解,变量和函数的命名是否规范。
- 函数实现:评审函数实现是否正确、高效、安全,是否存在潜在的内存泄漏。
- 异常处理:评审异常处理机制是否完善,是否存在可能引发异常或崩溃的代码。
- 数据结构:评审代码中使用的数据结构是否合理,是否能满足实际需求。
- 性能优化:评审代码中是否存在性能瓶颈,是否有不必要的计算和调用等问题,是否可以进行优化。
- 资源泄露:评审代码中是否存在资源泄露,是否有文件流、线程池等未关闭情况。
- 安全性:评审代码中是否存在安全漏洞,是否有防止SQL注入、XSS攻击等安全机制。
- 可读性:评审代码是否清晰易于读懂,注释是否充分、准确、规范。
## 任务输出: 评审代码存在的问题,并输出代码风险等级
## 待评审代码
[这里插入待评审的Java方法代码]
把 AI 大模型返回的 CodeReview 结果写入文件,方便后续查看和分析。
评审结果
代码走查报告
一、逻辑漏洞
在XXX方法中,XXXList values = new XXXList();被初始化为一个单例,然后在多线程环境下被多个线程共享。这可能导致线程安全问题,因为多个线程可能同时修改values的内容。根据方法内的使用情况来看,每个线程应该处理自己的XXXList实例,而不是共享一个。
countDownLatch.await();在调用时未设置超时时间,如果某个线程因为异常或其他原因未能执行countDown,那么主线程将永远等待下去,造成程序阻塞。
二、代码结构
代码结构基本清晰,但是使用了裸线程池和CountDownLatch,使得代码在并发控制上稍显复杂。建议使用更高级的并发工具,如CompletableFuture,以简化代码。
变量命名较为规范,但XXX方法作为lambda表达式中的匿名内部类调用,其参数列表过长,可以考虑封装成对象来传递。
三、函数实现
executor.submit中捕获了所有异常,但只是打印了日志,没有重新抛出或者对异常进行处理,这可能会导致调用者无法得知操作是否成功。
使用了CopyOnWriteArrayList来作为结果集合,这个数据结构适合读多写少的场景。然而,在本例中,写操作(添加元素)频繁发生,这可能会导致性能问题,因为每次写操作都会复制底层数组。如果并发写操作不多,可以考虑使用其他并发集合,如ConcurrentLinkedQueue。
四、异常处理
异常处理机制不完善,如上所述,捕获异常后只是打印了日志,并没有合适的错误处理逻辑。
五、数据结构
CopyOnWriteArrayList的选择可能不是最佳的数据结构,如上所述,它可能不适合写操作频繁的场景。
六、性能优化
由于使用了CopyOnWriteArrayList,且写操作频繁,可能会导致性能问题。建议考虑其他数据结构或并发控制策略。
线程池中的核心线程数设置为1,可能无法充分利用多核CPU资源,如果处理逻辑不是IO密集型的,考虑增加核心线程数。
七、资源泄露
代码中创建了线程池,但未在方法结束时关闭线程池。这可能导致资源泄露,因为线程池会一直存在,即使方法执行完毕。建议在方法结束时关闭线程池,或者使用try-with-resources语句(如果线程池实现了AutoCloseable接口)。
八、安全性
代码中未看到明显的安全漏洞,如SQL注入或XSS攻击,但需要注意XXX和XXX方法内部是否有可能引入安全问题。
九、可读性
代码整体可读性较好,但并发控制和异常处理部分可以进一步简化,以提高可读性。
代码风险等级
综合上述评审,代码存在逻辑漏洞、资源泄露等问题,风险等级评定为中等偏高。建议对上述问题进行修复,以提高代码的健壮性和性能。
这段代码线程泄露的问题当时没有测试到,从而在春节的时候泄露到外场去了 ,导致开发在春节还在排查问题。
,导致开发在春节还在排查问题。
还有一个问题是在修改后,通过大模型评审发现的,就是方法中 new 了个非线程安全的 List,并且线程池提交的多个线程都传入了这个 List,在处理逻辑中又进行了 add 的操作,所以可能会导致数据最后 add 少了或者直接抛出异常。
这些问题虽然很基础,但是如果没有进行代码走查,其实通过黑盒测试很难发现这两个问题,还是体现了该工具产生的价值!
把评审风险为中或者高的结果推送到相关人员进行进一步的人工评审。
通过自动化进行大模型 CodeReview,可以显著减少人工审查的时间和成本,提高代码质量和安全性。在分钟级的时间内就能完成需求或故障修改的大模型 CodeReview,极大地提升了开发效率和代码稳定性。同时,通过并发请求 AI 大模型,可以充分利用计算资源,进一步提高审查速度。
