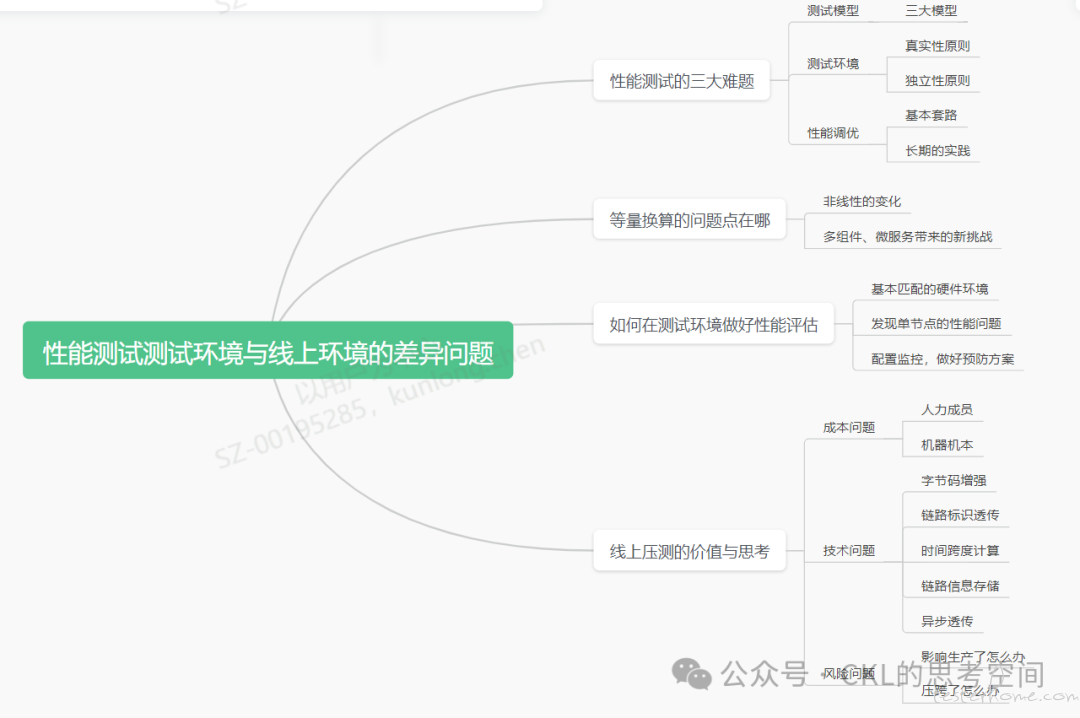
最近有人在咨询性能测试中,测试环境与线上环境的差异问题,想着如何把测试环境的结果拿来评估线上环境的能力,问我有没什么好的换算比例。这个也确实是性能测试中会遇到的三大难题之一。
在接触性能测试之后,基本上都会遇到三个难点:测试模型、测试环境结果换算以及性能调优。
什么是测试模型?简单来说就是如何模拟用户行为,它决定了你做性能测试的基本盘,如果这里没做好,那后续的一切,都是浪费。性能测试模型包含三部分的内容:业务模型(决定了我们要测试哪些场景)、数据模型(在性能测试开始前,我们需要做哪些铺底数据?做多少?)及流量模型(每个功能点或者子系统的流量转化率)。
如何做好性能调优呢?这需要对业务系统的整体技术构架和具体的技术实现有一定的了解,需要具备全局思考的能力。同时,更重要的是,需要有真实业务场景的练习和积累。当然,它也有一定的技巧和思路,后续有机会再展开。
(关于以上两点,可参考:构建性能测试知识体系)
那么,对于不同环境下的压测数据,是否存在一种简单的转换关系?以便于我们能够直接拿测试环境的结果拿来评估线上环境的能力?
在那个没有云的年代,在服务器就那么几种品牌的时代,有一种可直接换算的公式,那就是基于 TPC-C 规范,用于跑分,但是现在已经不适用了。因为现在的物理硬件变得太多样了,同时我们的业务系统也更复杂。基本上不能直接把性能结果用于不同环境之间的直接换算。
理由 1:计算机的硬件配置,性能变化并不是线性的,由于工艺的问题,以前所有的性能问题都可以归结为 IO 问题,但现在不一定了,固态硬盘的出现,基本上让 CPU、内存、硬盘的读写速率处于同一水平线,如何使用这些资源取决于你的代码调用方式。
随着压力的增加,这三者的变化完全不可控,变化速率也不一样,所以,谁会先出现瓶颈,无法预测。
理由 2:业务复杂度的提升、系统架构的演进,进一步导致了性能瓶颈的不可控。你不知道哪个环节会率先出现瓶颈,也许是中间件的消费能力,也许是某个微服务的性能,更有可能只是某个网络节点的抖动,都会影响整体的性能表现。
越精密的东西,其实越不稳定,越容易出错。
所以,不要想着可以直接换算结果,哪怕性能测试环境单机器的硬件与线上的一样,整体架构做了等比缩放,也是不行的。
那么,在测试环境做性能测试,是不是就没有意义了呢?
并不是,本质上,在测试环境做性能测试,更多的是为了验证和解决系统的单点性能问题,排查整体的性能表现下限在哪里。
首先,在测试环境做性能测试时,测试环境的硬件不能与生产差太多,否则整个性能测试就没什么意义,这样测试出来的结果虽然不能等比换算,但它还有基本的参考意义。
其次,在测试环境做性能测试时,我们需要验证系统节点性能没有问题,比如核心接口的压测、基础场景的压测等,它可以发现这些节点的基本性能有没有达标。有利于后续有序地观察系统整体的性能变化情况。
比如配置测试(主要指各技术组件的参数配置,比如中间件的缓存大小、等待时间、线程数等,这些并不是越大越好,需要相互配合,达到最优解)、单接口性能测试、针对性强的简单场景性能测试,都可以在测试环境中发现并优化其性能问题。
如果一上来就做系统整体的性能测试,对于测试结果的分析,会有很大的干扰。
最后,通过测试环境的性能测试,我们可以做好预防方案,知道哪些组件性能较差,那么就可以针对性地做重点监控,以便及时发现问题并启动预案,而不是被动地等待性能问题出现。
综上,性能测试是个系统工程,不能期待通过简单的数据换算就能得到一个定值,因为影响系统性能的因素太多,我们需要通过性能测试环境发现和解决系统中的基础性能问题,使它达到可用的状态,然后在线上通过合理的监控和预警,动态观察系统的性能表现。
可能很多人会提到线上全链路性能压测,可以非常有效地评估系统的性能表现。或者直接在夜深人静的时候,直接压生产环境,验证性能问题。
这是一种可行的方案,但是成本高、风险大,在没有基础技术保障的前提下,不要贸然进行。你需要有运维同事的配合,通过监控快速定位到瓶颈点。同时,还要想清楚如果压挂了,如何快速地恢复系统。
因为你很有可能把其他系统压挂而不自知。那后果可能只有跑路。
关于全链路线上压测的技术实现,现有很多成熟的方案,这里不做赘述,如果要引入全链路线上压测,需要评估好团队现有的技术能力。同时,这件事单靠测试是做不成的。
共勉。